博文
基于预训练表示模型的英语词语简化方法
|
引用本文
强继朋, 钱镇宇, 李云, 袁运浩, 朱毅. 基于预训练表示模型的英语词语简化方法. 自动化学报, 2022, 48(8): 2075−2087 doi: 10.16383/j.aas.c200723
Qiang Ji-Peng, Qian Zhen-Yu, Li Yun, Yuan Yun-Hao, Zhu Yi. English lexical simplification based on pretrained language representation modeling. Acta Automatica Sinica, 2022, 48(8): 2075−2087 doi: 10.16383/j.aas.c200723
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c200723
关键词
词语简化,候选词生成,候选词排序,预训练语言表示模型
摘要
词语简化是将给定句子中的复杂词替换成意义相等的简单替代词,从而达到简化句子的目的. 已有的词语简化方法只依靠复杂词本身而不考虑其上下文信息来生成候选替换词, 这将不可避免地产生大量的虚假候选词. 为此, 提出了一种基于预语言训练表示模型的词语简化方法, 利用预训练语言表示模进行候选替换词的生成和排序. 基于预语言训练表示模型的词语简化方法在候选词生成过程中, 不仅不需要任何语义词典和平行语料, 而且能够充分考虑复杂词本身和上下文信息产生候选替代词. 在候选替代词排序过程中, 基于预语言训练表示模型的词语简化方法采用了5个高效的特征, 除了常用的词频和词语之间相似度特征之外, 还利用了预训练语言表示模的预测排名、基于基于预语言训练表示模型的上、下文产生概率和复述数据库PPDB三个新特征. 通过3个基准数据集进行验证, 基于预语言训练表示模型的词语简化方法取得了明显的进步, 整体性能平均比最先进的方法准确率高出29.8%.
文章导读
在阅读资料时, 如果句子中包含不认识的词语, 将直接影响对文本内容的理解, 特别是阅读非母语的文本. Hirsh等[1]和Nation等[2]的研究表明, 英语学习者需要熟悉文本中95%的词汇才能基本理解其内容, 熟悉98%的词汇才能轻易地进行阅读. 词汇简化 (Lexical simplification, LS) 任务要求在不改变文本的语义、不破坏文本语法结构的情况下降低文本的阅读难度, 常采用的方法是用更简单的词语替换句子中的复杂词语. 词语简化有助于降低文本的阅读难度, 针对的人群包括且不限于儿童[3]、非母语人士[4]、有阅读障碍的人[5-6]等. 词语简化作为文本简化方法的一类, 已经有20多年的发展历史.
早期的LS系统主要使用人工制定或者自动学习的简化规则来完成词汇简化任务[7]. 例如, 使用WordNet生成复杂词的简单同义词[8-10]. 从简单维基百科和普通的维基百科组成的平行语料库中提取复杂词语与简单词语的对应关系[11-13]. 但是这两类方法有很多的局限性. 除了语义词典数据库的制作成本高昂和平行语料库提取困难, 这些规则只能提供有限数量的复杂单词与部分简单同义词的对应关系, 不能够覆盖所有需要简化的单词, 也不能囊括所有合理的简单替换词.
为了解决上述问题, 最近的一些词汇简化方法使用词嵌入模型来获取目标复杂词的简单候选词, 选择在向量空间中与复杂词的词向量余弦相似度最高的一些词语作为候选替代词[14-16]. Glavaš 等[14]在未注释的文本语料库中训练词嵌入模型, Paetzold等[15-16]在带有词性标签的文本上训练语境感知词嵌入模型. 这些方法解决了基于规则方法的局限性. 但是它们生成候选词时没有考虑复杂词的上、下文语境信息, 生成候选替代词集合中不可避免的生成了大量的虚假候选词.
本文提出了一种与已有LS系统完全不同的方法, 利用预训练语言表示模型 (Bidirectional encoder representations from transformers, BERT)[17]获得复杂词的简单替代词. BERT是无监督的通用语义表示模型, 使用掩码语言模型和下一句预测2个任务进行优化. 掩码语言模型通过随机掩码一定比例的输入, 然后根据上、下文对掩码的词进行预测, 这与LS任务中为目标复杂词生成符合语境的简单替代词的模式是可关联的. 本文将句子中的目标复杂词进行掩码后输入BERT模型进行预测, 从掩码词语的预测中选择高概率的词作为候选词, 并对它们进行排序. 具体方法是将两个原句进行串联, 随机掩盖前一个句子中一定比例的单词, 并对后一个句子的复杂词进行掩盖, 将其输入BERT模型, 预测出后一句中掩盖位置的词汇概率分布.
得到生成的候选替代词后, 基于预语言训练表示模型的词语简化方法(BERT-LS)使用5个特征对所有候选词进行排序, 选择平均值排名最高的词作为最佳替代词. 除了已有方法常使用的词频和候选替代词之间的相似度的特征外, 还结合了BERT本身的特色, 利用了BERT的预测顺序和基于BERT的语言模型作为特征, 还额外采用复述数据库PPDB作为特征. 最后, 最佳替代词是否替换原词需要考虑替代词与原词之间的简单程度和替代词与原有上、下文信息之间的流畅性.
图1展示了在词汇简化任务中, 两个基线系统PaetzoldNE[16]、Rec-LS[18]和BERT-LS对句子进行简化的实例. 对于句子“John composed these verses.”中的复杂词“composed”和“verses”, 已有的2个LS系统在生成候选词时只关注复杂词本身, 而没有考虑上、下文语境, 因此这些系统没有能捕获复杂词在句子中的准确词意, 生成的候选词也不符合具体的语境. BERT-LS生成的候选词不仅与复杂词在句子中的词义一致, 而且非常契合上、下文. 通过对生成的候选词进行排序后, 可以很容易地选择“wrote”和“poems”作为“composed”和“verses”的最终替代词. 替换后的句子“John wrote these poems”不仅没有改变句意, 而且保持了句子的语法结构, 达到了句子简化的目的.
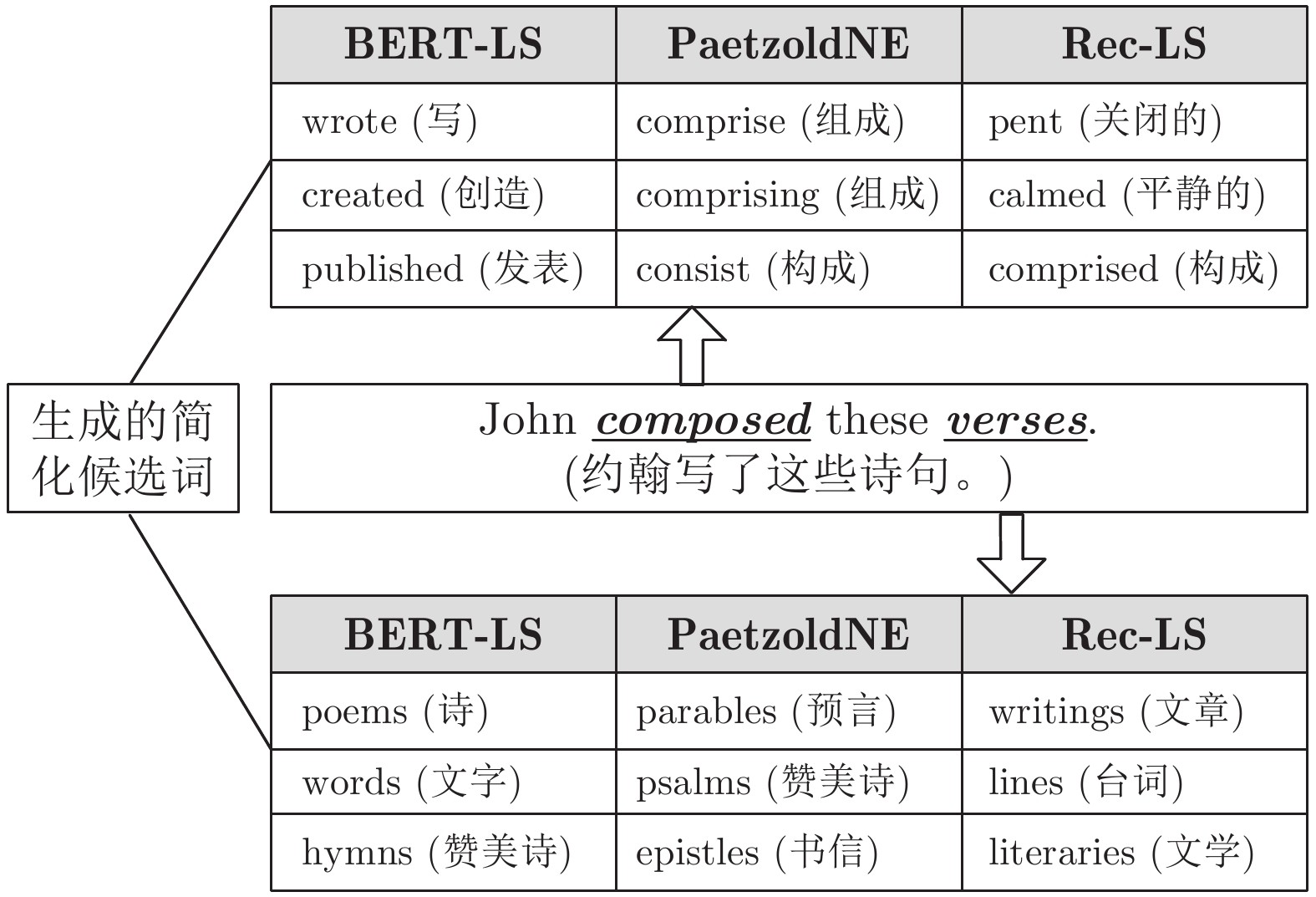
图 1 三种词语简化方法产生的候选替换词进行对比
本文的主要贡献总结如下:
1)提出了一种新的基于预语言训练表示模型的词语简化方法BERT-LS, 充分利用BERT的优势来生成候选替代词. 从查阅到的已有文献可知, BERT-LS是最先尝试利用预训练语言模型进行词语简化的方法. 与现有方法相比, 此方法不仅考虑了复杂词的上、下文信息, 而且生成的候选词无需考虑任何词形的变化.
2)提出了一种新的候选词排序方法. 最先采用了BERT的预测排名和基于BERT的上、下文产生概率, 还首次利用复述数据库PPDB作为一个特征. 这些特征能够充分地考虑候选词本身的简单性和它们与句子的契合程度.
3)BERT-LS在实验评估中优于基线算法, 候选词生成过程的性能比较之前最好的的方法的F值提升了41%, 整体系统的效果在准确率上提升了29.8%. 论文的源代码已公开在https://github.com和qiang2100/BERT-LS.

图 2 BERT-LS使用BERT模型生成候选词, 其中输入为“the cat perched on the mat”
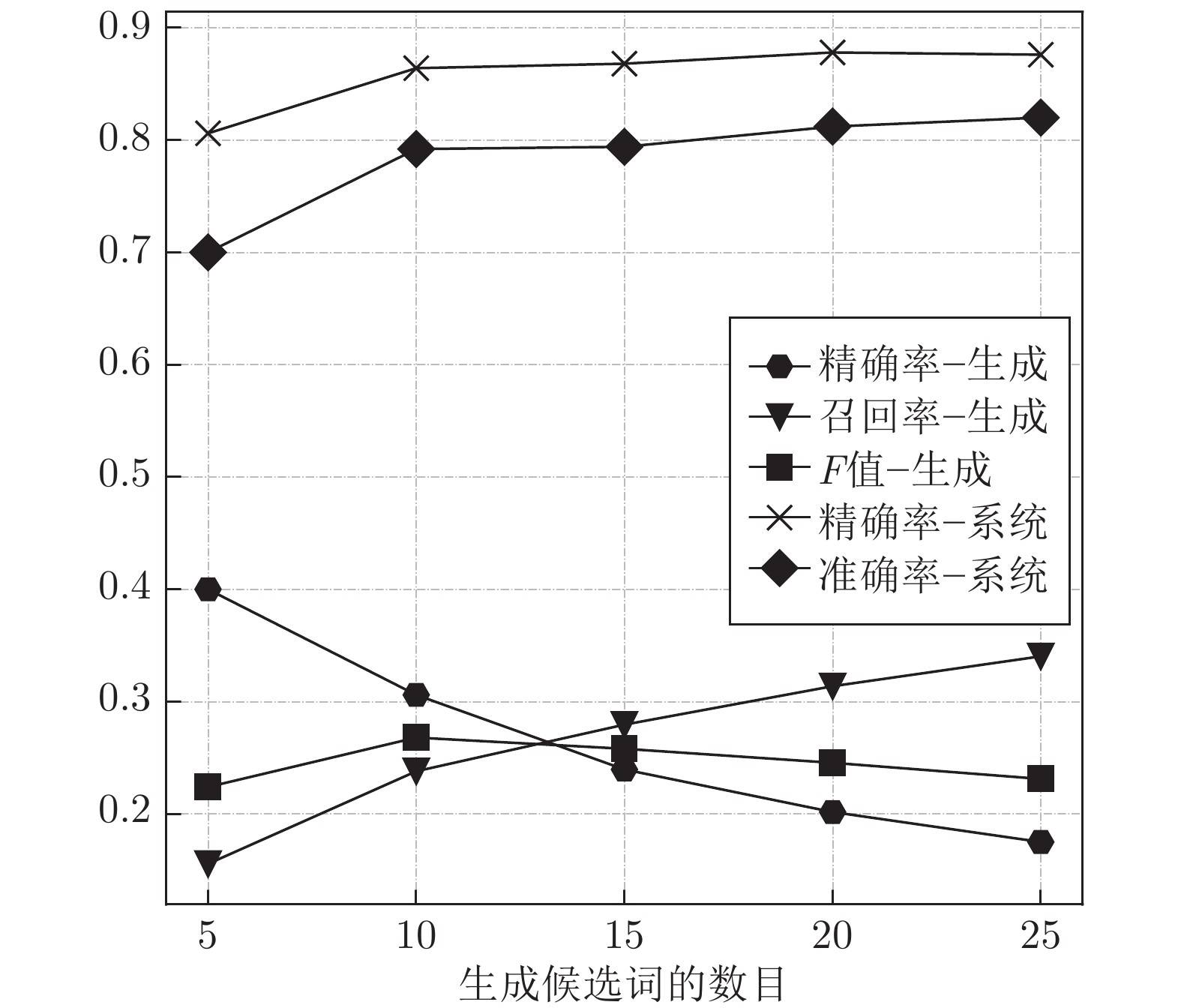
图 5 不同生成候选词数量的评估结果
本文提出了一种基于预语言训练表示模型的词语简化方法BERT-LS, 利用BERT的掩码语言模型进行候选词的生成和排序. 在不依赖平行语料库或语言数据库的情况下, BERT-LS在生成候选替换过程中既考虑了复杂词又考虑了复杂词的上、下文. 在3个的基准数据集上进行实验, 实验结果验证了BERT-LS取得了最好的性能. 由于BERT只利用了原始文本上进行训练, 针对不同语言的BERT模型(如中文、德语、法语和日语等)也被提出来, 因此该方法可以应用到对应语言中进行词语简化.
BERT-LS的一个限制是只能生成一个词而不是多个词来替换复杂的词. 下一步计划扩展BERT-LS支持多个词的替代, 进一步提高模型的实用性.
作者简介
强继朋
扬州大学信息工程学院副教授. 2016年获合肥工业大学计算机博士学位. 主要研究方向为数据挖掘和自然语言处理. E-mail: jpqiang@yzu.edu.cn
钱镇宇
扬州大学信息工程学院硕士研究生. 主要研究方向为主题建模和数据挖掘.E-mail: qzyjnwss@126.com
李云
中国扬州大学信息工程学院教授. 主要研究方向为数据挖掘和云计算. 本文通信作者. E-mail: liyun@yzu.edu.cn
袁运浩
扬州大学信息工程学院副教授. 2013年获南京理工大学模式识别与智能系统博士学位. 主要研究方向为模式识别, 数据挖掘和图像处理. E-mail: yhyuan@yzu.edu.cn
朱毅
扬州大学信息工程学院讲师. 2018年获合肥工业大学软件工程博士学位. 主要研究方向为数据挖掘和知识图谱. E-mail: zhuyi@yzu.edu.cn
https://m.sciencenet.cn/blog-3291369-1350565.html
上一篇:递归最小二乘循环神经网络
下一篇:基于梯形网络和改进三训练法的半监督分类