博文
F-邻域粗糙集及其约简
|
引用本文
邓志轩, 郑忠龙, 邓大勇. F-邻域粗糙集及其约简. 自动化学报, 2021, 47(3): 695-705 doi: 10.16383/j.aas.c180556
Deng Zhi-Xuan, Zheng Zhong-Long, Deng Da-Yong. F-neighborhood rough sets and its reduction. Acta Automatica Sinica, 2021, 47(3): 695-705 doi: 10.16383/j.aas.c180556
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c180556
关键词
邻域粗糙集,F- 粗糙集,属性约简,属性重要度矩阵
摘要
邻域粗糙集可以直接处理数值型数据, F- 粗糙集是第一个动态粗糙集模型. 针对动态变化的数值型数据, 结合邻域粗糙集和F- 粗糙集的优势, 提出了F- 邻域粗糙集和F- 邻域并行约简. 首先, 定义了F- 邻域粗糙集上下近似、边界区域; 其次, 在F- 邻域粗糙集中提出了F- 属性依赖度和属性重要度矩阵; 根据F- 属性依赖度和属性重要度矩阵分别提出了属性约简算法, 证明了两种约简方法的约简结果等价; 最后, 比对实验在UCI数据集、真实数据集和MATLAB生成数据集上完成, 实验结果显示, 与相关算法比较, F- 邻域粗糙集可以获得更好的分类准确率. 为粗糙集在大数据方面的应用增加了一种新方法.
文章导读
大数据时代下, 数据快速扩展, 在生产实践中获得的属性越来越多. 一部分属性可能是冗余的或与分类任务无关, 在进行任何进一步数据处理之前都需要将它们删除. 属性约简(或特征选择)是一种用于减少属性的技术. 其目的是找到最佳属性子集来预测样本类别. 属性约简还可以促进数据可视化和数据理解[1].
属性约简过程中存在一个关键问题: 属性评估. 如何有效地评估属性是最重要的步骤之一, 它直接影响分类器的性能. 迄今为止已经提出了许多属性评估准则, 例如信息熵[2]、依赖性[1]、相关性[3]和一致性[4]等. 通常, 不同的评估标准可能导致不同的最佳特征子集. 但是, 每项措施都旨在确定特征子集的区分能力.
粗糙集理论[5-6]是一种有效属性约简工具, 产生了增量式约简[7]、动态约简[8]、多决策表约简[9]和并行约简[10-11]等属性约简方法. 但是, 传统粗糙集模型仅适用于非数值型数据. 需要对数值型特征进行离散化, 而离散化会带来信息损失.
研究者们通过拓展粗糙集模型来解决这一问题, 如邻域粗糙集[12-21]、模糊粗糙集[22-25]等. 文献[13-14]基于邻域信息粒子逼近, 提出了邻域信息决策模型和数值型属性的选择算法, 能够无须离散化而直接处理数值型属性, 解决了离散化带来的信息损失问题, 使粗糙集模型得以更方便地处理现实生活中大量存在的数值型变量. 后继的研究者引入加权依赖度[15]、局部粗糙集[16]、模糊邻域与模糊决策[17]、Fish swarm算法[12, 18]等丰富了邻域粗糙集理论, 并将其应用推广于多标记数据的特征选择[19]、并行属性约简[20]、动态图像分类[21]等方面. 但并未考虑如何处理包含多个领域数据的数据集, 而不同类型数据的处理准则和要求有所不同, 如果放在同一个信息表中处理, 处理结果往往不尽如人意.
F- 粗糙集[26-29]是第一个动态粗糙集模型, 其子集可以很好地表示不同情况下的概念, 从而解决处理包含多个领域数据的动态属性约简问题. 其后研究结合了模糊粗糙集[28], 初步应用于非数值型数据. F- 粗糙集比较突出的应用在于概念漂移探测[29], 但相对较缺少非数值型数据处理方面的应用.
为了更好地解决邻域粗糙集和F- 粗糙集所遇到的问题. 本文结合邻域粗糙集和F- 粗糙集的优势, 提出了一种新的粗糙集模型——F- 邻域粗糙集. 首先定义F- 邻域粗糙集的邻域关系, 使用邻域决策子系统来表示不同情况. 然后, 使用F- 属性依赖度和属性重要度矩阵来评估属性. 充分考虑了在多种情况下同一概念的不同, 同时克服了邻域粗糙集模型和F- 粗糙集模型的缺陷. 最后设计了两个属性约简算法, 证明了约简结果的等价性, 并说明了它们的适用范围. 实验结果表明, 相对于邻域粗糙集、F- 粗糙集和主成分分析(Principal component analysis, PCA), 本文算法能获得更好的分类准确率.

图1 概念X在FIS中的上近似、下近似、边界区域、负区域
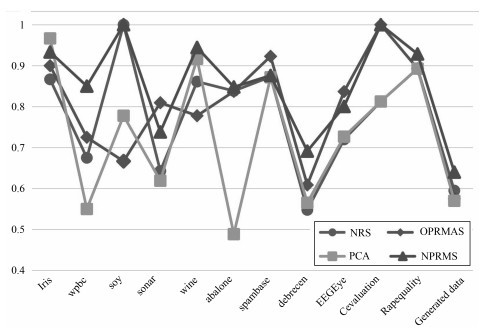
图2 在各个数据集中算法的分类准确率
减少冗余属性可以提高分类性能并降低分类成本. 在本文中, 首先介绍了两种粗糙集模型: F- 粗糙集和邻域粗糙集. 由于两种粗糙集模型都具有自身的优势, 但双方都未考虑对方的优点, 因此提出了F- 邻域粗糙集. 该模型结合了两个粗糙集模型的优势, 是一个无需离散化处理数值型数据的动态粗糙集模型. 最后, 用F- 属性重要度和属性重要度矩阵来评估属性, 使用它们来设计属性约简算法, 并说明两种算法的相同点和不同点. 实验结果表明两种算法能获得较高的分类准确率. 实验中还发现决策子系统的划分对所提出的两种属性约简算法的性能的影响较大. 应该根据属性数目和数据项数目为每个数据集选择合适的决策子系统划分.
未来的工作可能包括: 1)如何将所提出的模型应用于具有不确定性的分类学习和推理领域; 2)在所提出的模型中, 在数据集中划分决策子系统对所提出算法的性能具有重要影响. 它需要由用户提前划分. 如何为每个数据集自动自动划分决策子系统的最佳解决方案也是一项有意义的工作.
作者简介
邓志轩
浙江师范大学硕士研究生. 2016年获得河南师范大学电气工程及其自动化专业学士学位. 主要研究方向为粗糙集与图像识别技术. E-mail: zhixuandenga@163.com
邓大勇
浙江师范大学行知学院副教授. 2007年获得北京交通大学计算机应用技术专业博士学位. 主要研究方向为粗糙集理论及应用. E-mail: dayongd@163.com
郑忠龙
浙江师范大学数学与计算机学院教授. 2005年获得上海交通大学模式识别与智能系统专业博士学位. 主要研究方向为机器学习与模式识别. 本文通信作者. E-mail: zhonglong@zjnu.edu.cn
https://m.sciencenet.cn/blog-3291369-1358369.html
上一篇:基于方向场正则化的线描画生成算法
下一篇:具有拓扑切换特性的离散型不确定时空网络的指数同步