

现在深度学习(Deep Learning)得到广泛的工程应用,有时会和人工智能
混淆,本文介绍一下人的智能,人工智能,深度学习三者的区别和联系。
一 人工智能的一般概念
1956年夏,麦卡锡、明斯基等科学家在美国达特茅斯学院开会研讨
“如何用机器模拟人的智能”,首次 提出“人工智能(Artificial
Intelligence,缩写AI)”概念,标志着人工智能学科的诞生。
人工智能是研究开发能够模拟、延伸和扩展人的智能的理论、方法、
技术及应用系统的一门技术科学,研究目的是促使智能机器会听
(语音识别、机器翻译等)、会看(图像识别、文字识别等)、会说
(语音合成、人机对话等)、会思考(人机对弈、定理证明等)、会学习
(机器学习、知识表示等)、会行动(机器人、自动驾驶汽车等)。
人工智能3个主要的路线:
1. 确定性计算,比如专家系统,数理逻辑
2. 不确定性计算。基于概率统计。
3. 机器学习ML【1】,即计算机自动学习。深度学习是通过引入神经网络
(Neural Networks)实现机器学习的一种技术,特别依赖概率统计计算。
有时也结合确定性计算,比如AlphaGo下棋算法。
人工智能里解决类比问题的分支,并采用神经网络的技术,
这套事务综合起来叫神经网络学习技术,又叫深度学习。
二 人脑图形类比推理
先来做图形类比题。见图1。如果A变到B,那么C变到D,E,F中哪一个?
解答:A->B,我们人脑总结出规则,
不妨称之为规则I:比例未变,旋转了45°。
C->D,比例未变,旋转了45°,符合规则I;
C->E比例变了,
C->F 没有旋转。
既然我们从A->B学到了规则I,那么根据规则I,我们推断出C->D。
A,B用于训练,我们叫训练集。训练集数据越多越好。
C,D,E,,叫测试集,用来测试规则I是否可用。

三.神经网络图形类比推理
我们可以模拟人的神经细胞网络建个人工神经网络模型N,见图2。
N的结构是人指定的。
告诉N输入是A,输出是B,那么可以根据一些最优化(最小二乘法,
最大梯度下降法。。)算法或者贝叶斯定理推断倒推出N中的参数
(权重)【2】。
N的结构和参数确定后,N就具备了推理规则AI,
给N输入图形数据C,它会根据规则AI,判断出仅有C->D 符合规则.
上述人工神经网络的工作过程,又称为有监督(数据有标注)学习。
四. 人脑和机器/深度学习的共性:迁移学习
人脑/动物大脑天然已经通过遗传得到很多初始化参数,知识并进而
有很多功能,后天会改变这些功能,比如瞎子的听觉得到强化。
但是还有很多知识和一些功能是后天通过对广义数据的学习训练得到的。
而神经网络模型/机器/计算机一般初始是没有先验知识和功能的。
人脑/动物大脑或者神经网络模型受到训练后,形成规则或者经验,
再把这些规则或者经验迁移到新的数据或者领域。因此深度学习
并非只是单纯学习,而有两个含义,一是先学习,二是后判断。
当训练集和测试集数据类型相同时,上述学习步骤称为有监督学习,
训练集和测试集数据类型有差异时,上述学习步骤称之为迁移学习。
不失一般性,本文把监督学习视为迁移学习的特例。前面讲的(图形)
类比推理也属于迁移学习的一个例子。
深度学习即神经网络(模型)学习,和人脑/动物大脑学习有什么
区别呢?
它们的内涵有重叠之处,他们都是各种变形的迁移学习方式,
或者说迁移学习范式(paradigm)。但是人脑的功能远不止是迁移
学习范式,比如还有数学推理等等,这是动物所不会的。
五. 深度学习能取代人的智能吗?
人脸识别是深度学习最常见的应用。先喂给空白神经网络模型很多
同一人的证件照和摄像头拍的头像数据,空白的神经网络模型根据这些
数据计算出的模型参数,模型就做好了。火车站,机场,门禁都用这种
模型比对身份证件和人脸的相似度。
这个原理可以推广到其他目标检测和识别场景。
生物特征(人脸)识别/目标检测等重复性的简单智能,
并非人独有,动物也会。
深度学习还是人的智能高?这要看采用什么标准,在什么领域。
深度学习在某些特定的,重复性工作的领域,比如目标检测,
有速度和成本的优势。
从目标(图像,声音识别,情绪,语义词义)识别功能上讲,
大概相当于几岁的小孩或者宠物。
在医学图像方面有成功的经验。
对于封闭性有固定规则的问题,比如下棋,有速度和计算准确的优势,
可达到专业人员水平。
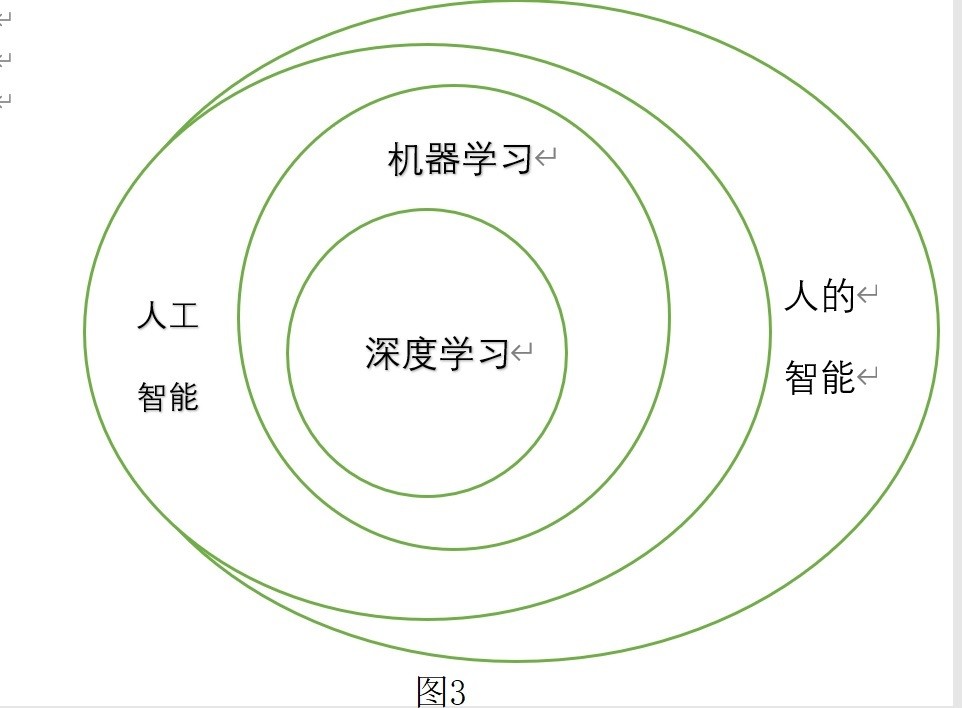
深度学习远不能涵盖人工智能的全面内容,而人工智能离人的智能
也还十分遥远,见图3。深度学习全面取代人的智能那是艺术想象。
参考文献:
【1】科学网—人工智能(机器深度学习..)无关乎人的智能 -
【2】(18条消息) 贝叶斯通俗易懂推导_jiangjiane-CSDN博客_
在贝叶斯写这篇文章之前,人们已经能够计算“正向概率”,如“假设袋子里面有 N 个白球,M 个黑球,你伸手进去摸一把,摸出黑球的概率是多大”。而一个自然而然的问题是反过来:“如果我们事先并不知道袋子里面黑白球的比例,而是闭着眼睛摸出一个(或好几个)球,观察这些取出来的球的颜色之后,那么我们可以就此对袋子里面的黑白球的比例作出什么样的推测”。这个问题,就是所谓的逆向概率问题。
条件概率:
P(B|A) = P(A|B) * P(B) / [P(A|B) * P(B) + P(A|~B) * P(~B) ], 收缩起来就是: P(B|A) = P(AB) / P(A)
示例:根据新情况更新先验概率
《决策与判断》第十二章中讲到人们都有保守主义情结,即使出现了新信息,也不愿意根据新信息来更新先验概率。用前面解释里面的话说就是:新信息是 B 事件不断发生,人们本应该根据这个信息去更新 A 事件发生的概率,但人们却更愿意固守之前估计的 A 事件发生的概率。
书中举了这样一个调查案例:
假设有两个各装了100个球的箱子,甲箱子中有70个红球,30个绿球,乙箱子中有30个红球,70个绿球。假设随机选择其中一个箱子,从中拿出一个球记下球色再放回原箱子,如此重复12次,记录得到8次红球,4次绿球。问题来了,你认为被选择的箱子是甲箱子的概率有多大?
调查结果显示,大部分人都低估了选择的是甲箱子的概率。根据贝叶斯定理,正确答案是96.7%。下面容我来详细分析解答。
刚开始选择甲乙两箱子的先验概率都是50%,因为是随机二选一(这是贝叶斯定理二选一的特殊形式)。即有:
P(甲) = 0.5, P(乙) = 1 - P(甲);
这时在拿出一个球是红球的情况下,我们就应该根据这个信息来更新选择的是甲箱子的先验概率:
P(甲|红球1) = P(红球|甲) × P(甲) / [P(红球|甲) × P(甲) + (P(红球|乙) × P(乙))]
P(红球|甲):甲箱子中拿到红球的概率
P(红球|乙):乙箱子中拿到红球的概率
因此在出现一个红球的情况下,选择的是甲箱子的先验概率就可被修正为:
P(甲|红球1) = 0.7 × 0.5 / (0.7 × 0.5 + 0.3 × 0.5) = 0.7
即在出现一个红球之后,甲乙箱子被选中的先验概率就被修正为:
P(甲) = 0.7, P(乙) = 1 - P(甲) = 0.3;
如此重复,直到经历8次红球修正(概率增加),4此绿球修正(概率减少)之后,选择的是甲箱子的概率为:96.7%。
我写了一段 Python 代码来解这个问题:
计算选择的是甲箱子的概率
1. def bayesFunc(pIsBox1, pBox1, pBox2):
2. return (pIsBox1 * pBox1)/((pIsBox1 * pBox1) + (1 - pIsBox1) * pBox2)
3. def redGreenBallProblem():
4. pIsBox1 = 0.5
5. # consider 8 red ball
6. for i in range(1, 9):
7. pIsBox1 = bayesFunc(pIsBox1, 0.7, 0.3)
8. print " After red %d > in 甲 box: %f" % (i, pIsBox1)
9. # consider 4 green ball
10. for i in range(1, 5):
11. pIsBox1 = bayesFunc(pIsBox1, 0.3, 0.7)
12. print " After green %d > in 甲 box: %f" % (i, pIsBox1)
13. redGreenBallProblem()
程序运行结果如下:在这个调查问题里面,8次红球与4次绿球出现的顺序并不重要,因为红球的出现总是使选择的是甲箱子的概率增加,而绿球的出现总是减少。因此,为了简化编程,我将红球出现的情况以及绿球出现的情况摆在一起了。
不断修正的选择的是甲箱子的先验概率
1. After red 1 > in 甲 box: 0.700000
2. After red 2 > in 甲 box: 0.844828
3. After red 3 > in 甲 box: 0.927027
4. After red 4 > in 甲 box: 0.967365
5. After red 5 > in 甲 box: 0.985748
6. After red 6 > in 甲 box: 0.993842
7. After red 7 > in 甲 box: 0.997351
8. After red 8 > in 甲 box: 0.998863
9. After green 1 > in 甲 box: 0.997351
10. After green 2 > in 甲 box: 0.993842
11. After green 3 > in 甲 box: 0.985748
12. After green 4 > in 甲 box: 0.967365
转载本文请联系原作者获取授权,同时请注明本文来自徐明昆科学网博客。
链接地址:https://m.sciencenet.cn/blog-537101-1293612.html?mobile=1
收藏