博文
文献阅读笔记(10)-利用信息熵进行网页去噪的方法
||||
[1] Yi L,Liu B.Web Page Cleaningfor Web Mining through Feature Weighting[C] Proc of the 18th Int Joint Conf onArtificial Intelligence(IJCAI-03).SanFrancisco:MorganKaufmann,2003:43-50
本文的方法
先将DOM树转化为CST树(Compressed Structure Tree,压缩结构树),然后计算CST树中节点的信息熵及叶子节点(即页面中的各个块)中的特征的权重,继而得到页面的特征向量(feature vector).(疑问:根据特征权重怎么去判断网页噪声呢?)
几个定义
Global noise(全局噪声):It refers to redundantobjects with large granularities, which are no smaller than individual pages.Global noise includes mirror sites, duplicated Web pages and old versioned Webpages to be deleted, etc.
Local (intra-page) noise(局部噪声): It refers to irrelevant items within a Webpage. Local noise is usually incoherent withthe main content of the page. Such noise includes banner ads, navigationalguides, decoration pictures, etc.
呈现样式(presentation style):DOM树中节点T的呈现样式用ST:<r1,r2,…,rn >表示.其中ri 由<Tag,Attr>构成,表示节点T中的第i 个孩子节点的标签和属性.当两个节点的样式满足下面条件时可以说这两个节点的样式相同:1)孩子节点树相同2)两个节点的第i 个孩子节点的Tag和Attr都分别相同.
元素节点(element node ):元素节点E表示CST树中的节点,用<Tag, Attr, TAGs, STYLEs,CHILDs >表示,其中Tag是E的标签名称,Attr是E的属性,TAGs是E的孩子节点的标签序列,STYLEs是E所覆盖的DOM树中的所有节点(标签)的样式集,CHILDs指向E孩子节点的指针. 下图是CST树的一个例子.

CST树的构造过程
1. 将所有DOM树的根节点合并成CST树的第一个元素节点(root). TAGs是DOM树根节点的标签集合.
2. 计算元素节点的STYLEs. 即原来DOM树中的所有节点的样式,相同的呈现样式会被合并.
3. 进一步合并孩子节点.由于E1,E2的Tag和Attr都分别相同,接下来比较E1,E2的文本内容.如果两个节点的文本特征(用Ii表示单词出现的频次,当Ii>=γ时则认为是文本特征)满足|I1∩I2|/|I1∪I2| ≥ λ,那么就进行合并.本文取γ,λ为0.85.
4. 如果没有孩子节点可以合并,那么就结束.否则取出孩子节点,进入第2步.
权重策略
1) CST树的内部节点E的重要度用下式计算.
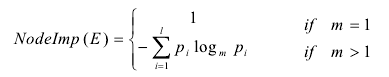
其中,l=| E.STYLEs|, m=E.TAGs.pi表示E.TAGs中的标签使用第i种样式的概率.
2) CST树的叶子节点E的重要度用特征的平均重要度来计算.

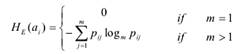
ai表示节点E的内容特征.HE(ai)表示特征的信息熵.由于NodeImp(E)只是反映了E的局部重要性,为了计算叶子节点的权重,还需要考虑从根节点到叶子节点的路径的重要度.

最后权重的计算公式为:
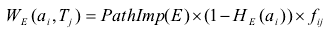
其中fij为特征ai在标签Tj下出现的频率.
在实际操作中,并没有采用真实的CST树的叶子节点来计算,而是用叶子节点的祖父母节点来计算,因为真实的叶子节点粒度很小.
3) 页面中块的权重计算出来之后,就把具有相同特征的块赋予权重,所有的这些特征权重构成页面的特征向量,用作聚类和分类的输入量.
实验分析
1)数据集.

2)衡量指标.用FScore来评价该方法在分类(k-means)和聚类(SVM)中的表现.
[2] Lin S H,Ho J M.Discoveringinformative content blocksfrom Web documents[C] Proc of the 8th ACM SIGKDDInt Conf on Knowledge Discovery and DataMining.NewYork:ACM,2002:588-593.
本文的方法
本文认为TABLE是HTML分块的依据,并且认为一个网站的网页同属一个页面群(page cluster,即共用相同的网页模板). 方法步骤如下:
基于TABLE标签从HTML中抽取出内容块
然后再从每个内容块中抽取特征(与关键字相关的文本或术语)
根据特征在页面群中出现的频率计算特征熵
通过加和得到内容块的信息熵(用H(CB)表示)
若H(CB)值大于阈值或越接近于1那么判为冗余块,反之则认为该内容块是信息块. 其中,阈值由贪婪法来确定,从0.1到0.9进行实验,依次增加0.1.
实验分析
1) 数据集. 选取13个新闻网站(都用TABLE来布局),每个网站选取10个页面
2) 衡量指标. 查准率(Precision),召回率(Recall).
论文点评
由于是较早的一篇文献,文中所提出的方法依赖很强的假设前提,比如1)认为大多数网站利用TABLE来布局2)认为网站的所有页面属于同一个页面群3)认为dot-com类的网站都是”上下左右”四个块的布局样式4)基于信息熵来判定冗余块的标准跟后续的相关研究有出入,即后续研究认为H(CB)值大于阈值或越接近于1那么判为信息块,反之则认为该内容块是冗余块. 除此之外,本文在内容块的抽取,信息熵的计算等关键环节描述得很模糊,使得读者难以细入研究.
https://m.sciencenet.cn/blog-719488-807872.html
上一篇:文献阅读笔记(9)-基于风格树的网页去噪方法
下一篇:文献阅读笔记(11)-基于VIPS的网页分块算法