博文
文献阅读笔记(13)-消去网页模板以提升信息检索性能
||||
消去网页模板以提升信息检索性能
[1] Yu S,Cai D,Wen J R,etal.Improving pseudo-relevance feedback in Web information retrieval using Web page segmentation [C] Proc of the 12th World Wide Web Conf.New York:ACM,2003.
Pseudo-Relevance Feedback从初始查询结果中选取k个页面,并抽取20-30个词语作为查询扩展,再次进行检索并将最终结果返回给用户.这样做是为了提高查询结果与用户query之间的相关性.
论文思路:InitialRetrievalàPage Segmentation (VIPS) àSegment SelectionàExpansionTerm Selection àFinal Retrieval.
VIPS
页面中存在很多视觉提示(visual cues)便于区分页面中的不同部分,如线条、空白区、图像、不同字体大小、不同颜色等. 基于视觉的内容结构跟树形结构相似,每个节点代表页面中的一个区域,并用内聚度反映节点内容的一致性.基于视觉的内容结构树能对页面进行语义上的分块,是DOM结构和语义结构的桥梁. 其有三个步骤:视觉块抽取à分隔符检测à内容结构创建. 第一步运用一些启发式规则(包括标签提示、颜色提示、文本提示、大小提示)来判定是否需要对DOM叶子节点作进一步划分,该步骤结束后每个节点就代表一个视觉块并且具有相应的DoC值. 第二步运用一些启发式规则(包括距离模式、标签模式、字体模式、颜色模式)来选择视觉块之间的分隔符. 第三步在第二步的基础上把分隔符同一侧的视觉块合并,并且作为内容结构树的一个节点.
数据集来源
Bailey, P., Craswell, N., and Hawking, D., Engineering a multi-purpose test collection for Web retrieval experiments , Information Processing and Management, in press.
实验分析
1)数据集. 选取Okapi作为检索系统,TREC-9的WT10g和TREC 2001 Web Track作为数据集. WT10g中有169万个页面.从TREC 2001 Web Track中选取50个queries .
2)衡量指标. 将传统的方法(FULLDOC),基于DOM的方法(DOMPS)和基于VIPS的方法对页面进行处理后检索得到的结果进行对比.
[2] Ma L,Goharian N,ChowdhuryA,et al.Extracting unstructured data from template generated Web documents[C]Procof the 12th Int Conf on Information and Knowledge Management.NewYork:ACM,2003:512-518.
Pagelet:a self-contained logical region within a page that has a well-defined topic or functionality.(页面中一个独立的逻辑区域且有明确的主题或者功能.) [Pagelet定义来源文献:Z. Bar-Yossef, S. Rajagopalan, “Template Detection via Data Mining and its Applications”, WWW02,2002.]
Template:a template is a consecutive group of text tokens that: (a) appear in every page belonging to that template, (b) share the same geometrical location and size within the web pages, (c) serve primarily as navigation, trademark, or advertising without providing otherinformation.
Table text chunk:A table text chunk is consecutive terms extracted between a pair of closest HTML table tags.(表间文本块是指从相邻TABLE标签之间抽取出的一段连续性短语).
论文思路
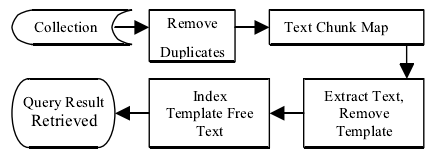
思路说明:首先运用IMatch算法检测网页集合中的重复页面(duplicate page)并去除,然后对页面进行两次遍历,第一遍将遇到的Table text chunk进行存储,并对其在页面集合中出现的次数计数,第二遍识别出现次数大于阈值的Table text chunk(这些就是模板类的Table text chunk),并对低于阈值的Table text chunk(内容类的Table text chunk)建立索引,并且作为输出结果.接下来进行queries检索实验,对比处理模板前和处理模板后的检索结果.
实验分析
1)数据集. 选用cnnfn网站的55711个页面作为检索源.从10000条该网站用户的queries中得到了800条与模板相关的query,去掉诸如”bill gates”,”interest rate cut”等520个具体名词类的queries,剩余280个抽象名词类的queries,基于此进行检索实验.
2)衡量指标. Froelich (1994)提出的衡量文档相关性的标准:话题性(topicallity),感知有效性(perceived validity),新颖性(novelty).Su (1998)提出评估模型,该模型包括对effectiveness(效用),efficiency(效率),user satisfaction(用户满意度),reliability of connectivity(连通可靠性),user characteristics(用户特征)的测量.
[3] NAVEENSUNDAR,G., D. NARMADHA, and AP HARAN. "SIMPLIFIED SCHEME FOR PERFORMANCE AUGMENTATION OF WEB DATA EXTRACTION." Journal of Theoretical & Applied Information Technology 60.3 (2014).
本文提出了一种用于网页模板检测的新的页面表示方法,使用DOM树的路径(path).如图
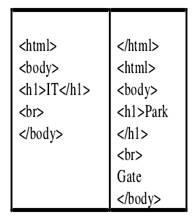

左边是两个页面的HTML标签列表,右边则是页面对应的path及pathno(代表path出现的次数). 每个页面会定义一个LPT(least path threshold) 和MST(minimum support threshold),前者是每个页面路径中的pathno值的众数(mode),后者是每个页面路径的支持度(support).如果一条路径满足LTP那么它是non-content path,如果一条路径满足MST那么它是页面的关键路径.
论文思路
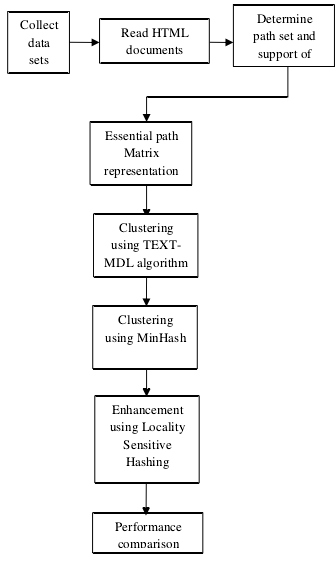
思路说明:对从5个网站中获取的页面进行读取和解析,根据解析结果LPT和MST被确定,进一步找出页面的关键路径并用矩阵表示.接着用TEXT-MDL进行聚类,从聚类结果中可以确定页面的模板.然后用另一个与此方法近似的MinHash再做一次聚类.为了提高整体的性能用LSH方法又做了一次聚类.最后比较三种方法在执行时间和内存使用上的表现.
https://m.sciencenet.cn/blog-719488-808770.html
上一篇:文献阅读笔记(12)-LRU分页算法对网页去噪的启示
下一篇:文献阅读笔记(14)-布局信息/锚文本/块分析