博文
文献阅读笔记(15)-基于STU-DOM的网页主题信息自动提取方法
||||
基于STU-DOM的网页主题信息自动提取方法
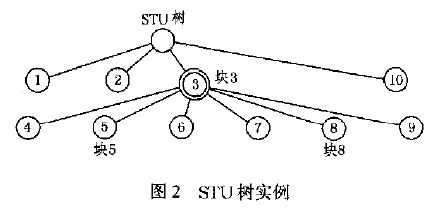
STU(SemanticTextual Unit)语义文本单元,DOM(Document ObjectModel)文档对象模型。首先将网页划分为几个块(block ),然后以这些块为结点构建STU树,STU树反映了源网页的上下文语义关系。如下图所示,图1中对网页进行了块的划分,图2基于块的嵌套关系构建了STU树。

WEB信息提取系统分为5个部分:HTML解析器à过滤器à分块器à语义分析器à剪枝器
2 HTML解析器(HTMLParse)将HTML文档解析成DOM树
2 过滤器是从DOM树中删除无关节点
2 分块器是向STU结点中添加语义属性,将DOM树转化为STU-DOM树
2 语义属性值由语义分析器计算
2 剪枝器从STU-DOM树中删除无关链接列表和没有内容的块,最后输出只含主题信息的HTML文档
实验分析
1)数据集. 选取了新浪新闻1252个网页,搜狐娱乐1168个网页,网易财经1121个网页,e国电子商务1613个网页,京卫大药房医药1159个网页进行分析。
2)衡量指标. 实验提取结果如下图所示

完整性:主题内容完整的网页数占源网页数的百分比
无关链接比:删除的无关链接数占源网页中所有链接数的百分比
压缩比:结果网页的大小占源网页大小的百分比
平均无关链接比和平均压缩比是自动计算的结果,完整性是随机抽样10%进行人工分析的结果。
参考文献
[1] 王琦,唐世渭,杨冬青,王腾蛟.基于DOM的网页主题信息自动提取[J].计算机研究与发展,2004(10):1786-1792.
https://m.sciencenet.cn/blog-719488-810964.html
上一篇:文献阅读笔记(14)-布局信息/锚文本/块分析
下一篇:文献阅读笔记(16)-网页的块重要性学习模型