博文
文献阅读笔记(19)-基于Crunch的网页内容提取的应用
||||
基于Crunch的网页内容提取的应用
Crunch是哥伦比亚大学Suhit Gupta牵头开发出来的一个页面代理(web proxy),与浏览器配合使用,对HTML页面进行内容过滤。其有独立的图形用户界面,用于手动设置各种过滤器(filter)。Crunch界面如下图所示:

其架构图如下:

通过设置不同的过滤条件,Crunch实现不同的过滤效果,如下所示:

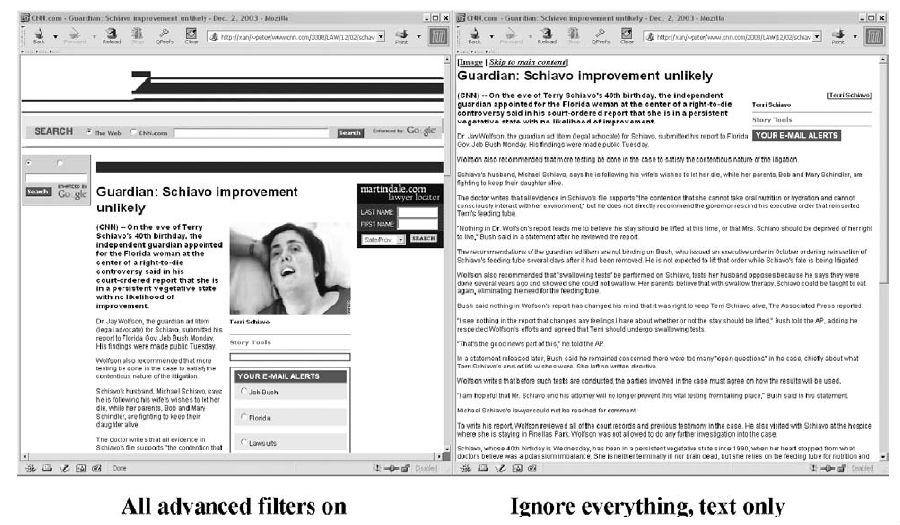
文献[1][2]介绍了Crunch的一些技术细节,其中[2]几乎涵盖了[1]的所有内容。由于Crunch在实施过程中需要人工配置filter,文献[3]对此缺陷作了改进。首先对访问排名前200的网站手工分类,并基于词频构建一个总的关键词集(Keywords Set),接下来把每个网站跟关键词集匹配得到网站各自的内容类型标识符(identifier)。对于未知网站通过计算其与已知网站的曼哈顿距离来进行分类。(此处没搞懂)由于已知的类型其过滤条件都已设置好,所以当对网站分类好之后就可以调用相应的过滤条件对该网站的页面进行处理了。文献[4]介绍了该技术基于W3C针对残障人士提出的网络无障碍(Web Accessibility Initiative)的指导方针而设计的内容提取的启发式规则,但是最后并没有达到预期的效果。
相关文献
[1] Suhit gupta GKDNPG. Dom Based Content Extraction ofHtml Documents [J]. In Proceedings of the 12th International Conference onWorld Wide Web, Pp., 2003: 207-214.
[2] Suhit gupta; Gail E Kaiser, Salvatore Stolfo.Automating Content Extraction of Htmldocuments [J]. World Wide Web, 2005, 8(2):179-224.
[3] Suhit gupta GEKSS. Extracting Context to ImproveAccuracy for Html Content Extraction [J]. In Special Interest Tracks and Postersof the 14th International Conference on World Wide Web, Pp., 2005: 1114-1115.
[4] Suhit gupta GK. Extracting Content From AccessibleWeb Pages [J]. Proceedings of the 2005 International Cross-disciplinaryWorkshop on Web Accessibility (w4a), 2005.
https://m.sciencenet.cn/blog-719488-812847.html
上一篇:文献阅读笔记(18)-网页信息抽取实验系统设计
下一篇:文献阅读笔记(20)-基于同层网页相似性的去噪方法