博文
现代生物研究必备的技能-(三)
 精选
精选
||||
数据分析是生物和其它任何学科都必须了解的手段,对小规模数据分析,简单的数据处理如求个均值,方差,相关性,弄个柱状图,线性图基本就可以。但随着各种高通量技术,系统生物学和各种组学的发展,大规模数据越来越多,如基因组数据库跟天书一样多,光人基因组就几十亿个碱基对。简单的统计处理已经难以得到有价值的信息,另外大规模数据的整理,储存,搜索,对比等也需要专门的平台处理,比如在人基因组中要寻找某一段特定序列,你不可能瞪眼睛一个一个地看,30亿个碱基对够你不吃不喝看两月的,我们必须利用计算机处理的优势。大规模数据涉及两个问题,一是处理数据的统计问题或数学问题,就是用什么方法处理数据,二是处理数据的编程问题,因为我们要用计算机,计算机不会说话,所以你必须把你的指令写成他能理解的语言。处理基因组这类以序列为核心的大规模数据,显微镜领域的发展也产生了大规模的图像和视频,结构生物学领域产生的大量X射线晶体结构,核磁共振结构,核磁共振收录的大量分子的的assignment信息,各种收集其它不同实验信息的文库到处都是,这些大规模数据同样需要数据处理。正是因为这些大规模数据的出现,使一部分不愿意做生物实验的人找到了一个好的入口,把别人的数据下载来,通过自己独到的算法,或者看问题独到的角度,还是能发现很多有趣的生物问题。在处理生物数据时有两个分枝,容易混淆,即生物信息学和计算生物学。前者就是用计算机,数学和工程的技术进行大规模数据处理,后者在于数据分析的理论和方法的发展,数据的模拟,预测等。比如基因组的序列比对就是生物信息学的东西,RNA-seq实验数据的处理也应该是生物信息学的东西,但比如你经典理学和量子理学为基础的对蛋白结构的预测,分子动力学的模拟等就是计算生物学,感觉后者更理论一些,前者更生物一些。单独从事生物信息和计算生物学的实验室非常多,国内现在也有很多,生物物理所的陈润生院士就是做生物信息学的,当年听过陈老师的课,也是生平头一次知道生物信息学这东西。做计算生物学的也非常多,比如上海生科院最近成立了一个计算生物学的研究所。个人感觉数学好点的做这行挺好,但像其它学科一样,不知延续性怎样,比如假设20年后随着计算机和算法的改进做生物的都可以自己处理大规模数据,因为生物口现在学生物信息和数据处理的越来越多,那这些人就要失业,有人现在即做实验又做生物信息,个人感觉更稳妥,不管什么时候单一技能的都吃亏,因为你分析的是别人的数据,如果人家不公开发表或者把数据给自己熟悉的人分析,你分析什么呢,永远别把刀把放到别人手里。
前面说过数据处理要涉及算法和编程,因此简单介绍一下这两部分,希望给生物口的学生一点帮助,如果您是学计算机,数学或统计出身,您可以自便了。计算机编程或者软件工程本身是独立学科,但对生物出身的人学一些还是非常有用的。计算机语言有很多种如R,C, C++, Java, Matlab, Visual C++, python, IDL, Labview,perl, fortran等几十种,计算机系有专门讲语言演化的课,即哪个语言在哪个的基础上发展起来,有什么改进,解决了什么问题等,是什么人什么公司推动了这个事情啊,等等。个人觉得学生物的没必要了解那么多,不用的化,学完过不了多长时间也就忘了,干脆不学省事。在基因组学领域perl, python, java应用相对广一些,比如perl和python有专门的bioperl,biopython包,里面有别人写好的很多function或者module,你可以直接调用。实际对编程的人,新手和老手一个差别就是老手会积累很多function或者moduel,遇到新的问题在原来的code基础上直接改改就可以了,当然他们debug的能力更一些。Perl对于文字为输入的数据处理更灵活,但看别人的程序不容易看懂。python应该不限于基因组学等,比如bruker公司的NMR脉冲序列就是python写的,一些显微镜图像处理软件,蛋白质结构处理软件等。在Windows操作环境下,可以下载python和Enthought Canopy,都是免费的,然后就可以编程,只要能学会一门语言,再学其它就容易多了,因为计算机语言的基本概念类似,因为最终的目标都是跟计算机交流发布命令并接受结果,不同的语言不过是殊途同归罢了。这里上传一个小的基本入门的python例子,照着做一遍,问题就不大。其实学语言越早越好,很多美国小孩十几岁就会编程,可惜我们在大学还他妈学Qbasic那种没用的东西,大学的教育改革确是不改不行,学的东西不能适应社会需求,所以毕业就失业。
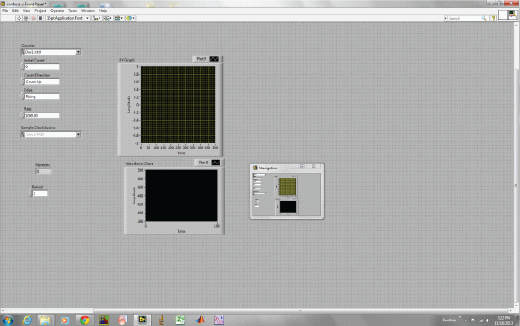
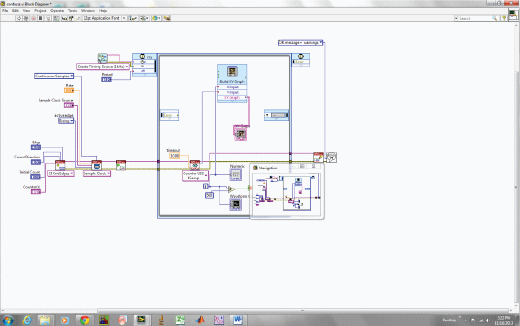
除了python,我觉得matlab也是非常强大的工具,里面有专门图像处理的软件包和信号处理软件包。很多任务如果用C语言要写上千行,matlab里面就几行,但matlab不是免费的还很贵。很多人都有盗版的,试着找找吧,我实际不鼓励盗版,但正版实在太贵,没办法,希望中国能有自己的免费且功能像matlab一样强大的东西。网上有很多别人上传的程序,以及他们的数据,多搜索看看多模仿,语言就是积累,唯熟能而,跟说话学英语一样,谁脸皮厚敢说谁学的就好,不过90后的英语都比较好,连李阳都失业开始搞传销了。这里想上传一些matlab图像处理的例子,但总是出错,可能文件太大,可以站内联系我,感兴趣的朋友可以自己重复一下。labview是做机械工程和电子工程的人经常用的来控制机器的以图像为基础的语言,其它的语言都是文字为基础,但labview是图像为基础很强大。google可以搜到一个专门讲labview编程的网络视频,可以作为入门,但真正想控制机器还需要专门的培训。因为直接的机器控制还要知道什么接口,比如是RS233接口还是USB或者PCI,机器和计算机之间的缓冲和控制的东西是什么呀,因为机器的直接输入信号如电压有可能超出电脑承受能力。labview不是免费,还很贵。下面是一个labview程序的例子,让大家对图像编程有个概念。这是一个自己搭建激光共聚焦显微镜的硬件控制程序。labview编程有几个窗口,上面那个是front panel,就像你的仪器的控制面板一样,可以加各种扭,控制键,后面的就是程序窗口(即文字编程语言如C里面说的source code, 源代码),跟计算机交流发出命令接受结果就是他,靠的就是像一个线一个连接的各种功能的网络。
我觉得对生物口的人适用的语言部分也就这么多,学一门语言,什么python, C++, java都行,这些都免费,再学点labview和matlab,这些都付费,但功能非常强大。还有一些简单的处理软件,如origin, IGOR, excel之类,这些是别人用前面提到的计算机语言写好的软件,你可以拿来用。有人会问,既然有直接的软件,为什么还要学语言,别人写的软件只针对一般问题,如果有特殊问题,比如特殊的文件格式,需要修改很多参数啊,用新算法啊,那别人的软件就不行了,所以最好自己会一门语言。用别人的软件很容易学,只要下载别人的软件,在本地电脑上安装,一般都支持windows系统,有一些是在mac系统下工作,还有一些只在linux系统下工作,但因为有很多软件,总能找到适合你的操纵系统的软件。有了软科,找几个例子,把软件上可能的钮都凄了卡叉按一篇,看看干啥用的,学习一下快捷键,就是几个键联合就能执行什么功能,看起来酷一点,比如ctrl+n(一切按control键和n键)就表示新开一个窗口啊。图像处理软件主要有imageJ,可以免费下载,没事可以玩一下,这个软件还是很强大的,一般的任务都能干,而且很多人都开发了一些插件,只要将他们拷贝到你安装后的lib文件夹内,你就可以做很多事情。比如可以去下载QuickPALM, 用他们的例子,可以看看PALM图像处理是怎么做的。对蛋白质结构分析,可以用Pymol, VVMD, chemira等免费软件,这几个学起来可能要花几天时间,chemera也很强大,是UCSF一个组写的软件,VMD是UIUC一个组写的,中国人在这领域还没有突出贡献,所以看SCI没意义,我们拿人家的软件发了几千几万的SCI,但没有一个是原创的,一提pymol,想到肯定不是中国人,虽然我们用的很多。
有了软件和编程的基础,需要了解一点算法。但这个行当深得很,想要多深有多深,因为一旦你求根溯源,源头是数学和理论物理。当然也可能我是小马过河,对高人来说是浅水,对小松鼠来说就是深不可测。自己按自己的能力和需要,适可而止,学得太多浪费时间,太少又理解不够,我只懂一点,告诉大家一些基本概念,后来的添枝接叶就靠自己了。我觉得必须的是machine learning,这里有一些大家每天在用却不知道自己在用的,比如比较两个序列或与基因数据库比对的blast,用的就是hidden markov模型,是machine learning算法中的一种。在分析单分子FRET数据的时候也需要隐性马尔科夫模型来分析分子的状态。在蛋白质结构预测领域用的最多的就是support vector machine算法,还有什么fuzzy logic,neural network, genetic annealing等等很多。斯坦福有个machine learning的网上课程,好像是个华人讲得,可以免费听,不知国内有没有被滤掉。还有图像处理领域用的贝叶斯统计,在分析蛋白质是不是有什么运输tag,分析蛋白的细胞定位的时候,有人就用naive bayes. 还有就是基本的统计概念,如各种统计分布方程,像高斯这种常见是必须知道的,还有什么像beta distribution, gamma distribution, uniform distribution, bernoulli, binomial distribution 等,对于连续分布和不连续分布的统计方程的平均值和方差的数学求法,各种验证算法,如判定分布是不是线性分布,方差是不是均一,比较两个数据的平均值和方差等。基本的统计和machine learning我觉得是生物必须的技能,具体也要根据自己的方向看看自己需要在两条路上走多远,学海无涯。
https://m.sciencenet.cn/blog-957815-742388.html
上一篇:现代生物研究必备的技能-(一)
下一篇:现代生物研究必备的技能-(四)