博文
嵌合体检测工具-UCHIME的原理解读
||||
文章:UCHIME improves sensitivity and speed of chimera detection
嵌合体产生的原因,主要是PCR的过程:The most common mechanism is incomplete template extension, when a partially extended sequence from one sequence reanneals to another parent in the next cycle of PCR. This problem is particularly acute in population studies that sequencea single region, such as the bacterial 16S ribosomal RNA gene(16S) or the fungal Internal Transcribed Spacer (ITS) region.
嵌合体的种类一般有:While chimeras with two segments (bimeras) are most common, chimeras with >2 segments (multimeras) may form at comparable rates and account for a significant fraction of the unique sequencesin an amplified sample.
嵌合体检测的工具有:CHIMERA_CHECK、Pintail、Mallard、Bellerophon、ChimeraSlayer. 各自检测的原理如下,Pintail and Mallard are 16S-specific programs that use a reference database of trusted chimera-free reference sequences. The query sequence is aligned to all(Pintail) or all pairs (Mallard) of reference sequences. Evolutionary distance is computed in a sliding window across the query sequenceand variations in distance are compared with the known ratevariability in the 16S gene, with larger variations indicating achimera. ChimeraChecker is an ITS-specific method using BLAST to search a reference database for taxonomic anomalies. ChimeraSlayer searches a multiple alignment of chimera-free reference sequences and constructs three-way alignments with candidate parents. Perseus is designed todetect chimeras in 454 pyrosequencing reads that have been filtered by the AmpliconNoise algorithm. Assuming that a chimera has undergone fewer rounds of amplification than its parents, the query is compared with all pairs of sequences having higher abundance. 方法主要分两类:基于reference database的检测,基于de novo策略的检测。
UCHIME的检测包含两种模式,UCHIME can use a trusted reference database of non-chimeric sequences (like ChimeraSlayer) and also offers a de novo mode (like Perseus).
UCHIME基于reference database的检测策略,主要原理如下图:
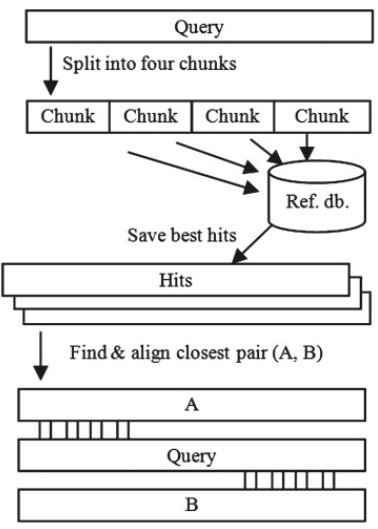
此算法主要分为以下几步,
1)The query sequence is divided into four non-overlapping segments (chunks), each of which is used to search a reference database, which is assumed to be chimera free. (将query sequence拆分成不存在overlap的chunks,然后比对数据库)
2)The best matches to each chunk are noted, and the two best candidate parents are identified from matches to all chunks. (选取每个chunk在数据库中最好的match,最终选择两条最好的parents序列)
3)A three-way multiple alignmentof the query to these two candidates is constructed.
4)If a pair of segments extracted from these two candidates has identity ≥0.8% closer to the query sequence than either candidate alone, a score is computed from the alignment and a chimera is reported if the score exceeds a predetermined threshold.
其中,UCHIME selects the best two candidates according to the following procedure,对于选择最好的parents,操作如下:A pair-wise alignment is computed between the query Q and each candidate parent P. The identity between P and Q is smoothed over a window(default size 32). For each position in Q, the highest value for the smoothed identity among the parents is recorded. The best candidate is then identifiedas the one with most positions having highest smoothed identity.
对于three-way的alignment,比对会出现local、local-X和global-X,三种情况如下:

这三种情况的操作如下:(i) searching for global-X alignments, as fewer global-X alignments usuallyexist compared with local or local-X; (ii) examining only two candidateparents; and (iii) discarding models having distance to the closest parent(divergence) <0.8%.最终会形成如下比对结果:

根据此比对结果进行score值计算,分值计算公式如下:
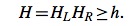 h是界限值,
h是界限值,
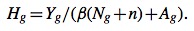 g可以表示L(left)或者R(right),Let Yg, Ng and Ag be the total numberof yes, no and abstain votes in segment g of the model.最终依据此分值去判段序列是不是嵌合体序列。
g可以表示L(left)或者R(right),Let Yg, Ng and Ag be the total numberof yes, no and abstain votes in segment g of the model.最终依据此分值去判段序列是不是嵌合体序列。
UCHIME基于de novo的检测策略,主要原理如下:sequences are considered in the order of decreasing abundance,and candidate parents must have abundance at least 2× that of the query sequence, assuming chimeras are less abundant than their parents because they undergo fewer rounds of amplification. 主要操作是Candidate parents are required to have abundance at least λ times that of the query sequence, on the assumption that a chimera has undergone fewer rounds of amplification and will therefore be less abundant than its parents. The parameter λ is called the abundance skew, and by default λ = 2,assuming at least one more round of amplification for the parents. 主要是通过量上的变化来进行检测。
UCHIME的最终检测效果如下:
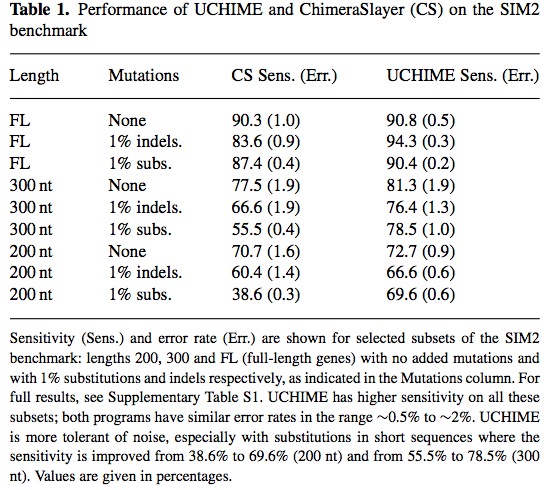
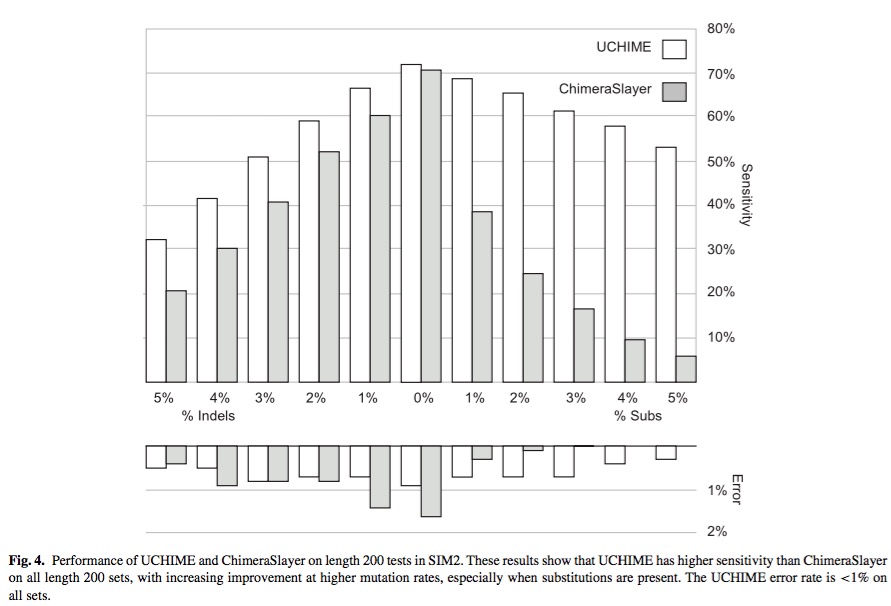
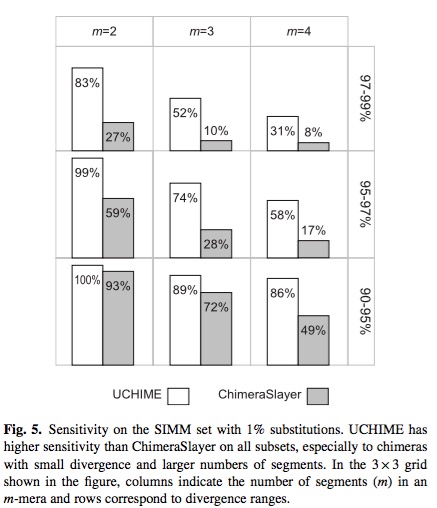
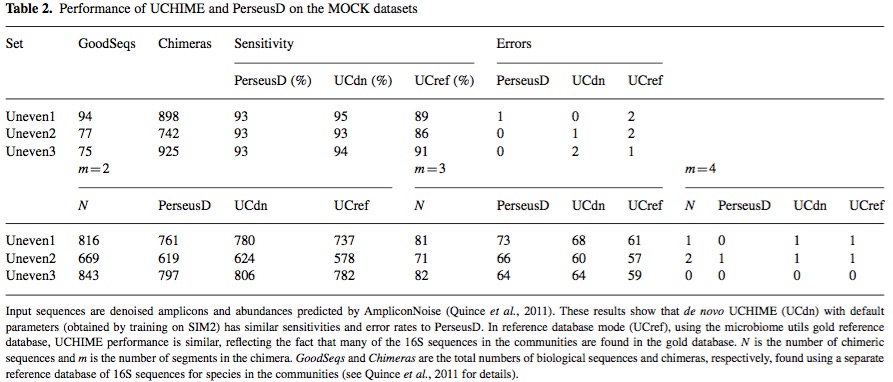

UCHIME检测的敏感性相较其他数据较好,速度更快!
参考文章:http://www.ncbi.nlm.nih.gov/pubmed/21700674
https://m.sciencenet.cn/blog-306699-945546.html
上一篇:基于NGS的产前诊断技术原理
下一篇:PICRSt:基于16s DNA进行功能注释的工具