博文
【立委科普:歧义parsing的休眠唤醒机制再探】
||||
词一级休眠的歧义被唤醒所需要的,就是词条里面给一个标签。说明该词 parse 后需要再调用一个词驱动(word-driven)系统,譬如: “难过”、“好过” 等。parsing 主线没有任何负担。“小孩很难过” 与 “小河很难过” 是同样的 parsing。但是parse完成后,在调用词驱动消歧模块的时候,这时候消灭结构歧义(所谓“唤醒”)以及wsd,这些工作的条件已经具备:既有现有parse tree 也有词node的信息。消灭歧义的个性规则不难想象,不外乎:主语如果不是人或动物,就翻盘。这是宽的条件,也可以收紧,极端一点就是:主语必须是河流或障碍类别的词,就翻盘。松紧可以根据数据去 fine tuning,达到精准与覆盖的合理平衡。
下面现场做一下“难过、好过”。没做之前是这样的,处于休眠状态:

因为 hidden ambiguity 休眠,因此 sentiment 也错了,小河也仍然是 Negative Sentiment:

好,加上对主语的限制,翻盘需要非Human或Animal,unit tests 结果就对了,就等看测试集里面有没有副作用了(估计不会有,因为这是 word driven 的休眠唤醒):
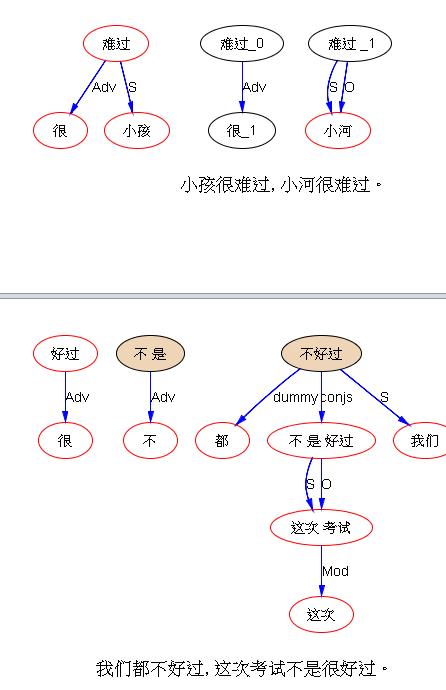
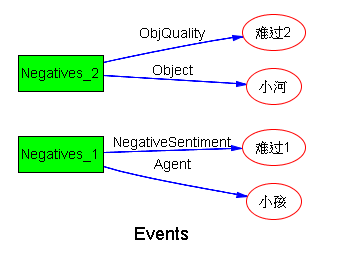
Note: sentiment analysis 中,“小河很难过” 依然是 negative 的,但是这种 negative 已经不再是情绪 (Negative Sentiment),而是客观的困境 (Negative 的 Objective Quality)。这个分析是对的,而且细致。
此前很多讨论觉得这个问题看上去无解或太复杂,是因为没有把大问题化小,没有分类别去考察和研究可行方案。如果分门别类了,其实自然语言 parsing 总体是一个可控的 tractable 的任务,基本可以见底的东西。绝大部分就是一个力气活。很多现有机制平台就可以对付的细活,没多少人有经验和耐心去做。换句话说,如果现有机制可以解决八成的问题,其他的机制包括休眠唤醒等可以帮助对付其余的两成问题,假如八成里面我们只做了四成, 那么我们平台机制无论多先进、做到极致,也还是出不了一个靠谱的 parser 出来。很多时候就是这样的情形。
【相关】
 【新智元:中文 parsing 在希望的田野上】
【新智元:中文 parsing 在希望的田野上】https://m.sciencenet.cn/blog-362400-953986.html
上一篇:《新智元笔记:找茬拷问立氏parser》
下一篇:《新智元:通用的机器人都是闹着玩的,有用的都是 domain 的》