博文
ubuntu12.04系统中Eclipse使用Hadoop调试mapReduce程序全攻略
||||
软件准备:
VMWare 10(虚拟机)
Ubuntu-12.0.4-desktop-i386.iso(32位视自己电脑配置而定)
Jdk(配置java环境)
Hadoop(2.4.0版本)
Eclipse
安装虚拟机VMWare 10
此安装和普通的软件安装没什么大的差别。
在VMWare上安装Ubuntu系统按照下面链接的安装方式即可:
http://jingyan.baidu.com/article/14bd256e0ca52ebb6d26129c.html
Ubuntu12.0.4下安装hadoop2.4.0(单机模式)一、在Ubuntu下创建hadoop组和hadoop用户增加hadoop用户组,同时在该组里增加hadoop用户,后续在涉及到hadoop操作时,我们使用该用户。
创建hadoop用户组
命令:sudoaddgroup hadoop
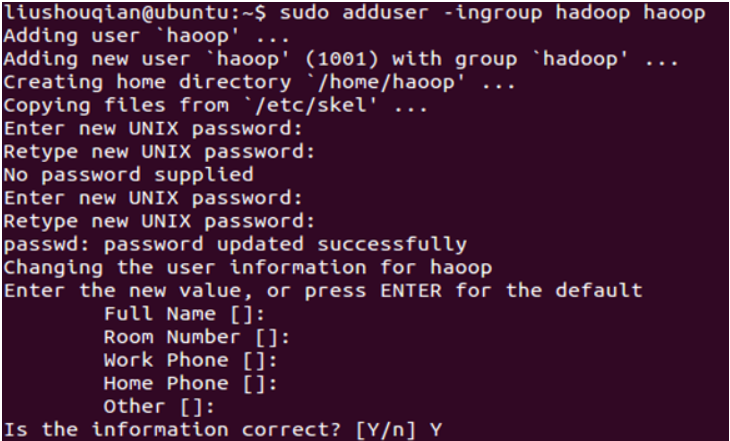
 2.创建hadoop用户
2.创建hadoop用户命令:sudo adduser -ingroup hadoop hadoop
回车后会提示输入新的UNIX密码,这是新建用户hadoop的密码,输入回车即可。
如果不输入密码,回车后会重新提示输入密码,即密码不能为空。
最后确认信息是否正确,如果没问题,输入 Y,回车即可。
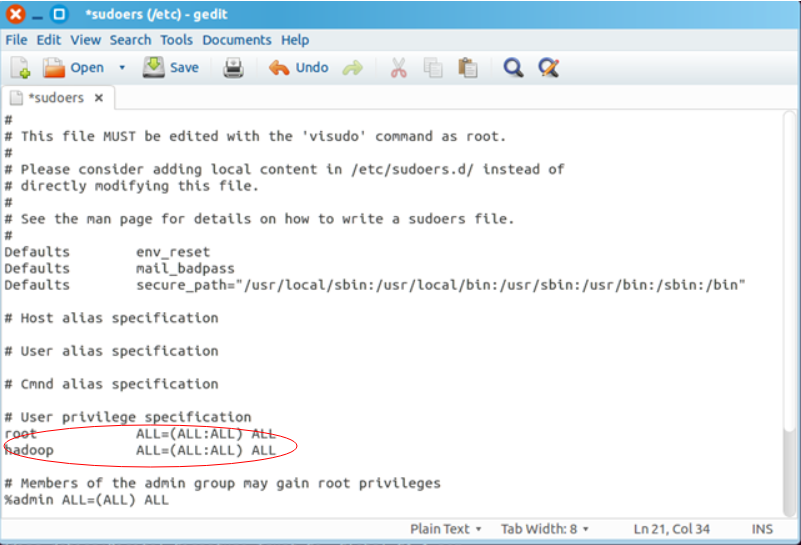
 3.为hadoop用户添加权限
3.为hadoop用户添加权限命令:sudo gedit /etc/sudogers
回车,打开此文档,给hadoop用户赋予和root用户同样的权限
文件如下:
 二、用新增的hadoop用户登陆Ubuntu系统
二、用新增的hadoop用户登陆Ubuntu系统命令:su hadoop (以后都是用这个命令切换到hadoop用户)
根据提示输入hadoop密码
三、安装ssh命令:sudo apt-getinstall openssh-server
如下图:根据提示输入Y即可

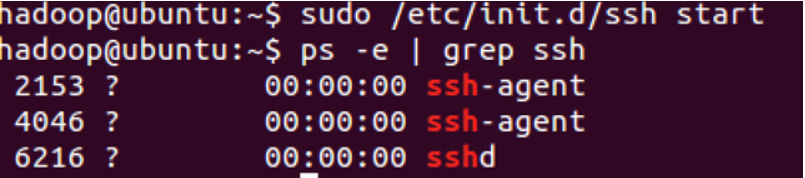
安装完成后,启动服务
命令:sudo /etc/init.d/ssh start
查看服务是否正确启动:
命令:ps-e | grep ssh
如下图:个数可能不一样,只要有就没错
设置免密码登录,生成私钥和公钥
命令:ssh-keygen-t rsa -P ""
如下图:中间要按一次enter键
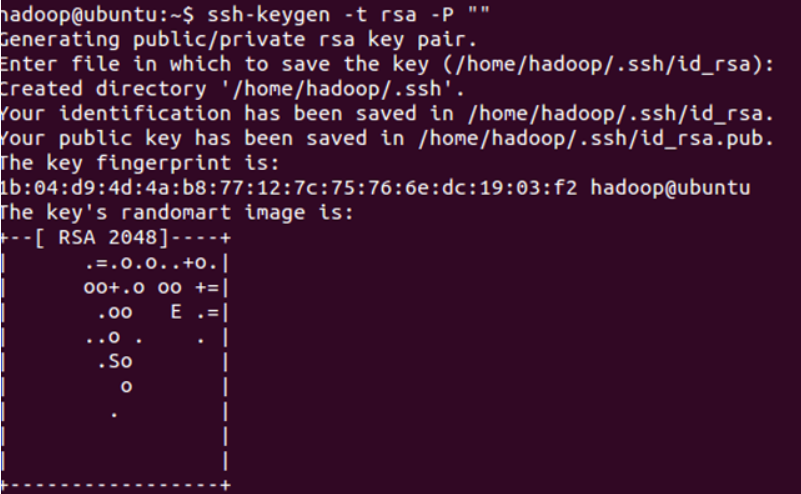
此时会在/home/hadoop/.ssh下生成两个文件:id_rsa和id_rsa.pub,前者为私钥,后者为公钥。
下面我们将公钥追加到authorized_keys中,它用户保存所有允许以当前用户身份登录到ssh客户端用户的公钥内容。
命令:cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
登录ssh
命令:ssh localhost
如下图:
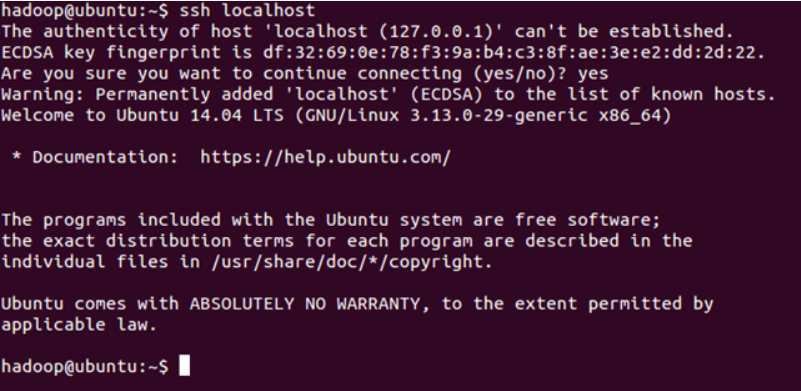
成功则退出
命令:exit
四、安装java环境
1、官网下载jdk版本 jdk-7u67-linux-i586.tar.gz(即7系列最新版本)可用Ubuntu系统直接上网下载(默认存放于/home/用户名/Downloads)
2、解压安装jdk
首先cd到Downloads目录
命令:cd /home/wzc/Downloads
找到上述文件,加压
命令:sudo tar xzf jdk-7u67-linux-i586.tar.gz
得到文件jdk-7u67-linux..
重命名为jdk
命令:sudo mvjdk-7u67-linux jdk
复制jdk到/usr/local文件夹下面
命令:sudo mv jdk/usr/local
配置环境变量:
命令:sudo gedit/etc/profile
如下:在文件末尾加入如下内容
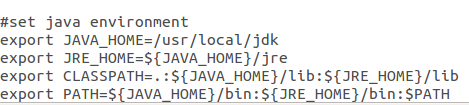
命令:source /etc/profile 让文件立即生效
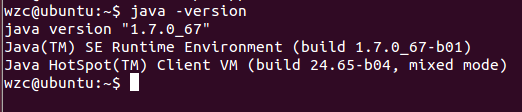
查看安装结果,输入命令:java -version,结果如下表示安装成功。
如下图:
五、安装hadoop2.4.0
官网下载软件
安装
还是cd 到Downloads目录
解压:
命令:sudo tar xzfhadoop-2.4.0.tar.gz
假如我们要把hadoop安装到/usr/local下
拷贝到/usr/local/下,文件夹为hadoop
sudomv hadoop-2.4.0 /usr/local/hadoop (以后就是hadoop文件名了)
赋予用户对该文件夹的读写权限
sudochmod 777 /usr/local/hadoop
配置
1)配置~/.bashrc 命令:sudo gedit ~/.bashrc
该命令会打开该文件的编辑窗口,在文件末尾追加下面内容,然后保存,关闭编辑窗口。
#HADOOP VARIABLES START
export JAVA_HOME=/usr/local/jdk (jdk配置地址)
export HADOOP_INSTALL=/usr/local/hadoop (hadoop安装地址)
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
exportHADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native
exportHADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib"
#HADOOPVARIABLES END
如下图:
执行命令:source ~/.bashrc 让文件生效
2)编辑/usr/local/hadoop/etc/hadoop/hadoop-env.sh
执行命令:sudo gedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh
找到JAVA_HOME变量,修改此变量如下
exportJAVA_HOME=/usr/local/jdk (即配上jdk目录)
六、WordCount测试
单机模式安装完成,下面通过执行hadoop自带实例WordCount验证是否安装成功
/usr/local/hadoop路径下创建input文件夹
mkdir input
拷贝README.txt到input
cp README.txt input
执行WordCount
bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.4.0-sources.jarorg.apache.hadoop.examples.WordCount input output
执行结果:
执行 cat output/*,查看字符统计结果

Hadoop版hello word执行成功,单机版宣告结束
在Ubuntu12.0.4下安装Hadoop2.4.0 (单机模式)基础上配置
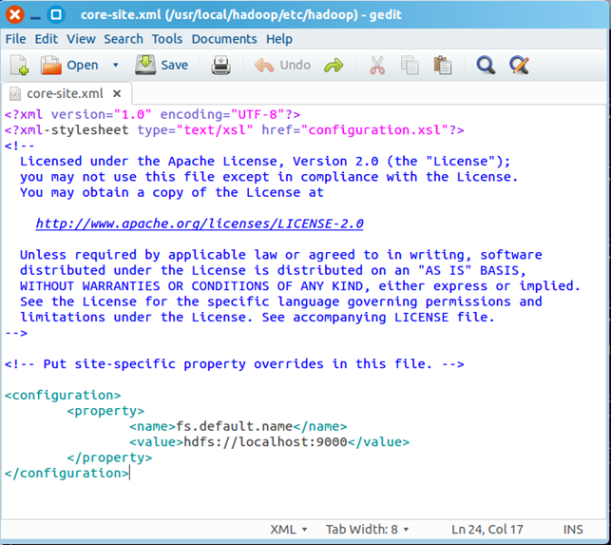
一、配置core-site.xml
/usr/local/hadoop/etc/hadoop/core-site.xml 包含了hadoop启动时的配置信息。
命令: sudogedit /usr/local/hadoop/etc/hadoop/core-site.xml

在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
保存、关闭编辑窗口。
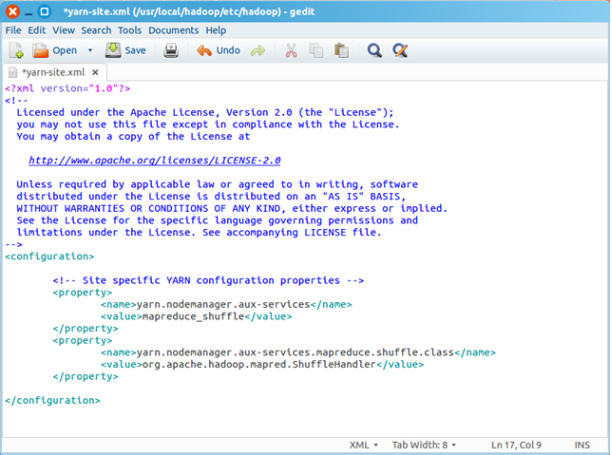
二、配置yarn-site.xml
/usr/local/hadoop/etc/hadoop/yarn-site.xml包含了MapReduce启动时的配置信息。 编辑器中打开此文件
命令:sudo gedit yarn-site.xml
在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
保存、关闭编辑窗口
最终修改后的文件内容如下
三、创建和配置mapred-site.xml
默认情况下,/usr/local/hadoop/etc/hadoop/文件夹下有mapred.xml.template文件,我们要复制该文件,并命名为mapred.xml,该文件用于指定MapReduce使用的框架。
复制并重命名
cpmapred-site.xml.template mapred-site.xml
编辑器打开此新建文件
sudogedit mapred-site.xml
在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
保存、关闭编辑窗口
最终修改后的文件内容如下

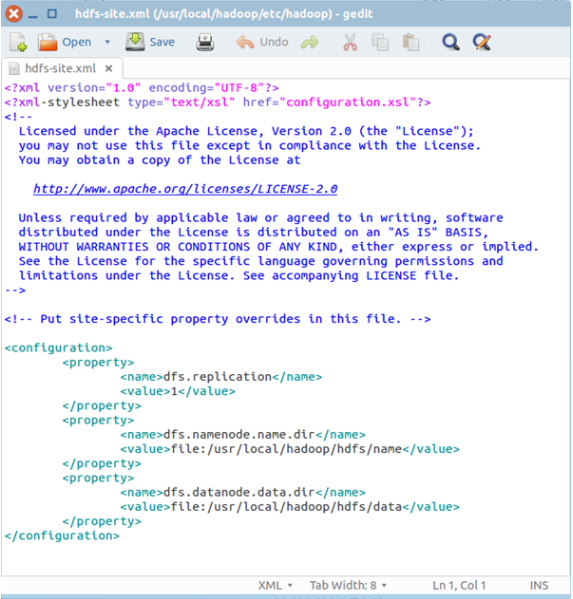
四、配置hdfs-site.xml
/usr/local/hadoop/etc/hadoop/hdfs-site.xml用来配置集群中每台主机都可用,指定主机上作为namenode和datanode的目录。
创建文件夹,如下图所示
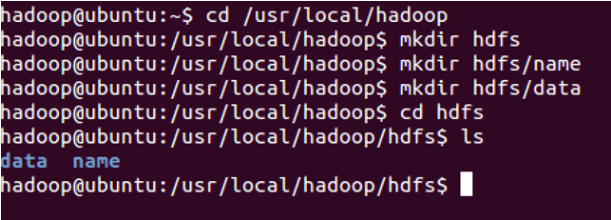
你也可以在别的路径下创建上图的文件夹,名称也可以与上图不同,但是需要和hdfs-site.xml中的配置一致。
编辑器打开hdfs-site.xml
在该文件的<configuration></configuration>之间增加如下内容:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
</property>
保存、关闭编辑窗口
最终修改后的文件内容如下:
五、格式化hdfs
hdfs namenode -format
只需要执行一次即可,如果在hadoop已经使用后再次执行,会清除掉hdfs上的所有数据。
六、启动Hadoop
经过上文所描述配置和操作后,下面就可以启动这个单节点的集群
执行启动命令:sbin/start-dfs.sh
执行该命令时,如果有yes /no提示,输入yes,回车即可。
接下来,执行: sbin/start-yarn.sh
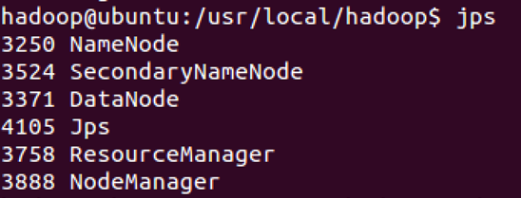
执行完这两个命令后,Hadoop会启动并运行
执行 jps命令,会看到Hadoop相关的进程,如下图:
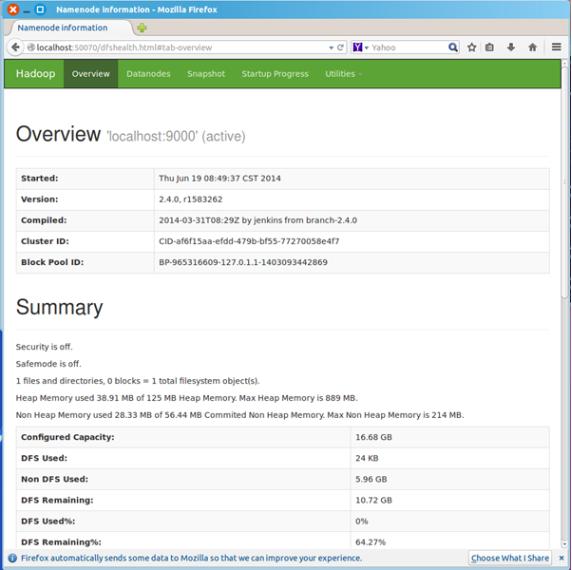
浏览器打开http://localhost:50070/,会看到hdfs管理页面
浏览器打开http://localhost:8088,会看到hadoop进程管理页面

七、WordCount验证
dfs上创建input目录
命令:bin/hadoopfs -mkdir -p input

把hadoop目录下的README.txt拷贝到dfs新建的input里
命令:hadoop fs -copyFromLocal README.txt input

运行WordCount
hadoopjar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.4.0-sources.jarorg.apache.hadoop.examples.WordCount input output

可以看到执行过程
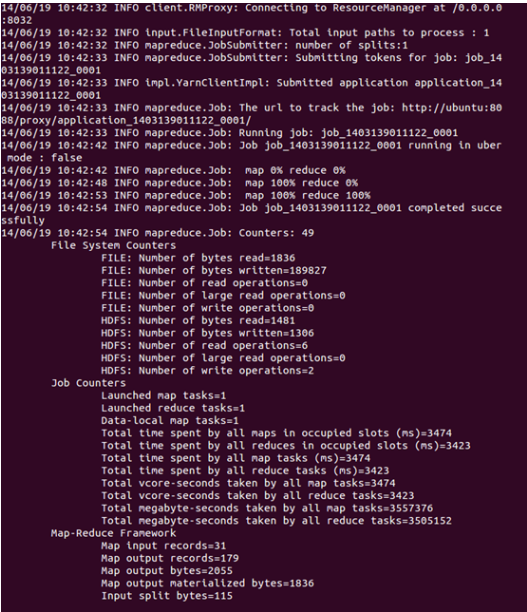
运行完毕后,查看单词统计结果
命令:hadoop fs -cat output/*
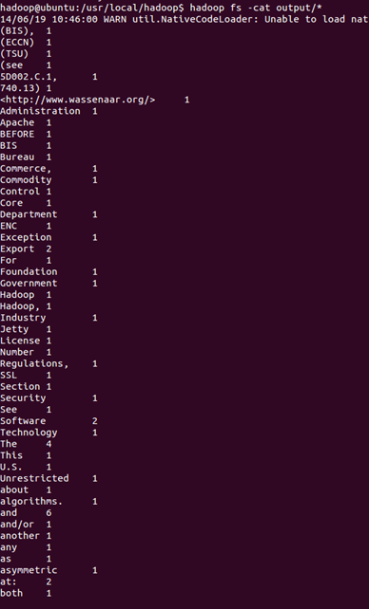
伪分布成功配置完成
类似上面,先下载,解压,然后还是复制到 /usr/local 比较妥当
二、在eclipse上安装hadoop插件
下载插件

命令:unzip/文件名
此zip文件包含了源码,我们使用使用编译好的jar即可,解压后,release文件夹中的hadoop.eclipse-kepler-plugin-2.2.0.jar就是编译好的插件。
2.将插件拷贝到Eclipse/plugins中 命令:sudomv hadoop.eclipse-kepler-plugin-2.2.0.jar /usr/local/eclipse/plugins
3、重启eclipse,命令:/usr/local/eclipse/eclipse 或cd到Eclipse然后./eclipse配置Hadoop installation directory
如果插件安装成功,打开Windows—Preferences后,在窗口左侧会有Hadoop Map/Reduce选项,点击此选项,在窗口右侧设置Hadoop安装路径。
打开Windows—OpenPerspective—Other
选择Map/Reduce,点击OK
在右下方看到如下图所示

点击Map/Reduce Location选项卡,点击右边小象图标,打开Hadoop Location配置窗口:
输入Location Name,任意名称即可.配置Map/Reduce Master和DFS Mastrer,Host和Port配置成与core-site.xml的设置一致即可。

点击"Finish"按钮,关闭窗口。
点击左侧的DFSLocations—>myhadoop(上一步配置的location name),如能看到user,表示安装成功
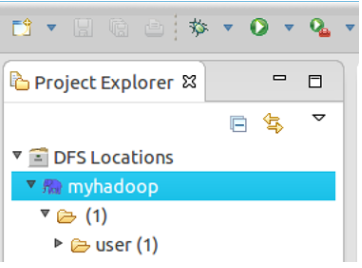
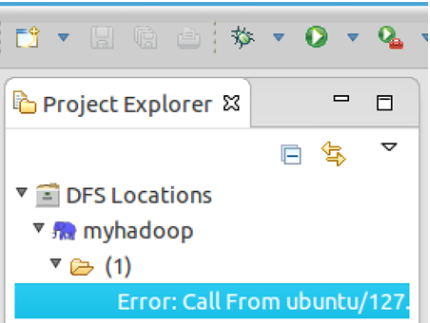
如果如下图所示表示安装失败,请检查Hadoop是否启动,以及eclipse配置是否正确。
 三、新建WordCount项目
三、新建WordCount项目File—>Project,选择Map/Reduce Project,输入项目名称WordCount等。
在WordCount项目里新建class,名称为WordCount,代码如下:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text,Text, IntWritable>{
privatefinal static IntWritable one = new IntWritable(1);
privateText word = new Text();
public voidmap(Object key, Text value, Context context) throws IOException,InterruptedException {
StringTokenizeritr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word,one);
}
}
}
public static class IntSumReducer extendsReducer<Text,IntWritable,Text,IntWritable> {
privateIntWritable result = new IntWritable();
public voidreduce(Text key, Iterable<IntWritable> values,Context context) throwsIOException, InterruptedException {
int sum =0;
for(IntWritable val : values) {
sum +=val.get();
}
result.set(sum);
context.write(key,result);
}
}
public static void main(String[] args) throws Exception {
Configurationconf = new Configuration();
String[]otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if(otherArgs.length != 2) {
System.err.println("Usage:wordcount <in> <out>");
System.exit(2);
}
Job job =new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job,new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true)? 0 : 1);
}
}
四、运行
在HDFS上创建目录input
hadoop fs -mkdir input
拷贝本地README.txt到HDFS的input里
hadoop fs -copyFromLocal/usr/local/hadoop/README.txt input
点击WordCount.java,右键,点击Run As—>Run Configurations,配置运行参数,即输入和输出文件夹
hdfs://localhost:9000/user/hadoop/inputhdfs://localhost:9000/user/hadoop/output

点击Run按钮,运行程序。
4、运行结果如下
方法1:hadoop fs -ls output
可以看到有两个输出结果,_SUCCESS和part-r-00000
执行hadoop fs -cat output/*
方法2:
展开DFS Locations,如下图所示,双击打开part-r00000查看结果
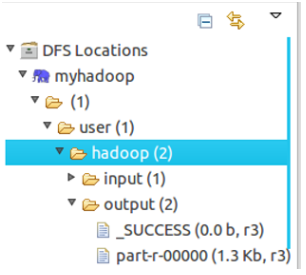
到此为止,全部配置成功。
本文参考系列博客:http://www.cnblogs.com/kinglau/p/3802705.html
附录:Hadoop常用命令启动hadoop start-all.sh
关闭hadoop stop-all.sh
查看制定目录下内容 hadoop fs –ls
打开某个已存在的文件 hadoop fs –cat input/test.txt
将本地文件复制到hdfs文件系统下 hadoop fs –copyFromLocal 本地文件夹路径 hdfs文件名 或:hadoop fs –put 本地目录 hadoop目录
将hadoop上某个文件down至本地已有目录下 hadoop fs –get hadoop文件本地目录
删除hadoop上指定的文件 hadoop fs –rm 文件
删除hadoop上指定的文件夹(包含子目录) hadoop fs –rmr 目录地址
Hadoop指定目录内创建一新目录 hadoop fs –mkdir 地址
在hadoop指定目录下新建一个空文件 hadoop fs –touchz 文件名
将hadoop上某个文件重命名 hadoop fs –mv 文件新文件名
将hadoop指定目录下所有内容保存为一个文件,同时down到本地 hadoop fs –getmerge hadoop目录本地目录
将正在运行的jobkill掉 hadoop job –kill [job-id]
查看Java进程数 jps
快捷键 ctrl+C复制、ctrl+T剪切、ctrl+P粘贴
Pwd 查看当前目录
Cd 目录 到目录下
Mkdir 路径创建目录
Rmdir 目录名从一个目录中删除一个或多个空的子目录
Tree 以树的形式显示当前目录下的文件和子目录
Touch 修改文件的存取和修改时间 (可选参数-d yyyymmdd 、-a(只把文件的存取时间改为当前时间)、-m(只把文件的修改时间改为当前时间) )
File 文件或目录查看文件类型
Cp [选项] 源文件或目录目标文件或目录 cp –r aabb 将aa目录下的文件复制到bb 下包括子目录
Rm [选项] 文件列表删除文件或目录
Mv [选项] 源文件目标文件 删除或重命名文件
Chomd [选项] 文件或目录列表 chmoda+x aa.txt 将aa.txt的权限改为所有用户都可以执行权限
Find [路径] [选项] [描述] find ./ -name s*.txt 查找名称为s*.txt的所有文件
Gzip [选项] 压缩文件名/解压缩文件名
Unzip [选项] 压缩文件名 unziptest.zip 将test.zip解压缩到当前目录下
Tar [选项] [打包文件名] 文件目录列表 tar –cvfwa.tar ./ 把当前目录中的所有文件打包到wa.tar文档中
Cat [选项] 文件名1 [文件名2]
Head [参数] 文件名 head -10readme.txt 看readme.txt中的前10行
Tail [参数] 文件名 。。。尾
More [选项] 文件名查看文件内容 enter键 q键
Less [选项] 文件名与上一致,方向键可翻页操作
Wc [选项] 文件列表得到行数字数字节数文件名
Useradd/adduser [-d home] [-sshell] [-c comment] [-m [-k template]] [-f inactive] [-e expire] [-p password][-r] username 如 useraddwzc –u 512创建新用户 然后通过passwd输入密码 其实是保存到 /etc/passwd文件中
Usermod [-l] [-L] [-U] username修改用户账户和相关信息 usermod –l wzc hadoop
Userdel [-r] wzc 删除用户
Finger username 显示账户信息
Chage username 修改用户密码时限
Who 显示当前账户
Last wzc 显示用户登陆情况
用户切换 su
Sudo 把当前用户执行的当前指令运行级别提升(一般会配套提示输入当前用户密码)
https://m.sciencenet.cn/blog-1191257-830497.html
上一篇:大数据时代,传统数据仓库面临的三个变化和两个问题
下一篇:apriori关联挖掘算法的mapreduce并行化