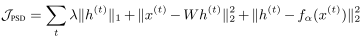此文又是Bengio大神的综述,2013年,内容更新,与09年那篇综述侧重点稍有不同,同样,需要完全读懂需要很好的基础和时间,反正我是很多地方懵懵懂懂,姑且将自己的翻译和摘取贴出来大家互相交流,如有不对的地方欢迎指正。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
1. Introduction
2. Why should we care about learning representation?
Although depth is an important part of the story, many other priors are interesting and can be conveniently captured by a learner when the learning problem is cast as one of learning a representation.
接下来几个领域的应用:
Speech Recognition and Signal Processing
Object Recognition
MNIST最近的记录:Ciresan et al. (2012) 0.27%
Rifai et al. (2011c) 0.81%
ImageNet:Krizhevsky et al.(2012) 15.3%
Natural Language Processing
Multi-Task and Transfer Learning, Domain Adaptation
3. What makes a representation good?
3.1 Priors for representation learning in AI
a. Smoothness
b. Multiple explanatory factors: 数据形成的分布是由一些隐含factors生成的
c. A hierarchical organization of explanatory factors:变量的层次结构
d. Semi-supervised learning
e. Shared factors across tasks
f. Manifolds:流形学习,主要用于AE的研究
g. Natural clustering
h. Temporal and spatial coherence
i. Sparsity
这些priors都可以用来帮助learner学习representation。
3.2 Smoothness and the Curse of Dimensionality
机器学习局部非参数学习例如核函数,它们只能获取局部泛化,假设目标函数是足够平滑的,但这不足以解决维度灾难。这些叫smoothness based learner和线性模型仍然可以用在这些学习到的表示的顶层。实际上,学习一个表示和核函数等同于学习一个核。
3.3 Distributed representations
一个one-hot表示,例如传统的聚类算法、高斯混合模型。最近邻算法、高斯SVM等的结果都需要O(N)个参数来区分O(N)个输入区域。但是像RBM、sparse coding、auto-encoder或者多层神经网络可以用O(N)个参数表示 个输入区域。它们就是分布式表示。
个输入区域。它们就是分布式表示。
3.4 Depth and abstraction
深度带来了两个明显的提高:促进特征的重复利用、潜在的获取更抽象的高层特征。
re-use:
深度回路的一个重要性质是path的数量,它会相对于深度呈指数级增长。我们可以改变每个节点的定义来改变回路的深度。典型的计算包括:weighted,sum, product, artificial neuron model,computation of a kernel, or logic gates.
Abstraction and invariance
更抽象的概念可以依靠less抽象的概念构造。例如在CNN中,通过pooling来构造这种抽象,更抽象的概念一般是对于大部分输入的局部变化具有不变性。
3.5 Disentangle factors of variation
最鲁棒的特征学习是尽可能多的解决factors,抛弃尽可能少的信息,类似降维。
3.6 What are good criteria for learning representations?
在分类中,目标很明显就是最小化错误分类,但是表示学习不一样,这是一个值得思考的问题。
4. Building deep representations
06年在特征学习方面有一个突破,中心思想就是贪婪单层非监督预训练,学习层次化的特征,每次一层,用非监督学习来学习组合之前学习的transformation。
单层训练模式也可以用于监督训练,虽然效果不如非监督训练,但比没有预训练要好。
下面几种方法组合单层网络来构成监督模型:
层叠RBM形成DBN,但是怎么去估计最大似然来优化生产模型目前还不是很清楚,一种选择是wake-sleep算法。
另一种方法是结合RBM参数到DBM中,基本上就是减半。
还有一种方法是层叠RBM或者AE形成深层自编码器,
另一种方法训练深层结构是iterative construction of a free energy function
5. Single-layer learning modules
在特征学习方面,有两条主线:一个根源于PGM,一个根源于NN。根本上这两个的区别在于每一层是描述为PGM还是computational graph,简单的说,就是隐层节点便是latent random variables还是computational nodes。RBM是在PGM这一边,AE在NN这一边。在RBM中,用score matching训练模型本质上与AE的规则化重建目标是想通的。
PCA三种解释:
a. 与PM相关,例如probabilistic PCA、factor analysis和传统的多元变量高斯分布。
b. 它本质上和线性AE相同
c. 它可以看成是线性流形学习的一种形式
但是线性特征的表达能力有限,他不能层叠老获取更抽象的表示,因为组合线性操作最后还是产生线性操作。
6. Probabilistic Models
Learning is conceived in term of estimating a set of model parameters that (locally) maximizes the likelihood of the training data with respect to the distribution over these latent variables.
6.1 Directed Graphical Models
6.1.1 Explaining away
一个事件先验独立的因素在给出了观察后变得不独立了,这样即使h是离散的,后验概率P(h|x)也变的intractable。
6.1.2 Probabilistic interpretation of PCA
6.1.3 Sparse coding
稀疏编码和PCA的区别在于包含一个惩罚来保证稀疏性。
Laplace分布(等同于L1惩罚)产生稀疏表示。与RBM和AE比较,稀疏编码中的推理包含了一个内在循环的优化也就增加了计算复杂度,稀疏编码中的编码对每一个样本是一个free variable,在那种意义上潜在的编码器是非参数的。
6.2 Undirected Graphical Models
无向图模型,也叫马尔科夫随机场(MRF),一种特殊形式叫BM,其能力方程:
6.2.1 RBM
6.3 Generalization of the RBM to real-valued data
最简单的方法是Gaussian RBM,但是
Ranzato2010给出了更好的方法来model自然图像,叫做
mean and covariance RBM(mcRBM),这是covariance RBM和GRBM的结合。还介绍了mPoT模型。
Courville2011提出了ssRBM在CIFAR-10上取得了很好的表现。
这三个模型都用来model real-valued data,隐层单元不仅编码了数据的conditional mean,还是conditional covariance。不同于训练方法,这几个的区别在于怎么encode conditional covariance。
6.4 RBM parameter estimation
6.4.1 Contrastive Divergence
6.4.2 Stochastic Maximum Likelihood(SML/PCD)
在每一步梯度更新时,不像CD算法中positive phase中gibbs sampling每次都更新,而是用前一次更新过的状态。但是当权值变大,估计的分布就有更多的峰值,gibbs chain就需要很长的时间mix。
Tieleman2009提出一种fast-weight PCD(FPCD)算法用来解决这个问题。
6.4.3 Pseudolikelihood,Ratio-matching and other Inductive Principles
Marlin2010比较了CD和SML。
7. Direct Encoding: Learning a Parametric Map from Input to Representation
7.1 Auto-Encoders
特征提取函数和重构误差函数根据应用领域不同而不同。对于无界的输入,用线性解码器和平方重构误差。对于[0,1]之间的输入,使用sigmoid函数。如果是二值输入,可以用binary cross-entropy误差。
binary cross-entropy:

线性编码和解码得到类似于PCA的subspace,当使用sigmoid非线性编码器的时候也一样,但是权值如果是tied就不同了。
如果编码器和解码器都使用sigmoid非线性函数,那么他得到类似binary RBM的特征。一个不同点在于RBM用一个单一的矩阵而AE在编码和解码使用不同的权值矩阵。在实际中AE的优势在于它定义了一个简单的tractable优化目标函数,可以用来监视进程。
7.2 Regularized Auto-encoders
传统的AE就像PCA一样,作为一种数据降维的方法,因此用的是bottleneck。而RBM和sparse coding倾向于over-complete表示,这可能导致AE太简单(直接复制输入到特征)。这就需要regularization,可以把它看成让表示对输入的变化不太敏感。
7.2.1 Sparse Auto-encoders
当直接惩罚隐层单元时,有很多变体,但没有文章比较他们哪一个更好。虽然L1 penalty看上去最自然,但很少SAE的文章用到。一个类似的规则是student-t penalty

。详见UFLDL。
7.2.2 Denoising Auto-encoders
7.2.3 Contractive Auto-encoders
Refai2011提出了CAE与DAE动机一样,也是要学习鲁棒的特征,通过加入一个analytic contractive penalty term。
令Jacobian matrix

,CAE的目标函数为:

是一个超参数控制规则强度。如果是sigmoid encoder:
三个与DAE不同的地方,也有紧密的联系,有小部分噪声的DAE可以看做是一种CAE,当惩罚项在全体重构误差上而不仅仅是encoder上。另外Refai又提出了CAE+H,加入了第三项使得

与

靠近:
注意CAE学习到的表示倾向于饱和而不是稀疏,也就是说大部分隐层单元靠近极值,它们的导数也很小。不饱和的单元很少,对输入敏感,与权值一起构成一组基表示样本的局部变化。在CAE中,权值矩阵是tied。
7.2.4 Predictive Sparse Decomposition(PSD)
PSD是sparse coding和AE的一个变种,目标函数为:
PSD可以看做是sparse coding的近似,只是多了一个约束,可以将稀疏编码近似为一个参数化的编码器。
8.Representation Learning As Manifold Learning
PCA就是一种线性流形算法。
8.1 Learning a parametric mapping based on a neighborhood graph
8.2 Learning a non-linear manifold through a coding scheme
8.3 Leveraging the modeled tangent spaces
9. Connections between probabilistic and direct encoding models
标准的概率模型框架讲训练准则分解为两个:log-likelihood  和prior
和prior 。
。
9.1 PSD:a probabilistic interpretation
PSD是一个介于概率模型和直接编码方法的表示学习算法。RBM因为在隐层单元连接的限制,也是一个交叉。但是DBM中就没有这些性质。
9.2 Regularized Auto-encoder Capture Local Statistics of the Density
规则化的AE训练准则不同于标准的似然估计因为他们需要一种prior,因此他们是data-dependent。
Bengio2012_Implicit density estimation by local moment matching to sample from auto- encoders
规则项需要学习到的表示尽可能的对输入不敏感,然而在训练集上最小化重构误差又迫使表示包含足够的信息来区分他们。
9.3 Learning Approximate Inference
9.4 Sampling Challenge
MCMC sampling在学习过程中效率很低,因为the models of the learned distribution become sharper, makeing mixing between models very slow.
9.5 Evaluating and Monitoring Performance
一般情况下我们在学习到的特征上加一层简单的分类器,但是最后的分类器可能计算量更大(例如fine-tuning一般比学习特征需要更多次数的迭代)。更重要的是这样可能给出特征的不完全的评价。
对于AE和sparse coding来说,可以用测试集上的重构误差来监视。
对于RBM和一些BM,Murray2008提出用Annealed Importance Sampling来估计partition function。RBM的另一种(Desjardins2011)是在训练中跟踪partition function,这个可以用来early stopping和减少普通AIS的计算量。
10. Global Training of Deep Models
10.1 On the Training of Deep Architectures
第一种实现就是非监督或者监督单层训练,
Erhan2010解释了为什么单层非监督预训练有帮助。这些也与对中间层表示有指导作用的算法有联系,例如Semi-supervised Embedding(
Weston2008)。
在Erhan2010中,非监督预训练的作用主要体现在regularization effect和optimization effect上。前者可以用stacked RBM或者AE实验证明。后者就很难分析因为不管底层的特征有没有用,最上面两层也可以过拟合训练集。
改变优化的数值条件对训练深层结构影响很大,例如改变初始化范围和改变非线性函数(
Glorot2010)。第一个是梯度弥散问题,这个难题促使了二阶方法的研究,特别是
Hessian-free second-order方法(
Marten2010)
。Cho2011提出了一种RBM自适应的学习速率。
Glorot2011表明了sparse rectifying units也可以影响训练和生成的表现。
Ciresan2010表明有大量标注数据,再合理的初始化和选择非线性函数,有监督的训练深层网络也可以很成功。这就加强这种假设,当有足够的标注样本时,无监督训练只是作为一种prior。
Krizhevsky2012中运用了很多技术,未来的工作希望是确定哪些元素最重要,怎么推广到别的任务中。
10.2 Joint Training of Deep Boltzmann Machines
DBM的能量方程:
DBM相当于在Boltzmann Machine的能量方程中U=0,并且V和W之间稀疏连接结构。
10.2.1 Mean-field approximate inference
因为隐层单元之间有联系,所以后验概率变得intractable,上文中用了mean-field approximation。比如一个有两层隐层的DBM,我们希望用
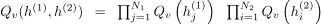
近似后验

,使得

最小。
10.2.2 Training Deep Boltzmann Machines
在训练DBM时,与训练RBM最主要的不同在于,不直接最大似然,而是选择参数来最大化lower-bound。具体见论文。
11. Building-in Invariance
11.1 Augmenting the dataset with known input deformations
11.2 Convolution and Pooling
论述这种结构与哺乳类动物的大脑在目标识别上的相同点:
Pooling的重要性:
Boureau2010:A theoretical analysis of feature pooling in vision algorithms
Boureau2011:Ask the locals:multi-way local pooling for image recognition
一个成功的pooling的变种是L2 Pooling:
Le2010:Tiled convolutional neural networks
Kavukcuoglu2009:Learning invariant features through topographic filter maps
Kavukcuoglu2010:Learning convolutional feature hierarchies for visual recognition
Patch-based Training:
(Coates and Ng, 2011):The importance of encoding versus training with sparse coding and vector quantization。
这篇文章compared several feature learners with patch-based training and reached state- of-the-art results on several classification benchmarks。
文中发现最后的结果与简单的K-means聚类方法类似,可能是因为patch本来就是低维的,例如边缘一般来说就是6*6,不需要分布式的表示。
Convolutional and tiled-convolutional training:
convolutional RBMs:
Lee,2009:Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations
Taylor,2010:Convolutional learning of spatio-temporal features
a convolutional version of sparse coding:
tiled convolutional networks:
Gregor&LeCun,2010: Emergence of complex- like cells in a temporal product network with local receptive field
Le,2010: Tiled convolutional neural networks
Alternatives to pooling: (Scattering operations)
11.3 Temporal Coherence and slow features
11.4 Algorithms to Disentanle Facotors of Variantion
这篇文章take advantage of some of the factors of variation known to exist in the data。
Erhan,2010:Understanding representations learned in deep architectures
这篇文章有实验表明DBN的第二层倾向于比第一层更具有不变性。
12. Conclusion
本文讲述了三种表示学习方法:概率模型、基于重构的算法和几何流形学习方法。
Practical Guide and Guidelines:
Hinton,2010:Practical guide to train Restricted Bolzmann Machine
Bengio,2012:Practical recommendations for gradient- based training of deep architectures
Snoek2012:Practical Bayesian Optimization of Machine Learning Algorithms