博文
新冠无症状比例问题——比较机器学习西瓜分类
||
摘要:为澄清新冠无症状比例减少问题,本文拿机器学习中典型的西瓜分类问题做比较。通过图解医学检验和西瓜分类原理,本文得出结论:新冠检测的特异性不够高以及基础概率增大是假阳性和无症状比例由大变小的主要原因。而核酸检测特异性不够高和我们为提高敏感性(为了清零)而增大CT划分点有关。最后文中提出一些改进措施。
1. 引言
我曾在科学网发表博文解释说:阳性无症状比例下降是因为检测的特异性不够高,导致感染的基础概率由小变大时,假阳性比例快速下降。假阳性当然无症状。详见:科学网—为什么现在新冠无症状比例下降那么大?——从检测特异性看 - 鲁晨光的博文 (sciencenet.cn)
现在我发现:人工智能中的二元分类(比如西瓜熟和不熟,或好和不好分类)存在同样问题;阳性无症状比例还和CT值划分点有关。
本文目的是通过比较新冠检测和西瓜分类,澄清新冠检测存在的技术问题和数学原因,并提出改进检测或分类方法,
2. 新冠检测和西瓜分类原理
周志华的《机器学习》【1】是很多人学习机器学习的入门书。其中用西瓜分类为例说明机器学习方法,由浅入深,引人入胜。我们用西瓜分类做对比解释医学检验,说明医学检验中的困难也是机器学习中的困难。
我们根据西瓜外部特征判断西瓜成熟没有,特征比如瓜皮颜色、条纹清晰度、拍打声音,瓜蒂光滑和卷曲程度等。我们用x1表示熟西瓜,x0表示生西瓜。假设特征是一维的,用z(变量)表示,划分点是z‘, 两类的名字是C0和C1,标签是y1和y0。大写X,Y,Z表示相应的随机变量。医学检验或新冠检测类似(参看图1)。
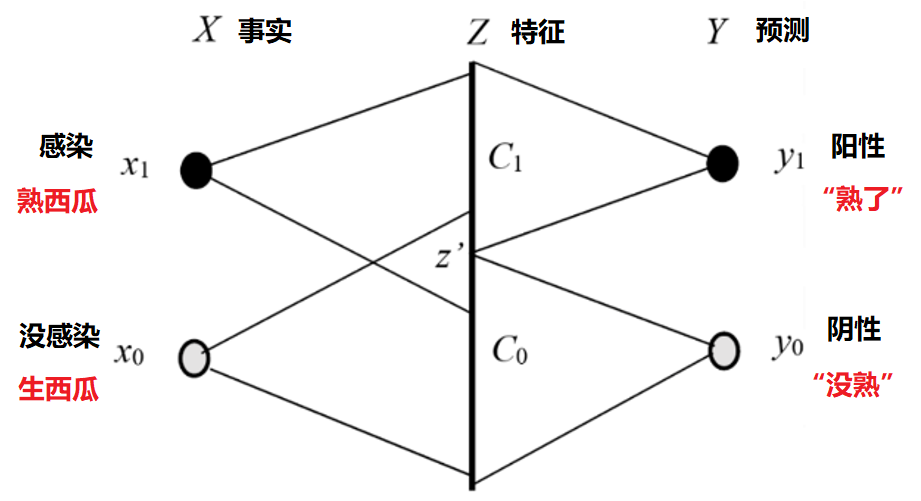
图1. 医学检验和西瓜分类(根据特征z)图解
假设西瓜成熟收获期是6月份,我们五月下旬按照同样标准(比如花纹清晰度或拍打声音)选瓜,选出来的生瓜比例一定很大。原因是,决定生瓜熟瓜的特征有很多,它们并不是严格相关的。如果我们只用一两种, 就难免会按一定的比例误判。早期熟瓜比例少时,选出不熟的瓜比例就大。而到六月下旬,生瓜熟判的比例就大大下降,相反,熟瓜生判的比例会大大增加。
医学检测是类似的。对于新冠核酸检验,特征值就是CT值。核酸检测利用聚合酶链式反应,放大扩增特定的核酸片段,完整的反应步骤称为循环。CT值是核酸扩增到检测阈值时所经历的循环数,CT值越小表示病毒数量越多。(参看:http://www.sz.gov.cn/ztfw/ylws/wyw_183957/ywzsk_184570/content/mpost_10347545.html
)。
设真的感染者和未感染者的在z(CT)上的概率分布是P(z|x1)和P(z|x0)。如图2所示。
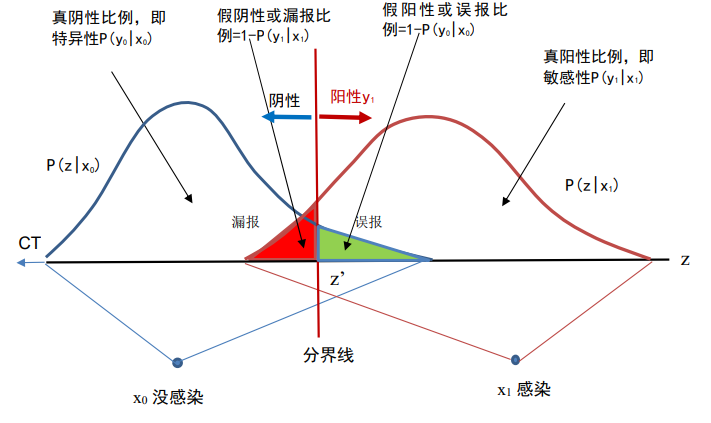
图2. 医学检验分类图解(误报和漏报不可避免)。假设基础概率P(x1)=0.5, 绿色面积和红线下面右侧部分面积之比就是假阳性和真阳性之比。
图2中其中两条曲线下面面积都是1,红色曲线下面右边部分面积是敏感性,蓝色曲线下面左边部分面积是特异性。绿色三角形就反映误报的相对比例(即假阳性比例),红色三角形面积反映漏报的相对比例。绝对比例是多少呢?那要看感染的基础概率P(x1)是多少。图3反映了基础概率很小时的情况。
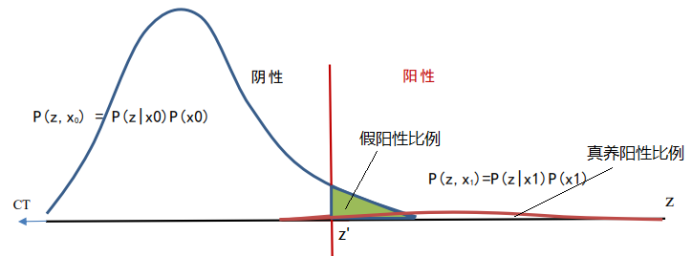
图3. 基础概率P(x1)很小时假阳性比例很大。这时两条曲线是联合概率分布,下面面积反映感染和未感然人数相对比例。绿色面积和红线右边下面面积之比就是假阳性和真阳性比例。
图3反映了中国2022年12月之前的情况,那时候大部分地区感染的基础概率P(x1)很小,所以按照同样的z’=35(循环次数)标准,假阳性比例很高。2022年年底和2023年年初,感染的基础概率增大到50%,假阳性的比例就如图2所示。这也就是为什么无症状比例下降了。其实主要原因是假阳性的比例下降了。假阳性当然无症状。
境外为什么没有报告如此高比例的无症状?因为境外基础概率大,并且没有用核酸普查。另一个原因是境外普遍用较低的CT分界点z’=30.
3. CT分界点(z’)和无症状比例的关系
新冠检测有核酸检测和抗原检测。核酸检测敏感性不高(通常只有0.6左右)特异性高(据说接近1)。抗原检测特异性和敏感性都比较高,但是也不太高(大概在0.9-0.98之间)。但是据说抗原在感染早期发现不了病毒——相当于早期敏感性很低。敏感性高就相当于不放过坏人,特异性高就相当于不冤枉好人。
为什么中国检测主要用核酸?因为当初感染比例小,用抗原冤枉好人太多,在清零政策下,导致方舱放不下。但是清零又要求不放过坏人,所以采用以下一种或几种措施:
1) 重复多次核酸检测(一次漏报0.4,两次漏报就只有0.16);
2) 提高CT值划分点(西方使用z’=30,中国开始使用z’=40,后来改为z’=35,等于图2图3中分界红线左移);
3) 用抗原辅助(比如:有症状但是核酸阴性就采用抗原捡漏,或者先用抗原从有症状人群筛选感染者,再用核酸核实)。
从图2和图3可以看出,假阳性比例大主要因为检测的特异性不高——导致绿色区域较大。专家都知道抗原特异性不够高,但是都认为核酸特异性很高,接近1. 按说核酸特异性高,假阳性比例应该很小。但是,上海曾报道核酸检测出现大量假阳性(见http://www.gov.cn/fuwu/2022-05/23/content_5691963.htm ),官方解释说是样本遭到污染。但是我以为核酸的特异性并没有大到1,即使是0.999,上海几千万人口的1/1000(被判为假阳性)也是数万人。特别是,当我们把CT值划分点定z’从0.3改为0.35或0.4时,增大敏感性的同时也降低了特异性。左移图2中垂直红线,绿色区域增大,增大部分就是特异性降低部分。
由此可见,当初无症状比例大是因为假阳性比例大,而假阳性比例大是因为CT值较大, 特异性达不到1. 而使用较大的CT值也是当初感染范围小,希望清零。
4. 二分类划界方法和准则——从西瓜分类看
(公式较多,省略,全文见:http://survivor99.com/lcg/covid-wzz.pdf )
5. 医学检验的改进方法——仿照西瓜分类
1)根据任务特殊性或损失优化分类边界z’。
西瓜分类,卖家和买家需求不同,分类标准也不同。比如卖家希望减少熟瓜生判,而买家希望减少生瓜熟判。
对于医学检验,目的不同,划分边界也应有改变。需要减少漏报(即需要不放过坏人)时,敏感性要高;希望减少误报(即希望不冤枉好人)或怕医疗资源挤兑时,特异性要高。
另外,有时候正确率重要,有时候信息重要,有时候减少损失重要。选择z’要综合考虑。
2)根据基础概率P(x)变化调整z’.
西瓜成熟早期,熟瓜比例少,成熟标准要严格一些,不然生瓜熟判的比例大。而成熟晚期,成熟的标准要松一些,不然熟瓜生判的比例大。
医学检验类似。应根据基础概率调整z’. 基础概率大可能因为被感染者比例大,也可能是因为我们选择了高危或有症状人群来检测。要想控制误报或漏报比例,划分边界也应调整(除了使用最大似然准则)。比如,基础概率小时,要想减少假阳性比例,就要降低CT的划分点z’。基础概率大时,要减少假阴性比例,就要增大z’.
3)使用多种检测手段。
同时根据西瓜外表、拍打声音和瓜蒂形状就能更可靠筛选出好瓜。因为每种特征都可能有不足之处,用每种特征淘汰一批,剩下的好瓜比例就比较大。
对于新冠检测,不妨用抗原减少漏报(因为它敏感性较高),再用核酸减少误报(因为它特异性较高),两种检测结果应该比两次重复用核酸好。当然这是假设抗原不是用在感染早期,敏感性确实高。
4)如实报告检测可靠性,让大家有合理预期。
当我们提供阳性和阴性判断时,最好同时注明基础概率和假阳性或假阴性比例,使大家对检测结果的误判有所预期。比如,当初核酸检测用CT的划分点z’=35(或者用抗原),如大海捞针发现阳性时,假阳性和无症状比例必然很高。但是这并不意味着病毒广泛传染后或基础概率增大后,假阳性和无症状比例还是这么高。如果大家对此有所预期,就不会错误地轻视病毒,以至于大面积发烧时不知所措。
6. 结束语
新冠传染早期无症状比例大,扩散期无症状比例小,这和西瓜分类类似——按照同样标准选瓜,早期不熟的比例大,中晚期不熟比例小。这是由于1)分类技术有限,减少漏报(假阴性)必然增大误报(假阳性);2)基础概率增大导致假阳性比例减小。
当初无症状或假阳性比例大,并不是有人造假。检测技术有限和清零需求是主要原因,我们为了减少漏报,提高了CT划分点z’,就必然减少检测的特异性,从而带来更多假阳性和无症状。承认检测结果可靠性有限,让大家有合理预期,将有助于应对未来疫情。
参考文献
【1】 周志华,《机器学习》,清华大学出版社,2017.
【2】 鲁晨光,Semantic Information G Theory and Logical Bayesian Inference for Machine Learning,Information 2019, 10(8), 261; https://doi.org/10.3390/info10080261; 中文:《语义信息G理论和逻辑贝叶斯推理用于机器学习》 http://www.survivor99.com/lcg/cm/gtheory/index.html
【3】 鲁晨光,Semantic Channel and Shannon Channel Mutually Match and Iterate for Tests and Estimations with Maximum Mutual Information and Maximum Likelihood,2018 IEEE International Conference on Big Data and Smart Computing (BigComp),15-17 Jan. 2018,https://ieeexplore.ieee.org/document/8367121
上面缺少第四节4节比较技术部分。全文见:http://survivor99.com/lcg/covid-wzz.pdf
https://m.sciencenet.cn/blog-2056-1371198.html
上一篇:为什么现在新冠无症状比例下降那么大?——从检测特异性看
下一篇:深度学习大牛们用我30年前提出的语义信息测度了