博文
首次发表的评论文章:《回顾学习函数和语义信息测度的进化——进而理解深度学习》
||
Entropy 是MDPI出版公司出版的一个专业期刊,汇集了全球许多对熵和信息感兴趣的作者和读者。这篇是我在Entropy上面发表的第4篇文章。这篇文章经过4位审稿人审稿 (可见编辑重视),一致同意修改发表。主要修改:更改了前两章结构;重要文献和述评集中于Introduction部分;添加了本人研究介绍和实验结果。
中文版见:回顾学习函数和语义信息测度的进化——进而理解深度学习
摘要: 最近深度学习出现了一股以互信息神经估计(MINE)和信息噪声对比估计(InforNCE)为代表的潮流。在这个潮流中,相似函数和估计互信息分别用作学习函数和目标函数。巧合的是, 估计互信息和笔者30年前提出的语义互信息在本质上完全相同。本文首先回顾了语义信息测度和学习函数的进化史, 然后简单地介绍了笔者的语义信息G理论——包括信息率-保真度函数R(G)(G表示给定的语义互信息,R(G)是信息率-失真函数R(D)的推广)——及其应用于多标签学习,最大互信息分类,和混合模型。然后,文章讨论了:从R(G)函数和G理论的角度,我们应当怎样理解语义互信息和香农互信息之间的关系、构成语义互信息的两个广义熵(模糊熵和覆盖熵)、自动编码器(AutoEncoder)、吉布斯分布(即玻尔茨曼-吉布斯分布)、划分函数…。一个重要结论是:混合模型和有限玻尔茨曼机(RBM)收敛是因为语义互信息最大化的同时香农互信息最小化,使得信息效率G/R接近1。一个潜在机会是:使用高斯信道混合模型预训练深度神经网络(DNN)的隐含层,不需要考虑梯度,从而简化学习。文章也讨论了语义信息测度作为奖励函数(反映控制结果的合目的性)用于强化学习。语义信息G理论有助于解释深度学习, 但是远远不够, 因为深度学习还涉及特征抽取和模糊推理。语义信息论和深度学习相结合应能加速双方发展。
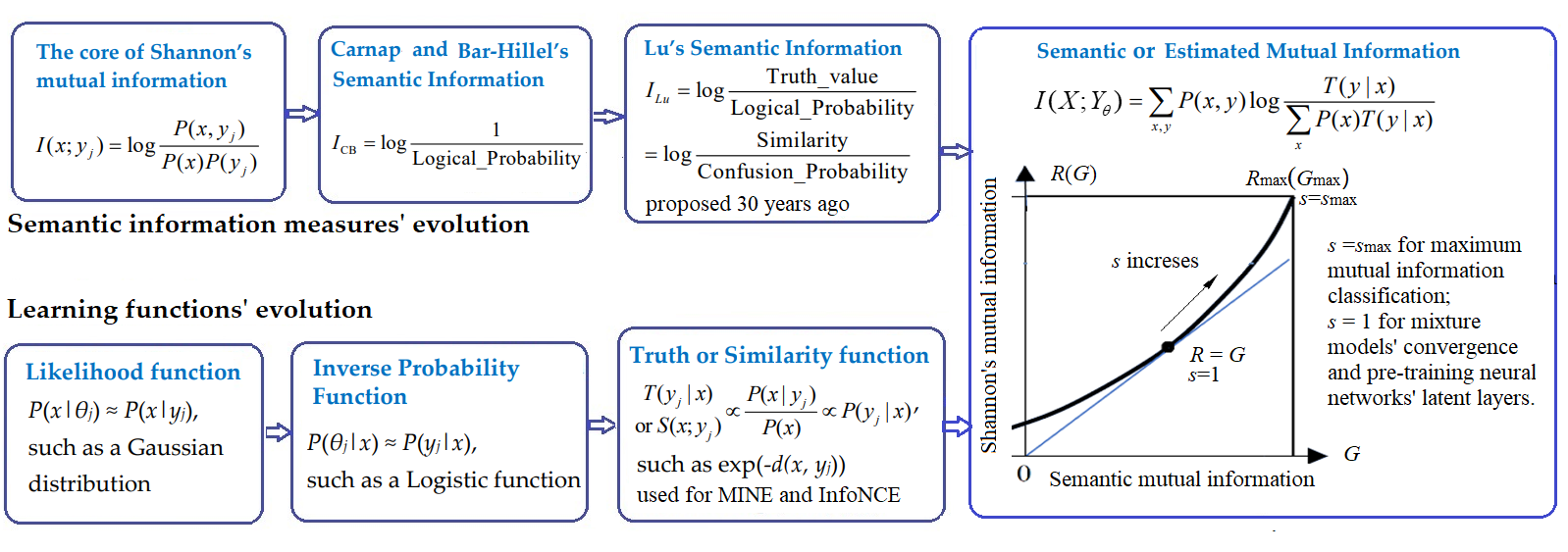
----
我相信,其中很多解释让人耳目一新。
对深度学习解释,我用R(G)函数应该好过用信息瓶颈。信息瓶颈理论只讲香农互信息,不讲估计互信息, 殊不知,深度学习最大化的是估计互信息,两者一般并不相等。有限波尔茨曼机要做的正是使两者接近。
https://m.sciencenet.cn/blog-2056-1395305.html
上一篇:语义信息论的两条路线之争——我和钟义信教授的对立统一
下一篇:根据现代科学和信息论改进反映论——一篇交流文章