ВЉЮФ
GWASЗжЮіжаЃКЮЊКЮгааЉSNPаЇгІжЕДѓШДВЛЯджјЃП
||
жЎЧАЕФGWASЗжЮіжаЃЌЮвВщПДНсЙћЪБгаЙ§етИівЩЮЪЃЌЫцзХВЛЖЯЕФбЇЯАРэНтЃЌЮввбОжЊЕРСЫЮЊЪВУДЃЌетРяНЋЮвЫМПМЕФНсЙћЗжЯэвЛЯТЁЃ
1. ДэЮѓЕФРэНт
ФГвЛИіSNPЃЌаЇгІжЕЃЈEffectЃЉдНДѓЃЌОЭдНЯджјЃПЃПЃП
ЁИЪТЪЕЩЯЃКЁЙаЇгІжЕКЭЯджјадЪЧСНТыЪТЃЁ
2. гУДњТыЫЕЛА
GWASЗжЮіжаЃЌзюМђЕЅЕФОЭЪЧвЛАуЯпадФЃаЭЃЈGLMЃЉЃЌЖјGLMФЃаЭНјааЕФGWASЗжЮіжаЃЌгУRгябдЪЕЯжЕФДњТыШчЯТЃК
mod_M7 = lm(phe.V3 ~ M7_1,data=dd)
summary(mod_M7)
ЁИНсЙћЃКЁЙ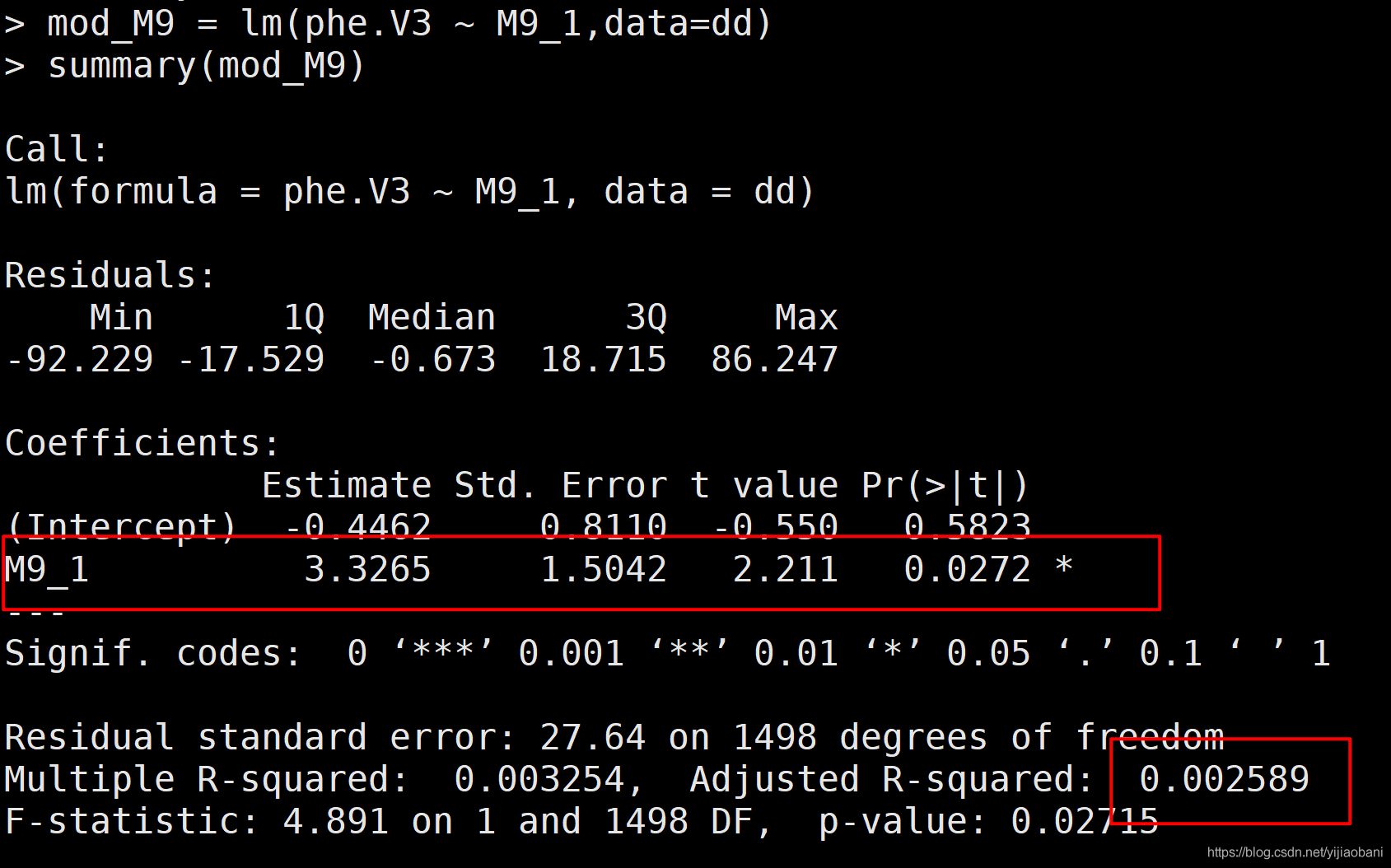 етИіРяУцЃК
етИіРяУцЃК
EstimateОЭЪЧаЇгІжЕЃК3.3265ЃЌетИіОЭЪЧSNP M9ЕФаЇгІжЕ PrОЭЪЧPжЕЃК0.0272ЃЌетИіОЭЪЧSNP M9ЕФPжЕ
ПЩвдПДЕНЃЌетСНИіЪЧСНИіжИБъЃЌЫћУЧжЎМфУЛгаБиШЛЕФСЊЯЕЁЃ
3. GWASЗжЮіЕФЫМТЗ
1ЃЌНЋSNPЕФЗжаЭзЊЛЏЮЊ 0, 1, 2ЕФаЮЪНЃЌжїаЇДПКЯЃЈmajorЃЉБрТыЮЊ0ЃЌдгКЯБрТыЮЊ1ЃЌДЮЕШЮЛДПКЯБрТыЮЊ22ЃЌxБфСПЮЊ 0,1,2ЕФЪ§жЕЃЌyБфСПЮЊадзДБэаЭжЕ3ЃЌЖдxКЭyзіЛиЙщЗжЮі y ~ a*x + bЃЌaЮЊаЇгІжЕЃЌaЪЧЗёЯджјЕФPжЕЃЌЮЊSNPЕФPжЕ
4. SNPаЇгІжЕКмДѓЃЌШДВЛЯджј
# SNP ЗжаЭ
set.seed(666)
x = rep(c(0,1,2),3)
x
# ФЃФтБэаЭжЕ
y = 12*x + rnorm(9)*10
# зїЛиЙщЗжЮі
mod = lm(y ~ x)
summary(mod)
# зїЭМ
dd = data.frame(x,y)
dd
ggplot(dd,aes(x=x,y=y)) + geom_point() + stat_smooth(method='lm',formula = y~x,colour='red')
ПДвЛЯТетИіЪ§ОнЃК
> dd
x y
1 0 7.533110
2 1 32.143547
3 2 20.448655
4 0 20.281678
5 1 -10.168745
6 2 31.583962
7 0 -13.061853
8 1 3.974804
9 2 6.077592
МЦЫуУПжжЗжаЭЖдгІЕФБэаЭЦНОљжЕЃК
> # ЦНОљжЕ
> aggregate(y~x,data = dd,mean)
x y
1 0 4.917645
2 1 8.649869
3 2 19.370070
ПЩвдПДГіЃЌЗжаЭ0ЖдгІЕФЪЧ4.9ЃЌзюаЁЃЌЗжаЭ1ЖдгІЕФЪЧ8.6ЃЌЗжаЭ2ЖдгІЕФЪЧ19.3ЃЌЧїЪЦЪЧБШНЯУїЯдЕФЁЃ
ЁИПДвЛЯТЛиЙщЗжЮіЕФНсЙћЃКЁЙ
> # зїЛиЙщЗжЮі
> mod = lm(y ~ x)
> summary(mod)
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-21.148 -12.128 2.243 13.379 21.164
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.753 8.558 0.439 0.674
x 7.226 6.629 1.090 0.312
Residual standard error: 16.24 on 7 degrees of freedom
Multiple R-squared: 0.1451, Adjusted R-squared: 0.023
F-statistic: 1.188 on 1 and 7 DF, p-value: 0.3118
ПЩвдПДГіЃЌаЇгІжЕЮЊ7.226ЃЌЕЋЪЧPжЕШДЪЧ0.312ЃЌВЛЯджјЁЃ
ЫљвдЫЕЃЌаЇгІжЕДѓЕФSNPЮЛЕуЃЌВЛвЛЖЈЪЧЯджјЕФЁЃ
ЁИЮЊКЮЛсГіЯжетжжЧщПіФиЃПЁЙЮвУЧЛвЛИіЩЂЕуЭМПДвЛЯТЗжВМЧщПіЃК
library(ggplot2)
ggplot(dd,aes(x=x,y=y)) + geom_point() + stat_smooth(method='lm',formula = y~x,colour='red')
 ПЩвдПДЕНЃЌЗжаЭЮЊ1ЕФБэаЭжЕЃЌгавЛИіЗЧГЃИпЃЌДяЕНСЫ31ЃЌЯрЕБгкдкНјаа
ПЩвдПДЕНЃЌЗжаЭЮЊ1ЕФБэаЭжЕЃЌгавЛИіЗЧГЃИпЃЌДяЕНСЫ31ЃЌЯрЕБгкдкНјааTМьбщЪБЃЌБъзМЮѓseБШНЯИпЃЌЕМжТPжЕНЯДѓЃЌВЛЯджјЁЃ
5. SNPаЇгІжЕКмаЁЃЌШДМЋЯджј
ЮвУЧЛЙФЃФтЪ§ОнЃК
# SNP ЗжаЭ
set.seed(666)
x = rep(c(0,1,2),3)
x
# ФЃФтБэаЭжЕ
y = 0.1*x + rnorm(9)*0.01
# зїЛиЙщЗжЮі
mod = lm(y ~ x)
summary(mod)
# зїЭМ
dd = data.frame(x,y)
dd
library(ggplot2)
ggplot(dd,aes(x=x,y=y)) + geom_point() + stat_smooth(method='lm',formula = y~x,colour='red')
# ЦНОљжЕ
aggregate(y~x,data = dd,mean)
ЁИФЃФтЕФЪ§ОнШчЯТЃКЁЙ
> dd
x y
1 0 0.00753311
2 1 0.12014355
3 2 0.19644866
4 0 0.02028168
5 1 0.07783126
6 2 0.20758396
7 0 -0.01306185
8 1 0.09197480
9 2 0.18207759
МЦЫуУПжжЗжаЭЖдгІЕФБэаЭЦНОљжЕЃК
> aggregate(y~x,data = dd,mean)
x y
1 0 0.004917645
2 1 0.096649869
3 2 0.195370070
ПЩвдПДЕНЃЌШ§жжЛљвђаЭЃЌНзЬнИавВКмЧПЁЃ
ЁИЛиЙщЗжЮіНсЙћЃКЁЙ
> # зїЛиЙщЗжЮі
> mod = lm(y ~ x)
> summary(mod)
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-0.021148 -0.012128 0.002243 0.013379 0.021164
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.003753 0.008558 0.439 0.674
x 0.095226 0.006629 14.365 1.89e-06 ***
---
Signif. codes: 0 ЁЎ***ЁЏ 0.001 ЁЎ**ЁЏ 0.01 ЁЎ*ЁЏ 0.05 ЁЎ.ЁЏ 0.1 ЁЎ ЁЏ 1
Residual standard error: 0.01624 on 7 degrees of freedom
Multiple R-squared: 0.9672, Adjusted R-squared: 0.9625
F-statistic: 206.4 on 1 and 7 DF, p-value: 1.886e-06
ПЩвдПДГіЃК SNPЕФаЇгІжЕЃК0.095 SNPЕФPжЕЃК1.89e-6ЃЈДяЕНМЋЯджјЫЎЦНЃЉ
ЁИзїЭМПДвЛЯТЃКЁЙ ЫфШЛЛиЙщЯЕЪ§ЃЈSNPаЇгІжЕКмаЁЃЉЃЌЕЋЪЧУПИіЗжаЭЖдгІЕФБэаЭжЕЯрВюВЛЖрЃЌзщФкБфвьЃЈЭЌвЛжжЛљвђаЭЕФБэаЭжЕЃЉдЖдЖаЁгкзщМфБфвьЃЈВЛЭЌSNPЗжаЭЖдгІЕФБэаЭжЕЃЉЃЌЕМжТНјаа
ЫфШЛЛиЙщЯЕЪ§ЃЈSNPаЇгІжЕКмаЁЃЉЃЌЕЋЪЧУПИіЗжаЭЖдгІЕФБэаЭжЕЯрВюВЛЖрЃЌзщФкБфвьЃЈЭЌвЛжжЛљвђаЭЕФБэаЭжЕЃЉдЖдЖаЁгкзщМфБфвьЃЈВЛЭЌSNPЗжаЭЖдгІЕФБэаЭжЕЃЉЃЌЕМжТНјааTМьбщЪБЃЌДяЕНМЋЯджјЫЎЦНЁЃ
етвВОЭГіЯжСЫSNPЕФаЇгІжЕКмЕЭЃЌЕЋЪЧШДДяЕНСЫМЋЯджјЫЎЦНЁЃ
6. ДгЩњЮябЇЫЎЦНШчКЮНтЪЭЃП
ПЩвдетбљРэНтЃЌЁИSNPаЇгІжЕаЁЕЋЯджјЕФЮЛЕуЃКЁЙЪєгкЖдБэаЭжЕЪЧгажБНггАЯьЕФЃЌЕЋЪЧгАЯьЕФаЇгІНЯаЁЃЌЕЋЪЧБШНЯЮШЖЈЃЌЫљвдВХБэЯжГіМЋЯджјЃЌЖјаЇгІаЁ
ЁИSNPаЇгІДѓЕЋВЛЯджјЕФЮЛЕуЃКЁЙгаПЩФмSNPЪЧгаДѓаЇгІЕФЃЌЕЋЪЧШнвзЪмЕНЛЗОГгАЯьЃЌЛђепгЩгкШКЬхЕФНсЙЙЃЈФГИіШКЬхФкОлМЏЃЉЃЌЛђепгЩгкФГаЉвьГЃжЕЕМжТетжжЧщПіЁЃвВгаПЩФмБОЩэОЭЪЧВЛЯджјЕФЁЃ
ЁИСжзгДѓСЫЃЌЪВУДФёЖМгаЃЁЁЙБЯОЙSNPЖМЪЧЩЯЭђЃЌЩЯЪЎЭђЃЌЩЯАйЭђЕФСПЁЃЖјБэаЭжЕЖМЪЧЩЯАйЃЌЩЯЧЇЃЌКмЩйДяЕНЩЯЭђЕФЃЌетОЭДцдкКмЖржжЧщПіЃЌЕМжТгааЉSNPаЇгІжЕКмДѓЃЌЕЋЪЧВЛЯджјЃЌгааЉSNPаЇгІжЕКмаЁЃЌЕЋЪЧМЋЯджјЁЃетРяашвЊЧјЗжЖдД§вЛЯТЁЃ
ШчЙћгаКмЖрSNPГіЯжетжжЧщПіЃЌБиШЛгаб§ЃЌВщПДЪЧЗёЙ§ТЫСЫmafЃЌЪЧЗёЖдЛљвђаЭНјааСЫЬюГфЃЌЪЧЗёБэаЭЪ§ОнгавьГЃЃЌШчЙћЖММьВщЙ§СЫЃЌГіЯжетжжЧщПіЃЌЮвУЧвВжЛФмЫЕЃКit happensЃЌгаЪБКђЛсГіЯжЃЌетВЛЪЧВЛПЩНтЪЭЕФЯжЯѓЃЌЗёепЮваДетЦЊЮФеТЕФвтвхдкФФРяФиЃПГ§СЫЙрЫЎЃЌЛЙгаьХММАЁ
7. GWASЯЕСаЯрЙи
БЪМЧ | GWAS ВйзїСїГЬ1ЃКЯТдиЪ§Он
БЪМЧ GWAS ВйзїСїГЬ2-1ЃКШБЪЇжЪПи
БЪМЧ | GWAS ВйзїСїГЬ2-2ЃКадБ№жЪПи
БЪМЧ GWAS ВйзїСїГЬ2-3ЃКзюаЁЕШЮЛЛљвђЦЕТЪ
БЪМЧ GWAS ВйзїСїГЬ2-4ЃКЙўЮТЦНКтМьбщ
БЪМЧ GWAS ВйзїСїГЬ2-5ЃКдгКЯТЪМьбщ
БЪМЧ GWAS ВйзїСїГЬ2-6ЃКШЅЕєЧздЕЙиЯЕНќЕФИіЬх
БЪМЧ GWAS ВйзїСїГЬ3ЃКplinkЙиСЊЗжЮі
БЪМЧ | GWAS ВйзїСїГЬ4-1ЃКLMФЃаЭassoc
БЪМЧ | GWAS ВйзїСїГЬ4-2ЃКLMФЃаЭlinear+Ъ§жЕаБфСП
БЪМЧ | GWAS ВйзїСїГЬ4-3ЃКLMФЃаЭ+вђзгаБфСП
БЪМЧ | GWAS ВйзїСїГЬ4-4ЃКLMФЃаЭ+Ъ§жЕ+вђзгаБфСП
БЪМЧ | GWAS ВйзїСїГЬ4-5ЃКLMФЃаЭ+Ъ§жЕ+вђзг+PCAаБфСП
https://m.sciencenet.cn/blog-2577109-1250860.html
ЩЯвЛЦЊЃКRгябдМЦЫугёУзВтНЛЪдбщЕФХфКЯСІ
ЯТвЛЦЊЃКRгябдtryCatchЪЙгУЗНЗЈЃКХаЖЯWarningКЭError