博文
多Agent深度强化学习综述
|
引用本文
梁星星, 冯旸赫, 马扬, 程光权, 黄金才, 王琦, 周玉珍, 刘忠.多Agent深度强化学习综述.自动化学报, 2020, 46(12): 2537−2557 doi: 10.16383/j.aas.c180372
Liang Xing-Xing, Feng Yang-He, Ma Yang, Cheng Guang-Quan, Huang Jin-Cai, Wang Qi, Zhou Yu-Zhen, Liu Zhong. Deep multi-agent reinforcement learning: a survey. Acta Automatica Sinica, 2020, 46(12): 2537−2557 doi: 10.16383/j.aas.c180372
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c180372
关键词
多Agent系统,深度学习,深度强化学习,通用人工智能
摘要
近年来, 深度强化学习(Deep reinforcement learning, DRL)在诸多复杂序贯决策问题中取得巨大突破.由于融合了深度学习强大的表征能力和强化学习有效的策略搜索能力, 深度强化学习已经成为实现人工智能颇有前景的学习范式.然而, 深度强化学习在多Agent系统的研究与应用中, 仍存在诸多困难和挑战, 以StarCraft Ⅱ为代表的部分观测环境下的多Agent学习仍然很难达到理想效果.本文简要介绍了深度Q网络、深度策略梯度算法等为代表的深度强化学习算法和相关技术.同时, 从多Agent深度强化学习中通信过程的角度对现有的多Agent深度强化学习算法进行归纳, 将其归纳为全通信集中决策、全通信自主决策、欠通信自主决策3种主流形式.从训练架构、样本增强、鲁棒性以及对手建模等方面探讨了多Agent深度强化学习中的一些关键问题, 并分析了多Agent深度强化学习的研究热点和发展前景.
文章导读
强化学习(Reinforcement learning, RL)是机器学习的一个子领域, 学习如何将场景(环境状态)映射到动作的策略, 以获取能够反映任务目标的最大数值型奖赏信号, 即在给定的环境状态下, 决策选择何种动作去改变环境, 使得获得的收益最大[1].同监督式的机器学习过程不同, 在强化学习过程中Agent1不被告知应该采用哪个动作, 而是通过不断与环境交互, 从而试错学习到当前任务最优或较优的策略.这一学习范式能够有效地解决在自然科学、社会科学以及工程应用等领域中存在的序贯决策问题.在强化学习的发展历史中, 强化学习和神经网络的结合已有较长的历史[2], 但是在复杂序列决策问题中始终没有显著的突破.然而, 随着深度学习(Deep learning, DL)在复杂数据驱动任务中展现出的卓越性能[3-4], 一种融合了深度学习强大的特征表示能力和强化学习高效策略搜索能力的学习范式—深度强化学习(Deep reinforcement learning, DRL)逐渐引起学者的广泛关注, DRL是将DL引入到RL, 将深度神经网络引入到RL的值函数、策略函数或者环境模型的参数估计中. DRL在游戏、机器人、自然语言处理等问题中, 取得了令人瞩目的成果[5-12]. AlphaGo的主要贡献者David Silver更是将现代人工智能定义为RL + DL[13], 即DRL才是人工智能的理想范式[14].赵冬斌等[7]认为人工智能将会是各国竞相争夺的下一科技高地.
1Agent:是学习者和决策者, 能够获取自身之外的环境信息, 采用学习算法, 对环境变化做出合适响应.
伴随着DRL在一些复杂单Agent任务中的有效应用, 人们又将DRL的研究成果转移到了多Agent系统(Multi-agent system, MAS)的应用中, 以期获得同样的突破. MAS由一组利用传感器感知共享环境的自治、交互的Agent组成, 每个Agent独立地感知环境, 根据个人目标采取行动, 进而改变环境[15].在现实世界中, 存在许多MAS的实例, 例如资源调度管理[16]、拥塞处理[17-19]、通信传输[20]、自动驾驶[21]、集群规划[22-25]等.
多Agent DRL (Multi-agent DRL, MADRL)是DRL在MAS中应用的研究分支, 理论基础源于DRL.虽然将DRL应用于MAS中有着许多研究, 但据我们所知, 尚没有关于多Agent DRL研究的综述性报告, 赵冬斌等[7]对DRL以及围棋的发展进行了综述, 但其出发点、综述角度以及内容安排与本文有较大不同, 如表 1所示.本文在对近些年国内外的研究现状进行分析与研究后, 从MADRL设计与实践的角度出发, 对这一领域进行归纳总结.
本文首先对DRL进行基本的介绍, 从策略表现的角度对当前DRL的两个主要方向, 即深度Q网络和深度策略梯度的发展进行了描述.在第2节, 我们首先分析了DRL与MAS的关系, 描述了DRL与MAS结合的优势与挑战; 同时我们利用部分可观测的马尔科夫决策过程对MADRL问题进行了模型设计, 用以表达MAS的数学过程; 之后, 根据当前DRL的实现结构以及多Agent在DRL实现中通信过程的发生阶段, 将现有MADRL划分为全通信集中决策、全通信自主决策以及欠通信自主决策等三类, 对每类决策架构的当前研究现状进行讨论分析, 对面向多Agent学习的开放训练平台进行介绍; 在第3节, 针对现有MADRL仍面临的一些关键问题, 从MADRL的学习训练框架、样本增强、鲁棒性研究以及对手建模等方面进行研究, 提出了当前MADRL可能发展的方向; 在第4节, 对全文进行总结.

图 1 MDP示意图
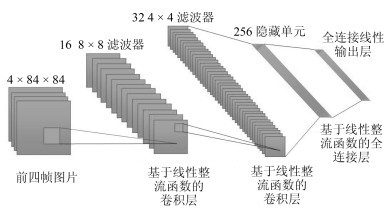
图 2 DQN架构

图 3 A3C框架
尽管DRL在一些单Agent复杂序列决策任务中取得了卓越的效果, 但多Agent环境下的学习任务中任然面临诸多挑战, 另一方面, 人类社会中很多问题都可以抽象为复杂MAS问题, 所以, 在这个领域需要进一步地深入探索.现有多Agent学习综述多同博弈论关联, 但伴随着DRL的产生与发展, 国内外尚没有一份关于MADRL的综述.我们通过总结近些年深度强化学习以及多Agent深度强化学习方面的论文, 从训练架构以及实现技巧方面着手, 撰写此文. MADRL是DRL在多Agent领域的扩展.本文首先对强化学习的基本方法以及DRL的主要方法进行了介绍与分析; 在此基础上, 从通信和决策架构方面对MADRL进行分类, 抽象为全通信集中决策、全通信自主决策、欠通信自主决策三类, 并对一些开放的多Agent训练环境进行了简要介绍; 然后, 对多Agent深度强化学习中需要用到的实用技术进行了分析与讨论, 包含多Agent训练框架、样本增强、鲁棒性以及对手建模等一些关键问题, 并根据对这些关键问题的认识, 给出MADRL领域的发展展望, 对仍待研究的问题进行了探讨.
随着深度强化学习的继续发展, 在MAS中的应用以及研究也将越来越广泛, 但其训练和执行方式也将属于这3种形式之一.我们的研究旨在对当前的MADRL研究现状进行整理与归纳, 为希望将DRL应用于MAS的学者或机构提供一份可供参考的概览.
作者简介
梁星星
国防科技大学系统工程学院博士研究生. 2014年获得国防科学技术大学学士学位. 2016年获得国防科学技术大学管理科学与工程硕士学位.主要研究方向为深度强化学习, 多Agent智能规划, 多Agent深度强化学习. E-mail: doublestar_l@163.com
马扬
国防科技大学系统工程学院博士研究生. 2014年获得国防科学技术大学学士学位. 2016年获得国防科学技术大学管理科学与工程硕士学位.主要研究方向为网络嵌入, 链路预测. E-mail: yang_ma_cn@163.com
程光权
国防科技大学系统工程学院副教授.主要研究方向为链路预测. E-mail: cgq299@163.com
黄金才
国防科技大学系统工程学院教授.主要研究方向为智能调度与控制. E-mail: huangjincai@nudt.edu.cn
王琦
国防科技大学系统工程学院博士研究生. 2015年获得四川大学基础数学系学士学位. 2017年获得国防科学技术大学管理科学与工程硕士学位.主要研究方向为不确定决策, 智能调度与控制, 复杂系统建模. E-mail: wangqi15@nudt.edu.cn
周玉珍
国防科技大学系统工程学院博士研究生. 2014年获得安阳师范学院数学与应用数学学士学位. 2017年获得郑州大学计算数学硕士学位.主要研究方向为交通, 物流, 偏微分方程的数值解. E-mail: yuzhen_zyz@163.com
刘忠
国防科技大学系统工程学院教授.主要研究方向为智能规划与决策, 深度强化学习和多智能体系统. E-mail: liuzhong@nudt.edu.cn
冯旸赫
国防科技大学系统工程学院副教授.获得国防科技大学硕士学位和博士学位.博士期间研究关注于构建“在线规划与离线学习”架构, 辅助计算机分析, 认知和预测真实世界的不确定性.曾任爱荷华大学访问学者与助理教授.主要研究方向为因果发现与推理, 主动学习和强化学习.本文通信作者. E-mail: fengyanghe@nudt.edu.cn
https://m.sciencenet.cn/blog-3291369-1368138.html
上一篇:基于T-S模糊模型的采样系统鲁棒耗散控制
下一篇:面向全量测点耦合结构分析与估计的工业过程监测方法