博文
什么?新冠病毒可能不是自然形成之物?!
||
一、印度学者的惊悚发现
几位友人询问我,有没有可能新冠状病毒2019-nCoV是通过基因工程技术(或者说生物技术)而被人为创造出来的?毕竟现代生物技术,尤其是合成生物学技术已经在这方面初现端倪了。更何况,2020年1月31日,印度理工学院和德里大学的学者在著名的美国冷泉港实验室举办的bioRxiv网站发布论文,爆出了一个惊天大发现:肆虐武汉及世界多国的新冠状病毒2019-nCoV不太可能是自然形成之物!详见论文链接:https://www.biorxiv.org/content/10.1101/2020.01.30.927871v1。换言之,新冠病毒有可能是人造之物。
仅看论文的标题就已经够惊悚的了。该论文的标题是“Uncanny similarity of unique inserts in the 2019-nCoV spike protein to HIV-1 gp120 and Gag”,翻译过来就是:2019-nCoV病毒棘突蛋白上存在的一些奇特的插入片段与HIV-1 的gp120 及 Gag蛋白之间存在着神秘的相似性。

论文摘要的截图
论文大致结论是:作者发现新冠病毒2019-nCoV和艾滋病病毒HIV-1具有4个类似的基因片段(插入片段),而这些基因片段从未被发现于任何其他冠状病毒,包括在蝙蝠中发现的、与本次新冠病毒相似度最高的冠状病毒。作者进一步指出:这些插入片段对应的氨基酸残基序列都与HIV-1关键结构蛋白中的氨基酸残基序列相同或相似。值得注意的是,所有4个插入片段的pI值均不低于10,第四个插入片段的pI值甚至达到了12以上,使得这四个插入片段带有较强的正电荷而有助于病毒与宿主的相互作用。3D建模显示,尽管这些插入片段在蛋白质的一级结构序列(也就是蛋白质中氨基酸的线性排列次序)中并不是连续的,但他们却在立体空间结构中正好聚集在一起而形成新冠病毒的受体结合位点!这种不可思议的相似性不太可能是在自然界偶然发生,所有这些研究结果都强烈地暗示着新型冠状病毒可能诞生于人为设计的基因改造!

人民网强国论坛甚至有网友发帖坚称“不是谣言”
这个发现可不得了,不妨发挥一下想象力:如果论文结果为真,新冠病毒会不会是生化武器研究的产物?这次疫情是生化恐怖袭击吗?亦或是某位失意或者变态的生化怪杰为报复社会的故意制造的恐怖病毒?
二、扒一扒事实真相
等一下、等一下,先冷静下来,让我们仔细阅读一下原文,看看还能不能读出一些新东西。
1、网站上的黄色警示语
注意到bioRxiv网站上文章首页有一个用黄色背景标示的提示框了吗?想想看,自然界中有许许多多有毒有害的生物,它们都用这些醒目的黄颜色做什么?警告,对啦,是警告!这里用这个颜色同样也是这个意思。
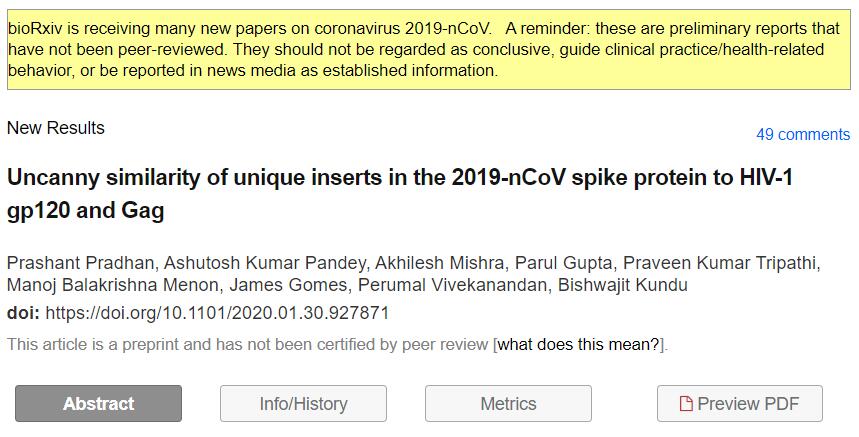
看到了截图中黄色的提示框了吗?
提示框中的内容是:bioRxiv近段时间接收了大量冠状病毒2019-nCoV的许多新论文。提醒:这些是未经同行评审的初步报告。它们不应被视为结论性的、指导临床实践/健康相关行为的,或作为既定信息在新闻媒体上报道。
文章标题doi链接的下方同样有一行提示:This article is a preprint and has not been certified by peer review (本文为预印本,未经同行评审认证)。什么是未经同行评审认证的“预印本”?就是说它的内容并没有得到同行专家的认可,是不能作为结论的!
看到没?网站已经为可能的风险甩锅了!
2、再看论文的写作结构
乍一看还真与正经学术论文并无二致。文章的标题、作者及作者单位、联系方式等等应该还好,基本找不出大毛病。但我并没有无聊地验证通讯作者Prashant Pradhan的联系方式,只是登陆到University of Delhi的Acharya Narendra Dev College网站,想浏览一下通讯作者的基本情况。然而,除了在Faculty中能看到通讯作者的名字,网站并没有提供有关Prashant Pradhan的详细资料,就连他的title (称号)也只是个可怜巴巴的Mr.(先生)。难道通讯作者连Dr.(博士)都不是?
好吧,也许学术大佬不屑于自我标榜吧。
文章大致分摘要、引言、方法学、结果、讨论、结论和文献等七个部分,看似比较符合学术八股文的套路。
再读读文章看。首先是摘要。摘要是学术论文的脸面,一般读者都是通过标题或关键词等索引到文章后就会首先阅读摘要部分,看看有没有自己感兴趣或对自己的研究有帮助的内容。先不谈摘要的写作是否符合普通学术论文的摘要特点,单就摘要用词就感觉比较有特点:比较文艺。
嗯嗯,也许是由于英语是印度的官语,印度人的英语普遍优于我们,所以他们就写得比较文艺了一些吧。
引言部分包含三个自然段落,分别介绍了冠状病毒的分类及其引发的人类疾病、传播特点,以及为何要研究棘突蛋白等等,表述的还算清晰。
接下来是方法学部分。噫,怎么就只有一个段落呢?有点奇怪,但大的方法学问题还算是都有一个简单的交代吧。现在是新冠病毒刚刚发现、疫情也才爆发不久的关键时刻,学术大佬都在争先恐后地贡献自己的最新研究成果。也许是为了在最短的时间内将自己的成果呈现给读者吧,写的匆忙了些,就将就着看吧。如果你是这个领域的学者,又对这个研究比较感兴趣的话,还可以用电子邮件与通讯作者联系和交流嘛。
再往下是结果部分,这是全文的重点。科技工作者做研究不就是为了贡献自己的研究成果吗?结果部分有1、2、3、4,哦,不对哟,是1、2、......、5,嗯,5个小标题。嘿,我说大神,你有这么多的新发现,是不是需要为每个小标题给一个编号呀?时间再怎么紧似乎并不缺多花几秒钟敲几个阿拉伯数字吧?还有,这么小标题的格式也不统一呢?太不认真了!
讨论部分写作的好坏往往能决定这篇论文的深度,也是其学术水平的标志。写过论文的小盆友都知道,学术论文的引言和讨论是最难写的两个部分,也是最考验研究者/作者学术水平和写作功力的部分。一篇优秀的学术论文不仅是向同行展示自己最得意的研究成果,告诉大家自己解决了什么样的科学问题、有怎样的科学新发现,是怎样解决和发现的?希望能得到同行的认可。同时也希望通过讨论部分的进一步的阐释,深刻揭示研究的意义、回应引言的立题因由。这些需要作者阅读和掌握大量已有文献,研读并仔细消化、理解这些文献,再从基础/背景上深入评述本项研究的意义、价值,以及独特性、创新性等等,讨论存在的问题与不足,并就将来的研究提出一些有益的建议,期待对同行研究有所启发和帮助。
这篇论文有如此惊悚的发现,按理应该能读到十分精彩的讨论。有点失望,按印度人的英语写作能力不应该呀!
结论部分简要地复述了一下该文的“3大惊悚发现”,没有什么特殊的。
文献部分有点小小的怪异,不知道是不是bioRxiv的特色?例如:绝大多数文献都给出了doi链接,但并没有给出印刷版的期卷号和起始、终止页码。有的文献既无doi,有无页码;有的又同时给了doi和页码。作者在写作时有点随意呀!
文末有4个作为补充资料的图片,图片的编号却不统一:前3个图片用的是Fig.S1 ~ Fig.S3,最后一个却用的Supplementary Fig 4。大神在写论文的时候都是这么随意的吗?
网站上还同时提供了一份补充材料的文档供下载。一般来说,补充材料是为了使正文尽可能地简洁,同时又能最大限度地满足读者对论文全方位的审读提供足够的信息和支撑材料。怎么下载下来后的补充材料就一个非常简单的exel文件呢?
失望!
3、最后大致看看内容的细节吧
本想抱着仰慕的心情仔细拜读大神的杰作,然后献上膝盖的。由于论文结构和格式问题太多,实在倒胃口,没有了刚刚看到那个惊悚热辣的标题时的那种渴望和忐忑不安的心情。再想想,毕竟有可能大神实在是太想尽快地贡献自己的研究成果,所以没有太在意结构、格式那些形式主义的东西吧。还是耐着性子往下看吧。
髯鹅,髯鹅,还是比较失望!
不再重复前文提到的结构与格式问题,单单文中的内容就发现了不少问题。为了保护尽可能多的脑细胞免于过劳死,防止过早老年痴呆,也为了尽可能节约时间和精力,就不必花时间一一考证每一处错误了。何况有些错误隐藏的比较深,需要扎实的专业知识,加上激烈的烧脑运动才能发现。这里仅列举一些明显的低级错误吧。
1)第3页第2行引用了编号为“Table S.File1”的附件表格文件。虽然点开网站的附件材料链接出现了S.File1的文件名,但下载该文后得到的只是一个内容异常简单的、名为media-1.xlsx的文件。该文件连最简单的相关描述(例如表题等)都没有,更不要指望什么详细的材料方法描述等等,文件名也与网站链接提供的名称不一致。
2)第4页最后一行引用了Fig.S3来佐证所发现的4个插入序列都是完全保守的(all the 4 insertions were absolutely (100%) conserved in all the available 2019- nCoV sequences analyzed [Fig.S2, Fig.S3]),可是文末提供的Fig.S3并不是序列分析图,而是系统进化树,而且这个系统进化树的中部右边有5条序列标注为outgroup(外类群)。作者理解outgroup的含义吗?那5条序列是outgroup吗?
3)文中第5页第1自然段说第2个插入序列有6个氨基酸序列与HIV的相同,可你到图2去数一数,看第二个插入序列共插入了几个氨基酸?同一段落引用的表1明明记载着第3个插入序列的起始和终止位点分别是245和256,可是图2中作者标出的第3个插入序列的起始点和终止点好像是256-261!同样的问题也出现在第4个插入序列上。这4个插入序列是作者最大、最重要的发现,理应给予高度关注,为什么文中出现这么低级的错误?不会数数还是不识数?亦或老眼昏花看混淆了?那么多作者都没发现这个低级错误吗?
4)图3是这么回事?怎么一个图上同时出现了Space-filling model (空间填充模型)和Schematic model (示意图模型)两种风格的图?为什么将所谓的插入片段的Space-filling model (空间填充模型)风格的图形“嫁接”在棘突蛋白的Schematic model (示意图模型)上?这是什么样作图软件能给出这么骚的操作?没猜错的话,是P图软件P的图片吧!
5)轻度烧脑的几个错误。大家仔细揣摩文中的图和表,还能发现不少不可理喻的错误,这里就不一一指出了。至于那些需要中度,甚至重度烧脑的错误就不列了。因为我想爱护大脑,它是个好东西!
三、结论
Excuse me,我还以为只有在每年评阅还是“愣头青”的粗心大意的本科生写的毕业论文是才会出现这么多的明显不符合学术规范的初级错误,难道印度理工学院(看过《三傻大闹宝莱坞》的电影吗?那可是印度最好的大学)和德里大学(仅次于印度理工的大学)的学者这么粗心吗?
所以,唯一靠谱的结论就是:这篇文章是用来搞笑的!唉,大家都在家中憋闷了这么多天,都快要憋疯了,文章作者的良苦用心还是要体谅的。当然还有一种可能,这篇文章可能根本就不是印度理工的Prashant Pradhan大神写的。
https://m.sciencenet.cn/blog-3357384-1216646.html
上一篇:《走楽》赏析
下一篇:镇服“冠瘟”需努力