【立委按】微信群拉近了天涯海角的华裔专家的距离。这类富于智慧的专业讨论及其碰撞出的火花是教科书上看不到的,一般的大学或研究所的讲堂里也难遇到。大概类似于早年高级知识分子的沙龙,唇枪舌战,佐以幽默机锋。但不同的是,这些有意思的笔记几乎瞬时记录在案,以飨天下。如果你感觉受益了,请先感谢张小龙,再感谢群主白老师。都是神仙。
宋: 分布还是有意义的,比如“戴帽子”和“穿帽子”就是一种词对词的分布。
白: 这个可以被统计完败。
宋: 对,分布式可以统计的,但受到语料库内容的局限。比如拔火罐的情景对话,语料库中可能没有,结果“紫”就是区别词。
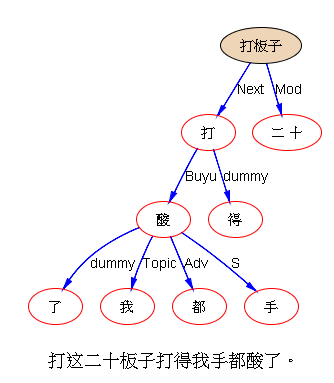
白: “这二十板子打得我手都肿了”。“这二十板子打得我手都酸了”。 我和打的关系,因为一个字而不同。
宋: 这种知识,怎样加到知识库中呢?
白: 肿,是伤病的一种;酸,是乏累的一种。施动导致乏累,受动导致伤病。这是知识图谱的思路。
宋: 句法语义分析,只能说打的结果我手肿或我手酸,至于我打还是我被打,不知道,这是常识范畴,是不是很难加紧知识库呢?
白: 也可以硬选一个概率大的,其他休眠。等常识有了相反线索再唤醒。
宋: “这穴位一捏,我的手立刻酸了”。
白: 嗯。这就需要唤醒了,捏穴位,被捏者有酸麻痛胀气感。但这不是词典级别的休眠唤醒,是语义角色指派(填坑)环节的休眠唤醒。
宋: “捏了一上午穴位,手都酸了”。
白: 时间又起作用了,再翻盘。
宋: “捏了半小时的穴位,我的手才感觉酸”。
白: 休眠唤醒本身的对象有个级别问题,休眠唤醒所依据的知识,也有个级别问题。 宋老师最后这个例子,歧义了。
宋: 是歧义。但是否有歧义,也是靠关于捏学位的知识来判定的。捏两秒钟酸是患者酸,捏两小时酸是医生酸,捏20分钟酸有歧义。
白: 以前面“板子”的例子为例,句法究竟要不要确定“我”是打的还是被打的?确定“这二十板子”是句法上的主语,最好交差。句法是不是到此为止?
宋: 我觉得是这样。从上面的例子看,我对于涉及常识的问题有点悲观,觉得碰不起。或者,要积累太多太多的知识才行。 但是,人是怎么获得和存储这些常识的呢?为什么人可以有这些常识从而能判断,机器就不行呢?
我:拿立氏parser分析一下看:
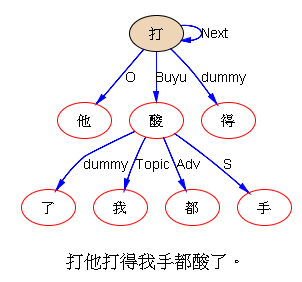
白: 伟哥更狠,上层无主语,下层俩主语(包括Topic)。 原因,居然是,他用了远距离相关。 “打板子”弄一起了。
我: 搭配啊。 这个分析形式上是合理的,隐含的坑没填。“我手疼”和“我手酸”是一样的,没有啥疑义,因为表达是显性的。问题出在,这个“我”怎样去填写上一层的坑。
白: 实际上,这两句微调一下,就是:“打这二十板子do得我手都肿/酸了。” 引入虚动词do表陈述,实动词和它的固定搭配一起表指称。 我在N多年前(N大于10起码)发表的文章《论语义重心偏移》就是这个路子。
我: 两个“打” unify,虽然汉语句法上必须重复(reduplication)。不过前面的合成词“打板子”与“打”,没能unify 虽然应该unify:问题出在,词典中合成词的搭配,默认是黑箱子。可这个黑箱子不够黑,其实是蛮透明的。
白: 这样交差,面子上最好看。 上层的坑,候选就在下层,可是咫尺天涯
我: 距离不远,如果有可靠的痕迹(常识不算),可以填坑。
白: 保持一种能交差的模糊还是确定一种能翻盘的推测,都可以,不同的技术路线。把去模糊或者翻盘的任务留给下道工序。
宋: 二十板子打得我手都酸/肿了。弄清楚二十板子是打的动量,我手酸肿是结果,就够了。为什么非要弄明白打的施事和受事呢?这个信息也许上下文中有明示,为什么非要从这一句话中凭常识去理解呢?我觉得这还是英语的影响,只要有及物动词,就非得有个施事有个受事,其实听的人可能不关心,至少在听这个句子的那一刻并不关心。英语是摆出了架子,论元结构,每个句子基本论元都要填全。汉语语法简单,语义也简单,关心的事情都不想说明白,不关心的事情绝对不说。汉语的语义分析句法分析,不能用英语的那一套。
我: 宋老师是在question为什么要补全,任它模糊不行么?补全了,究竟什么时候、哪些用场要用到?我有同样的疑惑。不过这不像宋老师的问题,因为宋老师就是做补全工作的。
宋:我现在没说补全。如果说补全,用堆栈结构,也是有限地补全,不一定包括基本论元。
白: 坑是在建立词典的时候就挖好的。有些语义的坑甚至与语种无关。理解就是坑驱动的并且以填坑为目标的。想要弄明白没错,常识也不是弄明白所唯一依靠的手段。了解没有填满的坑和没完句的标点句一样是有“张力”的,就够了。应用与哪些张力接轨,是应用的事。 “二十板子”那个,甚至可以说形式上都全了。但是张力依旧在。你可以明确地不理睬张力,但是这和没感到张力是有区别的。
宋: 我觉得要在话语内和话语外之间划一条界限。计算语言学先把话语内的事情解决,人工智能可能关心话语外。先搞字面理解。字面外的东西另说。
白: 这个可以有。
宋: 这就要建立一个适合汉语的字面理解的语义体系。
白: 但是接口的表达能力强,还是不一样。比如,“乒乓球是谁也打不过”,“足球是谁也打不过”。没有常识,你不知道谁强。但是,知道某两个成分一定分别填某两个坑,也够了。
宋: 两个问题所用的策略和资源可能不一样。先弄清楚字面的语义有哪几个要素,是用什么语言形式表现的,有什么规律性的东西可以让计算机抓住的。
我:“爱是一种珍贵的感情”。谁爱?爱谁?坑从词典里就有了。填不填呢?这是一个极端的例子,答案是:不需要填,或者按照标配去填。其实甚至按照标配填都不合适,因为在讨论爱这个概念的时候,人甚至不想被标配束缚。标配是人,可是我们的信教朋友讨论爱的时候,默认却是上帝。
白: 一种,已经指称化了,与陈述可以无关。无关就不需要填。只有陈述的坑才有张力,指称的没有。标配都不需要。去南极太危险了。谁去南极,不需要关心。不产生张力。
我: 是不是在填坑前,先掉一个程序确定谁有张力,谁没有张力,然后再去填?这个张力的标准也不是想象的那么容易识别,或容易有共识。
白: 在分析过程中就能确定吧。
我: 在一个充分开发的系统,填上了的就是有张力的,填不上的就是缺乏张力的?
白: 有些是跨句的。比如:“我知道谁是凶手”。“凶手”抛出一个“案件”的坑。但是句法上,这句话自足。如果系统认为“凶手”不需要关联“案件”,那也没什么,大不了信息抽取的时候再通过其他渠道重新发明轮子呗。
宋: 说英语大人也没那么较真儿。不关心失是受事的时候就用一个有行为意义的名次。表达成汉语,形式一样。人家已经不关心了,我们还在挖掘。
白: 也不是不关心,坑还是坑。比如the removal of sth,sth就是个填坑的。
宋: 英语通过词性标志明白地表示我关不关心,汉语没有这种标志。那就是在话语中直接表现出这种关心了。
白: The retirement of somebody,动词降格为名词,但动词的坑,通过名词的领属格,继续存在下去。
宋: 字面上有的,是我的职责,没能解决是我的失职或能力不足。字面上发没说的,请人工智能大哥解决。
白: “谁也打不过”,两种填坑方案,一个最强一个最弱。谁强谁弱,人工智能大哥可以告诉你。但是告诉你了还填不对,就是NLP的能力问题了。
宋: 隐喻之类的,是二者之间。
白: 隐喻另说吧。
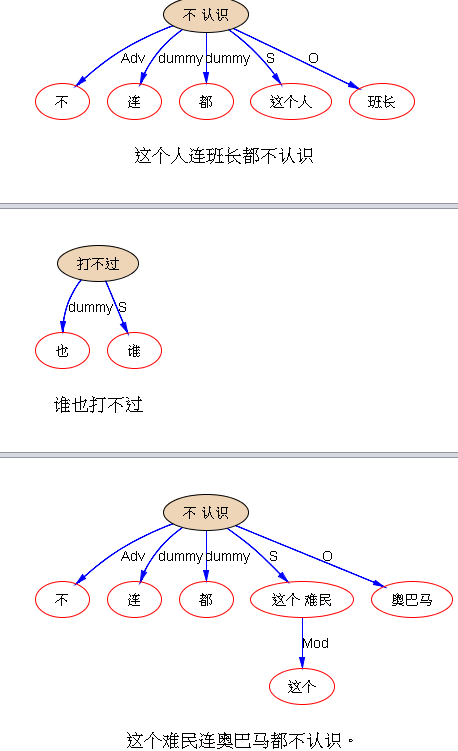
宋: 这是句式语义,字面问题。“这个人连班长都不认识”。
白: 这个也可以假装没有歧义,咬死了“这个人”是主语,“班长”是宾语,也可以交差。只不过把填坑的任务转嫁了而已。 parser是“能做多少做多少”,还是“能做多少做多少”?还是“面子上能做多少做多少,实质上能做多少做多少”? 确实有个取舍。
我: 这些个特别句式或特别的说法,它的歧义是容易识别的、它的标配语义是清晰的、它的排歧是困难的。费了半天劲,还是很难排除歧义,不如止于识别,或者止于标配(以后可以翻盘)。
宋: “这个难民连奥巴马都不认识”。这种话的理解,确实需要知识。但在计算语言学中,可以先悬起来,问大哥:奥巴马不认识一个难民是常规还是一个难民不认识奥巴马是常规?大哥告诉他前者是常规,于是小弟得出答案:这个难民不认识奥巴马。如果大哥不告诉小弟,小弟只能把结果模式和需要的知识都摆出来,收不了口。
宋: 没错。“拿多少钱干多少活儿”。
“有多少能力干多少活儿”。
白: 止于识别并保留明确的翻盘接口。 止于标配。 我的选择。 没有外部信息,就按先来后到了。
宋: 字面上的东西,计算语言学责无旁贷。堆栈模型就是字面上的。
白: 要翻盘,从队列里按顺序翻就是了。
宋: 难民的例子说错了。奥巴马不认识难民是常规,于是小弟知道是难民不认识奥巴马。
白: 知名度低的不认识知名度高的信息量大。 实力最弱的打不过实力最强的是标配。 填的时候,不是“两可”而是填这种系统调用附带逻辑约束。这样外部知识应用就有方向了。
宋: 标配就是缺省值,对吗?
白: 是。
我: 这些算标配了。 标配的翻盘可以在识别了这种歧义的句式的时候,设置一个 tag,后去的模块可以考虑基于 tag 所指,看有没有其他的依据去翻盘。
白: 不仅值缺省,标签也缺省。我是这个意思,见图:
我: 看成了 臭巴马。哈。
白: 嗯,字臭么。
知名度的值或序,外部给。但是除了这个,NLP都可以确定。
我: honestly 这样做系统,容易限于烦琐哲学。另一个风险是,容易引起很难判断的“语言外知识 vs 语言内句式的标配语义”的较劲。Case by case 可以说得头头是道,但也极易捉襟见肘,或聪明反被聪明误。毛主席说:知识越多越反动。
白: 贫下中农说,背着抱着一边儿沉。
我: 一个系统负载太多的碎片化知识,会陷系统于不鲁棒不好维护的境地。Stay simple,stay foolish,stay knowledgeless,as much as possible。
白: 加起来总是繁琐的。
我: taxonomy 这样的本体知识 hierarchy 用起来副作用较少,因为可以用这些 taxonomy 做细化的规则,下面的粗线条的标配并不变。但是一旦开始用常识或世界知识,这些非元知识的系统,危险大大增加,很容易弄巧成拙。
白: 角度不同。一个既要做parser又要做应用的开发总负责人会做合理分工的。这不是世界知识,只是一个接口,甚至你可以不命名。只用内部编号。总之,填坑的方案取决于一个量的外部排序。
我: 知名度当然是世界知识,不是本体知识。奥巴马知名度高,是一个非常实在的世界知识。
白: 可以不叫知名度,这行吧。叫external-quantity123,到时候给映射上就OK。
我: 叫什么都不改变知识的性质,这些知识是与 entity 关联的图谱性的东西,而不是不随世界而变化的本体知识。 奥巴马与一介平民的比较还好,换成两个其他人名,几乎没有可操作性。
白: 不可比,就不代入人名,死不了啊。实际上,语义场理论里,序结构是个基本的结构,这个完全是可控的。拿不可比的序关系说“连....都...”句式,那是语病。那种情况下不可操作是天经地义的。如果是人机对话,机器遇到人说了不可比的情况,可以生成问句,进一步追问二者在相关外部量上的排序。比如“不认识”可以驱动对知名度排序的追问。“打不过”可以驱动对实力排序的追问。parser只要能表示“孰高”就OK。
我: exactly,如果是人机对话的语用场景,问题根本就不存在。上帝的归上帝,人的归人,机器的归机器。机器只需识别歧义,which is tractable and easy in most such cases,消灭歧义归人。用些小的技巧就可以实现,一点都不困难。我专门为此写过两篇笔记。很多看似极为艰深的语言歧义,到了人机交互现场,简直就不是事儿。
白: 还要让人的体验好啊……不是为了消灭歧义而消灭歧义。 要让人知道机器除了问人的那一点不知道,该知道的都知道了。
QUOTE:“世界上怕就怕认真二字,昨晚对‘双关语’认真了一回,发现微妙的外表下面,是简单的实现可能,绝大多数双关不过是一词多义而已,识别它没有难处。 自动消歧自然是难,但是有消歧的必要么?双关之所以叫双关,就是否定消歧的必要性。”
白: 双关不在结果而在过程。
我: 要点是,一个词的多义,或者一个句式的多义,识别它非常容易。
白: 过程是休眠唤醒,最后都留下。中间一个休眠了。没这个过程,是索然无味的。“对付”人机对话太容易了,做好不容易,要有点追求么。
我: 不说人机对话,感觉上,需要核心引擎用细琐的知识排歧的语用产品,不为多数。
信息抽取是一个重要的语用场景,过去17年就做它了。虽然理论上说,所讨论的那些排歧和填坑,可以帮助抽取和抽取的信息融合(info fusion)。但实践中,在信息抽取(或知识图谱)的任务确定以后,信息融合所需要依仗的支持,在大数据的信息冗余的自然帮助下,很少要用到核心引擎的细颗粒度的排歧和填坑。这个体验是经验性的,可以信或不信,但这是真实的感受:独立于 domain 的细琐的语义求解对最终的知识图谱任务,没多大帮助。细颗粒度语义有科学意义,实用意义不大,况且很难实现。一个 light weight 的 deep parser 就够人忙的了,还要加载细琐语义,这是要压垮系统的节奏。
白: 排岐并不是唯一目的。设想尼克问你:你咋连冰冰都不认识?你回答:冰冰谁啊?这不是在排岐,但却使用了你自己的知名度排序,把冰冰知名度说的一钱不值……
我: 多数语义最好与语用一起做,而不是超前,虽然理论上超前的语义可以对所有语用有益。 其实这个道理与为什么大多数知识图谱项目并没有采纳 FrameNet 作为中间件是一致的。 理论上,FrameNet 的存在就是为语义和语用架设一座桥梁。 但实际上,稍微尝试一下就会发现,与其先瞄准 FrameNet 然后再从 FrameNet map 到语用的domain 定义的目标, 不如直接从句法结构去做domain语用。 后者不仅省力省工,而且更加容易掌控和debug。总之根本就没有可比性。
白: 即便董老师做Hownet,傻子也看得出来他的语用是机器翻译。世界上没有超前的语义,只有超前的语用。语义和语用不匹配是自己没把握好
我: 同意。
可以总结一下我的经验和立场了:
(1)WSD 这一层的词义 ambiguity,原则上 keep it untouched。很多词义的区别属于nuances,并不影响本体知识的 taxonomy的features,如果遇到两个词义相差大,那么就两条路径的 taxonomy 全给,系统用到哪条算哪条。以此来维护先句法后语义的大原则。
(2)对于句素之间的关系语义的歧义,PP-attachment 之类,两个策略都可以。deterministic 的策略就是先休眠其他可能,然后在需要的时候在后续的模块做reparsing去重建 non-determinitic parses 唤醒并重选。第二个策略,就是注重 identify 这种歧义,但不去排除它,而是都给连上(当然可以有个排序)。句素间连上多种parses,没有什么负担。一个Node 既连成了主语,又连成了宾语,虽然是违背了依存关系的原则,但却凸显了歧义。后去的模块只要在歧义中选优(排歧),或者语用中都尝试一下即可(不排歧,用语用知识弥补歧义路径的不足)。
(3)对于句素下的歧义,譬如短语内的歧义,最好是休眠,不能带着瓶瓶罐罐去做deep parsing。
这算是语重心长的经验之谈。值100文。
【相关】
【新智元笔记:搭配面面观】
【新智元笔记:汉语分离词的自动分析】
《 立委科普:机器可以揭开双关语神秘的面纱 》 《 贴身小蜜的面纱和人工智能的奥秘 》
【置顶:立委科学网博客NLP博文一览(定期更新版)】
转载本文请联系原作者获取授权,同时请注明本文来自李维科学网博客。 https://m.sciencenet.cn/blog-362400-954552.html
上一篇:
【新智元笔记:搭配面面观】 下一篇:
《新智元笔记:跨层次结构歧义的识别表达痛点》