博文
文献阅读笔记(7)-几种基于DOM的网页去噪方法
||||
几种基于DOM的网页去噪方法
[1] 李剑.基于DOM和神经网络的网页净化应用[J].电子科技,2012(1):109-111.
去噪步骤
l 运用HTML Parser将HTML文档解析成DOM树. 把DOM树节点分成两类:组织节点(如TABLE,TR,DIV,UL标签)、非组织节点(如TD,LI,P,IMG标签)。通常非组织节点包含在组织节点内。
l 基于DOM树建立内容块树. 即把以HTML为根节点的DOM树转化为以BODY为根节点以TABLE或DIV为孩子节点的内容块树.
l 初步选择子内容块. 内容块树由内容块子树构成.计算子内容块占内容块的文本比例和HTML编码比例,与设定好的临界值比较,选择出用于神经网络的训练输入子内容块.
l 运用BP神经网络选择出主内容块,得到过滤模型. 将上一步所得的子内容块输入BP神经网络进行训练和测试.本文所用神经网络由3层组成:输入层、隐藏层、输出层.作用函数为非线性的Singmod型函数.
l 运用过滤模型去噪.
实验分析
1)数据集.从新浪博客、网易体育、百度知道分别获取600个网页,其中分别取500个网页用作训练,100个用于测试.
2)衡量指标.正确率CR=CB/TB. 误取率ER=EB/TB. 漏取率LR=LB/TB. 其中TB是总的内容块数,CB是提取出的正确的内容块数,EB是误取的内容块数,LB是漏取的内容块数.
论文点评
本文的算法简单来说:DOM树à内容块树à子内容块àBP神经网络训练得到过滤模型à去噪.论文有三点不足.1)算法描述部分纯用文字描述,导致读者不易看懂算法过程.2)神经网络部分介绍的篇幅过少.3)没有给出实验结果具体数据,只有一个光秃秃的图表,有隐藏真实实验结果牵强附会之嫌.
[2] 何友全,徐澄,徐小乐,等.一种基于统计学特征和DOM树的网页去噪技术[J].重庆理工大学学报(自然科学版),2011(1):58-62.
去噪步骤
l 预处理网页.运用正则表达式过滤SCRIPT,STYLE等标签.
l 建立DOM树.运用HTML Parser将网页解析为DOM树.
l 分析容器标签并进行取舍.容器标签是本文用到的基本概念,指用来规划网页布局的较大粒度的标签,如BODY,OL,UL,TABLE,FORM,DIV等.(像TR,TD,SPAN等属于粒度较小的标签.B,BR,HL属于展现标签.另外,本文也规定:如果内容块(即DOM节点)有子节点,那么内容块的文本除了自身还加上所有子节点的文本).这一步考虑容器标签所包含文本长度与网页总文本长度之比、容器标签内的文本密度,通过跟阈值比较来判定是否是噪声节点.满足阈值的容器标签保留在节点列表里.
l 将节点列表的容器标签(这些标签都标记着正文)组合为最终页面.即得到去除噪声后的页面.
实验分析
1) 数据集. 采用12个站点的860个网页测试,最后随机抽取100个网页进行手工检查.
2)衡量指标.优良中差.
算法假定
1) 考虑到实际页面中,正文整体所处的容器标签不会太深,所以采用迭代深度参数为3层.
2)大部分情况下标签密度超过某个阈值或文本长度未达到一定比例的节点认为是噪声节点.节点的标签密度和文本长度是判定噪声节点的关键切入点.
论文点评
本文的算法简单来说:定义容器标签àDOM树à取舍容器标签à去噪.由于网页去噪目前并没有标准的算法评价标准,所以本文采用粗糙的“优良中差”来进行评价,因为缺乏对比所以并不能知道该算法的实际效果如何.另外,在最后的结果评价时需要手工进行检查,这也是一个不足.
[3] 罗成,李弼程,张先飞.一种有效的网页噪声消除的方法[J].计算机工程,2007(8):89-91.
去噪步骤
l 给每一个页面建立一棵文档树, 即DOM树.
l 将多个DOM树合并为一个模式树,即PT树. 模式树能将DOM树集合中相同的部分和不同的部分表示出来.如下图所示,阴影部分为不同部分.

l 根据模式树中的节点的信息熵对网页的噪声进行判断和消除.节点E信息熵定义为:
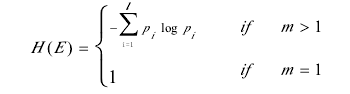
其中Pi表示基本节点E下一层的第i个节点在每个网页中出现的概率: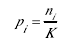 .式中,K表示网页集合中的网页个数,ni表示节点E下一层的第i个节点出现的网页的个数.
.式中,K表示网页集合中的网页个数,ni表示节点E下一层的第i个节点出现的网页的个数.
l 确定噪声节点之后并去除,得到去除噪声的模板.
l 运用模板对网页去噪.
实验分析
1)数据集. 用SVM分类器作为基准分类器,训练集合测试集共有2000个网页.随机抽取300个网页得到模板.用1200个网页训练,800个网页作测试.
2)衡量指标. 查准率precision,查全率recall,F1.先不对网页进行净化,用基准分类器训练、测试得到基准结果。然后对网页进行净化,分别进行训练和测试,得到净化结果,通过对比可以评价出算法的去噪效果.
论文评价
本文的算法简单表示:DOM树à模式树à信息熵à去噪.
https://m.sciencenet.cn/blog-719488-807177.html
上一篇:文献阅读笔记(6)-网页分割算法汇总图
下一篇:文献阅读笔记(8)-基于DIV位置的网页正文抽取方法和装置