博文
- When is nearest neighbor meaningful
- 热度 1
-
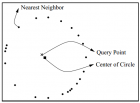
1999年的这篇文章,个人认为是涉及到近邻问题的研究领域,并且为核方法和降维方法提供很好的支持的很重要的文章。它的三个主要工作是: 1,说明并证明了数据集满足一定条件的前提下随着维度的增大,NN将变得毫无意义。 2,虽未给出证明,但从经验上给出了使得NN仍有意义的上限。 3,研究了满 ...
- FEKM: fast and extract out-of-core k-means clustering
- Kmeans的时间复杂度是O(m)(《数据挖掘导论》,m是数据规模)。但是,算法在每次迭代过程中需要计算每个点到各个质心的距离,于是距离函数需要被计算km次,k是质心个数,而计算欧氏距离的过程如果看成是求一个n次多项式的函数值的过程,就算运用秦九韶算法也需要n次乘法和n次加法。当数据规模很大甚至作 ...
- Naive Bayes和贝叶斯网络
- 热度 2
-
朴素贝叶斯和贝叶斯信念网络(简称贝叶斯网络)是数据挖掘和机器学习中基本的分类算法,其理论基础都是贝叶斯定理。 1,回归模型和生成模型 有监督的分类问题可以分为两大类,回归模型和生成模型。 回归模型:首先假设样本服从某一分布,常用的如高斯分布、伯 ...
- SDR, USDR and DRSC
-
2011 Dimensionality Reduction for Spectral Clustering 在处理大数据时,抽样和降维是两种常用的方法,但是二者的目的的方法却从来都大相径庭。抽样的目的是,在一定的聚类结果准确度的衡量标准下(如 ATutorialontheSpectralClusteringSection8 中用图的分 ...

- FASP 和 Nystrom low-rank approximation
- 热度 1
- FASP:Fast Approximate Spectral Clustering 2009年KDD上的这篇Fast Approximate Spectral Clustering,提出了一种谱聚类算法的框架,并设计了该框架下的两个实例:基于k-means算法的KASP,和基于随机游走的RASP。并通过实验说明了该框架的优势。这篇文章和之前阅读的Spectral Grouping Using Nystrom ...
- 阶段性总结
- 我对大数据谱聚类的学习,从2007年IEEE上的 A tutorial on spectral clustering 开始。这篇文章从相似度及拉普拉斯图这两个基本概念开始,介绍了基本的谱聚类算法,并针对运用三个不同的拉普拉斯矩阵(L,Lsym,Lrw)做谱聚类的三种方法分别解释了算法的由来,随后罗列了诸如相似度图的选取(相似 ...
- Nystrom估计的误差分析及改进
- 热度 1
- Improved Nystrom Low-Rank Approximation and Error Analysis 小秩矩阵(low-rank matrix)在核方法和抽样中,可有效地减小计算开销。给定数据集$X{\rm{ = }}\left\{ {{x_i}} \right\}_{i = 1}^n$,核矩阵为$K = \left\{ {{{\rm{k}}_{ij}}} \right\}_{i,j = 1}^n$,其中${k_{ij}} = k({x_i},{x_j}) = ...
本页有 3 篇博文因作者的隐私设置或未通过审核而隐藏