基于深度强化学习的六足机器人运动规划
傅汇乔 1 , 唐开强 1 , 邓归洲 2 , 王鑫鹏 2 , 陈春林 1
1 南京大学工程管理学院,江苏 南京 210046
2 西南科技大学制造科学与工程学院,四川 绵阳 621010
【摘 要】 六足机器人拥有多个冗余自由度,适用于复杂的非结构环境。离散环境作为非结构环境的一个苛刻特例,需要六足机器人具备更加高效可靠的运动策略。以平面随机梅花桩为例,设定随机起始点与目标区域,利用深度强化学习算法进行训练,并得到六足机器人在平面梅花桩环境中的运动策略。为了加快训练进程,采用具有优先经验重放机制的深度确定性策略梯度算法。最后在真实环境中进行验证,实验结果表明,所规划的运动策略能让六足机器人在平面梅花桩环境中高效平稳地从起始点运动到目标区域。为六足机器人在真实离散环境中的精确运动规划奠定了基础。 【关键词】六足机器人 ; 运动规划 ; 深度强化学习 傅汇乔, 唐开强, 邓归洲, 等. 基于深度强化学习的六足机器人运动规划[J]. 智能科学与技术学报, 2020, 2(4): 361-371.
FU H Q, TANG K Q, DENG G Z, et al. Motion planning for hexapod robot using deep reinforcement learning[J]. CHINESE JOURNAL OF INTELLIGENT SCIENCE AND TECHNOLOGY, 2020, 2(4): 361-371.
相对于传统的轮式与履带式机器人,足式机器人拥有更强的地形适应能力与越障能力。在多足机器人中,六足机器人具有多个冗余自由度和丰富的行走步态,具备更好的容错性和静态稳定性,在抢险救灾、物资运输、军事侦察、星球探索等领域具有广泛的应用前景。如何提升六足机器人在非结构环境乃至离散环境中的运动能力是当前的研究热点之一。 六足机器人的运动主要分为规划和控制两个部分。规划部分在环境模型的基础上,给定机器人的起始状态与目标状态,规划出一条可行的质心与足端运动轨迹;控制部分通过驱动机器人各关节运动来跟随目标轨迹。参考文献 聚焦于六足机器人在半结构环境中的运动规划问题,通过RGB-D相机建立环境2.5D模型,经分割处理后去除环境中不适合作为落足点的禁止区域,最后利用标准的A*算法得到机器人在所创建环境中的运动轨迹。参考文献 利用灰度腐蚀获得不连续地形边界图像,然后基于前进、旋转和自适应步态设计六足机器人在不连续地形上行走时的步态选择策略,通过图像处理技术提高六足机器人在不连续地形中的行走效率。 传统的 A*、广度优先搜索等算法能够在状态空间维度较低的情况下为机器人快速规划出可行运动轨迹,但在维度较高的状态动作空间中往往会面临维数灾难问题,因此使用此类算法需要将机器人的状态空间以及动作空间进行充分的离散精简,在降低优化指标的前提下得到次优策略。近年来,随着深度强化学习的发展,越来越多的研究人员开始利用深度强化学习算法在高维连续状态动作空间中为游戏 AI、机器人等智能体生成运动策略。参考文献 结合基于模型的运动规划方法和深度强化学习算法,利用可达性评价准则替代物理模拟来构建马尔可夫决策过程,在高维连续状态动作空间中为足式机器人规划运动轨迹,并控制各关节进行轨迹跟随,使得机器人能够在各类非结构环境中稳定运行。参考文献 提出一种基于强化学习和模糊奖励的步态生成策略,利用Q-learning算法和模糊奖励机制来判断六足机器人的每一步是否为工作空间中的最佳位置,通过迭代更新在不连续地形上规划运动策略。参考文献 提出基于迁移强化学习的六足机器人步态生成策略,通过基于规则的强化学习和迁移学习,加快了六足机器人的步态学习速率。 随机梅花桩作为离散环境的典型例子,能够在一定程度上表征任意非结构环境,适合作为验证六足机器人运动策略可靠性的基本环境。本文以平面梅花桩为例,随机设定六足机器人的初始位置与目标区域,利用深度强化学习算法在平面梅花桩环境中为六足机器人规划运动策略。文章首先对六足机器人在平面梅花桩环境中的正逆运动学、质心和足端的运动空间以及质心静态稳定裕度进行分析求解,建立基本的运动学模型;随后采用具有优先经验重放(prioritized experience replay,PER)机制的深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法为六足机器人在连续动作空间中规划运动策略;最后建立平面随机梅花桩实验环境,并在真实场景中验证所规划策略的可行性。 六足机器人具有多个冗余自由度以及丰富的行走步态,如三足步态、四足步态、五足步态、自由步态等,由于各时刻都有3条及以上的腿处于支撑相,在多数情况下六足机器人始终处于静态稳定的状态。在众多步态中,三足步态能够在保证静态稳定性的前提下具备较高的运动效率,本文将三足步态作为六足机器人在平面梅花桩环境下运动的基本步态,并忽略其动力学影响。本节首先建立六足机器人运动学模型,然后分别分析六足机器人的足端、质心在固定平面内的运动空间,最后对六足机器人在三足步态下的静态稳定性进行分析。 2.1 单腿正逆运动学建模
六足机器人的单腿结构连杆示意如图 1所示。每条腿包含3个旋转关节,分别是基节轴、大腿轴和小腿轴,分别对应了坐标系0、坐标系1和坐标系2,连杆长度分别为l1 、 l2 和 l3 ,坐标系 3为机器人足端坐标系。本文利用标准D-H建模法对单腿进行正逆运动学求解,D-H参数见表1,其中角标i代表连杆编号,αi 代表关节扭转角, ai 代表连杆长度, di 代表连杆偏移, θi 代表关节转角。六足机器人的尺寸参数和各关节转角范围见表 2。
利用D-H参数对相邻连杆进行旋转平移变换,得到式(1)所示的变换矩阵。
利用齐次变换矩阵,可以得到从坐标系0到坐标系3的变换矩阵:
对式( 2)中的px 、 py 、 pz 联立求解,最终可得到单腿 3个关节的逆运动学表达式:
其中, 。 2.2 足端和质心在平面内的运动空间
假设六足机器人的整体质心等价于机身质心,其在平面梅花桩环境中运动时,质心始终处于同一高度,因此支撑相足端与质心的垂直方向距离保持不变,在求解足端运动空间时只需考虑足端在固定平面内的运动空间。六足机器人单腿平面投影如图2所示,其中 l 1 、 l2 和 l3 为机器人腿部连杆长度,见表1,l′为A点到C点的直线距离。以六足机器人的一条腿为例,假设足端与基节的垂直距离为 h,水平距离为L,约束|h|< l 3 ,可得:
在△ADC中,当h一定时,随着l′的增大, 增大;随着l′的减小, 表2 可知,当小腿轴转角为-90°时, ,可得 。 六足机器人在平面梅花桩环境中运动时,若要得知环境中的某个梅花桩是否在某条腿的运动范围以内,需要求得各个足端相对于质心的运动空间,如 图3蓝色阴影部分所示。以1号腿为例,其足端相对于机身坐标系0的可行域数学约束为:
其中, , ,代表1号腿基节坐标系 1 相对于机身坐标系 0 的平移变换量,D为机身半径,( x 13 ,y 13 )为1号腿足端相对于质心的坐标。同理,可求得其余5条腿足端相对于机身坐标系0的可行域数学约束。
由于六足机器人在平面梅花桩环境中运动时机身始终在同一平面内做平移运动,类比于足端运动空间求解方法,在求解质心运动空间时,固定足端坐标,质心围绕足端做平移运动,以质心为坐标原点,已知足端坐标,可求得质心相对于单个足端的运动空间。以1号腿为例,将质心坐标系0作为基坐标系,求解质心的可行域数学约束,如式(6)所示。同理可求质心分别相对于其余5条腿的可行域数学约束。
在三足步态下,已知当前支撑相3条腿相对于质心的坐标,通过式(6)对所求 3 组质心运动空间求交集,便可得出当前质心在固定平面内的运动空间,如图3红色阴影部分所示。 2.3 稳定性分析
六足机器人在平面梅花桩环境中运动时始终保持静态稳定,因此可以利用静态稳定裕度法(static stabilitymargin,SSM)对其稳定性进行评估。以此方法求得的静态稳定裕度表示足式机器人质心在其支撑腿各足端形成的支撑多边形内的投影到支撑多边形各边的最小垂直距离。其计算式如下:
其中, S i 表示机器人质心投影到支撑多边形第i条边的垂直距离,i表示支撑腿数目。 在忽略六足机器人腿部运动对其整体质心的影响后,六足机器人的质心可以始终等价于其机身质心。六足机器人在三足步态下的静态稳定裕度如下:
其中, S 1 、 S 3 分别为六足机器人质心投影到3个、 S 2 支撑相所形成的三角形各边的垂直距离,SSM的值越大,六足机器人的静态稳定裕度越大,当前时刻的静态稳定性越好。当SSM的值为负时,说明六足机器人质心投影处于支撑相所构成的三角形范围以外,此时六足机器人处于失稳状态。为了避免六足机器人处于临界稳定状态,即在运动过程中质心投影处于支撑相所构成的三角形边界上,在第4.2节对支撑相所构成的三角形进行了一定比例的缩放。六足机器人在平面梅花桩环境中运动时,只关注其静态稳定裕度是否为正。
4.1 实验设置
平面梅花桩环境长1800 mm、宽1200 mm,根据六足机器人足端运动空间分析可知,在机身高度h=80 mm的条件下,六足机器人足端距离该腿第一个关节的最小距离,最大距离 ,最大距离与最小之差 。由此设置梅花桩在平面梅花桩环境的长宽范围内随机分布,相邻梅花桩在x轴与y轴方向上距离的均值为100 mm,梅花桩总数为18 ×12=216,并约束每个梅花桩与其相邻梅花桩之间的距离大于梅花桩的直径,防止两个相邻梅花桩相交,生成的梅花桩坐标以及六足机器人质心在平面梅花桩环境中的坐标默认已知。最终生成的梅花桩地形环境如 图4 所示。 其中,绿色方块表示六足机器人质心起始点,红圈以内的范围为目标区域,红圈半径为60 mm,黄点代表梅花桩。实验中随机设定绿色起始点与红色目标区域,并限制起始点与目标区域中心距离大于600 mm,六足机器人的任务是质心从起始点出发,在保证机身稳定的前提下,用最短的步态周期使质心到达红圈区域内。 4.2 运动策略生成
六足机器人在平面梅花桩环境中运动时采用三足步态行进,其机身高度h=80 mm。将六足机器人在平面梅花桩环境中的运动建模为有限马尔可夫决策过程,其状态空间S包含支撑相坐标、质心坐标以及目标区域中心点坐标,动作空间A包含六足机器人质心在平面内的运动方向。机器人质心全局坐标与各梅花桩的全局坐标默认为已知量,根据六足机器人摆动相与质心在平面内的运动空间范围,可以分别求出每一组摆动相可以落足的梅花桩与质心在某一方向上的最大运动距离。六足机器人在起始状态下,首先根据其质心坐标,由1、3、5 号腿作为摆动相选取目标落足点,随后机器人在每一个运动周期内均完成两步操作:第一步,根据支撑相坐标与质心运动方向,计算六足机器人质心在稳定裕度范围内能够运动的最大距离,并移动质心到目标点;第二步,根据新的质心坐标,选取摆动相目标落足点。以此循环,直到机器人质心到达目标区域内。支撑相三角形缩放示意如图5所示。
如 图 5所示,在每个运动周期内,为了保证六足机器人具备充分的稳定裕度,避免处于临界稳定状态,以支撑相坐标点 Pi (x i ,y i )、P i+2 (x i+2 ,y i+2 )、P i+4 (x i+4 ,y i+4 )所构成的三角形P i P i+2 P i+4 的重心 Pc 为中心,将其按缩放比 s=0.8 缩放为三角形,其中:
、 与 的求法相同。
在已知质心运动方向的前提下,根据六足机器人质心运动空间,可以求得六足机器人质心在稳定裕度范围内能够运动的最大距离,并移动质心到目标点。随后,摆动相选择落足点 Pi 、 Pi+2 、 Pi+4 ,每条腿可落足的梅花桩个数分别为 Ni 、 Ni+2 、 Ni+4 , 3 条腿足端全部可能的落足点组合共有Ni × N i+2 × N i+4 种。对于每一组落足点所构成的如 图 5所示的三角形,为了避免六足机器人质心运动到三角形的边界处,导致机器人处于临界稳定状态,以三角形重心为中心将其按缩放比 s=0.8缩放为三角形i 和 Pmid 的距离 ,其中:
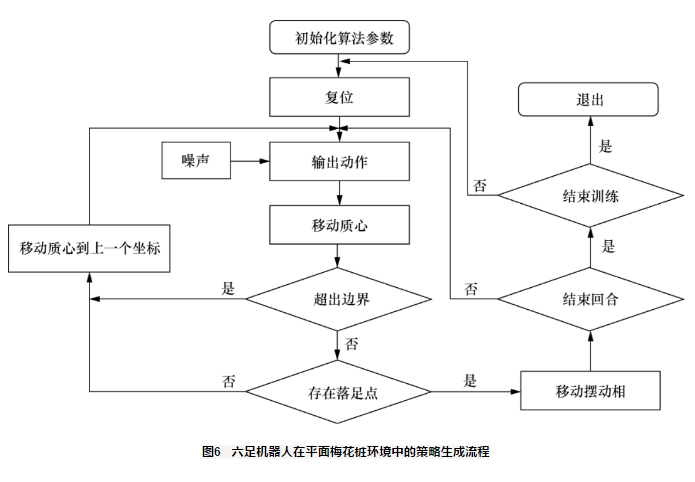
最终选取 六足机器人在平面梅花桩环境中运动时,采取的动作主要包括移动质心和选取摆动相落足点,其中移动质心时需要明确质心运动方向,进而计算该方向上稳定裕度范围内质心能够运动的最远距离。深度强化学习算法的任务是:输入各支撑相坐标、起始点坐标以及目标区域中心点坐标,输出质心运动方向,使得质心在稳定裕度范围内用最优的策略到达目标区域。 使用具有PER机制的DDPG算法训练六足机器人在平面梅花桩环境中的策略生成流程如图6所示。首先初始化算法参数,在每一个训练回合开始时,复位六足机器人质心到随机起始点,设定一个随机目标区域,并根据质心起始坐标点选取1、3、5 号腿的落足点,完成机器人的复位。然后对于每一个训练回合内的每一步,由动作网络输出一个带有随机噪声的动作a(a∈[-1,1]),六足机器人质心在平面内的运动方向θ=a·π,计算质心在θ方向上能够运动的最远距离,移动质心到目标点。判断质心点坐标是否超出环境边界:如果超出边界,则移动质心到上一个坐标,给予-10 惩罚值,重新输出动作 a;如果没有超出边界,则根据当前质心坐标选取摆动相落足点。如果不存在合适落足点,则返回质心到上一个坐标,给予-10 惩罚值,重新输出带有随机噪声的动作 a。如果存在合适落足点,则令摆动相的3个足端移动到所选落足点,并判断是否结束当前回合:若机器人质心坐标到达目标区域范围内,则给予100 奖励值,并结束当前回合,若该回合内总步数大于设置的最大步数,也结束当前回合。若当前回合未结束,则将新的落足点坐标输入动作网络,并输出新的动作 a,以此循环。对于回合内的每一步,给予-1的惩罚值。当训练回合数等于预设的最大回合数时,结束训练。
图7 为六足机器人在仿真平面梅花桩环境中的运动过程,其中绿色方块代表随机起始坐标,红色圆圈代表随机目标区域,蓝色线框代表机身,红色点代表六足机器人在运动过程中走过的梅花桩。图7(a)为开始训练时六足机器人的运动过程,随机生成的起始点坐标为(1 092, 900),目标区域中心坐标为(570, 407)。图7(b)为算法收敛时六足机器人的运动过程,随机生成的起始点坐标为(370, 372),目标区域中心坐标为(1 280, 761)。训练初期,六足机器人处于随机探索阶段,随着训练的进行,探索率降低,算法逐渐收敛,最终在给定起始点与目标区域的前提下,六足机器人能够在最少的步态周期内到达目标区域。 图8展示了采用具有PER机制的DDPG算法与采用标准 DDPG 算法平均回报曲线的收敛对比,其中深色实线为滑动平均滤波后的数据,浅色实线为原始未滤波的数据,平均回报的计算方式为回合总回报除以回合总步数。由于梅花桩分布的随机性以及奖励的稀疏性,使用标准的DDPG 算法收敛速度慢,某些情况下难以采样到有效经验甚至无法收敛。从图8 可以看出,具有PER机制的DDPG算法在150回合左右收敛,单个线程上用时约 3 min,收敛速度明显快于标准DDPG算法。
4.3 真实场景中的策略验证
为了进一步验证平面梅花桩环境下运动策略的正确性,根据仿真环境与仿真样机,等比例构建实际环境模型与实际样机模型进行策略验证。如图9所示,其中绿色方块代表质心起始点,红色圆圈代表目标区域,半径为60 mm,黄色点为随机生成的半径为30 mm的梅花桩。
根据仿真环境所得的六足机器人在平面梅花桩环境中的运动策略,可以在任意给定六足机器人起始坐标与目标区域的前提下规划出足端与质心的运动轨迹。六足机器人在平面梅花桩环境中采用三足步态行走,每一个步态周期内,3个支撑相移动质心到目标点,同时3个摆动相分别运动到目标梅花桩。根据第2.1节所求得的逆运动学计算式,在已知六足机器人足端离散运动轨迹的前提下,通过逆运动学计算式可以求得在每一个离散点处的各关节对应转角,由此可以控制实际样机始终跟随目标轨迹运动。图9(a)~图9(f)展示了六足机器人从起始坐标(300, 600)运动到中心点坐标为(1 500, 600)的圆形区域的运动过程。整个过程用时约30 s,共经历32个步态周期。 图10 展示了六足机器人运动过程中的各腿基节轴转角变化曲线,由于运动规划始终在表2所设置的关节转角范围限制下进行,因此基节轴转角始终处于±45°之间,进一步验证了所生成运动策略的正确性。
本文利用深度强化学习算法生成六足机器人在离散环境下的运动策略。针对六足机器人在平面随机梅花桩上行走的问题,对六足机器人进行了运动学分析,采用具有PER机制的DDPG算法,训练得到六足机器人在平面梅花桩环境中的运动策略,在随机给定起始坐标与目标区域的前提下,利用该运动策略可以规划得到六足机器人质心与足端的运动轨迹。最后等比例构建了真实平面梅花桩环境与六足机器人样机,利用规划得到的运动轨迹,六足机器人可以成功地从起始坐标运动到目标区域,进一步验证了运动策略的正确性。在未来的工作中,将针对六足机器人在三维随机梅花桩环境中的运动规划以及真实场景中的累计误差消除做进一步的研究。 作者简介 About authors
傅汇乔(1996-),男,南京大学工程管理学院硕士生,主要研究方向为机器人学、强化学习。 唐开强(1992-),男,南京大学工程管理学院博士生,主要研究方向为机器学习及随机优化等。 邓归洲(1998-),男,西南科技大学制造科学与工程学院硕士生,主要研究方向为机器视觉、机器人运动控制。 王鑫鹏(1995-),男,西南科技大学制造科学与工程学院硕士生,主要研究方向为深度学习、机器人运动控制。 陈春林(1979-),男,博士,南京大学工程管理学院教授,主要研究方向为机器学习、智能机器人与量子控制等。
转载本文请联系原作者获取授权,同时请注明本文来自王晓科学网博客。 https://m.sciencenet.cn/blog-951291-1288193.html
上一篇:
[转载]基于深度强化学习算法的自主式水下航行器深度控制 下一篇:
科技抗疫——无人车新战场