# 编者信息 熊荣川 明湖实验室 xiongrongchuan@126.com http://blog.sciencenet.cn/u/Bearjazz Some caveats in the interpretation of these results are in order. First, the nucleotide divergence statistics describe the average pattern of molecular evolution. Individual codons may, in many cases, deviate substantially from the norm. Second, for gene pairs with S 1, potentially large inaccuracies in the estimates of nucleotide divergence are expected to result from multiple substitutions per site. Nevertheless, as can be seen in Fig. 1, the patterns that we describe are fully apparent within the subset of gene duplicates with S 1. Third, although we have taken special precautions to avoid the inclusion of nonfunctional gene duplicates in our analyses (21), in the absence of actual expression pattern data, we cannot be certain that all of the genes we have included are functional. However, the fact that most of the pairs that we have identified have R/S 1 and that many pairs with small S have R/S 1.0 suggests that we have not inadvertently included many pseudogenes in our analyses. 对这些结果的解释有些警惕是合理的。首先,核苷酸分异统计描述了分子进化的一般模式。在许多情况下,个别密码子可能实质上会偏离正常。第二,对于 S1 的基因对,估计核苷酸差异的潜在大误差预计是由每个位点的多次替换引起的。然而,如图 1 所示,我们所描述的模式在 S1 的基因重复子集中是很明显的。第三,尽管我们已经采取了特别的预防措施,以避免在我们的分析( 21 )中包含非功能基因重复,但在缺乏实际表达模式数据的情况下,我们不能确定我们所包含的所有基因都是功能性的。然而,我们发现的大多数重复基因的 R/S 1 ,极小重复基因的 R/S 1.0 表明我们在我们的分析并没有在无意中包含许多假基因。 Lynch, M. The Evolutionary Fate and Consequences of Duplicate Genes . Science, 2000, 290(5494):1151-1155.
时间序列(time series)学习书籍 大数据(big data)的主要形式是“时间序列”,当然也有别的形式。 大数据的5V特点(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。 (1)应用时间序列分析,著者: 王燕编著,出版社: 中国人民大学出版社,出版日期: 2015 (2)时间序列分析的工程应用,著者: 杨叔子, 吴雅, 轩建平等著,出版社: 华中理工大学出版社,出版日期: 2007 (3)时间序列分析与动态数据建模,著者: 杨位钦,顾岚编著,出版社: 北京理工大学出版社,出版日期: 1988 (4)时间序列分析:预测与控制:第三版,著者: (美)George E.P.Box, (英)Gwilym M.Jenkins, (美)Gregory C.Reinsel著,出版社: 中国统计出版社,出版日期: 1997 (5)时间序列分析:预测与控制:forecasting and control,著者: (美) 乔治 E. P. 博克斯, (英) 格威利姆 M. 詹金斯, (美) 格雷戈里 C. 莱因泽尔著,出版社: 机械工业出版社,出版日期: 2011 (6)非线性时间序列:建模、预报及应用,著者: 范剑青, 姚琦伟著,出版社: 高等教育出版社,出版日期: 2005 相关资料: 时间序列_百度百科 https://baike.baidu.com/item/%E6%97%B6%E9%97%B4%E5%BA%8F%E5%88%97/1389644?fr=aladdin Time series. I.A. Ibragimov (originator), Encyclopedia of Mathematics. https://www.encyclopediaofmath.org/index.php/Time_series Time series, In statistics: Time series and forecasting https://www.britannica.com/science/statistics/Residual-analysis#ref367512 Time series, In automata theory: The automaton and its environment https://www.britannica.com/topic/automata-theory/Probabilistic-questions#ref383510 Time Series, International Encyclopedia of the Social Sciences https://www.encyclopedia.com/science-and-technology/mathematics/mathematics/time-series Time Series Analysis, Encyclopedia of Sociology https://www.encyclopedia.com/social-sciences/encyclopedias-almanacs-transcripts-and-maps/time-series-analysis 大数据相关资料: 大数据_百度百科 https://baike.baidu.com/item/%E5%A4%A7%E6%95%B0%E6%8D%AE/1356941?fr=aladdin IBM,Big data analytics https://www.ibm.com/analytics/hadoop/big-data-analytics SAS US,Big Data https://www.sas.com/en_us/insights/big-data/what-is-big-data.html Big Data Analytics - Time Series Analysis https://www.tutorialspoint.com/big_data_analytics/time_series_analysis.htm Encyclopedia of Big Data, Editors: Schintler, Laurie A., McNeely, Connie L. (Eds.) https://www.springer.com/us/book/9783319320090 相关链接: 2016-09-01,Crosswavelet and Wavelet Coherence 小波分析的程序网址 http://blog.sciencenet.cn/blog-107667-1000091.html 2016-09-01,支持向量机 Support Vector Machine 程序网址 http://blog.sciencenet.cn/blog-107667-1000087.html 2017-07-12,欧洲中期天气预报中心 ECMWF 网址 http://blog.sciencenet.cn/blog-107667-1065890.html 2018-08-26,估计 Largest Lyapunov exponent 的 matlab 程序搜集(网址) http://blog.sciencenet.cn/blog-107667-1131215.html 2017-07-11,布拉德利·埃弗龙(Bradley Efron):2005年美国国家科学奖章得主(统计学) http://blog.sciencenet.cn/blog-107667-1065714.html 感谢您的指教! 感谢您指正以上任何错误! 感谢您提供更多的相关资料!
我的教材来自于已经发表的文章。我喜欢用牛刊。 http://science.sciencemag.org/content/362/6419/1091 For China, a CRISPR first goes too far 1. Dennis Normile See all authors and affiliations Science 07 Dec 2018: Vol. 362, Issue 6419, pp. 1091 DOI: 10.1126/science.362.6419.1091 Summary The report of the live birth of twin baby girls with genetically engineered genomes caused an uproar around the world. Some of the criticism focused on China's allegedly permissive research ethics. Chinese scientists resent that characterization, but the incident has set off debate within the country over its regulation of biomedical research. The researcher, He Jiankui of the Southern University of Science and Technology in Shenzhen, China, allegedly violated a provision in a regulation that came into effect in 2003, long before gene editing became a common research tool. China's scientists and ethicists are now calling for new or revised regulations. But some researchers fear a backlash provoked by one group that deliberately ignored existing regulations could result in new rules that will burden even ethical scientists. 标题:主语= a CRISPR first。把For China放在句首,显然是“矛头”直指中国! [1] 主语= The report of the live birth of twin baby girls with genetically engineered genomes 我不喜欢长主语。我也不觉得“the report”是最好的选择。我觉得“live birth”的live是“蛇脚”(多余的)。这次birth如果是“死的”,我们现在不会“热血沸腾”。 [2] 学习一下 China's(比如 Zhang’s) [3] 学习一下 that characterization (not this, but that)和the incident。 [4] 学习一下 in Shenzhen, China, (两个逗号,都是我的朋友)。He Jiankui是姓在先,说明他足够出名了。学习用long before。 [5] 有意思,用China's, 而不是Chinese。用for new or revised(regulations), 说明作者不知道中国有没有regulations? [6] 我不喜欢用But开头,但是(but),历史的潮流不是我能阻挡的。 学习一下 could result in。 你也可以参加讨论。 如果你也想提高科技英语写作能力,请跟我来... http://blog.sciencenet.cn/blog-306792-1146577.html
Crosswavelet and Wavelet Coherence 小波分析的程序网址 http://noc.ac.uk/using-science/crosswavelet-wavelet-coherence 1. Theory Our paper describes the theory behind cross wavelet and wavelet coherence, starting from the basics of the Continuous Wavelet Transform: Application of the cross wavelet transform and wavelet coherence to geophysical time series. The Frequently asked questions section below contains some very good information, and we highly recommend the paper by Torrence and Compo, A practical guide to wavelet analysis, if you're completely new to wavelet analysis. (Also see Links for other resources.) 2. Example of how to use the package 3. Download the wavelet coherence package Copyright 2016 The National Oceanography Centre (NOC), the Natural Environment Research Council (NERC) or the University of Southampton owns copyright of the material available at this site, unless otherwise stated. All rights reserved. 感谢您提供更多的可下载程序! 感谢您的指教! 感谢您指正以上任何错误!
几个标准中的危险源(hazard)定义及分析 一、DEPARTMENTOF DEFENSE STANDARD PRACTICE-SYSTEM SAFETY(MIL-STD-882E,11 May 2012)对危险源的定义 ( 红色字体 为作者的注释) : 3.2.14 Hazard. A real or potentialcondition that could lead to an unplanned event or series of events (i.e.mishap) resulting in death, injury, occupational illness, damage to or loss of equipmentor property, or damage to the environment. ( hazard是 现实明确存在或者潜在的导致事故的因素,即明确或者潜在的事故原因。在 这个 标准里hazard主要指物态,没提到人的行为因素,但也没有排除人的行为因素 ) 二、煤矿安全风险预控管理体系-规范( AQ/T1093-2011)根据GB/T28001-2001定义3.4]定义的危险源: 危险源(hazard):可能导致伤害或疾病、财产损失、工作环境破坏或这些情况组合的根源或状态。 而 GB/T28001-2001的更新版 GB/T28001-2011 《职业健康安全管理体系-要求》在3.6节已经将危险源的定义改为“可能导致人身伤害和(或)健康损害的根源、状态或行为,或其组合”。GB/T28001-2011仅仅是BS-OHSAS18001:2007的汉译而已,“根源”一词的使用并不恰当。 三、 OCCUPATIONALHEALTH AND SAFETY ASSESSMENT SERIES(BS-OHSAS18001:2007)关于危险源的定义: 3.6 hazard source, situation, or act with a potentialfor harm in terms of human injury or ill health (3.8), or a combination of these.( source 没有根源的意思,理解为“来源”更确切,事故的来源也就是事故原因 ) 四、 ISO/DIS45001:2016(E) 没有专门定义危险源,但是在危险源识别一节,说了在很多方面识别危险源,其实就是很多的事故原因,也就是说,事故原因就是危险源。详细列出: 6.1.2.1 Hazard identification Theorganization shall establish, implement and maintain a process for the on-goingproactive identification of hazards arising. The process shall take intoaccount but not be limited to: a) routine and non-routineactivities and situations, including consideration of: 1) infrastructure,equipment, materials, substances and the physical conditions of the workplace; (物体或物质方面,即物方面) 2) hazards that arise asa result of product design including during research, development, testing, production,assembly, construction, service delivery, maintenance or disposal; ( 设计、研发、测试等过程中产生的危险源,可以看作是管理程序或者技术管理程序(方案)缺欠。这些程序的结果是不安全 物态 或者 不安全的 操作方案,分别归为不安全物态和管理体系的缺欠) 3) human factors; (人的因素,归为 5 个习惯性不安全行为中的一个或者几个、不安全动作) 4) how the work isactually done; (归为某种个人行为) b) emergency situations; (紧急情况下的做法,属于个人行为或者组织行为或者物态) c) people, including considerationof: (归为行为或者物态) 1) those with access tothe workplace and their activities, including workers, contractors, visitors andother persons; 2) those in the vicinityof the workplace who can be affected by the activities of the organization; 3) workers at a locationnot under the direct control of the organization; d) other issues, includingconsideration of: (归为某种行为或者物态) 1) the design of workareas, processes, installations, machinery/equipment, operating procedures andwork organization, including their adaptation to human capabilities; 2) situations occurringin the vicinity of the workplace caused by work-related activities under the controlof the organization; 3) situations notcontrolled by the organization and occurring in the vicinity of the workplacethat can cause work-related injury and ill health to persons in the workplace; e) actual or proposed changes inthe organization, its operations, processes, activities and OHS managementsystem (see 8.2); 属于 管理体系缺欠 f) changes in knowledge of, andinformation about, hazards; 知识和信息(实际也是知识)危险源 g) past incidents, internal orexternal to the organization, including emergencies, and their causes; 属于识别方法 h) how work is organized and socialfactors, including workload, work hours, leadership and the culture in theorganization . 影响因素,归为某种行为或者物态 五、分析结论:( 1 )危险源 =事故来源= 事故原因;( 2 )事故的各种原因(各层面的不安全行为 + 不安全物态)都是危险源;( 3 )标准(国际范围内很多个人和组织的综合意见)的定义比有关学者的的定义(个人意见)更具有学术意义、实践意义。
现阶段警用地理信息系统应用平台的建设和使用,使空间统计、数据挖掘等方法更多的应用在实际工作中,其中对案件的时空分析属于系统的核心部分,可以大大提高警情分析和预报的效率。 案事件时空分析的总体流程:从公安部门积累的案事件及其他相关业务数据出发,主要从三个方面加以考虑。首先针对案事件的时间 / 空间属性,探测案事件时空集聚性,并利用可视化方法生成犯罪热点图;第二个是进行相关分析,结合人口、场所、环境等分析影响因素;第三个方面是进行犯罪变化趋势的预测。这三个分析目标又支撑起了决策层面的各项工作。在这个流程中聚类分析和预测分析是难点。 图 1 案事件时空分析的总体流程 针对案事件数据,从时间、空间两方面入手,围绕案件高发的特定时段、区域、类别,及时准确地研判各类信息,发出预警处置通报,指令和督导发案地派出所调整警力打防。从 时间 这个角度,我们可以通过例如雷达图、等值区域图来反映一天内犯罪数量和周内各天犯罪数量的变化。从 空间 这个角度,在 不同维度 下,可以将犯罪热点地图表示类型分为热点地点、热点街道、热点地区(均质、分级)。 不同空间单元 下案件点图、趋势椭圆图、行政单元统计图、格网统计图、 KED 密度图。从 时空综合 热点这个角度下,通过地图与数据图表联动分析、对时空立方体的切片、时空棱镜的投影获得犯罪热点的时空变化特征。 图 2 不同角度 / 维度 / 单元下的犯罪表达 参考文献: PorterM D, Reich B J. Evaluating temporally weighted kernel density methods forpredicting the next event location in a series . Annals of GIS, 2012, 18(3):225-240. Eck JE, Chainey S P, Cameron J, et al. Mapping Crime: Understanding hotspots .Washington DC: National Institute of Justice, 2005. JohnsonS D, Bernasco W,Bowers K J, et al. SpaceTime Patterns of Risk: A Cross NationalAssessment of Residential Burglary Victimization . Journal of QuantitativeCriminology,2007,23(3):201-219. ChaineyS,Tompson L,Uhlig S.The utility of hotspot mapping for predicting spatialpatterns of crime . Security Journal,2008,21(1-2):4-28. NakayaT, Yano K.Visualising Crime Clusters in a Space-time Cube: An ExploratoryData-analysis Approach Using Space-time Kernel Density Estimation and ScanStatistics .Transactions in GIS,2010,14(3):223-239. TownsleyM. Visualising space time patterns in crime: the hotspot plot . Crimepatterns and analysis, 2008, 1(1): 61-74. Liu Q,Deng M, Shi Y, et al. A density-based spatial clustering algorithm consideringboth spatial proximity and attribute similarity . Computers Geosciences, 2012, 46: 296-309.
我是参照 第20120723期集结号-转录组测序分析中cufflinks的使用及问题 和 如何将几个不同的基因组注释文件合并起来 的方法进行转录组分析, 但我用中间产生的的gtf文件上传到UCSC,提示错误“ Error File 'slim.norandom.gtf' - GFF/GTF group NM_009362 on chr17-, this line is on chr5-, all group members must be on same seq and strand ” 此报错提示我的gtf格式出错了!! 于是我查看gtf文件,发现如下: 恍然大悟, 一个NM_009362号居然对应了多个位置 。 于是我又查看我的下载的refseq注释,发现其中居然有 4482重复的NM号。 这太坑人了。refseq居然提供的数据这么不人性化,既然NM_009362有两个duplicate,就应该加个标识NM_009362.1NM_009362.2 没办法,只能从来一摸子, 事先对下载的refseq进行了重命名操作 。命令如下: sort -t $'\t' -k 4,4 refseq.bed | awk -F "\t" '{if(it!=$4){i=0;it=$4;} else { i++;$4=$4"_dup"i;}OFS="\t" ;print $0; }' 这样再进行后序分析,一切OK!!
一篇Nature Method上一篇关于RNA-seq数据分析的文章,觉得很不错,里面还介绍了一些关于可变剪接的问题。下面列上列上的基本信息: Computational methods for transcriptome annotation and quantification using RNA-seq Manuel Garber, Manfred G Grabherr, Mitchell Guttman Cole Trapnell High-throughput RNA sequencing (RNA-seq) promises a comprehensive picture of the transcriptome, allowing for the complete annotation and quantification of all genes and their isoforms across samples. Realizing this promise requires increasingly complex computational methods. These computational challenges fall into three main categories: (i) read mapping, (ii) transcriptome reconstruction and (iii) expression quantification. Here we explain the major conceptual and practical challenges, and the general classes of solutions for each category. Finally, we highlight the interdependence between these categories and discuss the benefits for different biological applications. 全文链接:http://www.nature.com/nmeth/journal/v8/n6/full/nmeth.1613.html 复制代码 下面是在科学网上找到的一篇对该文章的点评和分析,附上全文,供大家参考阅读。 高通量RNA测序(RNA-seq)有望描绘出转录组的整体图像,实现样本内所有基因及其亚型的完整注释和定量。随着测序价格的不断下降,以及个人化测序仪的上市,更多的实验室有机会尝试这种新技术。 然而,测序之后的数据分析才是真正的挑战。在RNA-seq之后,还需要一些强大的计算工具,才能绘制出完整的转录组图谱。在这一期的《自然—方法学》(Nature Methods)上,来自MIT和哈佛Broad研究院的研究人员发表了一篇综述,介绍了转录组注释和定量的计算方法。 首先,他们介绍了一些方法,将读数与参考转录组或基因组直接比对。之后,他们讨论了鉴定表达基因和亚型的方法。最后,他们还介绍了一些方法,来预计基因和亚型的丰度,以及分析样品间的差异表达。 由于RNA-seq数据生成的不断改善,现有计算工具的发展有着很大差异。在某些领域,如读数定位,有多种算法存在,但在差异表达分析上,解决方案才刚刚出现。作者们强调了这些方法的核心原理和每种方法的关键差异,以及它们在RNA-seq分析上的应用。他们还讨论了这些不同的方法如何影响结果以及数据的阐释。 为了方便读者参考,他们还将现有的方法列成了一张表,注明了它们的原理和用途。另外,他们精选了一些有代表性的方法,应用在已经发表的RNA-seq数据组中。此数据组包含了5800万个末端配对的读数。 数据比对是RNA-seq分析中的一项基本任务,然而也面临着一些挑战,比如数据量大,读数很短(36-125 bp),错误率可观,且许多读数跨越外显子-外显子交界。对于RNA-seq的比对方法,作者将其分成“unspliced read aligners”和“spliced aligners” 两类,并分别介绍。 转录组重建也是个很困难的任务,因为基因表达差异很大,且读数可能来源于成熟的mRNA,也可能来源于未完全剪接的前体RNA,这样就很难鉴定成熟的转录本。当然,读数短也为分析带来了困难。目前的转录组重建方法主要有两类,一类是基因组指导的,另一类是不依赖于基因组的。作者比较了这两类方法,并具体介绍了每一类下面的几种方法。 至于转录组的图谱分析,DNA芯片一直是首选方法。在使用RNA-seq来估计基因表达时,需要将读数适当地标准化,才能提取出有意义的表达预测值。作者介绍了一些方法,来预计基因和亚型的丰度,以及分析样品间的差异表达。 作者还提到,随着测序技术的成熟,如读长不断增加,现有的计算工具需要发展,也能满足新的需求,同时新工具也会不断出现,满足新的应用。 http://seq.cn/forum.php?mod=viewthreadtid=2643
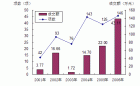
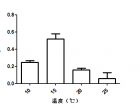
最近要处理数据,又要面对噪杂的数据,真是头疼。 有对照组吧,差异显著(P0.05),就标个星星,倒也简单。 没有对照组,两两比较,要用 a ab b来标,真是受不了啊。 难道就没有软件能直接做出这个a b么 记得之前处理数据,先用spss分析差异,先的到sig值,再求SSR, 然后在excel对数据从大到小排序,再代入SSR检验。 最后最后,再在word输入a ab b bc c 表示出来。 我就是嫌麻烦,可我就是在网上找不到一个“很明白很直接”得到数据差异的方法。 难道真没这么个软件吗? 为什么就不能直接点呢? 我要知道我的数据有木有显著差异,我不想spss后再excel再word,就是这样。 以上图为例,之前做数据时候,不是最高的柱子(最大数据)标a么。 为啥有的人不加选择在第一个柱子标a 是我糊涂了,还是目前的数据分析错综复杂呢
头部是中枢神经系统即大脑所在部位,交通、体育运动等领域事故及航空救生中损伤种类研究表明头部损伤是导致人体重伤甚至死亡的主要原因之一。而大自然中的啄木鸟,啄木时其瞬间加速度可高达1000~2000g,每次撞击频率18-22赫兹,每天可撞击12,000次,但在这过程中它却能“毫发无损”。在10月26日出版的网络版美国学术杂志《公共科学图书馆》上(PLoS ONE,6(10):e26490),北京航空航天大学生物医学工程学院“生物力学与力生物学”教育部重点实验室樊瑜波教授的团队揭开了啄木鸟能够高速撞击树干而不受损伤的秘密(发表论文Why Do Woodpeckers Resist Head Impact Injury: A Biomechanical Investigation),该研究发表后立即引起国际科学技术媒体的广泛关注。 经过两年的研究,该课题组利用运动生物力学观测、解剖形态学、材料力学特性分析、有限元应力分析等方法全面分析了啄木鸟撞击树干的过程。该研究全面、深刻、系统地解释了啄木鸟在高速撞击下无损伤的科学原理。该研究比较了啄木鸟及具有类似啄食特点的其他鸟在啄物过程中头部运动方式的差异,发现啄木鸟头部不仅具有线性加速度,还伴有旋转加速度;通过形态学观测手段,发现啄木鸟上下喙部结构具有不等长的特点,其下喙坚硬承载部分比上喙长1.2毫米,这使得撞击时的应力可集中于下颚,从而避免了撞击力转递到脑部造成脑损伤。研究发现啄木鸟特殊的舌骨能够有效地减缓其颈椎受伤风险,啄木鸟舌骨自其鸟喙下侧开始、左右分叉绕到颅骨后侧、延伸到上方,并在前额前方再度交会。啄木鸟啄树干的过程中,不仅需要用力向前撞击,头部向后摆动时的速度、加速度也非常大,而特殊的舌骨此时就好像是“安全带”,有效地避免了颈椎向后折断。此外,Micro-CT扫描显示,啄木鸟颅骨有不同于其它鸟类的海绵状的骨小梁,可使颅骨更有“弹性”,啄木鸟头骨的特殊形态结构可以有效地缓冲撞击。对于啄木鸟头部抗冲击的生物力学机制的深入研究将有助于交通事故、航空救生等领域人体头部冲击性损伤机制的认识及防护措施、设备的改进。
中承式拱桥的缺点分析与补救措施/张师定2011-07-15 22:23最近有好几座桥梁(钱塘江三桥引桥、武夷山公馆大桥、株洲高架桥、库尔勒孔雀河大桥、上虞立交桥、呼兰河大桥、凤凰大桥、綦江虹桥等,还有许多在建桥梁坍塌,许多桥梁建成后因内力及线形与设计预想差别较大而成危桥)接连坍塌,暴露出许多问题,而对于其中几座中承式拱桥的坍塌,出于对社会的负责,我做一些初步分析,供大家参考。 1、中承式拱桥的缺点 A 中承式拱桥缺纵梁,致使在轮载作用下,横梁顺桥向不断扭转; B 不断扭转致吊杆疲劳断裂; C 中承式拱桥“悬吊区”与“支撑区”过渡吊杆疲劳问题最严重; D 施工中很难保证吊杆轴线与锚固导管位于同一直线、且是铅垂线上,转折引起应力集中,疲劳问题更严重。 E 中承式拱桥悬吊桥面系顺桥向为几何可变体系,这是不允许的。 2、中承式拱桥的补救措施 A 设置纵梁,连接各横梁,可有效分散轮载,提高横梁的顺桥向抗扭能力,减少吊杆疲劳; B 设双吊杆(顺桥向),可提高横梁的顺桥向抗扭能力,减少吊杆疲劳,另外,方便吊杆更换; C 建议采用有钢管保护的吊杆(内填充水泥浆,保证饱满),形成刚性吊杆; D 对于已建成的桥梁,建议加设钢纵梁! E 为防止重型车辆对桥梁的伤害,建议桥面现浇层混凝土由现在的一层钢筋网改为设置两层钢筋网! F 加强施工控制,保证吊杆的垂直贯通! G 在措施未到位时,可实行禁止设计中承式拱桥! 另外,建议禁止设计砌体桥梁,禁止设计素混凝土桥梁!,避免采用大悬臂(因桥梁承受荷载大,避免潜在危险、维持稳定)!
简介一本书――《凭借情报分析学开展竞争》 武夷山 2007 年 3 月,哈佛商学院出版社推出了著名学者 Thomas H. Davenport (其《信息技术的商业价值》已有中译本)和 Jeanne G. Harris 合写的著作 Competing on Analytics: The New Science of Winning ( 凭借情报分析学开展竞争:关于竞争制胜的新学科)。众多媒体都发表了对此书的好评。比如,澳大利亚《普罗米修斯》杂志 2007 年第 3 期就发表了英国开放大学商学院讲师 Caroline Emberson 女士的书评。 情报分析学的定义是:广泛利用数据、统计分析和定量分析、解释模型和预测模型以及基于事实的管理来驱动决策和行动的一门学问。 我个人觉得:情报分析学就是竞争情报学和信息计量学的交集。 该书目录如下: 序 ForewordGary Lovemanix 鸣谢 Acknowledgmentsxiii 第一部分 竞争情报分析的性质 The Nature of Analytical Competition 1. 竞争情报分析的性质:利用情报分析学打造独特的能力 The Nature of Analytical Competition: Using Analytics to Build a Distinctive Capability 2. 具有情报分析能力的竞争者是什么样子的:此类公司的共同关键特征 What Makes an Analytical Competitor?: Defining the Common Key Attributes of Such Companies 3. 情报分析学与企业绩效:将利用情报分析学开展竞争能的力转化为持久的竞争优势 Analytics and Business Performance: Transforming the Ability to Compete on Analytics into a Lasting Competitive Advantage 4. 将竞争情报分析学应用于内部过程:在财务、生产、研发和人事等方面的应用 Competing on Analytics with Internal Processes: Financial, Manufacturing, RD, and Human Resource Applications 5. 将竞争情报分析学应用于外部过程:在客户和供应商方面的应用 Competing on Analytics with External Processes: Customer and Supplier Applications 第二部分 打造情报分析能力 Building an Analytical Capability 6. 加强情报分析能力的路线图:通过 5 个步骤循序渐进 A Road Map to Enhanced Analytical Capabilities: Progressing Through the Five Stages of Development 7. (以下几章不列原文 -- 因为网上提供的目录原文就不全,只列中文译文)情报分析人才之管理:培育使情报分析学发挥作用的稀缺成分 8. 企业情报的构架:用稳健的技术环境支撑企业战略 9. 利用情报分析学开展竞争的未来:技术驱动、人本因素驱动和企业战略驱动的进路 这本书是立足于企业做文章的。其实,将之放大到国家层次上,情报分析学的基本构架不会有太大变化。 另外,博友 kafkasong 2011-11-17 11:17 告知: 这本书已经有中译本了,2009年商务印书馆出版,数据分析竞争法 = Competing on analytics 企业赢之道 (美) 托马斯·H.达文波特, 珍妮·G.哈里斯著 康蓉, 吴越译 eng 著者 达文波特 (Davenport, Thomas H.), 1954- 著 ISBN:9787100058759
今天的國際學術期刊《自然》,刊登了香港大學物理系郭新教授和張泳博士有關複雜有機物質在宇宙中廣泛存在的報告。報告提出,複雜有機物質並不一定源自生物,而是可以在太空中自然合成。 郭新和張泳發現一種在宇宙普遍存在的有機物質,當中含有混合芳香族(環狀)和脂肪族(線狀)的成份,其在化學結構上的複雜程度猶如煤和石油。由於煤和石油都是古生物的殘骸,這類有機物質向來被認為只能源於生物。這次的發現表明,複雜的有機物質能夠在無生命的太空中自然合成。 以往的觀測顯示恆星、星際雲和星系光譜中存在着不明紅外線輻射(UIE)。郭新和張泳對這一長期未能解釋的現象進行了研究。二十年來,研究者普遍認為多環芳香族碳氫化合物(PAH)份子很可能就是這些特徵譜線的載體。PAH是由碳和氫原子組成的簡單有機份子。然而郭新和張泳通過紅外線太空望遠鏡(Infrared Space Observatory)和史匹哲太空望遠鏡(Spitzer Space Telescope)的觀測數據發現PAH份子並不能解釋UIE所有的特徵。他們因而建議發射出這些紅外線輻射的物質有極為複雜的化學結構。通過新星爆發的星塵光譜分析,他們發現恆星在數星期的極短時間內製造出這些複雜的有機物質。 研究發現,恆星不僅生產這些有機物質,更將它們抛射出星際空間,這與郭教授過往有關恆星是製造有機物質的份子工廠的說法脗合。對於他們的發現,郭教授指出:「恆星能在幾乎真空的情況下高效地製造出複雜的有機份子,理論上這是不可能的,但根據我們的觀測卻是發生了。 最令人感興趣的是,這些有機星塵在結構上,跟隕石中找到的複雜有機物質相類似。由於隕石是早期太陽系的殘餘物質,這些發現令人聯想到恆星可能曾經播送有機物質到早期太陽系。地球在遠古時曾遭受彗星和小行星的嚴重撞擊,有機星塵有可能因此而被運載至地球。這些從外太空傳來的有機物質,在地球生命的發展中扮演了甚麼角色,仍是一個未知之數。
1 – An Introduction to Markov Chain Analysis (Lyndhurst Collins) – 2 – Distance Decay in Spatial Interactions (Peter J. Taylor) – 3 – Understanding Canonical Correlation Analysis (D. Clark) – 4 – Some Theoretical and Applied Aspects of Spatial Interaction Shopping Models (Stan Openshaw) – 5 – An Introduction to Trend Surface Analysis (David Unwin) – 6 – Classification in Geography (R. J. Johnston) – 7 – An Introduction to Factor Analysis (J Goddard A Kirby) – 8 – Principal Components Analysis (S. Daultrey) – 9 – Causal Inferences from Dichotomous Variables (N. Davidson) – 10 – Introduction to the Use of Logit Models in Geography (Neil Wrigley) – 11 – Linear Programming: Elementary Geographical Applications of the Transportation Problem (Alan Hay) – 12 – An Introduction to Quadrat Analysis (R. W. Thomas) – 13 – An Introduction to Time-Geography (Nigel Thrift) – 14 – An Introduction to Graph Theoretical Methods in Geography (K. J. Tinkler) – 15 – Linear Regression in Geography (R. Ferguson) – 16 – Probability Surface Mapping. An Introduction with Examples and Fortran Programmes (N. Wrigley) – 17 – Sampling Methods for Geographical Research (C. Dixon B. Leach) – 18 – Questionnaires and Interviews in Geographical Research (C. Dixon B. Leach) – 19 – Analysis of Frequency Distributions (V. Gardiner G. Gardiner) – 20 – Analysis of Covariance and Comparison of Regression Lines (J. Silk) – 21 – An Introduction to the Use of Simultaneous-Equation Regression Analysis in Geography (D. Todd) – 22 – Transfer Function Modelling: Relationship Between Time Series Variables (Pong-wai Lai) – 23 – Stochastic Processes in One Dimensional Series: an Introduction (K. S. Richards) – 24 – Linear Programming: The Simplex Method with Geographical Applications (James E. Killen) – 25 – Directional Statistics (Gary L. Gaile James E. Burt) – 26 – Potential Models in Human Geography (D. C. Rich) – 27 – Causal Modelling: The Simon-Blalock Approach (D. G. Pringle) – 28 – Statistical Forecasting (R. J. Bennett) – 29 – The British Census (J. C. Dewdney) – 30 – The Analysis of Variance (J. Silk) – 31 – Information Statistics in Geography (R. W. Thomas) – 32 – Centrographic Measures in Geography (Aharon Kellerman) – 33 – An Introduction to Dimensional Analysis for Geographers (Robin Haynes) – 34 – An Introduction to Q-Analysis (J. R. Beaumont A.C. Gatrell) – 35 – The Agricultural Census – United Kingdom and United States (G. Clark) – 36 – Order-Neighbour Analysis (Graeme Aplin) – 37 – Classification Using Information Statistics (R. J. Johnston R. K. Semple) – 38 – The Modifiable Areal Unit Problem (S. Openshaw) – 39 – Survey Research in Underdeveloped Countries (Chris Dixon Bridget Leach) – 40 – Innovation Diffusion: Contemporary Geographical Approaches (G. Clark) – 41 – Choice in Field Surveying (Roger P.Kirby) – 42 – An Introduction to Likelihood Analysis (Andrew Pickles) – 43 – The UK Census of Population 1981 (J. C. Dewdney) – 44 – Geography and Humanism (John Pickles) – 45 – Voronoi (Thiessen) Polygons (B. N. Boots) – 46 – Goodness-of-Fit Statistics (A. S. Fotheringham D. C. Knudsen) – 47 – Spatial Autocorrelation (Michael F. Goodchild) – 48 – Introductory Matrix Algebra (K. J. Tinkler) – 49 – Spatial Applications of Exploratory Data Analysis (David Sibley) – 50 – The Application of Nonparametric Statistical Tests in Geography (John Coshall) – 51 – The Statistical Analysis of Contingency Table Designs (L. G. O’Brien) – 52- A Classification of Geographical Information Systems Literature and Applications (I. Bracken, G. Higgs,D. Martin C. Webster) – 53 – An Introduction to Market Analysis (John R. Beaumont) – 54 – Multi-Level Models for Geographical Research (K. Jones) – 55 – Causal and Simulation Modelling Using System Dynamics (Ian Moffatt) – 56 – The UK Census of Population 1991 (David Martin) – 57 – Dynamic Analysis of Spatial Population Systems (Jianfa Shen) – 58 – Doing Ethnographies (Ian Cook Phil Crang) – 59 -Area Cartograms: Their Use and Creation (Daniel Dorling) –
A diverse bacterial community in a n anoxic quinoline-degrading bioreactor determined by using pyrosequencing and clone library analysis Zhang X , Yue S , Zhong H, Hua W, Chen R, Cao Y, and Zhao L . A diverse bacterial community in a n anoxic quinoline-degrading bioreactor determined by using pyrosequencing and clone library analysis. Applied Microbial and Biotechnology , 2011, 91:425–434. Abstract There is a concern of whether the structure and diversity of a microbial community can be effectively revealed by short-length pyrosequencing reads. In this study, we performed a microbial community analysis on a sample from a high-efficiency denitrifying quinolinedegrading bioreactor and compared the results generated by pyrosequencing with those generated by clone library technology. By both technologies, 16S rRNA gene analysis indicated that the bacteria in the sample were closely related to, for example, Proteobacteria, Actinobacteria, and Bacteroidetes. The sequences belonging to Rhodococcus were the most predominant, and Pseudomonas, Sphingomonas, Acidovorax, and Zoogloea were also abundant. Both methods revealed a similar overall bacterial community structure. However, the 622 pyrosequencing reads of the hypervariable V3 region of the 16S rRNA gene revealed much higher bacterial diversity than the 130 sequences from the full-length 16S rRNA gene clone library. The 92 operational taxonomic unit (OTUs) detected using pyrosequencing belonged to 45 families, whereas the 37 OTUs found in the clone library belonged to 25 families. Most sequences obtained from the clone library had equivalents in the pyrosequencing reads. However, 64 OTUs detected by pyrosequencing were not represented in the clone library. Our results demonstrate that pyrosequencing of the V3 region of the 16S rRNA gene is not only a powerful tool for discovering low-abundance bacterial populations but is also reliable for dissecting the bacterial community structure in a wastewater environment. 原文链接:http://www.springerlink.com/content/c763h26l28541v38/ PDF 原文下载: Zhang2011-AMB.pdf
台湾的陈达仁、黄慕萱老师将专利的检索类型归纳为四种:可专利性检索、专利侵权检索、技术现状检索、专利权利检索。 我个人将专利的检索的基本类型划分为三个部分:技术检索、权利检索、战略检索。 下面分别论述一下三个方面的区别。 一、技术检索: (一)检索目的:探索技术机会、规避重复技术、技术现状分析。 (二)专门检索字段: (51) International Patent Classification (52) Domestic or national classification (54) Title of the invention (56) List of prior art documents (57) Abstract or claim (58) Field of search (三)检索程度 根据检索目的的区别,检索程度有一定的区别。如探索性的技术机会发掘、技术现状分析,则可以更广的去检索文献、专利资源,这种情况下,专利引文可以作为很好的线索,另现状分析中也关注查全率;而避免重复技术则可能更强调检索的精确性。这可以通过组合检索(关键词+专利分类)来实现。 二、权利检索 (一)检索目的:了解专利权是否存续、谁是专利权人、是否存在专利侵权 (二)专门检索字段:专利持续时间( Maintenance), 专利权利人(Assignor),专利权利受让人(Assignee). (三)检索程度:精细检索、检索范围一般为专利,不涉及文献,但检索字段要超出专利文献数据( BIBLIOGRAPHIC DATA )的范畴,会扩展到技术持续期,技术权利转移等字段内容。 三、战略检索 (一)检索目的:兼并与收购;竞争态势分析;竞争对手知识产权管理策略 (二)专门检索字段:技术优先权信息;专利发明人;专利专利人;专利受让人;专利分类号;专利家族信息等 (三)检索程度:检索范围最大,包括专利、文献、标准、商业、财务信息等。检索字段也超出专利文献数据范围。
完备的内积空间称为 Hilbert 空间,需要注意的是,内积空间貌似没有涉及到距离(或范数),那么这里的完备性相对于什么而言呢?回顾欧氏空间中内积与距离(或向量长度)的关系不难发现,在一般的内积空间中同样有一个与内积密切相关的范数,这就是 ||x||=(x, x) 1/2 不难验证这是个范数,由此可见内积可以诱导一个范数,换句话说,内积空间是赋范空间。 如前文所说,一般线性距离空间或线性赋范空间中的几何非常复杂,可否在赋范空间中引入适当的内积使之成为内积空间呢?这样的内积当然不能胡乱构造,它与空间原有的赋范结构得是相容的,也就是说,范数与内积应满足等式 ||x||=(x, x) 1/2 。 这就需要我们找出内积与范数之间的关系,或者说,能够用范数表示这个内积,揭示这一关系的是著名的极化恒等式 x, y=(1/4)(||x+y|| 2 - ||x-y|| 2 + i||x+iy|| 2 – i||x-iy|| 2 ) 。 由此看来,赋范空间也是内积空间了,只需按照极化恒等式炮制一个内积即可。且莫盲目乐观,假如果真如我们所愿,也就不会有 Banach 空间与 Hilbert 空间之别了。在欧氏几何中向量长度之间不仅满足三角不等式,还满足平行四边形法则,直接计算不难发现由内积诱导的范数也满足平行四边形法则,即 ||x+y|| 2 + ||x-y|| 2 =2(||x|| 2 + ||y|| 2 ) 它是说:“平行四边形对角线长度平方之和等于四个边的边长平方之和”。因此,如果范数可以诱导出一个内积的话,这个范数必须满足平行四边形法则。遗憾的是,并非所有的范数都具有这个性质!你能举个例子吗?不满足平行四边形法则的范数不可能诱导一个内积,满足平行四边形法则的范数是否一定可以诱导一个内积?幸运的是,结论是肯定的。 内积空间蕴含了大量的特殊空间,最为广泛运用的是各种函数空间。回顾傅里叶分析中函数的三角级数展开,假设 f(x) 是 上的 Riemann 可积函数,则 f(x) 有傅里叶展开: f(x) ∽∑ n=- ∞ ∞ (a n cosnx+b n sinnx) 其中 a n =(1/ π ) ∫ - π π f(x)cosnxdx, b n =(1/ π ) ∫ - π π f(x)sinnxdx , n ≠ 0, a 0 =(1/2 π ) ∫ - π π f(x)dx 。如果用内积的语言来叙述,傅里叶系数 a n 、 b n 分别是函数 f(x) 与三角函数 cosnx 、 sinnx 的内积,即 a n =f(x), cosnx, b n =f(x), sinnx 。 如果我们的记忆没有问题,一定还记得微积分中几个积分式 cosnx , cosmx=0 , sinnx, sinmx=0,n ≠ m ; cosnx, sinmx=0 。 这就是说, {cosnx , sinnx} n=- ∞ ∞ 是相互直交的函数集合。 众所周知,即使 f(x) 是连续函数,其傅里叶级数也未必收敛到该函数,事实上,傅里叶级数的收敛性是个非常复杂的问题,需要一点专门的手段才能解决它,但如果限定在 L 2 ( ) 中考察,情况就简单多了,原因就在于 L 2 ( ) 是个 Hilbert 空间。 由于 Hilbert 空间中存在内积,所以研究 Hilbert 空间的一个基本想法是建立直角坐标系(在线性代数中叫正交基),在有限维欧氏空间中,只要找到一组最大线性无关组,就可以利用施密特正交化过程得到一个正交基。这个方法在一般的 Hilbert 空间中遇到了困难,因为空间中可能存在不可数多线性无关的向量,你如何将它们正交化?即使你找到了一组正交向量,如何判断它是否为正交基? 首先要弄清楚什么叫正交基,在有限维欧氏空间 R n 中,所谓正交基指的是一组满足下列条件的向量 {e i } i=1 n : (1) e i ⊥ e j , i ≠ j , ||e i ||=1; (2) 对任意 x ∈ R n ,存在 c 1 ,…,c n ∈ R ,使得 x=c 1 e 1 + … + c n e n 其中 c i 可以用内积来表示,即 c i =x,e i 。将这一概念推广到 Hilbert 空间的困难在于( 2 ),有人会说,这还不简单?大家都学过级数理论,用级数表示就是了。不要忘记微积分中讲的级数指的是最多可数个函数项之和,而在 Hilbert 空间中可能存在不可数个相互正交的向量,这就涉及到不可数个项之和的问题,即如果 M={e λ } λ∈Λ 是 Hilbert 空间中的正交向量构成的集合,级数∑ λ∈Λ c λ e λ 是什么意思(其中 c λ 是复数)?受有限维空间的启发,对任意 x ∈ H ,也可以令 c λ =x,e λ ,级数∑ λ∈Λ x,e λ e λ 有意义吗?它与 x 是什么关系?两者是否相等?有意思的是,可以证明在这个级数中,最多只有可数多个 x , e λ 不等于 0 。因此只需考察该级数的收敛性以及与 x 的关系,假如对 H 中的任意向量 x ,等式 x= ∑ λ∈Λ x,e λ e λ 皆成立,则可以称 M 为 H 的一个正交基,上述级数也称为 x 的傅里叶级数。这样的 M 是否存在?如何判断空间的一个正交集是否为正交基?证明任何 Hilbert 空间均有正交基需要利用所谓的超穷归纳法,在实变函数《说课》系列中介绍过这一方法,大家不妨一试。 判断 Hilbert 空间中一个正交向量集 M 是否为正交基的基本方法是判断空间中是否有与该正交集中所有向量都正交的非零向量,如果有, M 显然不是正交基,如果没有, M 就是个正交基。还有一个方法是通过 Hilbert 空间中向量的范数与其“傅里叶系数”的关系来判断。在欧氏空间中,如果 x=c 1 e 1 + … +c n e n ,则 ||x||=(|c 1 | 2 + … +|c n | 2 ) 1/2 ,在 Hilbert 空间中是否有类似的等式?这就是著名的巴塞佛公式,即 M ={e λ } λ∈Λ 是正交基当且仅当对任意 x ∈ H ,巴塞佛公式: X=( ∑ λ∈Λ |x,e λ | 2 ) 1/2 成立。
番茄果实的发育可以分为四个主要时期:座果期、细胞分裂期、细胞体积扩展期和成熟期。而前三个时期是决定果实最终大小和形状的关键时期。目前已克隆的几个控制番茄果实大小和形状的QTL位点中 fw2.2, ovate, fasciated 均在开花前决定了表型,最近克隆的 SUN 主要在开花后起作用 1, 3 。但这些基因的作用机理多不清楚。总的来说,我们对番茄早期果实生长和发育(细胞分裂期前后)的认识还非常缺乏。利用组学手段,我们鉴定出了大量在番茄果实早期发育过程中特异表达的基因 3 。我们拟通过功能分析,重点研究几个转录因子在番茄果实早期生长发育过程中的作用,以增加对番茄果实早期发育的新认识。 Jiang N., Gao D., Xiao H. , van der Knaap E. (2009) Genome organization of the tomato sun locus and characterization of the unusual retrotransposon Rider. Plant J . 60(1):181-193 Xiao H*. , Radovich C*., Welty N*., Hsu J., Li D. Meulia T., van der Knaap E. (2009) Integration of tomato reproductive developmental landmarks and expression profiles, and the effect of SUN on fruit shape. BMC Plant Biology . 9:49. (*, co-first author) Xiao H*. , Tang J*., Li Y*., Wang W., Li X., Jin L., Xie R., Luo H., Zhao X., He G., Zhu L. (2009) STAMENLESS 1, encoding a zinc finger protein of C2H2 type, regulates rice floral organ identity. Plant J . 59(5):789-801. (*, co-first author) Xiao H. , Jiang N., Schaffner E., Stockinger EJ., van der Knaap E. (2008) A retrotransposon-mediated gene duplication underlies morphological variation of tomato fruit. Science . 319:1527-1530 (cover story)
一般泛函分析教材通常是在介绍了线性距离空间后便介绍这些空间上的算子,然后再定义内积与内积空间,继而研究内积空间上的算子。我觉得将线性距离空间与内积空间放在同一章处理或许更自然一些。 有人说泛函分析是有限维线性空间及其线性变换在无限维空间的推广,从空间与变换的定义角度讲,此言不无道理。不过话说回头,任何抽象概念都非空中楼阁,就说这抽象代数,你要说“群运算”是小学生学过的加法运算的推广又有何不可?问题是两者可以相提并论吗?回到线性距离空间与线性赋范空间,线性空间(也称向量空间)是有限维向量空间的推广,然而两者有质的不同,其主要差别表现在两个方面,一是两者适用的对象不可同日而语,无限维线性赋范空间涵盖了非常广泛的各类数学与物理问题,微分方程、积分方程、傅里叶分析等均可纳入到泛函分析中。二是无限维空间中出现了许多与有限维空间不同的现象,例如欧氏空间中重要的聚点原理、有限覆盖原理等在无限维线性距离(赋范)空间中不再成立了。我们知道这些原理在函数及方程研究中起着举足轻重的作用,离开了它们,很多问题寸步难行,为了解决这些问题,不得不引入一些新的概念:“列紧集、紧集”等。 有了向量的范数与向量间的距离,可以像欧氏空间那样定义点列的收敛性、开集、闭集等概念(这些将在后面作介绍),但仅仅依靠距离或范数来研究几何是很艰难的。事实上, Banach 空间(完备的线性赋范空间)几何理论迄今为止也远没有完善,很多基本问题悬而未决。这些空间上的几何之所以困难,一个很重要的原因是不像在有限维空间中可以借助基底(相当于几何上的坐标系)来研究。我们知道,解析几何之所以成功,得益于笛卡尔坐标系,而笛卡尔坐标系的出现得益于“角”的概念,正是在平面或空间中两个向量有夹角的概念,才可以定义直角坐标系。有了夹角概念,就可以定义向量间的许多运算:“内积、叉积、混合积”等。然而,将这些概念推广到高维欧氏空间却是反过来做的,因为在高维空间中没有角的概念,但我们从内积的定义可以看出,这个运算与两个向量的角度有关系,即: cos α =x, y/||x||||y|| 。 其中 α 表示向量 x 与 y 的夹角, x, y 是 x 与 y 的内积, ||x|| , ||y|| 分别是 x 与 y 的“长度”(模或范数)。虽然在高维空间中没有角度概念,但可以定义内积与向量的“长度”,从而利用上面的关系式来定义两个向量的“夹角”,可以看到 x 与 y 垂直(夹角为 π /2 )的充要条件是它们的内积等于 0 。利用施密特正交化过程可以将任意一组基底变成正交基(直角坐标系),通过这个正交基,空间中的几何问题可以代数化,这正是解析几何的基本思想。现在很多教材将解析几何与线性代数合二而一并不是什么创新,它们本来就是血脉相承的。 有了从平面与三维空间中角度概念到高维空间的推广就不难理解为什么要在更一般的向量空间中定义内积了。就内积定义本身而言,没有什么令人费解之处,我们只要将有限维空间中内积的概念抽象出来便可以得到一般空间中的内积概念,换句话说,完全可以通过公理化的方法来定义内积: 定义 :假设 X 是复数域(或实数域)上的线性空间, . , . 是 X × X 到复数域 C 的映射,如果它满足: ( 1 ) x, x ≥ 0 ,且 x, x=0 当且仅当 x=0 ; ( 2 ) x+y , z=x , z+y , z , x, y, z ∈ X ; ( 3 ) α x, y= α x, y , α∈ C , x , y ∈ X ; ( 4 ) x , y=\bar{y ,x } , x, y ∈ X ; 则称 . , . 为 X 上的内积,( X , . , . )称为复数域上的 内积空间 。 有了内积的概念,自然知道如何定义两个向量的直交与正交概念,不过事情远没有解决,内积空间是否完备?如何完备化?内积空间与赋范空间有什么关系?如何定义空间的正交基?是否每个内积空间中都能找到正交基?欲知答案如何,且听下回分解。
美國副總統拜登九月七日在美國《紐約時報》網站發表《中國的崛起並不是美國的覆滅》一文,細讀之下,有些常識性的分析令人振聾發聵。例如文中說:「二十一世紀一個國家的真正財富在於國民的創新精神和創造力。」「我們的實力要歸功於我們的政治和經濟制度,以及我們教育孩子的方式。」「眼下看來,美國的強項就是中國的弱項。」確實如此,這種軟實力的巨大差距,隨著時間的推移,就要凸顯其真正的硬實力,使得中共在和平競爭中不戰自敗。 China’s Rise Isn’t Our Demise By JOSEPH R. BIDEN Jr. I FIRST visited China in 1979, a few months after our countries normalized relations. China was just beginning to remake its economy, and I was in the first Senate delegation to witness this evolution. Traveling through the country last month, I could see how much China had changed in 32 years — and yet the debate about its remarkable rise remains familiar. Then, as now, there were concerns about what a growing China meant to America and the world. Some here and in the region see China’s growth as a threat, entertaining visions of a cold-war-style rivalry or great-power confrontation. Some Chinese worry that our aim in the Asia-Pacific is to contain China’s rise. I reject these views. We are clear-eyed about concerns like China’s growing military abilities and intentions; that is why we are engaging with the Chinese military to understand and shape their thinking. It is why the president has directed the United States, with our allies, to keep a strong presence in the region. As I told China’s leaders and people, America is a Pacific power and will remain one. But, I remain convinced that a successful China can make our country more prosperous, not less. As trade and investment bind us together, we have a stake in each other’s success. On issues from global security to global economic growth, we share common challenges and responsibilities — and we have incentives to work together. That is why our administration has worked to put our relationship on a stable footing. I am convinced, from nearly a dozen hours spent with Vice President Xi Jinping, that China’s leadership agrees. We often focus on Chinese exports to America, but last year American companies exported more than $100 billion worth of goods and services to China, supporting hundreds of thousands of jobs here. In fact, our exports to China have been growing much faster than our exports to the rest of the world. The Chinese leaders I met with know their country must shift from an economy driven by exports, investment and heavy industry to one driven more by consumption and services. This includes continued steps to revalue their currency and to provide fair access to their markets. As Americans save more and Chinese buy more, this transition will accelerate, opening opportunities for us. Even as the United States and China cooperate, we also compete. I strongly believe that the United States can and will flourish from this competition. First, we need to keep China’s rising economic power in perspective. According to the International Monetary Fund, America’s gross domestic product, almost $15 trillion, is still more than twice as large as China’s; our per-capita G.D.P., above $47,000, is 11 times China’s. And while there is a lot of talk about China’s “owning” America’s debt, the truth is that Americans own America’s debt. China holds just 8 percent of outstanding Treasury securities. By comparison, Americans hold nearly 70 percent. Our unshakable commitment to honoring our financial obligations is for the sake of Americans, as well as for those overseas. It is why the United States has never defaulted on its obligations and never will. Maybe more important, the nature of 21st-century competition favors the United States. In the 20th century, we measured a nation’s wealth primarily by its natural resources, its land mass, its population and its army. In the 21st century, the true wealth of a nation is found in the creative minds of its people and their ability to innovate. As I told students in Chengdu, the United States is hard-wired for innovation. Competition is in the very fabric of our society. It has enabled each generation of Americans to give life to world-changing ideas — from the cotton gin to the airplane, the microchip, the Internet. We owe our strength to our political and economic system and to the way we educate our children — not merely to accept established orthodoxy but to challenge and improve it. We not only tolerate but celebrate free expression and vigorous debate. The rule of law protects private property, lends predictability to investments, and ensures accountability for poor and wealthy alike. Our universities remain the ultimate destination for the world’s students and scholars. And we welcome immigrants with skill, ambition and the desire to better their lives. America’s strengths are, for now, China’s weaknesses. In China, I argued that for it to make the transition to an innovation economy, it will have to open its system, not least to human rights. Fundamental rights are universal, and China’s people aspire to them. Liberty unlocks a people’s full potential, while its absence breeds unrest. Open and free societies are best at promoting long-term growth, stability, prosperity and innovation. We have our own work to do. We need to ensure that any American willing to work can find a good job. We need to keep attracting the world’s top talent. We must continue to invest in the fundamental sources of our strength: education, infrastructure and innovation. But our future is in our own hands. If we take bold steps, there is no reason America won’t emerge stronger than ever. As vice president, I’ve traveled half a million miles around the world. I always come home feeling the same confidence in our future. Some may warn of America’s demise, but I’m not among them. And let me reassure you: based on my time in China, neither are the Chinese. Joseph R. Biden Jr. is the vice president of the United States. 转载自:争鸣第408期,花崗岩的文章和 http://www.nytimes.com/2011/09/08/opinion/chinas-rise-isnt-our-demise.html?_r=1ref=opinion
实验室里,看着数学,喝着咖啡,听着刀郎的《十送红军》,真是开心啊 ~~~~~~~~~~~~~~~ 不是放假,胜似放假~~~~~~~~~~~~~~~~ 今天有心讲讲数值积分。。。。。。。 上过数值分析的人都知道,课怎么个难听,好像八股文,数不清的证明,看不明白的数 学符号,第一排更知道的时老师愤青般的吐沫星子和他的如雪般的头皮屑。。。。。。。。 上完课,一头雾水,只有老师那紧皱的眉头,和前排女生美丽背影,还有点印象。。。。。。。。 什么是数值计算? 其实她是一门可爱的小姑娘,就是比较害羞,不太喜欢和你讲话;但是真正的泡妞高手都 知道对付这种女人就是四个字:死缠烂打。绝对搞定!!! (也 有人说如果理论数学是淑女,那么应用数学就是荡妇,哈哈 !) 谈到微积分的历史,就不能不提到阿基米德大叔,就是那个洗澡出来不穿裤子的犀利大 叔,主要的贡献是用穷竭法求圆的面积(本质是pi),其实微积分的本质是穷竭法。 什么是穷竭法??? 古代最牛逼的职业就是土地丈量师,很有技术含量!工作的主要就是测量土地面积,那可 是收 税的标准啊!面积怎么求:图形要分了正方形边长(a): a*a; 然后转化为矩形:a*b;矩 形化 为两个正方形;矩形在变化为平行四边形,切割后成为一个矩形和三角,所有的正规直 线图 形包围的面积就全部转化为如何求一个三角形面积! 兄弟姐妹,也就是会了三角,你就能求所有直线包围的几何面积! 很多人都会以为够了,但是实际啊,实际啊,还有曲线,有了曲线,你可以不思考,但是 你家的地有个弧边,要是算不好,就要多收你的钱,你就不愿意了,妈的,就是再有钱,也 不愿意接受随便收钱。(俗话说的好:地主家也没有余粮) 所以,就产生了计算曲线下包围的面积的任务。 什么是曲线,最简单的曲线是什么? 曲线的定义:不是直线的就是曲线! 最简单的曲线:圆! 平面上最规则的图形,也就是最特殊的图形,就是圆和正方形。 用最基本的图形计算一般 的形状的面积,也就是微积分最为基本,最为朴实的思想,最为 深邃的思想。 那么圆怎么算? 18世纪美国哈佛大学数学系的本科毕业论文。 阿基米德很早就给了我们答案:最开始用正方形围,再用六边形,然后正多边形。。。。 直到正几千边形。。。。。。,n越大,正n变形的面积越接近圆(也就是收敛)(微积分课 上老师的顺口溜(求近似,取极限)-----------------微积分的源头思想 讲了那么多的废话 ,开始正式讲数值积分的求法。 牛顿哥哥费了很大劲的说: 积分与微分是逆计算。 其实很多的积分是求不出原函数的!!例如高斯函数。。。。。 那怎么计算积分啊? 回到积分的最基本定义:求曲线下的面积!(终于,我开始说的废话没有白说,好累啊) 这样所有的不可用逆计算求出来的积分就一下都有办法了! 怎么算有三种方法, “我胡汉三又回来了。。。。” 算法回到了几千年前,求曲线下的面积。 第一种是梯形算法,就是把曲线下面积划分为一个个梯形(矩形+三角),也是将曲线用直线替代;(公式:区间*函数值 值,端点是函数值的二分之一) 第二种是抛物线算法,曲线用抛物线替代,函数上的点用抛物线拟合,然后对抛物线下的 面积求解(公式:区间宽的1/3*(偶数点的四倍和基数点的两倍)) 既然上面是对函数进行替代,那么有一种更加不要脸的算法了:函数用无穷级数来 替代,也就有了第三种算法,无穷级数展开求数值积分了!(key:是否收敛和 数值计算是什么呢? 百度( 1. 数值计算的结果是离散的,并且一定有误差,这是数值计算方法区别与解析法的主要特征。 哈哈,讲完了,好开心啊!!!!!! 2. 注重计算的稳定性。控制误差的增长势头,保证计算过程稳定是数值计算方法的核心任务之一。 3. 注重快捷的计算速度和高计算精度是数值计算的重要特征。 4. 注重构造性证明。) 维基: (Numerical analysis is the study of algorithms that use numerical values (as opposed to general symbolic manipulations ) for the problems of continuous mathematics (as distinguished from discrete mathematics ). One of the earliest mathematical writings is the Babylonian tablet YBC 7289, which gives a sexagesimal numerical approximation of , the length of the diagonal in a unit square. Being able to compute the sides of a triangle (and hence, being able to compute square roots) is extremely important, for instance, in carpentry and construction. Numerical analysis continues this long tradition of practical mathematical calculations. Much like the Babylonian approximation to , modern numerical analysis does not seek exact answers, because exact answers are often impossible to obtain in practice. Instead, much of numerical analysis is concerned with obtaining approximate solutions while maintaining reasonable bounds on errors. Numerical analysis naturally finds applications in all fields of engineering and the physical sciences, but in the 21 st century, the life sciences and even the arts have adopted elements of scientific computations. Ordinary differential equations appear in the movement of heavenly bodies (planets, stars and galaxies) ; optimization occurs in portfolio management; numerical linear algebra is important for data analysis; stochastic differential equations and Markov chains are essential in simulating living cells for medicine and biology. Before the advent of modern computers numerical methods often depended on hand interpolation in large printed tables. Since the mid 20th century, computers calculate the required functions instead. The interpolation algorithms nevertheless may be used as part of the software for solving differential equations .)
Project HindSight是美国国防部上世纪60年代所做的研究,用于 分析 其RD的投资收益 (Abelson, 1966; Hayes, 1966; Layton, 1971; Leiserson, 1967; Sherwin Isenson, 1966, 1967) 。该计划耗资庞大,覆盖了二战后到60年代13个最具影响力的军事技术系统。计划针对每个系统,指派专门的专家团队,追踪其科研报告,并对原始科研参与人员进行三角检验,上溯追踪引起该十三个技术系统发展的每一个科学发现和技术发明,对 发现发明继续上溯 直至源头,共锁定七百余个发现发明---称为HindSight Events (Sherwin Isenson, 1966, 1967)。其研究结果惊奇的发现,这七百余个HindSight Events中只有8%属于科学发现(2%基础科学,6%应用科学),92%都是技术发明 (Sherwin Isenson, 1967) 。 该研究打破了大家对“基础科学将直接促进应用科学,应用科学将直接促进技术发明”这样线形知识生产的假想(参见Ehlers 1999的美国科技政策回顾)。“科学发现将引发更多科学发现,技术发明将引发更多的技术发明,这正是Project HindSight的结论”(Layton, 1971)。 我的论文有小小的一部分涉及技术知识的特点和思维方式,以及如何借鉴到其他职业行业,并具体运用到我所在的这个小小的景观规划设计学科。 相关文献 Layton, E. T. (1971). Mirror-Image Twins: The Communities of Science and Technology in 19th-Century America. Technology and Culture, 12(4), 562-580. Sherwin, C. W., Isenson, R. S. (1967). Project Hindsight. Science, 156(3782), 1571-1577. Sherwin, C. W., Isenson, R. S. (1966). First interim report on Project Hindsight (summary). Washington DC: Office of The Director of Defense Research and Engineering Leiserson, L. (1967). Project Hindsight. Science, 157(3796), 1512. Abelson, P. H. (1966). Project Hindsight. Science, 154(3753), 1123. Hayes, H. L. (1966). Project Hindsight: Basic Research. Science, 154(3756), 1504. Ehlers, V. J. (1999). Unlocking Our Future Science and Technology Policy Yearbook: AAAS.
 标签: 分析
标签: 分析
![[转载]FDI与贸易结构优化关系的实证分析](http://image.sciencenet.cn/album/201212/21/082900c1xikrp0jxjxfxkp.jpg.thumb.jpg)




![[转载]分析类工具 2](http://image.sciencenet.cn/album/201208/13/110107ni850uggba5g3532.jpg.thumb.jpg)
![[转载]管理类工具 1](http://image.sciencenet.cn/album/201207/24/15235491st19t1or6ols71.jpg.thumb.jpg)





![[转载]微博应用布局及Twitter代表应用分析](http://image.sciencenet.cn/album/201109/06/184333nahd3fmdikmunmqi.jpg.thumb.jpg)