16日我应邀参加北师大举办的《2011国际莱布尼茨学术研讨会》,研讨会给每人35分钟的时间,其中25分钟为报告,10分钟为讨论。二者不可混用。我今天刚刚将参会的PPT文件赶制出来,明天就要报告了。现在将我的PPT文件的pdf版本传到网上,供大家批评指正。我的发言题目是:On Universal Number of Heaven and Earth, Leibniz's Universal Character and Universal Turing Machine (论大衍之数、莱布尼茨的普遍逻辑和通用图灵机)。但愿能对人有所启迪。 On UNHE, UC UTM.pdf
请进 http://www.nextbio.com/b/nextbio.nb 这个搜索引擎最关键的是对本体语言和语义网的强大应用,类似于标签的概念,制作用户和搜索item的通用词表。该系统利用个人资料,以及用户交互信息,包括短期和长期的信息,提供搜索推荐。 NextBio 提供了一个创新的平台,生命科学研究人员可以在这个平台上检索、发现、分享公共和专用的数据。 NextBio 的平台无缝整合了强大的工具,具有独特的相关内容,能将信息转化为知识,为新的科学发现提供基础。 NextBio能 帮助科研机构提高科研效率,提高不同科研机构和不同地域间的科研合作。 随着跨学科和学科间的研究越来越普遍,对于科研人员而言,能够轻松掌握其他学科领域的新概念将十分重要。爱思唯尔集团在产品内植入了 NextBio 开发的某些新功能,以方便研究人员根据上下文的意思和前后关联来迅速判断出一些新概念的涵义。 http://en.wikipedia.org/wiki/Nextbio Nextbio From Wikipedia, the free encyclopedia Jump to: navigation , search NextBio Type Private Founded California , USA (2004) Founder(s) Saeid Akhtari Ilya Kupershmidt Mostafa Ronaghi Headquarters Cupertino , California , US Area served Worldwide Key people Saeid Akhtari (President CEO) Ilya Kupershmidt (VP of Product Management) Dr. Satnam Alag (VP of Engineering) Employees 50 Website www.nextbio.com NextBio is a privately owned software company that provides a platform for drug companies and life science researchers to search, discover, and share knowledge across public and proprietary data. It was co-founded by Saeid Akhtari, Ilya Kupershmidt and Mostafa Ronaghi in 2004 and based in Cupertino, California , USA . The NextBio Platform is an ontology -based semantic framework that connects highly heterogeneous data and textual information. The semantic framework is based on gene, tissue, disease and compound ontologies. This framework contains information from different organisms, platforms, data types and research areas that is integrated into and correlated within a single searchable environment using proprietary algorithms. It provides a unified interface for researchers to formulate and test new hypotheses across vast collections of experimental data. According to the company, the enterprise version of the NextBio platform is being used in life science research and development and drug development by researchers and clinicians at: Merck Pharmaceutical , Johnson Johnson Pharmaceutical Research Development, L.L.C., Celgene , Genzyme , Eli Lilly and Company , and Regeneron Pharmaceuticals . This enterprise version allows internal, proprietary data to be uploaded and integrated into the NextBio database of publicly-available data. According to the company, scientists are using NextBio to improve their ability to identify relevant prognostic and predictive molecular signatures which are significant in their research. NextBio was a receiver of the Frost Sullivan North American Life Sciences Customer Value Enhancement Award in 2008. Since the release the website has had more than 1,500,000 hits. Articles Business Wire, March 2007 Venture Beat, February 2007 Scientific Computing, May 2008 References ^ stanford.edu | 2008 Release: What is NextBio? ^ bio-itworld.com | 2007 Release: NextBio Life Science Search Engine Advances Systems Biology Approach to Research ^ businesswire.com | 2008 Release: NextBio Announces Public Launch of Its Life Science Search Engine ^ nextbio.com | 2008 Release: NextBio FAQ ^ nextbio.com | 2008 Release: NextBio Testimonials ^ businesswire.com | 2008 Release: NextBio Awarded the 2008 Frost Sullivan North American Life Sciences "Customer Value Enhancement Award" for Innovative Life Science Search Engine Retrieved from " http://en.wikipedia.org/wiki/Nextbio " Categories : Internet search engines | Bioinformatics | Online databases | Companies established in 2004 | Privately held companies of the United States NextBio支持 sciencedirect全文检索平台 实例 通过与 NextBio 合作,ScienceDirect的内容更为丰富, NextBio 采用语义检索功能,使得生命科学、医学和化学领域的研究者可以在进行检索的同时深入了解相关科研信息、数据和知识。 Lancet 柳叶刀杂志 Volume 361, Issue 9366, 19 April 2003, Pages 1319-1325 ISSN: 01406736 CODEN: LANCA DOI: 10.1016/S0140-6736(03)13077-2 PubMed ID: 12711465 Document Type: Article Source Type: Journal View references(15) View at publisher | 论文题目 Coronavirus as a possible cause of severe acute respiratory syndrome Peiris, J.S.M. a g , Lai, S.T. b , Poon, L.L.M. a , Guan, Y. a , Yam, L.Y.C. d , Lim, W. c , Nicholls, J. a , Yee, W.K.S. e , Yan, W.W. b , Cheung, M.T. d , Cheng, V.C.C. a , Chan, K.H. a , Tsang, D.N.C. f , Yung, R.W.H. d , Ng, T.K. b , Yuen, K.Y. a a Dept. of Microbiology and Pathology, Queen Mary Hospital, University of Hong Kong, Hong Kong, Hong Kong b Department of Medicine, Intensive Care and Pathology, Princess Margaret Hospital, Hong Kong, Hong Kong c Government Virus Unit, Department of Health, Hong Kong, Hong Kong d Department of Medicine and Pathology, Pamela Youde Nethersole E. Hospital, Hong Kong, Hong Kong e Department of Medicine, Kwong Wah Hospital, Hong Kong, Hong Kong f Department of Pathology, Queen Elizabeth Hospital, Hong Kong, SAR, Hong Kong g Department of Microbiology, University of Hong Kong, Queen Mary Hospital, Pokfulam Road, Hong Kong, SAR, Hong Kong Cited by since 1996 This article has been cited 1237 times in Scopus: 1996年至今本文已被引用1237次 http://www.sciencedirect.com/science?_ob=ArticleURL_udi=B6T1B-48CW83Y-7_user=9230734_coverDate=04%2F19%2F2003_rdoc=1_fmt=high_orig=gateway_origin=gateway_sort=d_docanchor=view=c_acct=C000059499_version=1_urlVersion=0_userid=9230734md5=ad65d18d9e275165e81c4cfdcf2a6b29searchtype=a Relevant terms from this article 本文相关词汇 Click for Data Correlations, Clinical Trials and more 31diseases 相关疾病 severe acute respiratory syndrome pneumonia atypical pneumonia fever lymphopenia infection coronavirus infection cough influenza disease progression leucopenia thrombocytopenia parainfluenza shortness of breath adenovirus infection adult respiratory distress syndrome anaemia anorexia avian influenza chills common cold convalescence headache inflammation laboratory infections leucocytosis liver dysfunction multiple sclerosis respiratory failure sore throat urinary-tract infection View more... View less... 10compounds 相关化合物 ribavirin alanine hydrocortisone oxygen viral particles chloride ether fluoroquinolones magnesium methylprednisolone View more... View less... 16tissues cells 相关组织和细胞 sera lung chest kidney blood respiratory-tract cytoplasm sputum body fluids brain cell cultured cell lines liver neurons platelet pneumocytes View more... View less... 19organisms 相关生物体 human coronaviridae rhesus murine hepatitis virus adenovirus bacteria bovine coronavirus mycoplasma respiratory syncytial virus rna virus torovirus viral particles virus particles b virus escherichia coli haemophilus influenzae human-metapneumoviru... klebsiella pneumoniae porcine transmissible gastroenteritis virus View more... View less... What is this? 智能信息分析和知识获取原理、方法 ScienceDirect has partnered with NextBio to connect articles with additional research content and experimental data from sources such as PubMed, GEO, and ClinicalTrials.gov. Using life science relevant ontologies, synonym recognition, gene and protein linkages, and tissue and disease nomenclature, links are made between experimental data and peer-reviewed content. This box contains the key terms extracted from this ScienceDirect article. Clicking on a term will take you to an overview page where you will see associated content and will be able to find relevant information fast, thereby accelerating your scientific discovery. 参考资料 中国近十年论文总引用次数超过四百万 http://news.sciencenet.cn/htmlnews/2011/3/245238.shtm 8. 中国(近十年论文总引用数4,227,779) 论文: CORONAVIRUS AS A POSSIBLE CAUSE OF SEVERE ACUTE RESPIRATORY SYNDROME 被引次数:1,025 领域:临床医学 发表期刊:《柳叶刀》(THE LANCET ) Enhanced PubMed Alternative The Scientist http://blog.sciencenet.cn/home.php?mod=spaceuid=280034do=blogid=403931 医学信息智能语义检索平台 www.Quertle.info http://bbs.sciencenet.cn/home.php?mod=spaceuid=280034do=blogid=409307
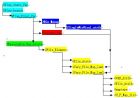
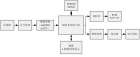
智能仪器仪表通用硬件架构与软件中间件研究 摘要 : 研究智能仪器仪表的技术现状、发展方向以及关键技术,着重解决制约当前行业发展的智能处理系统、人机界面、底层驱动软件和可靠性四个共性关键技术问题,研制一种以 ARM+DSP 处理器为核心,彩色液晶图形显示、多点触控键盘输入,具备底层驱动和软件中间件的高可靠性智能仪器仪表开发平台 。 1.1智能仪器仪表及其关键技术 智能仪器是把一个微型计算机系统嵌入到数字式电子测量仪器中而构成的独立式仪器。嵌入的计算机系统可以是芯片级,如单片机、数字信号处理(DSP)等;可以是模板级,如PC104;也可以是系统级,如微型计算机系统,可编程单芯片系统(SOPC)等。智能仪器在结构上自成一体,带有专用的微型处理器系统和丰富的接口,能独立完成测试。 智能仪器由于引入了高性能处理器,功能强大,性能优异,使用灵活、方便,是现阶段仪器仪表的主体。随着新技术、新工艺和嵌入式系统技术的不断进步,智能仪器也在不断发展,不断提高智能水平。最初作为测量器具的仪器已发展成一门较为完整的学科,并在当今国民经济和科技发展中发挥着日益重要的作用,占有至关重要的地位。 智能仪器仪表发展的关键技术包括: ①传感技术:传感技术是仪器仪表实现检测和控制的基础。 ②系统集成技术:系统集成技术直接影响仪器仪表的应用广度和水平。 ③智能处理技术:智能处理技术可以说是仪器仪表中最重要硬件平台和最关键的软件资源。 ④人机界面技术:人机界面技术主要为方便仪器仪表操作人员操作仪器仪表。 ⑤可靠性技术:随着仪器仪表技术复杂性增大和应用领域的扩大,可靠性技术的重要性越来越受到重视。 1.2国家产业政策 国家发改委、科技部等主管部门按“十一五”规划及国务院8号文件精神,对仪器仪表、控制系统、智能化等高新技术及其产业化的支持力度不断加强,国家发改委对该领域的支持重点明确,立项审批加快。 科技部多项智能化仪表、控制系统、印刷、无线通讯、科学仪器的研发项目已立项,有的已付诸实施。国电集团、中石化、中石油等有重大影响的单位都在积极采取措施,推进国产仪器仪表和控制系统在重大工程的应用,并研究加大投入力度,支持其研发和产业化。重庆、天津、沈阳、宁夏、湖南等省市都在结合本地区的发展,研究和采取支持仪器仪表行业发展的措施。 郑州市政府为了更有力地推动本区仪器仪表行业的发展,提升行业的自主创新能力,努力发展高端产品,提高行业整体技术水平和产业规模,在2008年10月15日,在郑州高新技术产业区成立郑州仪器仪表产业联盟。 1.3 我国仪器仪表业的现状和发展目标 (1)现状: 我国仪器仪表产业从无到有、从小到大,初步形成了门类比较齐全的仪器仪表生产、科研、营销体系。通过科技攻关、联合开发、合资合作和引进技术、消化吸收、实现国产化等多种形式,使我国仪器仪表行业部分中高档主导产品缩小了与国际先进水平的差距,并形成生产能力。仪器仪表行业整体综合技术水平达到国际20世纪80年代中期水平。微电子技术和计算机技术在仪器仪表产品中普遍采用,约15%的产品实现了智能化,达到国际90年代水平;30%的产品实现了数字化,达到国际20世纪80年代末期水平。从产品满足需要程度上看:中高档科学测试仪器国内市场满足率为30%,中低档科学仪器满足率65%;大型工程项目中配套仪器的品种满足率达50%,中小型工程达70%。 当前国内仪器仪表产品的普遍形态是: 以LED数码管为显示,以薄膜开关按键为输入; 以MCS8051系列单片机为主要处理器。 其工作原理是:首先被测量通过传感器转化为电信号,经过放大和滤波后送入A/D转换器转换成相应的数字量后送入单片机,单片机根据仪器所设定的初值进行相应的数据运算和处理(如非线性校正等),运算的结果被转换为相应的数据进行显示和打印并保存。此外,可以与PC机组成分布式测控系统,由单片机作为下位机采集各种测量信号与数据,通过串行通信将信息传输给PC机,由PC机进行全局管理。其硬件结构如图1所示。 图1 当前我国仪器仪表仪器的硬件结构图 (2)发展目标: 我国仪器科学与技术学科的总体目标是:从目前至2020年,充分利用我国经济高速发展和巨大的市场优势,结合测控技术的深化研究,大力推进新技术、新工艺在仪器仪表中的应用研究,掌握各类仪器仪表的设计、生产工艺等关键技术,满足各个方面对测量控制与仪器仪表的需求,减少进口,扩大出口,使产业总体水平与国际水平差距普遍缩短到3~5年;行业内约30%的产品达到国际同期先进水平,国内生产的仪器仪表在大工程的配套能力达到80%以上。 1.4 国外仪器仪表业的现状与技术发展趋势 国际智能仪器仪表发展极为迅速,发展的主要趋势是: 微型化:微型智能仪器指微电子技术、微机械技术、信息技术等综合应用于仪器的生产中,从而使仪器成为体积小、功能齐全的智能仪器。 多功能:多功能本身就是智能仪器仪表的一个特点。 智能化:智能化是计算机应用于仪器仪表行业的明显特征。 网络化:融合ISP和EMIT技术,实现仪器仪表系统的Internet接入。 虚拟化:在虚拟仪器中,使用同一个硬件系统,只要应用不同的软件编程,就可得到功能完全不同的测量仪器。 仪器仪表作为信息工业的源头,以电脑和微处理器的技术为核心技术,以计算机、网络、系统、通信、图像显示、自动控制理论为共性关键技术基础。随着这些技术的发展,智能仪器仪表作为信息工业领域中一大系列产品群体,正向智能化、微型化、网络化和虚拟化方向迅速迈进,我国智能仪器仪表行业也将发生新的变化并获得新的发展。 2.1 基于 ARM+DSP 高端智能仪器仪表的架构 当前按照仪器仪表的适用场合和复杂程度,其硬件结构大体有以下几种形式: l 电池供电的低功耗便携式仪表的硬件架构 l 基于ARM通用仪表的硬件架构 l 基于ARM+DSP高端智能仪器仪表的硬件架构 本项目重点研究基于ARM+DSP高端智能仪器仪表的硬件架构。其框架如图2所示。研究的主要内容包括以下5个部分。 图2基于ARM+DSP高端智能仪器仪表的硬件架构 (1)智能仪器仪表平台的硬件体系结构 l 智能仪器仪表平台功能分析 l 智能仪器仪表平台的硬件体系结构 (2)智能仪器仪表平台的软件系统模型 l 仪器仪表平台的软件体系结构 l 智能仪器仪表平台底层软件模型 (3)智能仪器仪表平台底层设备驱动技术研究 l 智能仪器仪表平台各功能模块底层设备驱动技术研究 n 数据测量模块接口驱动技术 n 数据存储模块驱动技术 n 人机接口模块设备驱动技术 n 数据通信模块接口驱动技术 (4)智能仪器仪表平台底层设备驱动的设计实现 智能仪器仪表底层驱动与中间件结构如图3所示,研制的软件模块包括: l 设备驱动的模块化构建与内核的裁剪配置 n 设备驱动模块的添加 n 内核的裁剪配置 l 系统引导程序 bootloader 的设计 l 主要设备及接口驱动程序的设计实现 n SPI 接口驱动的设计及实现 n LCD 驱动的设计及实现 n USB 驱动的设计实现 n 以太网接口驱动的设计与实现 图3 智能仪器仪表底层驱动与中间件结构图 (5)智能仪器仪表平台应用实例 借助于嵌入式处理器的强大功能,在嵌入式操作系统和实时操作系统的配合下,可大大简化系统软硬件设计,使得复杂的系统功能模块化,各个模块通过操作系统的调度实现了并行执行,充分发挥嵌入式处理器的性能、提高运行效率、增强系统可移植性、可裁减性、可维护性。拟用于开发电力负荷管理终端,验证开发平台的先进性。 2.1.2 以 LCD 显示技术和多点触控输入为核心的人机接口界面 ( 1 )智能仪器仪表平台的 LCD 图形化显示 利用帧缓冲(framebuffer)技术,完成彩色LCD的帧缓冲驱动程序,并设计MiniGUI用户程序界面触摸屏驱动程序。 帧缓冲(framebuffer)是操作系统为图形设备提供的一个抽象接口,帧缓冲设备属于字符设备,采用“文件层一驱动层”的接口方式。对用户而言,它和其他设备文件没有区别,用户程序可以把framebufer看成一块内存,既可以向这块内存中写入数据,也可以从这块内存中读出数据,LCD显示器将根据相应指定内存块的数据来显示相应的图形。应用程序对显示缓冲区的读写操作是抽象的、统一的。用户程序不必关心物理显存的位置、换页机制等具体细节,这些是由帧缓冲设备驱动来完成。基于framebuffer的LCD显示原理如图4所示。 图4基于framebuffer的LCD显示原理如图 其研究的主要内容包括: l 智能仪器仪表平台LCD图形化显示功能分析 l 智能仪器仪表平台的LCD图形化显示硬件体系结构 l 智能仪器仪表平台的LCD图形化显示软件中间件 l 智能仪器仪表平台的LCD图形化显示软件实例 ( 2 )智能仪器仪平台的多点触控输入 多点触控技术以为苹果公司的iPhone手机为代表,它必将快速延伸到仪器仪表行业。 在多点触控中如何有效地执行对象追踪技术是决定多点触控效能的关键,当扫描系统建立对象的信息之后,必须配合一个有效而稳健的搜寻与配对策略,在连续扫描的信息中快速而精准地找出对象的位置,或是建立对象所需要搜集的信息。 在压电式触控技术中,使用区域合并方法来消除破碎或分散的对象,以提高整个系统的处理速度,此外依据主动式轮廓追踪技术来掌控触控屏上每个点的移动状况,而且进一步利用特征追踪法对对象位置变化作预测,以缩小搜寻比对的范围,主要步骤包括预测下个时间点的对象状态与依据变化量来更新系统内部参数,真正达到一个具有动态调整的精密追踪技术。 主要研究内容包括: l 智能仪器仪平台的多点触控的硬件结构 l 智能仪器仪平台的多点触控的对象跟踪 n 区域合并(Region—Based combination) n 主动式轮廓追踪(Active Contour—BasedTracking) n 特征追踪(Feature—Based Tracking) n 物件追踪的算法— biparite matching 2.1.3 其他共性关键技术问题研究 l 可靠性问题:硬件可靠性问题、软件可靠性问题 l 传感器静态建模和设计 n 解析、数值建模方法 n 计算机模拟与辅助设计 l 传感器动态建模和校正 n 系统辨识建模方法 n 沃尔什变换方法 n 神经元网络方法 n 动态补偿方法 l 误差修正技术: n 系统误差的数字修正方法 n 随机误差的数字修正方法 n 动态误差的数字修正方法 l 信号处理技术: n 周期图法 n 最大熵谱分析法 n 自适应滤波法 n 小波变换法 2.2 技术方案 ( 1 )主要芯片的选型 l ARM芯片选用英特尔公司PXA270。 PXA270 是Intel公司开发的基于XScale架构的处理器,内核采用ARMv5TE,外围控制器众多。内置了Intel的无线MMX技术,能够显著的提升多媒体性能,此外PXA270也包含了Intel的SpeedStep技术,能够根据需要动态调节CPU的性能,真正实现了低功耗,高性能。同其他XScale处理器一样,支持多种嵌入式操作系统,如Linux、Windows、WinCE、Nucleus、Palm OS、VxWorks、Java等。 PXA270的产品除基本接口功能外,可以扩展特殊接口,能满足军用级和工业级的环境要求,带有强大的电源管理功能和强大的图像处理功能,是工控ARM主板中的高端产品。在石油和矿业等行业有广泛应用。 l DSP芯片选用TI公司TMS320F2812 TMS320F2812是美国TI公司推出的新一代32位定点数字信号处理器,该芯片每秒可执行1.5亿次指令,具有单周期32 bit×32 bit的乘和累加操作功能,片内集成了丰富的外围设备,如16路A/D转换器、面向电机控制的事件管理器以及多种标准串口通信外设等。可见,其不仅具有数字信号处理器卓越的数据处理能力,又像单片机那样具有适于控制的片内外设及接口;它在数字控制系统中有着广泛的应用,特别是在运动控制领域以及嵌入式开发系统设计中,常常成为微处理器的首选。 ( 2 )操作系统的选型 在嵌入式应用领域,其操作系统主要是Linux、WinCE和 VxWorks。在突出图形显示界面、要求实时性、工业环境下的仪器仪表应用中,三者各有利弊。 l Linux:代码开源 Linux 操作系统是一款优秀的操作系统,支持多用户、多线程、多进程,实时性好,功能强大且稳定。同时,它又具有良好的兼容性和可移植性,被广泛应用于各种计算机平台上。缺点:代码开源可靠性、安全性难以保证。 l Windows CE .NET 是Windows CE 3.0的后继产品。Windows CE .NET为嵌入式市场重新设计,为快速建立下一代智能移动和小内存占用的设备提供了一个健壮的实时操作系统。Windows CE .NET具备完整的操作系统特性集包和端对端开发环境,它包括了创建一个基于Windows CE的定制设备所需的一切,例如:强大的联网能力、强劲的实时性和小内存体积占用以及丰富的多媒体和Web浏览功能。 l VxWorks操作系统:注重实时性 它是美国WindRiver公司于1983年设计开发的一种嵌入式实时操作系统(RTOS),它以其良好的可靠性和卓越的实时性被广泛地应用在通信、军事、航空、航天等高精尖技术及实时性要求极高的领域中,如卫星通讯、军事演习、弹道制导、飞机导航等。VxWorks原先对中国区禁止销售,自解禁以来,在我们的军事、通信、工业控制等领域得到了非常广泛的应用。缺点:价格昂贵。 综合上述因素,项目选择WinCE作为首选系统。 ( 3 )对象跟踪的实现:物件追踪的算法 (biparite matching) 多点触控技术中每个frame会有不定个数的对象,可能只有一个,也可能有二个,甚至有十个。必须持续追踪这些对象的变化,包括每个点什么时候出现、中间移动的轨迹以及什么时候消失,如果追踪机制只面对一个点,那么问题很简单。在图5中,圆形为前一个frame对象的位置,方形为当前这个frame的位置,在单一点的情况下,可以直接断定圆形和方形是同一个对象,并且移动路径是A。 图 5 单一物件的位移与追踪 图6展示了两个点的情况,如何判断两个对象是走了路径A还是路径B以及更复杂的可能。为了简化,用一个简单的策略来解决:在两个frame间,相对位移越短就越可能是相同的一个点, 也就是说在图 6 中,上方的方形应该是点 1 ,下方的是点 2 ,因为这样两个点移动的距离都比较短。 图6 多点物件的位移与追踪 利用图论中的 bipartite matching 问题来解全域的最佳解。详细的配对方法如下: 1 .假设前一个 frame 的所有对象集合为 A , 目前 frame 的则为 B ; 2 .对于 A 中的所有点 a ,计算出到 B 中所有点 b 的 edge 长度,并放进一个数组 E 中; 3 .把数组 E 中距离太远的 edge 剔除掉: 4 .将 E 按 edge 长度排序,从小到大; 5 .从 E 的开头开始, 每取出一条 edge 前先看看 edge 的两端点是否已经配对成功过,配对时同时会判断对象的各种特征,除了距离要最短之外,其余的特征也必须符合才能完成一组配对: 6 .重复上一步直到取出所有 edge 为止。 运行完上面的算法,就可以标记出两个 frame 中所有对应的对象,并且可以产生每一个对象所对应的移动轨迹。就可以对这些对象的状态做进一步的处理。
 标签: 通用
标签: 通用