人工智能很火, 人工智能大神很火。大神们的神器是什么? 有人说找到了,就是EM算法。 请看这篇: EM 算法的九层境界: Hinton 和 Jordan 理解的 EM 算法 http://mp.weixin.qq.com/s/NbM4sY93kaG5qshzgZzZIQ 但是最近网上引人关注的另一传闻是,一位人工智能论文获奖者在获奖感言中说人工智能方法是炼金术, 从而引起大神家族成员反驳。 报道见: http://baijiahao.baidu.com/s?id=1586237001216079684wfr=spiderfor=pc 看到上面两篇, 使我想到: EM 算法是炼金术码? 我近两年碰巧在研究用以改进 EM 算法的新算法: http://survivor99.com/lcg/CM/Recent.html ,对 EM 算法存在的问题比较清楚。我的初步结论是: EM 算法虽然在理论上有问题, 但是确实炼出金子了。 反过来也可以说, 虽然 EM 算法练出金子了,但是收敛很不可靠,流行的解释 EM 算法的收敛理由更是似是而非。有人使之神秘化,使得它是有炼金术之嫌。论据何在?下面我首先以混合模型为例,简单介绍 EM 算法, 并证明流行的 EM 算法收敛证明是错的 ( 没说算法是错的 ) 。 因为公式太多, 详见PDF文件: http://survivor99.com/lcg/CM/cm-ljs.pdf
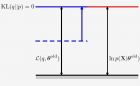
EM算法总结.docx (鉴于博文插入图片比较麻烦,进一步了解请下载附件查看) EM 算法是常用来进行概率密度估计或者给数据建模,这样说有点难以理解,这可以通过对高斯混合模型, K-Means 的算法的学习进一步了解。 用百度百科的话来说: 最大期望算法 ( Expectation-maximization algorithm ,又译 期望最大化算法 )在统计中被用于寻找,依赖于不可观察的隐性变量的概率模型中,参数的最大似然估计。 最大期望算法经过两个步骤交替进行计算: 第一步是计算期望( E ),利用对隐藏变量的现有估计值,计算其最大似然估计值; 第二步是最大化( M ),最大化在 E 步上求得的最大似然值来计算参数的值。 M 步上找到的参数估计值被用于下一个 E 步计算中,这个过程不断交替进行。 总体来说, EM 的算法流程如下: 1. 初始化分布参数 2. 重复直到收敛: E 步骤:估计未知参数的期望值,给出当前的参数估计。 M 步骤:重新估计分布参数,以使得数据的似然性最大,给出未知变量的期望估计。 说到 EM 算法,不得不提的是 Jensen 不等式,定理如下: 定理:如果 f 是一个凸函数, X 是随机变量,则有: E ≥ f( E(X) ). 进一步的如果 f 是一个严格的凸函数 注:凸函数要求其二次导数不小于零,比如 x2 是一个严格凸函数,因为其二次导数是一个常数 2 恒大于零(没有等号);一个常数函数比如 f(X)=5, 其二次导数恒等于 0 ,则其是一个不严格的凸函数。可以看出来,若一个凸函数包含一段常数函数,则其为一个不严格的凸函数。 而凹函数与凸函数相对,其性质恰好相反,不再多说,仅给出以下不等式,若 f 是一个凹函(比如对数函数),有: E ≤ f( E(X) ) 。 为何要提这个 Jensen 不等式呢?因为在 EM 算法中第一步是对隐藏变量的期望的估计,然后根据 Jensen 不等式构造出一个下界函数(因为一般都是 log 函数),第二步就是再计算这个下界函数的最大值(其实也就是让 Jensen 不等式的等号成立的条件)的参数,后面详细过程中会讲到。 下面是细致的说明和推导过程: 假设给定了 m 个独立样本 {x (1) , ... , x (m) } ,假设我们想根据这些数据选择合适的参数构造模型 p(x,z) 。其似然函数可以写作: 但是根据上式往往直接估计参数θ会非常困难。上式中 z (i) 是一个个的隐含变量,一般情况下,当观察到这个隐含变量时再进行 MLE 会比较容易。第二个式子是边际分布,很容易得到。 根据上面介绍, EM 算法给出了一个高效的解决策略: E 步,总是为似然函数 l 构造一个下界函数; M 步,最大化这个下界函数。 具体说来,首先做一个假设:对于每一个 z (i) ,设 Q i (Z) 为其对应的分布,因此满足 z Q i (z) =1 , Q i (z)≥0 . 因此对于上面提到的似然函数可以做如下推导: 其中第一步是根据边际分布得到的不再多说,第二步更容易看懂,但是把 z 的分布加进去了,从第二步到第三步是利用的 Jensen 不等式,构造了一个下确界函数(因为似然函数里面的 log 函数是凹函数)。 注: 仔细解释下第二步到第三步,可以将 看成是一个关于 z (i) 的函数 g(z (i) ) ,而且 logX 是一个凹函数, Q i (Z (i) ) 是一个关于 z (i) 的分布, 因此 可以看成是一个变量的期望的函数,根据 Jensen 不等式有对于凹函数“期望的函数≥函数的期望”,即: 其中 f 指的是 log 函数,因此有公式( 2 )到公式( 3 )。 此时, Q i (z) 可以是任何形式的分布,但是应该如何选择呢?直观上看,在当前θ的条件下,应该使 似然函数 尽可能的大,其实说白了让 Jensen 不等式的等号成立找到一个紧确界就好了。问题又来了,怎样才能找到一个紧确界呢?哈哈,根据前面对 Jensen 不等式的分析,只需要满足 其中 c 是一个不依赖于 z (i) 的常数就可以了,进一步讲,就是这时候满足了 Jensen 中的凹函数是一个常数,即期望的函数等于函数的期望了。因此说这样就可以构造一个紧确界了。这可以通过选择 达到目的。 再根据 z Q i (z) =1 ,可做如下推导: 其实,到目前为止,我们也就完成了 E 步当中对 Q i (z (i) ) 的选择过程。 至此,可以写出 EM 算法的过程为: 至于收敛性证明此处不再多讲。值得一提的是,若定义 则根据前面的推导有 l( θ ) ≥ J(Q, θ ). 则 EM 算法可以看成是一个对于 J 的坐标上升算法,其中 E 步是关于 Q 最大化 J ,而 M 步是关于θ最大化 J 。 至此, EM 算法总结完毕,事实上我们只学到了 EM 算法的一些基本思想和推导过程,要想真正的掌握,本人建议通过对高斯混合分布模型的学习以及 K-Means 算法来进一步的理解和巩固。
 标签: EM算法
标签: EM算法