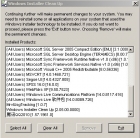
安装MSN 2009时提示“试图读取文件c:\windows\installer\messenger.msi时发生网络错误”解决办法 安装MSN 2009时有时会出现“试图读取文件c:\windows\installer\messenger.msi时发生网络错误”这样的提示,这是因为以前安装程序是的一些存储信息被破坏,导致无法正常卸载! 本文将应用软件Windows Install Clean Up来解决这个问题。 Windows Install Clean Up 下载地址为 msicuu2.rar 安装后,在程序中打开Windows Install Clean Up,这时就会显示出一个列出了当前经Windows Installer安装上去的程序列表,如图: 此时你选择"windows live messenger",然后点击remove;类似的依次删除"windows live mail"、"windows live picture"等,最后你再安装MSN 2009就能安装上了。 Windows Install Clean Up 也可以解决其他软件安装或卸载类似问题。
 标签: 应用软件
标签: 应用软件