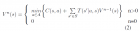In Daphne Koller's book (probabilistic graphical model: principles and techniques), there are 3 kinds of Markov Properties: pairwise Markov Property, Local Markov Property and Global Markov Property. Obviously, global indicates local, and local indicates pairwise. However, the reverse is not necessary true. However, for a distribution p(y) 0, these three properties are equivalent.Proof can be found from Koller's book. One Problem: when can we make use of these three properties? Answer: during graph construction. In most computer vision applications, graph structure is not learnt from data, but constructed from specific applications. So there is no graph construction step in most CV problems. However, in data mining, the underlying graph structure of the big data is hidden from us, which is not easy to get. Then we have to learn structure from data. At this time, it's more convenient to check whether two nodes are independent than to check whether a bunch of nodes A are independent from another bunch of nodes B. If we further assume p(y) 0 for any y, then from pairwise independence, we get global independence easily with no need to probablistically checking.
单分子阶梯事件分析 Single-molecule detection (SMD) and tracking in living cells is becoming a powerful method for the study of protein local environments, the time course of the enzymatic reaction, and the structure fluctuations of macromolecules, etc. Many single molecule studies have offered new insights into their localization, assembly and activation. Perhaps the dominant advantage of single-molecule fluorescence detection is that it can provide information on the spatial and temporal heterogeneity of molecule that underlies the ensemble average in conventional biochemical experiments. These spatial and temporal heterogeneities often appear as step events, for example, the discrete steps of photobleaching of single fluorescent molecules response to the number of subunits in membrane proteins. Hence , the step events analysis is becoming an important method of stochiometry study. However, SMD is also a difficult task. The most experiments of single-molecule fluorescence detection are approaching the limits of optical detection, and that the raw experimental data are inundated with all kinds of noise, especially, the Poisson distributed photon shot noise. These steps are so dim that it is very difficult to distinguish them. To leach out the useful information from these noisy raw data is still a challenging task. Perhaps the simplest and most commonly used method for the analysis of step events of single molecule inundated in these noisy data is the thresholding method. When a single-molecule trajectory has sufficient contrast between states, thresholds can be applied to distinguish the states of the molecule. These thresholds are typically chosen manually and introduce subjectivity into the analysis inevitablly. Before thresholding, binning of the data is also required, and this limits the temporal resolution of the measurement to be 1 or 2 orders of magnitude lower than the photon count rate to overcome the effects of shot noise. To mitigate the effects of shot noise, some investigators have applied filters to the data prior to applying a threshold. This can substantially improve the time resolution of the experiment by mitigating some of the effects of shot noise, but there is still the difficulty associated with choosing a threshold. Recently, many methods, such as hidden Markov models, applications of information theory, photon statistics in the context of two colors, maximum likelihood and Bayesian inferential estimation of change points using Poisson statistics, wavelet correlation, and wavelet shrinkage have been developed and applied to single molecule data as a means of extracting more accurate information about the system under observation. Although direct, model-independent information theoretical approaches may also work well, especially when a kinetic model is inapplicable. HMM, which uses all the information from the data prior and posterior, has enjoyed wide applicability and success. However, this method needs a long sequence to train the HMM for the parameter extraction. Many important experimental data sets are far too short to satisfy this requirement, so that the algorithm will converge to a local maximum depending on the initialization of the emission probability distribution. Another problem of HMMs is the necessary prior knowledge of the number of the states.
Markov Random Fields假设一个随机变量序列按时间先后关系依次排开的时候,第N+1时刻的分布特性,与N时刻以前的随机变量的取值无关,却只与N时刻的取值有关。 激光点云的分布是一个典型的随机场,但是否具有Markov性质呢?国外那么多专家用改进的Markov Random Fields自动提取点云,似乎取得了很好的效果。典型的有Carnegie Mellon University的AMN(Associative Markov Network)和Moscow State University的NON-AMN。
《Dynamic Workflow Composition using Markov Decision Processes》, Prashant Doshi, Richard Goodwin and Rama Akkiraju IEEE International Conference on Web Services ( ICWS 04) Abstract The advent of Web services has made automated workflow composition relevant to web based applications. One technique, that has received some attention, for automatically composing workflows is AI-based classical planning . However, classical planning suffers from the paradox of first assuming deterministic behavior of Web services, then requiring the additional overhead of execution monitoring to recover from unexpected behavior of services. To address these concerns, we propose using Markov decision processes (MDPs), to model workflow composition. Our method models both, the inherent stochastic nature of Web services, and the dynamic nature of the environment. The resulting workflows are robust to non-deterministic behaviors of Web services and adaptive to a changing environment. Using an example scenario, we demonstrate our method and provide empirical results in its support. 1. Introduction business process integration and management (BPIM) AI-inspired planning techniques utilize Markov decision processes (MDPs) to model the problem of workflow composition t he structure of this paper: 1) Section 2briefly dwell on the workflow composition problem andsome related work 2) Section 3 introduce a motivating scenario. 3) Section 4introduce author's stochastic optimization framework and its application to workflow generation 4)Section 5 focuses onmodel learning approach. 5) Finally, Section 6 conclude this paper with a discussion 2. Dynamic Workflow Composition Definition: Optimal Workflow four distinct steps for composing workflows 1) identifying the required functionality; 2) semantic matching of Web services; 3) creating or updating the workflow; 4)executing and monitoring the workflow The problem of composing adaptive workflows 3. Motivating Scenario 4. Markov Decision Processes Definition Markov Decision Process (MDP) to find the optimal policy for the MDP 5. Model Learning a Bayesian learning algorithm Definition Kullbach-Leibler Divergence (KLD), that is, relative entropy two important conclusions: 1) First, the experiments validate our hypothesis that the Bayesian learning approach is effective for model learning. 2) Second, the results reveal an important observation that during learning, models of events less likely to be observed take more runs to converge. 6. Discussion primary focus:assembling the workflow at an abstract level, ignoring the implementation-level details. contributions: i) utilized a stochastic optimization framework, namely Markov decision processes ii) interleaved workflow generation and execution with model learning, 个人点评: 有新意,对比 博文 《review: Adaptive Service Composition Based on Reinforcement 》, 后者可以说是对此文照葫芦画瓢。 作者还有一篇相关 期刊文章 发表在 International Journal of Web Services Research Author: Prashant Doshi 值得关注, http://www.cs.uga.edu/~pdoshi/ Dynamic_Workflow_Composition_using_Markov_Decision_Processes.pdf 期刊 International Journal of Web Services Research 文章 《Dynamic Workflow Composition using Markov Decision Processes》对于ICWS上文章扩充
 标签: Markov
标签: Markov