一个流行学习demo,并且有源代码 里面实现的代码有一下文章: MDS Michael Lee's MDS code ISOMAP J.B. Tenenbaum, V. de Silva and J. C. Langford. A global geometric framework for nonlinear dimensionality reduction. Science, vol. 290, pp. 2319--2323, 2000. LLE L. K. Saul and S. T. Roweis. Think Globally, Fit Locally: Unsupervised Learning of Low Dimensional Manifolds . Journal of Machine Learning Research, v4, pp. 119-155, 2003. Hessian LLE D. L. Donoho and C. Grimes. Hessian Eigenmaps: new locally linear embedding techniques for high-dimensional data . Technical Report TR-2003-08, Department of Statistics, Stanford University, 2003. Laplacian Eigenmap M. Belkin, P. Niyogi, Laplacian Eigenmaps for Dimensionality Reduction and Data Representation , Neural Computation, June 2003; 15 (6):1373-1396. Diffusion Maps Nadler, Lafon, Coifman, and Kevrekidis. Diffusion maps, spectral clustering and reaction coordinates of dynamical systems LTSA Zhenyue Zhang and Hongyuan Zha. Principal Manifolds and Nonlinear Dimension Reduction via Tangent Space Alignment. SIAM Journal of Scientific Computing, 2004, 26 (1): 313-338. 原始链接: http://www.math.ucla.edu/~wittman/mani/index.html 本文引用地址: http://blog.sciencenet.cn/blog-722391-583977.html
ICML 2012 Maximum Margin Output Coding Information-theoretic Semi-supervised Metric Learning via Entropy Regularization A Hybrid Algorithm for Convex Semidefinite Optimization Information-Theoretical Learning of Discriminative Clusters for Unsupervised Domain Adaptation Similarity Learning for Provably Accurate Sparse Linear Classification ICML 2011 Learning Discriminative Fisher Kernels Learning Multi-View Neighborhood Preserving Projections CVPR 2012 Order Determination and Sparsity-Regularized Metric Learning for Adaptive Visual Tracking Non-sparse Linear Representations for Visual Tracking with Online Reservoir Metric Learning Unsupervised Metric Fusion by Cross Diffusion Learning Hierarchical Similarity Metrics Large Scale Metric Learning from Equivalence Constraints Neighborhood Repulsed Metric Learning for Kinship Verification Learning Robust and Discriminative Multi-Instance Distance for Cost Effective Video Classification PCCA: a new approach for distance learning from sparse pairwise constraints Group Action Induced Distances for Averaging and Clustering Linear Dynamical Systems with Applications to the Analysis of Dynamic Visual Scenes CVPR 2011 A Scalable Dual Approach to Semidefinite Metric Learning AdaBoost on Low-Rank PSD Matrices for Metric Learning with Applications in Computer Aided Diagnosis Adaptive Metric Differential Tracking (HUST) Tracking Low Resolution Objects by Metric Preservation (HUST) ACM MM 2012 Optimal Semi-Supervised Metric Learning for Image Retrieval Low Rank Metric Learning for Social Image Retrieval Activity-Based Person Identification Using Sparse Coding and Discriminative Metric Learning Deep Nonlinear Metric Learning with Independent Subspace Analysis for Face Verification ACM MM 2011 Biased Metric Learning for Person-Independent Head Pose Estimation ICCV 2011 Learning Mixtures of Sparse Distance Metrics for Classification and Dimensionality Reduction Unsupervised Metric Learning for Face Identification in TV Video Random Ensemble Metrics for Object Recognition Learning Nonlinear Distance Functions using Neural Network for Regression with Application to Robust Human Age Estimation Learning parameterized histogram kernels on the simplex manifold for image and action classification ECCV 2012 Metric Learning for Large Scale Image Classification: Generalizing to New Classes at Near-Zero Cost Dual-force Metric Learning for Robust Distractor Resistant Tracker Learning to Match Appearances by Correlations in a Covariance Metric Space Image Annotation Using Metric Learning in Semantic Neighbourhoods Measuring Image Distances via Embedding in a Semantic Manifold Supervised Earth Mover’s Distance Learning and Its Computer Vision Applications Learning Class-to-Image Distance via Large Margin and L1-norm Regularization Labeling Images by Integrating Sparse Multiple Distance Learning and Semantic Context Modeling IJCAI 2011 Distance Metric Learning Under Covariate Shift Learning a Distance Metric by Empirical Loss Minimization AAAI 2011 Efficiently Learning a Distance Metric for Large Margin Nearest Neighbor Classification NIPS 2011 Learning a Distance Metric from a Network Learning a Tree of Metrics with Disjoint Visual Features Metric Learning with Multiple Kernels KDD 2012 Random Forests for Metric Learning with Implicit Pairwise Position Dependence WSDM 2011 Mining Social Images with Distance Metric Learning for Automated Image Tagging
Dear Colleague, BMJ Learning is celebrating success following the completion of two million learning modules. To mark this milestone, we're throwing open our 1,000-strong collection of modules for free, for everyone, for one week. To thank you for helping us hit the two million mark, you can access hundreds of modules not usually available - free of charge any time during the week of July 2-9th. Whether it's our new, animated procedure based modules, journal-related CPD or anything from the A-Z of our offer (from Abdominal pain to Whooping cough), there's something extra for everyone. Here are some modules suitable forhealthcare professionalsto keep you busy in the mean time: Alcohol withdrawal: managing patients in the emergency department Arterial blood gases: a guide to interpretation Addison’s disease Upper gastrointestinal bleeding: a guide to diagnosis and management of non-variceal bleeding Acute kidney injury: a guide to diagnosis and treatment Best wishes, Dr. Helen Morant Editor, Online learning http://learning.bmj.com/learning/info/twomillionthmodule.html?utm_source=Adestrautm_medium=emailutm_campaign=2994utm_content=Celebrate%20with%20us%20-%20over%201%2C000%20free%20modules%20for%20one%20weekutm_term=BMJ%20LearningCampaign+name=SP%20250612%20healthcare%20professions%20weekly%20alert%20fre
一个流行学习demo,并且有源代码 里面实现的代码有一下文章: MDS Michael Lee's MDS code ISOMAP J.B. Tenenbaum, V. de Silva and J. C. Langford. A global geometric framework for nonlinear dimensionality reduction. Science, vol. 290, pp. 2319--2323, 2000. LLE L. K. Saul and S. T. Roweis. Think Globally, Fit Locally: Unsupervised Learning of Low Dimensional Manifolds . Journal of Machine Learning Research, v4, pp. 119-155, 2003. Hessian LLE D. L. Donoho and C. Grimes. Hessian Eigenmaps: new locally linear embedding techniques for high-dimensional data . Technical Report TR-2003-08, Department of Statistics, Stanford University, 2003. Laplacian Eigenmap M. Belkin, P. Niyogi, Laplacian Eigenmaps for Dimensionality Reduction and Data Representation , Neural Computation, June 2003; 15 (6):1373-1396. Diffusion Maps Nadler, Lafon, Coifman, and Kevrekidis. Diffusion maps, spectral clustering and reaction coordinates of dynamical systems LTSA Zhenyue Zhang and Hongyuan Zha. Principal Manifolds and Nonlinear Dimension Reduction via Tangent Space Alignment. SIAM Journal of Scientific Computing, 2004, 26 (1): 313-338. 原始链接: http://www.math.ucla.edu/~wittman/mani/index.html
邹晓辉:如何在大学教育层面开展阅读和写作的国家项目? 回答这个问题,至少要考虑: 1.当前大学在母语和外语以及自然语言和程序语言乃至通用俗语与专用术语这三类双语教学及研究甚至计算机交互三个方面的现状调查; 2.如何借鉴国内外这方面成功的做法及事例? 3.怎样搭建基于三类双语教学及研究甚至计算机交互网络平台? 附录 : NWP 国家写作项目 ( http://www.nwp.org/ ) Writing is Essential Writing is essential to communication, learning, and citizenship . It is the currency of the new workplace and global economy. Writing helps us convey ideas, solve problems, and understand our changing world. Writing is a bridge to the future . About NWP Our Mission The National Writing Project focuses the knowledge, expertise, and leadership of our nation's educators on sustained efforts to improve writing and learning for all learners. Our Vision Writing in its many forms is the signature means of communication in the 21st century. The NWP envisions a future where every person is an accomplished writer, engaged learner, and active participant in a digital, interconnected world . Who We Are Unique in breadth and scale, the NWP is a network of sites anchored at colleges and universities and serving teachers across disciplines and at all levels , early childhood through university . We provide professional development, develop resources, generate research, and act on knowledge to improve the teaching of writing and learning in schools and communities . The National Writing Project believes that access to high-quality educational experiences is a basic right of all learners and a cornerstone of equity. We work in partnership with institutions, organizations, and communities to develop and sustain leadership for educational improvement. Throughout our work, we value and seek diversity—our own as well as that of our students and their communities—and recognize that practice is strengthened when we incorporate multiple ways of knowing that are informed by culture and experience. A Network of University-Based Sites Co-directed by faculty from the local university and from K–12 schools, nearly 200 local sites serve all 50 states, the District of Columbia, Puerto Rico, and the U.S. Virgin Islands. Sites work in partnership with area school districts to offer high-quality professional development programs for educators . NWP continues to add new sites each year, with the goal of placing a writing project site within reach of every teacher in America. The network now includes two associated international sites . A Successful Model Customized for Local Needs NWP sites share a national program model , adhering to a set of shared principles and practices for teachers’ professional development , and offering programs that are common across the network. In addition to developing a leadership cadre of local teachers (called “ teacher-consultants ”) through invitational summer institutes , NWP sites design and deliver customized inservice programs for local schools, districts, and higher education institutions, and they provide a diverse array of continuing education and research opportunities for teachers at all levels. National research studies have confirmed significant gains in writing performance among students of teachers who have participated in NWP programs. The NWP is the only federally funded program that focuses on the teaching of writing . Support for the NWP is provided by the U.S. Department of Education , foundations, individuals, corporations, universities, and K-12 schools. NWP Core Principles The core principles at the foundation of NWP’s national program model are: Teachers at every level—from kindergarten through college—are the agents of reform ; universities and schools are ideal partners for investing in that reform through professional development . Writing can and should be taught , not just assigned, at every grade level. Professional development programs should provide opportunities for teachers to work together to understand the full spectrum of writing development across grades and across subject areas . Knowledge about the teaching of writing comes from many sources : theory and research, the analysis of practice, and the experience of writing . Effective professional development programs provide frequent and ongoing opportunities for teachers to write and to examine theory, research, and practice together systematically. There is no single right approach to teaching writing; however, some practices prove to be more effective than others. A reflective and informed community of practice is in the best position to design and develop comprehensive writing programs . Teachers who are well informed and effective in their practice can be successful teachers of other teachers as well as partners in educational research, development, and implementation. Collectively, teacher-leaders are our greatest resource for educational reform. http://www.nwp.org/cs/public/print/doc/about.csp
2012 International Workshop on Swarm Intelligent Systems (IWSIS2012) http://www1.tyust.edu.cn/yuanxi/yjjg/iwsis2012/iwsis2012.htm Special Session- Recent Advances on Opposition-Based Learning Applications Session Chair: Dr. Qingzheng Xu Department of Military Electronic Engineering, Xi’an Communication Institute, China Scope: Diverse forms of opposition are already existent virtually everywhere around us and the interplay between entities and opposite entities is apparently fundamental for maintaining universal balance. However, it seems that there is a gap regarding oppositional thinking in engineering, mathematics and computer science. A better understanding of opposition could potentially establish new search, reasoning, optimization and learning schemes with a wide range of applications. The main idea of opposition-based learning (OBL) is to consider opposite estimates, actions or states as an attempt to increase the coverage of the solution space and to reduce exploration time. OBL has already been applied to reinforcement learning, differential evolution, artificial neural network, particle swarm optimization, ant colony optimization, and genetic algorithm, etc. Example applications include large scale optimization problem, multi-objective optimization, traveling salesman problem, data mining, nonlinear system identification, image processing and understanding. However, finding killer applications for OBL is still a hard task that is heavily pursued. The objective of this special session is to bring together the state-of-art research results and industrial applications on this topic. Contributed papers must be the original work of the authors and should not have been published or under consideration by other journals or conferences. Topics of primary interest include, but are not limited to: l Motivation and theory of opposition-based learning l Opposition-based optimization techniques l Reasoning and search strategies in opposition-based computing l Real-world applications in signal processing, pattern recognition, image understanding, robotics, social networking, etc. l Other methodologies and applications associated with opposition-based learning Submission and review process: Submissions should follow the IWSIS2012 manuscript format described in the Workshop Web site at http://www1.tyust.edu.cn/yuanxi/yjjg/iwsis2012/iwsis2012.htm . All the papers must be submitted electronically in PDF format only via email to Dr. Qingzheng Xu at xuqingzheng@hotmail.com . All the submitted papers will be strictly peer reviewed by at least two anonymous reviewers. Based on the reports by the reviewers, the final decision on papers submitted to this Special Session will be taken by General Chairs of IWSIS2012, Prof. Zhihua Cui and Prof. Jianchao Zeng. All accepted papers will be published in some EI journals as regular papers : Important dates: Submission Date: April 20, 2012 Acceptance Date: May 20, 2012 Registration Date: June 1, 2012 Final version Date: June 1, 2012 Publication Date: All accepted papers will be published in EI-indexed international journals within the late of 2012 and early of 2013
Future work on social tagging The results from evaluations of social tags by experienced indexers in MELT highlighted a number of interesting issues that need further validation and investigation. Social tagging, as a feature in a conventional learning resource repository, is a very new phenomenon and it will take time before those interested in this approach have well developed evaluation methodologies and tools in this new context. Nevertheless, the MELT analysis shows that: Tags that expert indexers don't understand mostly constitute ‘noise’, but there are exceptions to this (see 2). Some tags travel across languages; i.e. people understand them even if they do not speak the language. These “travel well” tags can support retrieval in a multilingual context by facilitating the cross-border retrieval of resources. Some tags are understood only by a sub-group of users (e.g. “esl” = English as a Second Language) enhancing cross-border use and adding value for these sub-groups, but mostly they constitute ‘noise’ to others. Some tags correspond to descriptors in the LRE Thesaurus and can be used as indexing keywords for a resource, especially when the existing indexing is poor or the tag represents a narrower term. ”Thesaurus tags” can be used to determine the language equivalences between keywords, and affinities between tags and indexing keywords. Thesaurus terms could be used in order to determine affinities between tags, thus helping describe resources, as well as retrieval of resources in multiple languages. Tags can lead to interesting non-descriptors in the thesaurus and thus facilitate and enhance multilinguality. Tags can help enrich the thesaurus in terms of suggesting new descriptors based on how users have used tags to describe resources. Lots of food for thought here that can be investigated further once a critical mass of user-generated tags has been accumulated as a result of many thousands of teachers using the public version of the LRE portal in 2009. Look out for a fast expanding LRE tag cloud! The LRE tag cloud in May 2009
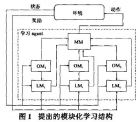
##一种新的多智能体Q 学习算法 郭锐 吴敏 彭军 彭姣 曹卫华 自动化学报 Vol. 33, No. 4 2007 年4 月 摘要 针对 非确定马尔可夫环境 下的多智能体系统, 提出了一种新的多智能体Q 学习算法. 算法中通过对联合动作的统计来学习其它智能体的行为策略, 并利用智能体策略向量的全概率分布保证了对联合最优动作的选择. 同时对算法的收敛性和学习性能进行了分析. 该算法在多智能体系统RoboCup 中的应用进一步表明了算法的有效性与泛化能力. 关键词: 多智能体, 增强学习, Q 学习 1 引言 机器学习 根据反馈的不同将学习分为: --监督学习 -- 非监督学习: 增强学习(Reinforcement learning) {一种以反馈为输入的自适应学习方法} 多智能体系统(Multi-agent systems) : 合作进化学习 Mini-Max Q学习算法 FOF Q 学习算法: 竞争 + 合作 2 多智能体Q 学习 2.1 多智能体Q 学习思想 增强学习 + 多智能体系统. the arising difficulties: -- 首先必须改进增强学习所依据的环境模型 -- 再者, 在多智能体系统中, 学习智能体应学习其它智能体的策略, 系统当前状态到下一状态的变迁 由学习智能体与其它智能体的动作决定, -- 2.2 多智能体Q 学习算法 学习策略 期望累计折扣回报 引入多个智能体的行为: 迭代: 多智能体Q 学习算法: 2.3 算法收敛性和有效性分析 2.3.1 算法收敛性证明 2.3.2 算法有效性分析 PAC 准则 3 学习算法在RoboCup 中的应用 RoboCup 机器人仿真足球比赛 4 结论 I comment: I will study reinforcement learing in MAS in the next step. the Q-learing algorithm for MAS will provide some insight and references to my future study. 一种新的多智能体Q学习算法.pdf this paper written by the same correspond author, which emphasize the architecture of agent in MAS: 一种新的多智能体系统结构及其在RoboCup中的应用.pdf *** ##一种新颖的多agent强化学习方法 周浦城, 洪炳镕, 黄庆成 电子学报 2006-8 摘要 : 提出了一种综合了模块化结构、利益分配学习以及对手建模技术的多agen t强化学习方法, 利用 模块化学习结构来克服状态空间的维数灾问题, 将Q学习与利益分配学习相结合以加快学习速度, 采用基于观察的对手建模来预测其他agent的动作分布. 追捕问题的仿真结果验证了所提方法的有效性. 关键词: 多agen t学习; Q学习; 利益分配学习; 模块化结构; 对手建模 1 引言 多agen t系统 + 强化学习: 1) 一种方式将多agent系统作为单个学习agent, 借助单agent强化学习 维数灾问题. 2) 另一种方式系统中每个agent拥有各自独立的强化学习机制. 由于多个agent协同学习, Note:对比 协同进化 2 强化学习 2.1 Q学习 Q-learning: 一类似于动态规划的强化学习方法 2.2 利益分配学习 Profit Sharing, PS 学习: 强化学习算法 3 提出的模块强化学习方法 学习agen t由三种模块构成: (1)学习模块LM, 实现强化学习算法. (2) 对手模块OM, 用于通过观察其他agent的动作来得到其动作分布估计, 以便评估自身动作值. (3) 仲裁模块MM, 用来综合学习模块和对手模块的结果. 3.1 对手建模 MAS: agent的动作效果 = 外界环境 + Other agents动作影响. 3.2 混合强化学习算法 author idea: PS-learning + Q-learning 3.3 仲裁模块决策 3.4 多agent学习过程 4 仿真 4.1 追捕问题 I comment: one of authors is Prof. 洪炳镕, whose robotic dance group attend the festival celebration of Spring in 2012. from various information source, I believe he and his team may be develop some program to collaborate robot dance and the kernel of system also come from the commerical product of foreign company. 一种新颖的多agent强化学习方法.pdf
 标签: Learning
标签: Learning![[CODE] manifold learning matlab code 一个流行学习的matlab代](http://image.sciencenet.cn/album/201206/20/085337lklznks5lfrknsni.jpg.thumb.jpg)