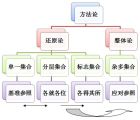
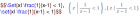交并集公理——关于“一”的哲学(上) 汉字中的“一”字,可以说是笔画最简单的汉字。和西方的用拉丁字母组成的数词相比,这个看上去像是横躺着的阿拉伯数字“1”,却充满了古代中国人所寄托的哲学情怀。先看看下面一段文字: “惟初太始,道立于一,造分天地,化成萬物” 这是什么?这就是中国人对“一”这个概念的哲学认知——许慎的《说文解字》对“一”的解释:所谓“一”,就是这个世界诞生前的状态。 和这个汉字相对应的德语词是“einheit”,大致相当于英语的“oneness”——统一性、完整性,大一统,它是从“ein(一)”派生而来,和汉字“一”的意思有着相当的重叠之处。最有意思的是,它还可以动词化:einen。 和西方语言不同的是,古汉语是没有句法意义上的词性的,一个“一”字如何使用端看使用者的“运用之妙,存乎一心”。杜牧的《阿房宫赋》第一句便是:六王毕、四海一。短短6个字,三个数词:6、4、1,可谓把数字用到了极致。不过依个人愚见,其中的“一”最为精妙,我更愿意把这个“一”字理解为动词,和德语那个einen有着同样意义的动词,这样就可以和前面的“毕”字相呼应,因为“毕”的意思是“停止”、“式微”或“衰落”,如果把“一”理解为动词,那么整个句子则对仗工整,无论“毕”还是“一”展示的都是一种过程的完成状态。更重要的,只有把 “一” 理解为动词,才可以精确地传达本篇笔记的核心内容——“并”与“交”的概念。所谓的“并”,就是合N为一的过程——归一。而归一,是中国文化中的一种理想境界,政治情怀,也是“并”操作背后的哲学理念。 无独有偶,在《Naive Set Theory》中,作者对“并”的解释也很传神:a sweeping generalization——横扫式的统一。什么叫“横扫式的统一”?那就是“秦王扫六合”后的“六王毕、四海一”,扫除一切屏障,实现“车同轨、书同文”的天下大一统。这个思想如果用集合的形式表示就是: (1) {秦、楚、燕、赵、韩、魏、齐} = {秦}, 其中{}中的每个字符代表一个集合。具体的形式就是: (2) 秦 = {a : a属于秦国人或x属于秦国土地} 楚 = {b : b属于楚国人或x属于楚国土地} 燕 = {c : c属于燕国人或x属于燕国土地} 赵 = {d : d属于赵国人或x属于赵国土地} 魏 = {e : e属于魏国人或x属于魏国土地} 齐 = {f : f属于齐国人或x属于齐国土地} 秦统一六国的方式正是这种“a sweeping generalization”——拆除六国各自为政所产生的政治、经济、文化、军事屏障,横扫千军如卷席后的天下统一。 “并”,作为集合操作的术语本身也具有“一”的原意:多个集合合在一起形成大一统的意味:union,而相应的过程则是unify——unification——合一、统一。这个过程最朴素的表达就是:在做了“一”的运算之后,我的是我的,你的也是我的。 书中对“并公理”的表述是: (3) 对于若干集合的聚集(collection),都存在一个集合,这个集合包含了属于聚集中至少一个集合的所有元素。 如果把这个集合的聚集看做是各个集合进行“并”运算之前的“集合的集合”,那么就应当存在一个论域集合U,使得聚集中某个集合中的元素的元素属于该集合的同时也应当属于U。在上面的语境中,U应当是天下所有的人或者土地的集合。 由于U包含了所有的人民和土地,因此就存在着不属于该集合聚集——战国七雄之外的化外之民和化外之地。因此要精确表达有论域作背景的U的元素,我们就要明确指出这个元素和所属集合、集合聚集的关系: 首先,基本元素是人或者土地:x∈U; 第二,一些基本元素是战国七雄中某个国家的人或土地:x∈X,X∈{秦、楚、燕、赵、韩、魏、齐}; 第三,{秦、楚、燕、赵、韩、魏、齐}构成集合的聚集C。把这三个要素放在一起,就得到关于“并”操作的形式表述: (4) {x∈U : 对于C中某个X,x∈X} 如果我们对U没有明确的要求,而且不再要求X的聚集C只限于“{秦、楚、燕、赵、韩、魏、齐}”,而是“天下大同”,所有的人民和土地,就称为对于“天下”的一般性表述: (5) U = {x : 对于C中某个X,x∈X} 这个U,就是真正的大一统,由天下所有的土地和人民构成的大一统,尽管现实中这些土地和人民分属不同的国家X,而所有国家的集合则是C。所谓“天下大同”,有两种情况,仍然存在着国家,另一种是没有国家这个组织存在。对前一种的表示我们可以简化为: (6) ∪ C,或者 ∪ {X: X∈C},或者 ∪ X∈C X 不管符号如何表示,“并”的核心思想就是“一”,其基本符号同样是大一统的 U 。如果真正的天下大同来到,没有国家、没有地域屏障,那么这个理想的画面就是这样的: (7) ∪ {X : X∈{A}} = A A,这个理想天国的A,就是著名的乌托邦——Utopia——人类的幸福乐土。从政治学意义上讲,这个乐土又回到了中国人对“一”的解释——惟初太始,道立于一。 当然,天下并不是如此理想,人类的杀伐征战总是在改变着我们对国家的认知。上世纪90年代,大国分裂成多个小国,欧洲多国形成准国家欧盟,天下事分分合合,这就是集合论中所有“并”操作背后的人类史:“并操作”遵循下列定律: 1.交换律—— A U B = B U A 2.结合律——( A U B) U C = A U (B U C) 3.幂等律—— A U A=A 4. 真子集——A ⊂ B 当且当A U B = B 5. 空集并——A U ∅ = A 大一统,深深地植入中国文化的核心,同时这也是这个文化看天下的方式。与这种世界观相对的,就是强调“个性解放”——世界上只有“一个”我,每个人都是不同的“自我”。这个世界观的集合论表示就是: {a} U {b} = {a, b} a和b虽然生活在一个集合中,但仍然可以把它们看做是独特的自我,在{a}或{b}中,a或b是它们自己世界的主宰,没有人和它们分享这个世界,但是某种命运以“并”的方式把它们联系在了一起,构成了它们共同的世界。因此当我们俯瞰一个集合 A = {a 1 , a 2 , a 3 , a 4 , …a n } 中的芸芸众生时,千万别忘记每一个a i 实际上都有自己的个性和世界,因为同样的, A = {a 1 } U {a 2 } U {a 3 } U {a 4 }…{a n }。 记住,{a 1 }并不是a 1 ,a 1 是一个个体,而{a 1 }是一个世界,一个由a 1 单独占有的世界,这个世界因为a 1 存在而存在,也因为a 1 消失而不存在,这就是集合中每个成员存在的价值,它们的集体存在,定义了这个集体,同时也定义了属于它们自己的世界。 集合的“并”,现代的商业术语称作“收编”或“收购”,是说一家强有力的公司凭借雄厚的实力将另外一家公司并为自己的一部分,这个过程有可能是将被合并的公司彻底消灭,只是将其构成元素——员工和知识产权收归于己,也有可能将被合并公司作为本公司的一个部门或者子公司,独立存在。如果你恰好是被合并公司的一员,这个合并行为并不影响你的个性,在{你}这个世界中,你是主宰,{你}是由你定义的,尽管你和他人同时定义了被收购公司和收购公司未来的命运。 集合的“并”,是世界存在的一种方式,是个性和统一的共同体;“一”这个承载了某种哲学理念的思想,从来就不是一个原子概念,“惟初太始,道立于一”,说的是统,多个集合所形成的大一统概念,而“造分天地,化成萬物”则是统之中的个性化——万物各不相同,“并”后的集合仍然可以看做是由每个元素构成的集合的集合。 下一篇,我们聊聊“交”——集合的另一个操作。
python的set和其他语言类似, 是一个无序不重复元素集, 基本功能包括关系测试和消除重复元素. 集合对象还支持union(联合), intersection(交), difference(差)和sysmmetric difference(对称差集)等数学运算. sets 支持 x in set, len(set),和 for x in set。作为一个无序的集合,sets不记录元素位置或者插入点。因此,sets不支持 indexing, slicing, 或其它类序列(sequence-like)的操作。 下面来点简单的小例子说明把。 x = set( 'spam' ) y = set( ) x, y (set( ), set( )) 再来些小应用。 x y # 交集 set( ) x | y # 并集 set( ) x - y # 差集 set( ) 记得以前个网友提问怎么去除海量列表里重复元素,用hash来解决也行,只不过感觉在性能上不是很高,用set解决还是很不错的,示例如下: a = b = set(a) b set( ) c = c 很酷把,几行就可以搞定。 1.8 集合 集合用于包含一组无序的对象。要创建集合,可使用set()函数并像下面这样提供一系列的项: s = set( ) #创建一个数值集合 t = set( Hello ) #创建一个唯一字符的集合 与列表和元组不同,集合是无序的,也无法通过数字进行索引。此外,集合中的元素不能重复。例如,如果检查前面代码中t集合的值,结果会是: t set( ) 注意只出现了一个 'l' 。 集合支持一系列标准操作,包括并集、交集、差集和对称差集,例如: a = t | s # t 和 s的并集 b = t s # t 和 s的交集 c = t – s # 求差集(项在t中,但不在s中) d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中) 基本操作: t.add( 'x' ) # 添加一项 s.update( ) # 在s中添加多项 使用remove()可以删除一项: t.remove( 'H' ) len(s) set 的长度 x in s 测试 x 是否是 s 的成员 x not in s 测试 x 是否不是 s 的成员 s.issubset(t) s = t 测试是否 s 中的每一个元素都在 t 中 s.issuperset(t) s = t 测试是否 t 中的每一个元素都在 s 中 s.union(t) s | t 返回一个新的 set 包含 s 和 t 中的每一个元素 s.intersection(t) s t 返回一个新的 set 包含 s 和 t 中的公共元素 s.difference(t) s - t 返回一个新的 set 包含 s 中有但是 t 中没有的元素 s.symmetric_difference(t) s ^ t 返回一个新的 set 包含 s 和 t 中不重复的元素 s.copy() 返回 set “s”的一个浅复制 请注意:union(), intersection(), difference() 和 symmetric_difference() 的非运算符(non-operator,就是形如 s.union()这样的)版本将会接受任何 iterable 作为参数。相反,它们的运算符版本(operator based counterparts)要求参数必须是 sets。这样可以避免潜在的错误,如:为了更可读而使用 set( 'abc' ) 'cbs' 来替代 set( 'abc' ).intersection( 'cbs' )。从 2.3 . 1 版本中做的更改:以前所有参数都必须是 sets。 另外,Set 和 ImmutableSet 两者都支持 set 与 set 之间的比较。两个 sets 在也只有在这种情况下是相等的:每一个 set 中的元素都是另一个中的元素(二者互为subset)。一个 set 比另一个 set 小,只有在第一个 set 是第二个 set 的 subset 时(是一个 subset,但是并不相等)。一个 set 比另一个 set 打,只有在第一个 set 是第二个 set 的 superset 时(是一个 superset,但是并不相等)。 子 set 和相等比较并不产生完整的排序功能。例如:任意两个 sets 都不相等也不互为子 set,因此以下的运算都会返回 False :ab, a==b, 或者ab。因此,sets 不提供 __cmp__ 方法。 因为 sets 只定义了部分排序功能(subset 关系),list.sort() 方法的输出对于 sets 的列表没有定义。 运算符 运算结果 hash(s) 返回 s 的 hash 值 下面这个表列出了对于 Set 可用二对于 ImmutableSet 不可用的运算: 运算符(voperator) 等价于 运算结果 s.update(t) s |= t 返回增加了 set “t”中元素后的 set “s” s.intersection_update(t) s = t 返回只保留含有 set “t”中元素的 set “s” s.difference_update(t) s -= t 返回删除了 set “t”中含有的元素后的 set “s” s.symmetric_difference_update(t) s ^= t 返回含有 set “t”或者 set “s”中有而不是两者都有的元素的 set “s” s.add(x) 向 set “s”中增加元素 x s.remove(x) 从 set “s”中删除元素 x, 如果不存在则引发 KeyError s.discard(x) 如果在 set “s”中存在元素 x, 则删除 s.pop() 删除并且返回 set “s”中的一个不确定的元素, 如果为空则引发 KeyError s.clear() 删除 set “s”中的所有元素 请注意:非运算符版本的 update(), intersection_update(), difference_update()和symmetric_difference_update()将会接受任意 iterable 作为参数。从 2.3 . 1 版本做的更改:以前所有参数都必须是 sets。 还请注意:这个模块还包含一个 union_update() 方法,它是 update() 方法的一个别名。包含这个方法是为了向后兼容。程序员们应该多使用 update() 方法,因为这个方法也被内置的 set() 和 frozenset() 类型支持。
博文“ 谈蝉说生死 ”提及周作人《看云集》。“看云”二字来自唐·王维( 701~761 )诗句“行到水穷处,坐看云起时”。读诗之后又回味了30多年前学习“无穷”时的惊奇,因而略述几句,以为纪念。 1 自然数 1、2、3、4、5、6……一一数下去,没有穷尽。2、4、6、8、10……是偶数,其余是奇数,当然都是无穷的。又,0是印度人发明的,并不能算作自然数。 自然数乘以 2 就是偶数,因而 每一个自然数都能找到一个偶数与之对应,即自然数不会比偶数“更多” ;当然偶数也不会比自然“更多”。就“无穷多”而言,偶数与自然数级别相等,称为“可列集”。集或集合就是具有某一性质东西( 雅称元素 )的全体。 有限个乃至 可列个 可列集的总合,其元素也是可列 。可列集 A 1 、 A 2 、 A 3 、 A 4 …… A 1 ={ a 11 , a 12 , a 13 , a 14 , a 15 ,…… } A 2 ={ a 21 , a 22 , a 23 , a 24 , a 25 ,…… } A 3 ={ a 31 , a 32 , a 33 , a 34 , a 35 ,…… } A 4 ={ a 41 , a 42 , a 43 , a 44 , a 45 ,…… } ……………………………… 所有元素可按下标之和逐步列出 A ={ a 11 , a 12 , a 21 , a 13 , a 22 , a 31 , a 14 , a 23 , a 32 , a 41 , a 15 , a 24 , a 33 ,…… } ; 集合 A n 的第 m 元素 a nm 列于第 ( n + m -1)( n + m -2)/2+ m 位 . 有理数是自然之比值 。若记 a nm = n / m ,则每一个正有理数对应于 无限个 a nm ,而后者可列, 有理数的全体当然也是可列的。 需要知道, 有理数之平均值还是有理数,因而任意两个有理数之间有无穷个有理数;而全部有理数竟可以按顺序一一排列出来 ,竟与自然数同等“( 无穷 )多”。这是何等地令人惊奇啊。 2 古希腊的毕达哥拉斯(约前 580-前500 )发现直角三角形两直角边平方之和等于斜边之平方,即勾股定理。直角边为 3 和 1 时,斜边平方为 10 。以反证法说明该斜边不是有理数。 若斜边是有理数,则有 ( n / m )^2=10 ,当然, 自然数 n 和 m 不能都是 10 的倍数,不然就先进行约简 。于是, n ^2=10 m ^2 ; n 得是10 的倍数, n =10 k ;也就有 10 k ^2= m ^2 。这必然要求 m 也是 10 的倍数, 与前述条件不符 。顺便说一句,毕达哥拉斯的学生希帕索斯发现, 任何有理数的平方都不可能等于2 ;该认识不能得到老师的认可,又因将此传到学派之外而被判罪溺死。其时中国的孔子大约已经五十而知天命啦。 有理数并不是数的全部。我们要问, 所有的数能与自然数对应而可列吗?不能! 仍反证法说明。 0~1 之间的数可以小数表示,假设其可列 B 1 =0. b 11 b 12 b 13 b 14 b 15 …… B 2 =0. b 21 b 22 b 23 b 24 b 25 …… B 3 =0. b 31 b 32 b 33 b 34 b 35 …… B 4 =0. b 41 b 42 b 43 b 44 b 45 …… …………………………… 若 b nn ≠ 5 令 b n =5 ,若 b nn =5 令 b n =4 ; 则小数 B =0. b 1 b 2 b 3 b 4 b 5 ……不在上述排列之中 ,因而原假设不能成立。 0~1之间的 数为不可列,其比有理数要“无穷得多”。 3 为叙说便利,将 a ≤ x ≤ b 的数 x 全体记为闭集 ;而不包含端点则记为开集( a , b )。 基于一一对应的观点, 由 y =3 x 知道 与 的数或点具有相同数量;由 y =tan(180 x - 90)ordm; 知道 与所有数或整个数轴上点具有相同数量。局部并不少于全体! 若建立直角坐标系,边长 1 的正方形内点可用一对小数表示。 X =0. x 1 x 2 x 3 x 4 x 5 … … Y =0. y 1 y 2 y 3 y 4 y 5 …… 其与小数 C =0. x 1 y 1 x 2 y 2 x 3 y 3 x 4 y 4 x 5 y 5 ……对应,即平面内每一个点 ( X , Y ) 都有不重复的 数 C 与 其对应;因而正方形内点不会多于线段 内的点,至于少当然也是不会的!很容易说明,线段 内的点与整个平面、整个空间的点具有相同的“无穷多” 。 4 在介绍“最惊奇”的无穷之前 ,先简单说一下数的进制 。时间之外,我们用十进制,逢十进位:3 4表示 3个十 、 4个1;而0.54则表示5个“十分之一”、4个“十分‘十分之一’”。计算机以线路之通、断表示0、1,采用二进制。十进制的9写成二进制就是1001;小数也可换成二进制,十进制0.25和0.75写成二进制就是0.01和0.11。三进制则用0、1、2来表示数,并不用符号3。 将数集 挖掉中间三分之一, 用三进制表示时 所余两段是 及 。方括号表明包含端点,而 新增端点标为红色 。再挖掉这两段中间三分之一,则所余为 和 及 和 ;第三次挖后是 、 和 、 以及 、 和 、 ;依次挖除不止。 显然,端点不会因挖除消失。最终整个 被挖掉, 留下称为 康托尔尘集(1883)的无穷多个点 。 对上述红色数字作“ 1改为0,2改为1 ”的变换,得0.0,0.1; 0.00,0.01,0.10,0.11 ; 0.000,0.001,0.010,0.011,0.100,0.101,0.110,0.111 ;……。每组数字分别是1位、2位、3位……的二进制小数全体。这就是说, 中每一个二进制数都在 康托尔尘集中找到 ( 无穷多个 ) 对应点 , 因而 点数不多于 康托尔尘集,当然后者也不会更多 。 总长为零的 康托尔尘集与 数集、整个平面、整个空间的点具有相同的“无穷多”;而尽管 任意两个有理数之间有无穷个有理数, 全部有理数却只是与自然数同等“( 无穷 )多”。说到无穷,真是不能想当然啊。 附录: 20年前用扑克牌算24。偶尔遇见些有趣的算例:如 (13*7 + 5) / 4 和 (13*11 + 1) / 6 等。 也曾主动作些研究,如 7 * (3 + 3 / 7 ) 和 8 / (3 – 8 / 3 ) 可是在梦里想出来的啊。引入分数而在有理数范围内计算,思路开阔 也就 “生存空间”增加!自那以后就将“这算不出来”改口为“我算不出来”。文史研究“ 说有易,说无难 ”,真是这样呢。 意大利人 L. Fibonacci (1170 – 1250) 以兔子繁殖为例引入数列: 兔子月初出生,两个月整后即可每月生育一对 , 其前十个及第 20 和 30 个的月底数是: 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, …, 6765, …, 832040, … 该数列可定义为: F (0)=0 , F (1)=1, F ( n +2)= F ( n +1)+ F ( n ) 方程 q 2 = q +1 的根 q 1 =(1+sqrt(5))/2 和 q 2 =(1–sqrt(5))/2 : 数列可表示为 F ( n ) =( q 1 n – q 2 n )/sqrt(5) , abs( q 2 )1 可不予考虑, F ( n ) 近似于公比 q 1 =1.6180 … 的等比级数,倍增时间 1.44 月。 为表示整数列竟引入无理数 sqrt(5) ,得在实数范围内计算才行。 假设老鼠 生育三胎后月底前死亡。 前十个月及第 20 和 30 个的月底数是: 1, 1, 2, 3, 4, 6, 9, 13, 19, 28, …, 1278, …, 58425, … , 满足 S ( n +3) = S ( n +2) + S ( n ) , 老鼠有初生及 1~3 月四龄,在 n +2 月底的数量分别为 s0 , s1 , s2 , s3 。 因 s3 在 n +3 月生育后死亡,对总量增加没有贡献;而 s0 尚不能生育。 S ( n +3) 比 S ( n +2) 的增加量是 s1+s2 。 s1 就是 n +1 月的初生鼠;而 s2 是 n +1 月的 1 龄鼠、 n 月的初生鼠。 n +1 月初生鼠数量 s1 就是 n 月 1~3 龄鼠数量,与 n 月的初生鼠数量即 s2 之和等于 n 月总量 S ( n ) 。 特征方程 q 3 = q 2 +1 ;记 q = r +1/3 即 r 3 – r /3– 29/27=0 ; 拆分 r = x + y , x 3 , y 3 = /2 实数三次方根为 X =1.02370 … , Y =0.10854 …。记 ω=(–1+i*sqrt(3))/2 , q 1 = X + Y + 1/3 =1.46557 …, q 2 = X ω+ Y ω 2 + 1/3 , q 3 = X ω 2 + Y ω + 1/3 S ( n ) = aq 1 n + bq 2 n + cq 3 n 满足递推关系, 由 S (0)=1, S (1)=1, S (2)=1 确定 a =0.61149… q 2 和 q 3 为共轭复根,由维达定理知模长为 sqrt(1/ q 1 )=0.82603 … 1; S ( n ) 近似为公比 q 1 = 1.46557 … 的等比级数,倍增时间 1.81 月。 计算表明, S ( n ) 就是 aq 1 n 的整数取值。 (本段内容摘自笔者未完成的文章,相关分析计算为自己所做) 为确定整数列的通项公式竟引入虚数 i ,需在复数范围内计算才行。 解决问题可能需要在高于问题的层次上进行; 陷入困境也得登高望远才能寻找出路。
个体 - 标志值 - 集合 和它的复杂程度之七 ( 7 )复杂程度的定律 (张学文, 2008-7-22 ) 1. 最复杂原理 l 个体集的随机性 掷一个骰子,它出现几点(那点向上)就有随机性,从一副麻将牌中随便取一张牌,它究竟是什么牌也有随机性。玩麻将牌者要拿 13 张牌,这 13 张牌就构成了一个个体集(群体)。显然在没有拿到牌之前,这付牌究竟是什么也有随机性。 100 位顾客买了那些东西,他们的花费各是多少?在 事先也有随机性。看来,某些 个体集及其分布函数究竟是什么的随机性问题是值得研究的 。而这也就引出了 不同的个体集 (如抓 13 张麻将牌) 有不同的出现概率问题 。现在我们设法把它量化和深化。 l 红绿灯模型 某人上班要经过 10 个红绿灯路口。针对每次上班可以问:你遇上了几次红绿灯。本问题的答案显然有随机性。从个体集语言的角度看,经过 10 个有红绿灯的路口等价一个个体集有 10 个个体,红灯、绿灯对应两种标志值。而回答了红灯(或者绿灯)的出现次数也就等价于知道了分布函数(不同颜色的灯各有多少)。如果遇到的红灯次数被概率计算出来了也就知道了 不同的个体集(分布函数)的出现概率(机会) 。 本问题是概率论中的二项分布问题。设红绿灯的出现概率都是 0.5 (相等),经过 10 次路口遇到 m 次红灯的概率 p ( m ) 为 p ( m ) = {10! / }(0.5) 10 ( 11 ) --- 表 8 第二行给出了不同的红绿灯次数 m 对应的不同的出现概率 p ( m ) ,第三行是利用复杂程度公式( 9 )计算出来的对应的复杂程度值。 表 8 不同红绿灯的出现概率 (不同的个体集、分布函数、复杂程度的出现概率不同) 红灯次数 m m =0 m =1 m =2 m =3 m =4 m =5 m =6 m =7 m =8 m =9 m =10 该事件出现的概率 1024 1 10 45 120 210 252 210 120 45 10 1 复杂程度 ( 比特 ) 0 4.6 7.2 8.8 9.7 10 9.7 8.8 7.2 4.6 0 表 8 说明: 出现概率最高的个体集(事件)也是复杂程度最大的个体集(事件) 。在概率的对数与复杂程度的坐标图(略)上它们是直线关系。 l 最复杂原理 如果标志值不仅只是两个(红绿灯)而是 k 个可能值 x 1 , x 2 ,, x i ,, x k 、而它们的出现的概率 p 1 , p 2 ,, p i ,, p k (也称为先验概率)可以彼此不相同、个体的总个数相当多(可以利用 Stirling 公式 ln N != N ln N-N ),利用概率论中的多项式分布公式,可以得到下面的关系 ln P = C + ni ln pi i=1,,k ( 12 ) n i 是概率为 p i 的标志值占有的个体数量。 --- 这个公式体现了不同的个体集的出现概率 P 与其复杂程度 C 的关系。 它表示该个体集的出现概率的对数等于该个体集的复杂程度再加上另外一项。显然当概率达到最大值时,复杂程度与另外一项的合计值也达到最大值。概率最大的事情自然是在一次实验中最容易出现,所以最容易出现的个体集是复杂程度与另外一项的合计值最大的个体集。 另外一项在本例中包括了各个结局的出现概率,它对应着一种限制、约束条件。在另外的场合它的外型可能不同。但是它都包括着一些约束条件。考虑到有的个体集的出现还会附有其他的约束条件,我们把另外一项更含糊化为在限制条件下。于是上面的公式、红绿灯的例子、概率公理和以后的例子,我们把: 有随机性的客观事物(个体集)都自动使自己内部状态的复杂程度在限制条件下达到最大值 称为 最复杂原理。 最复杂原理的正确性体现于多次实践中它经常是对的,而不是每次必然正确,它与正方形的面积等于边长的平方之类的确定性规律在品格上是不同的。 l 定性的例子 你在街上会遇到很多人,有买东西的、上学的、做生意的、出差的、看病的等等。把遇到的人看成是一个个体集,根据最复杂原理这个个体集内的人(个体)的活动目标(标志值)会自动最复杂化。从商店出来的人都买了相同商品的事件的出现概率就非常小的,最容易出现的情况是买什么东西的人都有。所以最容易出现的也正是复杂程度最大的。你把一个玻璃杯摔碎了,碎玻璃的大小都相同?根据最复杂原理,它们是尽量地不相同,碎玻璃的大小尽量复杂化。仔细想想,符合最复杂原理的事物几乎是司空见惯。 l 定量的例子 斩乱麻问题 最复杂原理不仅在生活的事例早已司空见惯,而且也可以推导出很多定量规律。 利用分布函数可以计算该个体集的复杂程度。对此也可以 反过来思考 :对于有随机性的个体集,根据最复杂原理(复杂程度最大),能否反算出分布函数? 这个问题非常有吸引力。但是,在离散变量的情况要利用求函数的极值的技巧反求自变量(分布函数)。在连续变量的情况下就要利用变分技术去反算未知函数(连续型的分布函数)。拉哥朗日乘子方法经常帮助我们达到目标。现以 斩乱麻问题 为例说明之。 把长为 L 的绳子 随机地 切割成充分多的 N 段,问 不同长度的线段各有多少 。这就是斩乱麻问题 。把切碎的绳子看作是个体集,这就是利用随机性从理论推测其分布函数。 切割的随机性造成了线段长短不齐,它体现了事物的 复杂性 。以 f(x) 这个分布函数表示不同长度的线段占的百分比(权重),那么它对应的复杂程度为 C =- Nf ( x )ln f ( x )d x ( 13 ) 切割当然不是烧掉,切割后的线头总长度应当等于 L ,即 L = Nxf(x )d x ( 14 ) 根据最复杂原理, C 应当在一定的约束条件下达到最大值。而上式是一个约束,另外百分比的合计值应当等于 1 ,即 1= f(x )d x ( 15 ) 也是一个约束条件。 现在的问题是:在( 14 )、( 15 )的约束条件下使 C 最大的分布函数 f(x ) 应当是什么。根据求泛函数极值的拉哥朗日方法,构造一个新的函数 F : F =- f(x )ln f( x)dx + C 1 + C 2 ( 16 ) -- 这里的 C 2 , C 2 是待定常数。很显然,复杂程度 C 达到最大值, F 也达到了最大值。在 F 达到最大值(体现最复杂原理,也考虑了本问题的特殊约束条件)时它对未知函数 f(x ) 的变分应当等于 0 。利用 F 对 f 的变分为 0 ,我们得到 f ( x )=exp ( -1+ C 1 x + C 2 )。 -- 利用( 14 )和( 15 )消去未知数 C 2 , C 2 解得 f(x )= ( N/L ) exp(- Nx/L ) 注意到 L/N 的含义是线头的平均长度,以 a 表示它 ( 也是常数 ) ,有 f(x )=(1/ a )exp ( 17 ) 它是一个负指数函数。即一堆斩乱麻中,不同长度的线头占的百分比(分布函数),应当是 负指数函数 (相对密度分布函数)。 它显示长度 x 短(小)的线头多而长线头很少。 根据相对密度分布函数的定义,线头长度在 x x+ x 范围的有 Nf(x ) x 段。如 L = 200 米 ,切成 N =20000 段(平均值 a = 1cm ),可以计算出长度在 3 4 cm 范围的线头有 604 段,占总量的 3% 。 我们可以做一个 数值模拟实验 以得到一个斩乱麻的样本。对比显示最复杂原理得到的理论分布与模拟实验结果的 一致的 。这说明最复杂原理与实际相符合。例子中虽然利用了复杂程度最大,但是没有计算复杂程度的最大值究竟是多少。原因是我们主要兴趣是利用复杂程度最大去推算理论的分布函数。 一般地说,只要某个体集具有随机性,就可以 利用最复杂原理配合不同的约束条件得到不同的理论分布函数 。客观存在的有随机性的个体集很多,所以利用最复杂原理求分布函数的一般方法有广泛的应用和价值。 l 熵原理与最复杂原理 我们从不同的个体 - 标志着 - 集合的出现概率入手,利用了概率最大对应复杂程度最大,从而得到了复杂程度最大的个体集也就是出现概率高的个体集。我们把它称为最复杂原理。由于已经说明热力学熵是复杂程度的特例,所以联系着热力学熵的热力学第二定律(熵原理,熵最大原理)也是最复杂原理的特例。 2. 复杂度定律 复杂程度是物质自身天然具有的属性,它和质量、能量一样地真实。关于物质的质量、物质的能量已经有了质量守恒、能量守恒定律,与之对应也应当 存在一个关于物质的复杂程度的变化规律,现在暂称为复杂度定律 。限于篇幅这里仅指出某些观点: l 个体集概念有层次性,复杂程度也具有层次性。不同层次(形态)的复杂程度都客观存在。这类似物质的能量有化学能和核能。不同形态的能量可以互相转化, 不同层次(形态)的复杂程度也可以互相转化。 l 有限的物质仅具有有限的质量和能量,它也仅具有有限的复杂程度。 物质可以无限分隔的观点等价于有限物质的复杂程度为无穷大,这个观点使复杂程度概念失去物质性,所以它是错误的。 l 建议 把目前流行的 世界的 三元观 (物质 + 能量 + 信息)修改为 物质属性 的三元观 (质量 + 能量 + 复杂程度)。 l 存在着质量变换机构(如木器厂)、能量变换机构(如水利发电厂)和信息变换机构(如电视机),但是使 输出的质量、能量、信息大于出入的变换机构是不存在的 。 l 爱因斯坦的质量能量公式可能要扩大为 质量、能量、复杂程度之间的定量互相转化关系 ,而其总量具有保守性。写为公式就是,对于孤立系统,有 m + E / v 2 + k C =0 ( 18 ) 这里的 v 是光速、 C 是复杂程度、 m , E 分别是质量和能量。而 k 是待定常数。 l 我们暂且 把上面的认识连同最复杂原理合称为复杂度定律 。 3. 小结 根据个体集(客观事物)的分布函数,利用公式( 9 )可以计算该广义集合的内部状态的复杂程度。具有随机性的广义集合,它的复杂程度常常是在一定约束条件下的最大值。利用这个最复杂原理可以推导很多事物(个体集)的理论分布函数。 复杂程度是客观物质具有的基本物理量,它与质量、能量一样的真实,在一定的意义下它与信息熵成正比例。关于客观事物的复杂程度的一般规律与最复杂原理一并称为复杂度定律。 本部分的内容取自 2002 年《物理与工程》杂志 12 卷第 5 期上 组成论 介绍(中)一文,但是做了一些删减、修订、补充。
个体 - 标志值 - 集合 和它的复杂程度之五 ( 5 )个体集的表示、运算和特征量 张学文 20080630 在数学中一切进步都是引入符号(表意符号)后的反应――皮亚诺( G.Peano ) 让个体概念进入科学领域,还需要引入有关的符号以及量化、运算方法 1. 字符多项式 我们一般地把有 p 项组成的 a 1 x 1 +a 2 x 2 ++a i x i +a p x p 的式子称为字符多项式。在外型上,字符多项式类似初等代数里的多元一次多项式,但是它们的各个 a i 和 x i 都可以是独立的,有一定意义的 字符串 (不再单纯是数了)。而 + 号也需要针对需要去定义(说明)。由于它们经常不再是数,所以连写在一起,也不具有数的乘法的意义。 这里有 9 个水果: 3 个苹果, 2 个梨, 4 个香蕉,可以用字符多项式写为 ( 3 个)(苹果) + ( 2 个)(梨) + ( 4 个)(香蕉)。它对应的字符多项式里的字符串见表 6 表 6 例子里的各个字符串在字符多项式一般公式中的含义 符号 a 1 a 2 a 3 x 1 x 2 x 3 含义 3 个 2 个 4 个 苹果 梨子 香蕉 而字符多项式里的 + 号具有还有的意义(不是强行把含义不同的东西做 代数 加法)。 数学老师会告诉我们 3 个苹果不能与 2 个梨做加法,因为它们的单位不同。但是这里对加号有了另外的理解,于是 3 个(苹果) +2 个 ( 梨 ) 就是合格的表达式了。显然, 3 个(苹果) +2 个 ( 梨 ) = 2 个 ( 梨 )+3 个(苹果)。 文献【 3 】初步讨论了字符多项式和它的一些应用。哪里还指出它可以表示各种表格。下面我们要用它表示个体集。 2. 个体集的符号表示 对于个体集本身,我们一般用被方括弧包起来的大写粗斜体的字母表示它(这与集合的表示类似)。如用 表示盘子里有 9 个水果: 3 个苹果, 2 个梨, 4 个香蕉。 、 、 等等都是可以用的符号。 3. 离散的分布函数的符号表示 鉴于经常出现分布函数的自变量不是过去常用的连续变量而可以是离散的特征标志(如名字是苹果、梨、香蕉的水果、兰色的,黄色的 .. ),所以我们推荐用 字符多项式去表示分布函数 。例如前面的例子里,我们就用下式表示这个个体集的分布函数 = ( 3 个)(苹果) + ( 2 个)(梨) + ( 4 个)(香蕉) 这里的 代表了一个个体集,而等号后面表示该个体集的分布函数。 显然 =15 个(儿童) +16 个(成年人) +9 个(老年人)表示了不同年龄段的人各有多少, 就是一个分布函数明确的个体集。这里把园括号省略了。 =14(70 分以下 )+25 ( 70-90 分) +10 ( 90 分以上)表示了一次考试的全班成绩的个体集的分布函数,它告诉我们 70 分以下的学生有 14 个, 70 到 90 分的学生 25 个,高于 90 分的学生有 10 个。 根据上面的说明,我们一般用方括弧包起来的大写粗斜体的字母表示个体集本身;而用字符多项式表示该个体集的分布函数。这里的等号=体现了前面的认识:知道了它的分布函数,也就 等于 知道了一个确定的个体集。而加号 + 的意义是还有、还包括有的意思。 如果再借用数学里的求和符号,个体集的分布函数就可以一般的写为下面格式: = n i x i 这里的各个 x i 是彼此不同的标志值(也称为变量);而各个 n i 是对应于该标志值的个体的数量(这里用符号 n 代替了 a , 它包含计量单位个)。我们也用系数称呼它。 对于分布函数是连续变量的情况(标志值是连续变化的),它们对应的个体数量也是连续变化的情况(在个体数量十分大的情况下才会出现化离散为连续的数学处理技巧问题)出现这个问题,我们依然可以用数学里惯用的连续函数去表示它。 4. 个体集的运算 如果我们给某概念一个比较严的定义,而提不出随后有什么好处(定量的计算、新规律的发现 )这样的定义也就没有吸引力了。 已知甲小学的不同年级各有多少学生,还知道乙小学不同年级各有多少学生。求两个学校合并以后的不同年级各有多少学生。如果用个体集 分别表示两个学校的学生个体集,两个小学合并以后的个体集用 表示,那么个体集 就是 、 的和。这里的和是一种数学运算,这可以写为 = + 如何对两个个体集做加法运算?其实,运用代数里的多项式加法(合并同类项)正合适。在这里已经看到我们定义的字符多项式的好处。 《组成论》里介绍了个体集(哪里称为广义集合)的某些运算规则。它把我们过去熟悉的一些逻辑和代数运算规则,如加、减、乘、除等,引用到个体集中。通过这些运算可以得到含义明确的新的个体集。个体集不仅成为可以运算的对象,而且通过运算扩展了我们的知识。 5. 个体集的某些特征量(参数) 个体集存在一些重要的特征量或者说重要参数。 5.1 个体集的 个体总数 N :由于我们突出了个体的完整性(量子化)、离散化(现在时髦的称呼是数字化)所有个体集里所包括的个体的数量应当是个正整数。这个正整数自然称为该个体集的个体总数。这个小学校有 400 学生,中国有 13 亿人、哪个盘子里有 7 个水果都是例子。根据定义,个体集的个体总数显然是个体集的分布函数多项式表示下的各个系数的和,即 N = n i i =1, ,p 5.2 个体集的标志值的 平均值 m :如果某一个体集的各个标志值 x i 是 物理量 (包括单位)而不是字符串,那么通过下面公式得到的数值显然应当称为该个体集的标志值的平均值(与统计学里的定义一致) m = n i x i /N ( i =1p) 公式中的 n i 和 x i 都是数,而且这里是真的在 n i 和 x i 进行普通的代数运算(相乘)。运算得到的 m 的量纲应当与 x i 相同。 甲班的学生 - 年龄个体集为 = 3 个( 12 岁) +15 个( 13 岁) +11 个( 14 岁) +1 个( 15 岁) 那么甲班学生的平均年龄 m 显然是 M=(3*12+15*13+14*11+1*15)/(12+15+14+1)=13.3 即平均年龄是 13.3 岁。 5.3 个体集内不同标志值占的百分比(权重) f i :它等于具有标志值 x i 的个体数量 n i 与总体内的个体总量 N 的比值。即 f i = n i / N 百分比本来就是大家熟悉的统计量。现在用到这里了。 显然,各个标志值的 f i 的合计值应当等于 1 。 有时这被称为归一性。 1= f i = n i /N i =1, ,p 表 7 可以帮助理解上面谈到的一些特征量的关系。 表 7 个体集的一些特征量的关系 一般符号表示 总计 标志值(区间) x 1 x 2 x i 从下界到上界 个体数量 n 1 n 2 n i N 比例 n 1 / N n 2 / N n i / N N / N 百分比 f 1 f 2 f i 下面是特例 总计 年龄(岁) 12 13 14 15 12-15 学生(个) 3 15 11 1 30 百分比 3/30 15/30 11/30 1/30 30/30 定义: 百分比矢量 f 是个体集必然具有的一个矢量,它的各个分量就是具有特定的标志值 x i 的个体的数量与个体集内个体总量的比值 n i / N ,即 f i ( i =1,2, )。 如本班有 50 个同学,女生占 30 人,男生 20 人,则这个个体集的百分比矢量 f 的两个分量(顺序是女,男)是( 0.6 , 0.4 )。任何一个个体集的百分比矢量的各个分量代数和等于 1 。 5.4 百分比的代数平均值和几何平均值 (冯向军博士 2004 年评论《组成论》的一篇短文指出了百分比或者概率的平方和的物理意义。这里是在该认识上的综合和发挥,在此特做说明,在笔者看来这是冯向军博士的一个重要贡献。) 假设个体集内的每个个体用一个卡片代表它,而在卡片上根据它原来的标志值 x i ,写上该标志值对应的百分比的值 f i 。那么也可以认为 百分比本身就是标志值 了。即这个个体的标志值 x i 就改用 x i 占的百分比 f i 来代替了。 由于百分比这个新的标志值是数值,我们自然可以求这个个体集内各个个体的百分比的平均值。而根据平均值的定义, m = n i x i /N ,注意到现在 f i 代替 x i (相当于对自变量的函数求平均值),而 f i = n i /N ,自然有百分比的平均值公式: m f = n i 2 / N 2 = f i 2 i =1, ,p 于是我们知道一个个体集内的不同的标志值占的百分比的平方和,就是各个个体的新标志(百分比)的平均值。按照统计学的语言,这种平均值应当称为代数平均值或者算术平均值。 对于直角坐标系下的平面上的一个矢量,我们知道其分量的平方和是个有意义的量(开平方以后是该矢量的长度)。在 p 维空间中的一个矢量,其各个分量的平方和也是有意义的。对于个体集来说,它的百分比矢量的平方和等于百分比的平均值。 另外,对百分比,还可以求其几何平均值。根据几何平均值的定义,个体集内的百分比的几何平均值 m' f 应当是 m' f N = f i ni i =1, ,p 以上两个平均值都是个体集的重要特征量,它们与熵有特殊关系,这些后面再讨论。 5.5 个体集的复杂程度 C :其定义是 C = N log N - n i log n i i =1, ,p 这个公式给复杂程度以定量的定义,它还把应用于热力学的熵和应用于通讯领域的信息熵扩展到更广的领域。我们在下一讲再展开讨论。
 标签: 集合
标签: 集合