Nick T. Thomopoulos Essentials of Monte Carlo Simulation Statistical Methods for Building Simulation Models Preface I was fortunate to have a diverse career in industry and academia. This included working at International Harvester as supervisor of operations research in the corporate headquarters; at IIT Research Institute (IITRI) as a senior scientist with applications that spanned worldwide in industry and government; as a professor in the Industrial Engineering Department at the Illinois Institute of Technology (IIT), in the Stuart School of Business at IIT; at FIC Inc. as a consultant for a software house that specializes in supply chain applications; and the many years of consulting assignments with industry and government throughout the world. At IIT, I was fortunate to be assigned a broad array of courses, gaining a wide breadth with the variety of topics, and with the added knowledge I acquired from the students, and with every repeat of the course. I also was privileged to serve as the advisor to many bright Ph.D. students as they carried on their dissertation research. Bits of knowledge from the various courses and research helped me in the classroom, and also in my consulting assignments. I used my industry knowledge in classroom lectures so the students could see how some of the textbook methodologies actually are applied in industry. At the same time, the knowledge from the classroom helped to formulate and develop Monte Carlo solutions to industry applications as they unfolded. This variety of experience allowed the author to view how simulation can be used in industry. This book is based on this total experience. Simulation has been a valuable tool in my professional life, and some of the applications are listed below. The simulations models were from real applications and were coded in various languages of FORTRAN, C++, Basic, and Visual Basic. Some models were coded in an hour, others in several hours, and some in many days, depending on the complexity of the system under study. The knowledge gained from the output of the simulation models proved to be invaluable to the research team and to the project that was in study. The simulation results allowed the team to confidently make the decisions needed for the applications at hand. For convenience, the models below are listed by type of application. essentials of Monte carlo simulation.rar
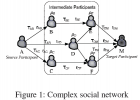
Contents 1 Trust-Oriented Composite Service Selection with QoS Constraints Trust-Oriented Composite Service Selection and Discovery Finding K Optimal Social Trust Paths for the Selection of Trustworthy Service Providers in Complex Social Networks A Subjective Probability Based Deductive Approach to Global Trust Evaluation in Composite Services The Prediction of Trust Rating Based on the Quality of Services Using Fuzzy Linear Regression A Heuristic Algorithm for Trust-Oriented Service Provider Selection in Complex Social Networks Context Based Trust Normalization in Service-Oriented Environments Trust Transitivity in Complex Social Networks Subjective Trust Inference in Composite Services The study of trust vector based trust rating aggregation in service-oriented environments 2 1 Yan Wang http://web.science.mq.edu.au/~yanwang/ Trust-Oriented Composite Service Selection with QoS Constraints Lei Li, Yan Wang,Ee-Peng Lim Journal of Universal Computer Science , vol. 16, no. 13 (2010), 1720-1744 Abstract: In Service-Oriented Computing (SOC) environments, service clients interact with service providers for consuming services. From the viewpoint of service clients, the trust level of a service or a service provider is a critical factor to consider in service selection, particularly when a client is looking for a service from a large set of services or service providers. However, a invoked service may be composed of other services. The complex invocations in composite services greatly increase the complexity of trust-oriented service selection. In this paper, we propose novel approaches for composite service representation, trust evaluation and trust-oriented composite service selection (with QoS constraints). Our experimental results illustrate that compared with the existing approaches our proposed trust-oriented (QoS constrained) composite service selection algorithms are realistic and enjoy better efficiency. Key Words: composite service, composite service selection, composite service representation, trust evaluation, Monte Carlo method 1 Introduction Service-Oriented Computing (SOC) Quality of Service (QoS) the reputation-based trust service composition + trust Open problem: trust-oriented composite service selection 1. The proper definition of the graph representation of composite services including both probabilistic and parallel invocations is still lacking. 2. subjective probability 3. no proper mechanism exists for evaluating the global trust of a composite service with a complex structure over service components with different trust values. 4. Call for effective algorithmsfor trust-oriented composite service selection the work of this paper: --first present the service invocation graph for composite service representation. --propose a trust evaluation method for composite services based on Bayesian inference -- propose composite service selection algorithms based on Monte Carlo method. The organization of this paper: 1) Section 2 reviews existing studies in service composition, service selection and trust management. 2)Section 3 presents our proposed composite services oriented service invocation graph. 3) Section 4 presents a novel trust evaluation method for composite services. 4)Section 5 proposed Monte Carlo method based algorithms for trust-oriented composite service selection (with QoS constraints). 5) Section 6 presents experiments for further illustrating the properties of our models. 6) Finally Section 7 concludes our work. 2 Related Work QoS-aware Web service selection mechanisms: -- linear programming -- Multi-Constrained Optimal Path (MCOP) problem -- the drawbacks of existing approaches: none of these works addresses any aspect of trust 3 Service Invocation Model the aim of this section: present the definitions of our proposed service invocation graph for representing the complex structures of composite services 3.1 Composite Services and Invocation Relation Six atomic invocation relationsare depicted as follows and in Fig. 1. -• Sequential Invocation -• Parallel Invocation: -• Probabilistic Invocation: -• Circular Invocation: -• Synchronous Activation: -• Asynchronous Activation: 3.2 An Example: Travel Plan 3.3 Service Invocation Graph Definition 1. The service invocation graph (SIG) 4 Trust Evaluation in Composite Services the purpose of this section: trust evaluation models for composite services the outline of this section: -- Section 4.1 describes a trust estimation model to estimate the trust value of each service component from a series of ratings according to Bayesian inference -- Section 4.2 proposes a global trust computation model to compute the global trust value of a composite service based on the trust values of all service components 4.1 Trust Estimation Model subjective probability Bayesian inference 4.2 Global Trust Computation in Composite Services Our goal: to select the optimal one from multiple SEFs (service execution flows) in an SIG aiming at maximizing the global trust value of SEF 5 Trust-Oriented Composite Service Selection the aim: the trust-oriented (QoS constrained) service selection algorithm is applied to find the most trustworthy SEF (satisfying QoS constraints). 5.1 Monte Carlo Method Based Algorithm (MCBA) in Trust-Oriented Composite Service Selection without QoS Constraints divide and conquer author's idea: propose a Monte Carlo method based algorithm (MCBA) to find the optimal SEF. Monte Carlo method: 5.2 QoS Constrained Monte Carlo Method Based Algorithm (QC MCBA) in Trust-Oriented Composite Service Selection with QoS Constraints 6 Experiments 6.1 Experiment on Trust-Oriented Composite Service Selection 6.1.1 Comparison Using Travel Plan Composite Services Matlab 6.1.2 Comparison Using Complex Composite Services 6.2 Experiment on Trust-Oriented Composite Service Selection with QoS Constraints 7 Conclusions 文献类型: 方法揉合 研究目标: 研究方法:方法揉合 比基尼: 难点 重点 疑点 个人点评: 文章写得很一般, 文章不足之处: 作者其它文献脉络 相关重要文献 beamer_Trust-Oriented_Composite_Service_Selection_QoS_Constraints.pdf Trust-Oriented Composite Service Selection with QoS Constraints.pdf 另外三位作者有一篇大致相同文章,我只看了一大概: Trust-Oriented Composite Service Selection and Discovery.pdf 予以对比: Trust-Oriented Composite Service Selection and Discovery Lei Li, YanWang, and Ee-Peng Lim ICSOC-ServiceWave '09 Proceedings of the 7th International Joint Conference on Service-Oriented Computing, Springer-Verlag Berlin Abstract. In Service-Oriented Computing (SOC) environments, service clients interact with service providers for consuming services. From the viewpoint of service clients, the trust level of a service or a service provider is a critical issue to consider in service selection and discovery, particularly when a client is looking for a service from a large set of services or service providers. However, a service may invoke other services offered by different providers forming composite services. The complex invocations in composite services greatly increase the complexity of trust-oriented service selection and discovery. In this paper, we propose novel approaches for composite service representation, trust evaluation and trust-oriented service selection and discovery. Our experiments illustrate that compared with the existing approaches our proposed trust-oriented service selection and discovery algorithm is realistic and more efficient. 1 Introduction Service-Oriented Computing (SOC) Trust: the measure by one party on the willingness and ability of another party to act in the interest of the former party in a situation the reputation-based trust Trust: the subjective probability, that is, trust is a subjective belief Web services Composition trustworthy service selection and discovery:a very challenging some open research problems : 1. The definition of a proper graph representation of composite services including both probabilistic invocations and parallel invocations is still lacking. ( 我认为此点并不成立!) 2. subjective probability theory 3. no proper mechanism exists for evaluating the global trust of a composite service with a complex structure from the trust values of all service components 4. effective algorithms 作者工作步骤: 1)first present the service invocation graph and service invocation matrix for composite service representation 2)propose a trust evaluation method for composite services based on Bayesian inference 3)propose a service selection and discovery algorithm based on Monte Carlo method 2 Related Work QoS (quality of service) and trust previous works: 1-) Zeng: service selection linear programming 2-) Yu: QoS constraints in composite services =two optimal heuristic algorithms -- the combinatorial algorithm --the graphbased algorithm. subjective ratings: 1) Jsang 2) Wang and Singh 3) Malik 3 Service Invocation Model the outline of this section: -- present the definitions of our proposed service invocation graph -- service invocationmatrix for representing the complex structures of composite services 3.1 Composite Services and Invocation Relation Six atomic invocations: 1) Sequential Invocation 2) Parallel Invocation 3) Probabilistic Invocation 4) Circular Invocation 5) Synchronous Activation 6) Asynchronous Activation complex invocations • Probabilistic inlaid parallel invocation, denoted as Pa(S : Pr(S : A|p, B|1−p), C). • Parallel inlaid probabilistic invocation, denoted as Pr(S : Pa(S : A, B)|p, C|1 −p). • Asynchronous inlaid synchronous activation, denoted as Sy(A, As(B, C : S) : S). • Synchronous inlaid asynchronous activation, denoted as As(A, Sy(B, C : S) : S). 3.2 An Example: Travel Plan 3.3 Service Invocation Graph Definition: The service invocation graph (SIG) A service execution flow (SEF) 3.4 Service Invocation Matrix Definition: a service invocation matrix 4 Trust Evaluation in Composite Services 4.1 Trust Estimation Model 1) subjective probability theory is the right tool for dealing with trust ratings 2) Bayesian inferenceestimate the trust value 4.2 Global Trust Computation in Composite Services Goal: select the optimal one from multiple SEFs (service execution flows) in an SIG aiming at maximizing the global trust value of SEF 5 Composite Service Selection and Discovery 假设: assume that a service trust management authority stores a large volume of services with their ratings (此假设并不成立!) 5.1 Longest SEF Algorithm Dijkstra’s shortest path algorithm 5.2 Monte Carlo Method Based Algorithm (MCBA) a Monte Carlo method based algorithm (MCBA) to find the optimal SEF Monte Carlo method consists of four steps: (1) defining a domain of inputs, (2) generating inputs randomly (3) performing a computation on each input, (4) aggregating the results into the final one 6 Experiments 6.1 Comparison on Travel Plan Composite Services 6.2 Comparison on Complex Composite Services 7 Conclusions author summary: -- first propose our service invocation graph and service invocation matrix for composite service representation -- a novel trust evaluation approach based on Bayesian inference has been proposed that can aggregate the ratings from other clients and the requesting client’s prior subjective belief about the trust -- a Monte Carlo method based trust-oriented service selection and discovery algorithm has been proposed future work: -- optimize the Monte Carlo method based algorithm -- study some heuristic approaches for trust-oriented optimal service selection and discovery Conclusions 1)first propose our service invocation graph and service invocation matrix for composite service representation 2)proposed a novel trust evaluation approach based on Bayesian inference that can aggregate the ratings from other clients and the requesting client’s prior subjective belief about the trust 3)Monte Carlo method based trust-oriented service selection and discovery algorithm 个人点评: Monte Carlo method 应用尚未看懂!实验部分一般 Trust-Oriented Composite Service Selection and Discovery.pdf Finding K Optimal Social Trust Paths for the Selection of Trustworthy Service Providers in Complex Social Networks Guanfeng Liu,Yan Wang,Mehmet A. Orgun 2011 IEEE International Conference on Web Services Abstract— In a service-oriented online social network consisting of service providers and consumers as participants, a service consumer can search trustworthy service providers via the social network between them. This requires the evaluation of the trustworthiness of a service provider along a potentially very large number of social trust paths from the service consumer to the service provider. Thus, a challenging problem is how to identify K optimal social trust paths that can yield the K most trustworthy evaluation results based on service consumers’ evaluation criteria. In this paper, we first present a complex social network structure and a concept, Quality of Trust (QoT). We then model the K optimal social trust paths selection with multiple end-to-end QoT constraints as the Multiple Constrained K Optimal Paths (MCOP-K) selection problem, which is NP-Complete. For solving this challenging problem, based on Dijkstra’s shortest path algorithm and our optimization strategies, we propose a heuristic algorithm H-OSTP-K with the time complexity of O(m+Knlogn). The results of our experiments conducted on a real dataset of online social networks illustrate that H-OSTP-K outperforms existing methods in the quality of identified social trust paths. Keywords: trust, social networks, K paths selection, service provider selection I. INTRODUCTION social networks trust and social network trust path trust propagation A challenging problem: how to select those paths yielding the most trustworthy results of trust propagation based on the source participant’s trust evaluation criteria. An optimal social trust path selection model: classical MCOP selection problem, author's idea: 1) first present the structure of complex social networks 2) then introduce a concept, Quality of Trust (QoT), 3) propsed a new efficient Heuristic algorithm for the K Optimal Social Trust Path selection, called H-OSTP-K 4) conducted extensive experiments on a real online social network dataset, the Enron email dataset II. RELATED WORK A. Social Network Analysis B. Trust in Online Social Networks social relationships and recommendation roles C. Social Trust Path Selection SmallBlue: an online social network constructed for IBM staff the drawback of all existing methods: III. COMPLEX SOCIAL NETWORKS three impact factors: trust, social intimacy degree and role impact factor IV. QUALITY OF TRUST AND QOT ATTRIBUTES AGGREGATION the outline of this section: 1) first present a general concept called Quality of Trust (QoT) 2) then propose a novel K optimal social trust paths selection model with end-to-end Quality of Trust (QoT) constraints. A. Quality of Trust (QoT) Definition 1: Quality of Trust (QoT) B. QoT Attribute Aggregation 1) Trust Aggregation: 2) Social Intimacy Degree Aggregation: 3) Role Impact Factor Aggregation: C. Utility Function V. K OPTIMAL SOCIAL TRUST PATHS SELECTION the outline of this section 1) first analyze some existing algorithms for K shortest paths selection 2)then propose an efficient heuristic algorithm H-OSTP-K for the NP-Complete MCOP-K selection in complex social networks. A. Existing Algorithms The algorithms for finding K general shortest paths can be classified into two categories: (1) K general paths selection based on Dijkstra’s shortest algorithm (2) K general paths selection based on A∗ algorithm. the shortcoming of aboved methods: they are all deterministic and thus can not be used to solve the NP-Complete MCOPK selection problem B. Our Proposed H-OSTP-K author's strategy: 1) first adopt the Backward K-Search procedure 2) then adopt the Forward K-Search procedure an objective function Backward K-Search: Forward K-Search: two optimization strategies to improve the efficiency of the Forward K-Search procedure. Optimization Strategy 1: Optimization Strategy 2: VI. EXPERIMENTS A. Experiment Settings The Enron email dataset B. Experiment Results VII. CONCLUSIONS 个人点评: 没有看懂,关键是其算法。感觉作者从 social network 角度去剖析? Finding K Optimal Social Trust Paths for the Selection of Trustworthy Service Pr.pdf A Subjective Probability Based Deductive Approach to Global Trust Evaluation in Composite Services Lei Li, Yan Wang 2011 IEEE International Conference on Web Services Abstract— In Service-Oriented Computing (SOC) environments, the trustworthiness of each service provider is critical for a service client when selecting one from a large pool of service providers. The trust value of a service provider is usually in the range of and is evaluated from the ratings given by service clients, which represent the subjective belief of service clients on the satisfaction of delivered services. So a trust value can be taken as a subjective probability, by which one party believes that another party can perform an action in a certain situation. Hence, subjective probability theory should be adopted in trust evaluation. In addition, in SOC environments, a service provider usually can invoke the services from other service providers forming a composite service. Thus, the global trust of a composite service should be evaluated based on both the subjective probability property of trust and complex invocation structures. In this paper, we first interpret the trust dependency caused by direct service invocations as conditional probability. Then, on the basis of trust dependency, we propose a SubjectivE probabiLity basEd deduCTIVE (SELECTIVE) approach to evaluate the subjective global trustworthiness of a composite service. All these processes follow subjective probability theory and keep the subjective probability property of trust in evaluations. Our experimental results demonstrate that when compared with existing approaches our proposed SELECTIVE approach can yield more reasonable results. I. INTRODUCTION service composite services trust subjective belief the callenges in SOC: to evaluate the global trust of a composite service the open problems: 1) how to adopte subjective probability theory in trust evaluation? 2) how to evaluate global trust of a composite trust? author's procedures: 1) First interpret the trust dependency caused by direct service invocations as conditional probability 2) Then propose a SubjectivE probabiLity basEd deduCTIVE (SELECTIVE) approach for subjective global trust evaluation in composite services the oraganization of this paper: 1) Section II reviews existing studies in trust evaluation, service compositionand service selection. 2) Section III briefly introduces composite services with six atomic invocations, and the probability interpretation of trust dependency. 3) Section IV presents a novel SubjectivE probabiLity basEd deduCTIVE (SELECTIVE) approach in composite services. 4) Section V presented experimentsfor further illustrating 5) Finally Section VI concludes our work. II. RELATED WORK subjective probability theory Bayesian inference QoS-aware service selection mechanisms trust-oriented service composition and selection the some drawbacks of author's previous work: trust evaluation VS reliability evaluation III. SERVICE INVOCATION AND TRUST DEPENDENCY A. Composite Service Structures Six atomic invocation relations in composite services: • Sequential Invocation: • Parallel Invocation: • Probabilistic Invocation: • Circular Invocation: • Synchronous Activation: • Asynchronous Activation: Example 1: a service invocation graph (SIG) a service execution flow (SEF) B. Rating Determination of Service Component Definition 1: C. Probability Interpretation of Trust Dependency Definition 2: trust dependency in composite services Example 2: IV. SUBJECTIVE PROBABILITY BASED DEDUCTIVE (SELECTIVE) APPROACH FOR GLOBAL TRUST EVALUATION OF COMPOSITE SERVICES Example 3: V. EXPERIMENTS the following questions: Q1: why service invocation structures should be taken into account in trust evaluation? Q2: why trust dependency caused by direct invocations should be taken into account in global trust evaluation? Q3: why the dependency caused by indirect invocations should be taken into account in trust evaluation? A. Experiment 1 on Service Invocation Structure B. Experiment 2 on Trust Dependency C. Experiment 3 on Trust-Oriented Composite Service Selection VI. CONCLUSIONS 个人点评: Yan Wang group(Macquarie University: http://web.science.mq.edu.au/~yanwang/ )研究 Trust-oriented Web selection有自己特色,值得学习,但是 machine learning部分力度不够,我可在此改进。 另外,精读文章的参考文献值得一篇一篇研究和分析 A Subjective Probability Based Deductive Approach to Global Trust Evaluation in .pdf The Prediction of Trust Rating Based on the Quality of Services Using Fuzzy Linear Regression M. Hadi Mashinchi, Lei Li, Mehmet A. Orgun, and Yan Wang 2011 IEEE International Conference on Fuzzy Systems ( CCF C level Conference ) Abstract— With the advent of service-oriented computing, the issue of trust and Quality of Service (QoS) have become increasingly important. In service-oriented environments, when there are a few service providers providing the same service, a service client would be keen to know the trustworthiness of each service provider in the forthcoming transaction. The trust rating of a delivered service from a service provider can be predicted according to a set of advertised QoS data collected by the trust management authority. Although trust and QoS are qualitative by nature, most data sets represent trust and QoS in the ordinal form for the sake of simplicity. This paper introduces a new approach based on Fuzzy Linear Regression Analysis (FLRA) to extract qualitative information from quantitative data and so use the obtained qualitative information for better modeling of the data. For verification purposes, the proposed approach can be applied for the trust prediction in the forthcoming transaction based on a set of advertised QoS in service-oriented environments. Index Terms— Fuzzy linear regression; Trust prediction; Quality of service; I. INTRODUCTION web service selecting criteria: functionality, QoS and reputation-based trust the neglect of current work: quantization both subjective and qualitative information in the trust data set The motivations of applying FLRA for predicting trust: • Capturing the hidden fuzziness: why not machine learning • Having a transparent model: • More detailed information: This organization of thispaper: 1) Section IIreview trust management, trust evaluation and uncertainty. 2) Section IV presents our QoS based trust prediction method with fuzzy regression. 3) Section V present some experiments for illustrating how our proposed method can predict trust with QoS values. 4) Finally Section VI concludes our work. II. RELATED WORK A. Trust Evaluation in E-Commerce Environments eBay, Sporas B. Trust Evaluation in P2P Information Sharing Networks XRep, EigenTrust, PeerTrust C. Trust Evaluation in Service-Oriented Environments machine learning and soft-computing D. Uncertainty several reasons causinguncertainty : • The high complexity of the environment, • The influence of human subjective judgement in thedecision process or the involvement of human-machine interactions • Partially available information the previous work which use FLRA (Fuzzy Linear Regression Analysis): III. FUZZY REGRESSION ANALYSIS A. Classical Regression Analysis B. Fuzzy Regression Model Parameters 1) Membership Function: 2) Goodness-of-fit: 3) Fuzziness: C. Fuzzy Linear Regression Analysis (FLRA) IV. TRUST PREDICTION BASED ON FUZZY REGRESSION the objective of this paper: the application of FLRA for the prediction of trust based on a set of advertised QoS values the problem of current The critical issue: the best option: not defuzzify the data but to take the uncertainty in the data into consideration in the level of inference spread increasing problem V. EXPERIMENTS the web-services data set The settings of experiments VI. CONCLUSIONS I comment: I don't comprehensive the author's meaning. The Prediction of Trust Rating Based on the Quality of Services Using Fuzzy Line.pdf A Heuristic Algorithm for Trust-Oriented Service Provider Selection in Complex Social Networks Guanfeng Liu, Yan Wang and Mehmet A. Orgun and Ee-Peng Lim 2010 IEEE International Conference on Services Computing Abstract— In a service-oriented online social network consisting of service providers and consumers, a service consumer can search trustworthy service providers via the social network. This requires the evaluation of the trustworthiness of a service provider along a certain social trust path from the service consumer to the service provider. However, there are usually many social trust paths between participants in social networks. Thus, a challenging problem is which social trust path is the optimal one that can yield the most trustworthy evaluation result. In this paper, we first present a novel complex social network structure and a new concept, Quality of Trust (QoT). We then model the optimal social trust path selection with multiple end-to-end QoT constraints as a Multi-Constrained Optimal Path (MCOP) selection problem which is NP-Complete. For solving this challenging problem, we propose an efficient heuristic algorithm, H OSTP. The results of our experiments conducted on a large real dataset of online social networks illustrate that our proposed algorithm significantly outperforms existing approaches. I. INTRODUCTION Online social networking FilmTrust trust propagation a social trust path A challenging problem:which one is the optimal yielding the most trustworthy result of trust propagation among multiple paths? the drawbacks of previous working: neglect -- social relationships between adjacent participants -- the recommendation roles of a participant research problem: to solve the optimal social trust path selection problem in complex social networks the main contributions of this paper are summarized as follows. (1)first present the structure of complex social networks taking trust information, social relationships and recommendation roles of participants into account. In addition, we also introduce a new concept, Quality of Trust (QoT), taking the above three factors as attributes. Furthermore, we model the optimal social trust path selection problem as a Multi-Constrained Optimal Path (MCOP) selection problem. (2) propose an efficient heuristic algorithm, H-OSTP for solving the optimal social trust path selection problem (3)conducted experiments on a real online social network dataset, Enron email corpus The organization of this paper: 1) Section II presents the novel social trust path selection model in complex online social networks. 2) Section III introduces our proposed heuristic algorithm, H-OSTP. 3) Section IV presents the experimental results and analysis. 4) Finally, section V concludes this paper. II. SOCIAL TRUST PATH SELECTION IN COMPLEX SOCIAL NETWORKS the outline of this section: -- first introduce the complex social network structure --then propose a novel social trust path selection model with end-to-end Quality of Trust (QoT) constraints. A. Complex Social Networks previous work: -- Golback -- Jamali the shortcoming of current works: neglect social relationships and recommendation roles A: proposed a complex social network structure that comprises of the attributes of three impact factors of trust, social intimacy degree and role impact factor, as shown in Fig. 2. 1) Trust: 2) Social Intimacy Degree: SID 3) Role Impact Factor: RIF B. Quality of Trust (QoT) Definition 1: Quality of Trust (QoT) C. QoT Attribute Aggregation procedure: -- first need to know the aggregated value of each QoT attribute in every social trust path between a source participant and the target participant. -- The aggregated values of all the QoT attributes are then combined in a utility function defined over social trust paths, -- and then the path with the best utility value is selected as the optimal social trust path. 1) Trust Aggregation: 2) Social Intimacy Degree Aggregation: 3) Role Impact Factor Aggregation: D. Utility Function The goal of optimal social trust path selection = to select the path that satisfies multiple end-to-end QoT constraints and yields the best utility with the weights specified by the source participant. III. SOCIAL TRUST PATH SELECTION ALGORITHM the outline of this section: -- The optimal social trust path selection with multiple end-toend QoT constraints can be modelled as the classical Multi-Constrained Optimal Path (MCOP) selection problem -- first analyze some of those algorithms --then propose an efficient Heuristic algorithm for Optimal Social Trust Path selection. A. Existing Algorithms H-MCOP algorithm MCSP-K algorithm: an approximation algorithm based on H MCOP B. H-OSTP H-OSTP: an efficient heuristic algorithmfor the optimal social trust path selection with end-to-end QoT constraints in complex social networks -- first adopt the Backward Search procedure from the target -- then adopt the Forward Search procedure to search the network if a feasible solution exists an objective function in Eq. (6) to investigate whether the aggregated QoT attributes of a path can satisfy the QoT constraints Backward Search: Forward Search: IV. EXPERIMENTS the small-world characteristic the Enron email dataset A. Experiment Settings B. Performance in Social Trust Path Selection V. CONCLUSIONS A Heuristic Algorithm for Trust-Oriented Service Provider Selection in Complex S.pdf Context Based Trust Normalization in Service-Oriented Environments Lei Li and Yan Wang ATC 2010, LNCS 6407, pp. 122–138, 2010. Abstract. With the development of information technology, the issue of trust becomes more and more important. In e-commerce or service-oriented environments, when there are a few sellers or service providers providing the same product/service, the buyer or service client would like to request the trust management authority to provide trust values of sellers or service providers, which are based on the ratings reflecting the quality of previous transactions. In addition, trust is context dependent, i.e. for different context of transactions, there are different factors influencing the trust result. In this paper, we propose a fuzzy comprehensive evaluation based method for building up a projection from the trust ratings in the transaction history of a service provider to an upcoming transaction depending on the similarity between previous transactions and the upcoming one, and the familiarity between each rater and the service client of the upcoming transaction. This process is termed as context based trust normalization. After trust normalization, normalized trust ratings are used for trust evaluation, the results of which would be closely bound to the upcoming transaction. Finally, we introduce the results of our conducted experiments to illustrate how our proposed method can detect some typical risks. 1 Introduction service-oriented computing (SOC), social network and cloud computing: Trust The concept of trust varies in different disciplines. subjective probability reputation-based trust Peer-to-Peer (P2P) the following types of risks for trust management: -- Type 1 risk. -- Type 2 risk. -- Type 3 risk. trust vs. context author's work: This paper is organized as follows: 1) Section 2, we review the concept of trust, trust evaluation and subjective probability. 2) Section 3 presents our context based trust normalization method and evaluates the trust value that would be closely bound to the upcoming transaction. 3) Some experiments are presented in Section 4 for illustrating that our proposed method can detect some typical risks. 4) Finally Section 5 concludes our work. 2 Related Work 2.1 Trust Evaluation in Computer-Mediated Environments 2.2 Trust Evaluation and Subjective Probability trust vs.subjective probability Subjective probability: one of the most popular interpretations of the concept of probability -- Bayesian inference -- the rule of probability kinematics:the typical non-Bayesian inference method 3 Trust Normalization Q: trust and context dependent A: context based trust normalization 3.1 Comprehensive Evaluation Index System Q: how to find the main factors which influence context based trust normalization the most A: The criteria for developing the comprehensive evaluation index system are as follows: author's comprehensive evaluation index system: -- Transaction cost relativity: -- Transaction category similarity: -- Social relationship influence: 3.2 Fuzzy Comprehensive Evaluation Model Fuzzy comprehensive evaluation model: a synthetical application of analytical hierarchy process and fuzzy mathematics by inspecting many influencing factors. Single-level and Multi-level Fuzzy Comprehensive Evaluations. Fuzzy comprehensive evaluation: single-level and multi-level. The steps of single-level fuzzy comprehensive evaluation are as follows. The steps of multi-level fuzzy comprehensive evaluation are as follows. Establishing Affiliation Score Set. Establishing Fuzzy Affiliation Matrix. Establishing Weight Vector Establishing Affiliation Vector. Discounting Rate. 4 Experiments Epinions: a popular online reputation system 4.1 An Example of Context Based Trust Normalization 4.2 Experiment on Type 1 Risk 5 Conclusions Context Based Trust Normalization in Service-Oriented Environments.pdf Trust Transitivity in Complex Social Networks Guanfeng Liu, YanWang and Mehmet A. Orgun Proceedings of the Twenty-Fifth AAAI Conference on Artificial Intelligence Abstract In Online Social Networks (OSNs), participants can conduct rich activities, where trust is one of the most important factors for their decision making. This necessitates the evaluation of the trustworthiness between two unknown participants along the social trust paths between them based on the trust transitivity properties (i.e., if A trusts B and B trusts C, then A can trust C to some extent). In order to compute more reasonable trust value between two unknown participants, a critical and challenging problem is to make clear how and to what extent trust is transitive along a social trust path. To address this problem, we first propose a new complex social network structure that takes, besides trust, social relationships, recommendation roles and preference similarity between participants into account. These factors have significant influence on trust transitivity. We then propose a general concept, called Quality of Trust Transitivity (QoTT), that takes any factor with impact on trust transitivity as an attribute to illustrate the ability of a trust path to guarantee a certain level of quality in trust transitivity. Finally, we propose a novel Multiple QoTT Constrained Trust Transitivity (MQCTT) model. The results of our experiments demonstrate that our proposed MQCTT model follows the properties of trust and the principles illustrated in social psychology, and thus can compute more resonable trust values than existing methods that consider neither the impact of social aspects nor the properties of trust. 1 Introduction social networks a trust path: the trust transitivity property a critical and challenging problem in OSNs: how trust is transitive along a social trust path? three factors: -- the social relationships -- the recommendation roles -- the preference similarity main contributions of this paper: (1)first propose a complex social network structure that takes trust, social relationships, recommendation roles and preference similarity into account (2) Based on the properties of trust illustrated in social psychology, we then propose a new Multiple QoTT Constrained Trust Transitivity (MQCTT) model. (3)conducted experiments on several subnetworks extracted from the Enron email dataset 2 RelatedWork three categories according to the types of trust transitivity strateg: 1-) multiplication strategy 2-) averaging strategy 3-) confidence-based strategy some drawbacks in the above three categories of trust transitivity models: 3 A Complex Social Network a new complex social network structure, as depicted in Fig. 1. It contains the attributes of four impact factors, i.e., trust, social intimacy degree, role impact factor and preference similarity. 3.1 Trust 3.2 Social Intimacy Degree The following principle in social psychology illustrates the impact of the social relationships between participants on trust. Principle 1. 3.3 Role Impact Factor 3.4 Preference Similarity 4 Trust Properties and the Quality of Trust Transitivity the outline of this section: -- 4.1 The properties of Trust 4.2 Quality of Trust Transitivity (QoTT) Definition 4. Quality of Trust Transitivity (QoTT) 4.3 QoTT Constraint 4.4 The Aggregation Method for QoTT Attributes 4.4.1 Trust Aggregation 4.4.2 Social Intimacy Degree Aggregation 5 Multiple QoTT Constrained Trust Transitivity (MQCTT) Model Step 1 (average trust decay speed): Step 2 (intersection angle θ): Step 3 (the scope of θ): Step 4 (logistic function): Step 5 (computing θ value): 6 Experiments 6.1 Experiment Settings I comment: Trust Transitivity in Complex Social Networks.pdf Subjective Trust Inference in Composite Services Lei Li and YanWang Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence (AAAI-10) Abstract In Service-Oriented Computing (SOC) environments, the trustworthiness of each service is critical for a service client when selecting one from a large pool of services. The trust value of a service is usually in the range of and is evaluated from the ratings given by service clients, which represent the subjective belief of these service clients on the satisfaction of delivered services. So a trust value can be taken as the subjective probability, with which one party believes that another party can perform an action in a certain situation. Hence, subjective probability theory should be adopted in trust evaluation. In addition, in SOC environments, service usually invokes other services offered by different ervice providers forming a composite service. hus, the global trust of a composite service should be valuated based on complex invocation structures. In this paper, firstly, based on Bayesian inference, we propose a novel method to evaluate the subjective trustworthiness of a service component from a series of ratings given by service clients. Secondly, we interpret the trust dependency caused by service invocations as conditional probability, which is evaluated based on the subjective trust values of service components. Furthermore, we propose a joint subjective probability method to evaluate the subjective global trust of a composite service on the basis of trust dependency. Finally, we introduce the results of our conducted experiments to illustrate the properties of our proposed subjective global trust inference method. 1 Introduction Service-Oriented Computing (SOC) a service: an autonomous, platform-independent computational entity, which can be described, published, discovered and dynamically assembled for developing massively distributed systems trust:the measure taken by one party on the willingness and ability of another party to act in the interest of the former party in a certain situation open problems: author's work: -- first propose a Bayesian inference based subjective trust estimation method for service components. --interpret the trust dependency caused by service invocations as conditional probability, which can be evaluated based on the trust values of service components. --propose a joint subjective probability method to evaluate the subjective global trust of a composite service on the basis of trust dependency. the organization of this paper: 1)Section 2 reviews existing studies in trust management, service selection and service composition. 2) Section 3 briefly introduces composite services with six atomic invocations. 3) Section 4 presents our novel joint subjective probability method in composite services. 4) Experiments are presented in Section 5 for further illustrating the properties of our proposed method. 5) Finally Section 6 concludes our work. 2 RelatedWork the drawbacks of previous work: -- omit parallel invocation the focus ofthis paper: a proper subjective global trust inference methodfor trust-oriented composite service selection and discovery 3 Service Invocation Model A composite service Six atomic invocationsin composite services are introduced below and depicted in Fig. 1 Example 1: a service invocation graph (SIG) in Fig.2. a service execution flow (SEF), which is the subgraph of SIG. 4 Subjective Trust Inference subjective probability theory the outline of this section: --Section 4.1 presents a novel method , based on Bayesian inference, evaluates the subjective trust of service components -- Section 4.2interprets the trust dependency caused by service invocations as conditional probability -- Section 4.3propose a joint subjective probability method that evaluates the subjective global trust value of an SEF from the trust values and trust dependency of all service components. 4.1 Trust Estimation of Service Components Rating Space and Trust Space Definition 1 The rating space Definition 2 The trust space Bayesian Inference Certainty, Expected Positiveness and Expected Negativeness Definition 3 The certainty Definition 4 The expected positiveness From Rating Space to Trust Space 4.2 Probability Interpretation of Trust Dependency 4.3 Joint Subjective Probability Method 5 Experiments and Analysis 5.1 Important Properties in Trust Estimation 5.2 Experiment on Subjective Trust Inference 6 Conclusions I comment: Subjective Trust Inference in Composite Services.pdf mynote: Subjective Trust Inference in Composite Services.pdf The study of trust vector based trust rating aggregation in service-oriented environments Lei Li · Yan Wang WorldWide Web journal (Springer), 2011 Abstract In most existing studies on trust evaluation, a single trust value is aggregated from the ratings given to previous services of a service provider, to indicate his/her current trust level. Such a mechanism is useful but may not be able to depict the trust features of a service provider well under certain circumstances. Alternatively, a complete set of trust ratings can be transferred to a service client for local trust evaluation. However, this incurs a big overhead in communication, since the rating dataset is usually in large scale covering a long service history. The third option is to generate a small set of data that should represent well the large set of trust ratings of a long time period. In the literature, a trust vector approach has been proposed, with which a trust vector of three values resulting from a computed regression line can represent a set of ratings distributed within a time interval (e.g., a week or a month, etc.). However, the computed trust vector can represent the set of ratings well only if these ratings imply consistent trust trend changes and are all very close to the obtained regression line. In a more general case with trust ratings for a long service history, multiple time intervals have to be determined, within each of which a trust vector can be obtained and can represent well all the corresponding ratings. Hence, a small set of data can represent well a large set of trust ratings with well preserved trust features. This is significant for large-scale trust rating transmission, trust evaluation and trust management. In this paper, we propose one greedy and two optimal multiple time interval (MTI) analysis algorithms. We also have studied the properties of our proposed algorithms analytically and empirically. These studies can illustrate that our algorithms can return a small set of MTI to represent a large set of trust ratings and preserve well the trust features. Keywords reputation-based trust · trust rating aggregation · trust vector · multiple time intervals 1 Introduction Service-Oriented Computing (SOC) a trust vector with three values: -- final trust level (FTL) -- service trust trend (STT) -- service performance consistency level (SPCL) multiple time interval (MTI) analysis the contributions of this paper can be briefly summarized as follows: 1-. The bisection-based boundary excluded greedy MTI algorithm consumes much less CPU time than any of the other four MTI algorithms. 2-. The boundary excluded optimal MTI algorithm can return the minimal set of boundary excluded MTI. 3-. The boundary mixed optimal MTI algorithm returns a minimal set of boundary mixed MTI. This set is no larger than the set returned by any of the other four MTI algorithms. 4-. With any of our proposed algorithms, a small set of data can represent well a large set of trust ratings with well preserved trust features. 2 Related work 2.1 Trust aggregation approaches in online environments 2.1.1 Trust evaluation in e-commerce environments eBay Sporas system Histos system fuzzy logic trust model 2.1.2 Trust evaluation in P2P information sharing networks XRep EigenTrust PeerTrust two main features of PeerTrust -- voting reputation system PowerTrust 2.1.3 Trust evaluation in service-oriented environments 2.1.4 Trust evaluation in multi-agent systems TRAVOS system 2.2 Existing trust vector approaches 3 Trust vector evaluation the outline of this section: 3.1 Final trust level (FTL) evaluation 3.2 Service trust trend (STT) evaluation 3.3 Service performance consistency level (SPCL) evaluation 4 Multiple time interval (MTI) analysis 4.1 Boundaries of MTI 4.2 Bisection-based boundary excluded greedy MTI algorithm 4.4 Boundary mixed optimal MTI algorithm 5 Experiments 6 Conclusions I comment: I don't find the originality of this paper The study of trust vector based trust rating aggregation in service-oriented env.pdf
蒙特卡罗(Monte Carlo)方法,也称为计算机随机模拟方法,是一种基于随机数的计算方法。 一 起源 这一方法源于美国在第二次世界大战进研制原子弹的曼哈顿计划。Monte Carlo方法创始人主要是这四位:Stanislaw Marcin Ulam, Enrico Fermi, John von Neumann(学计算机的肯定都认识这个牛人吧)和 Nicholas Metropolis。 Stanislaw Marcin Ulam是波兰裔美籍数学家,早年是研究拓扑的,后因参与曼哈顿工程,兴趣遂转向应用数学,他首先提出用Monte Carlo方法解决计算数学中的一些问题,然后又将其应用到解决链式反应的理论中去,可以说是MC方法的奠基人;Enrico Fermi是个物理大牛,理论和实验同时都是大牛,这在物理界很少见,在物理大牛的八卦那篇文章里提到这个人很多次,对于这么牛的人只能是英年早逝了(别说我嘴损啊,上帝都嫉妒!);John von Neumann可以说是计算机界的牛顿吧,太牛了,结果和Fermi一样,被上帝嫉妒了;Nicholas Metropolis,希腊裔美籍数学家,物理学家,计算机科学家,这个人对Monte Carlo方法做的贡献相当大,正式由于他提出的一种什么算法(名字忘了),才使得Monte Carlo方法能够得到如此广泛的应用,这人现在还活着,与前几位牛人不同,Metropolis很专一,他一生主要的贡献就是Monte Carlo方法。 蒙特卡罗方法的名字来源于摩纳哥的一个城市蒙地卡罗,该城市以赌博业闻名,而蒙特罗方法正是以概率为基础的方法。与它对应的是确定性算法。 二 解决问题的基本思路 Monte Carlo方法的基本思想很早以前就被人们所发现和利用。早在17世纪,人们就知道用事件发生的频率来决定事件的概率。19世纪人们用投针试验的方法来决定圆周率。本世纪40年代电子计算机的出现,特别是近年来高速电子计算机的出现,使得用数学方法在计算机上大量、快速地模拟这样的试验成为可能。 为了说明Monte Carlo方法的基本思想,让我们先来看一个简单的例子,从此例中你可以感受如何用Monte Carlo方法考虑问题。 例1:比如y=x^2(对x)从0积到1。结果就是下图红色部分的面积: 注意到函数在(1,1)点的取值为1,所以整个红色区域在一个面积为1的正方形里面。所以所求区域的面积即为 在正方形区域内任取点,点落在所求区域的概率。这个限制条件是yx^2。用matlab模拟,做一百万次(即共取1000000个点),结果为0.3328。 1) 总结Monte Carlo方法的基本思想:所求解问题是某随机事件A出现的概率(或者是某随机变量B的期望值)。通过某种实验的方法,得出A事件出现的频率,以此估计出A事件出现的概率(或者得到随机变量B的某些数字特征,得出B的期望值)。 2) 工作过程 在解决实际问题的时候应用蒙特卡罗方法主要有两部分工作: 用蒙特卡罗方法模拟某一过程时,需要产生各种概率分布的随机变量。 用统计方法把模型的数字特征估计出来,从而得到实际问题的数值解。 3) 蒙特卡罗解题三个主要步骤: (1) 构造或描述概率过程: 对于本身就具有随机性质的问题,如粒子输运问题,主要是正确描述和模拟这个概率过程,对于本来不是随机性质的确定性问题,比如计算定积分,就必须事先构造一个人为的概率过程,它的某些参量正好是所要求问题的解。即要将不具有随机性质的问题转化为随机性质的问题。 (2) 实现从已知概率分布抽样: 构造了概率模型以后,由于各种概率模型都可以看作是由各种各样的概率分布构成的,因此产生已知概率分布的随机变量(或随机向量),就成为实现蒙特卡罗方法模拟实验的基本手段,这也是蒙特卡罗方法被称为随机抽样的原因。最简单、最基本、最重要的一个概率分布是(0,1)上的均匀分布(或称矩形分布)。随机数就是具有这种均匀分布的随机变量。随机数序列就是具有这种分布的总体的一个简单子样,也就是一个具有这种分布的相互独立的随机变数序列。产生随机数的问题,就是从这个分布的抽样问题。在计算机上,可以用物理方法产生随机数,但价格昂贵,不能重复,使用不便。另一种方法是用数学递推公式产生。这样产生的序列,与真正的随机数序列不同,所以称为伪随机数,或伪随机数序列。不过,经过多种统计检验表明,它与真正的随机数,或随机数序列具有相近的性质,因此可把它作为真正的随机数来使用。由已知分布随机抽样有各种方法,与从(0,1)上均匀分布抽样不同,这些方法都是借助于随机序列来实现的,也就是说,都是以产生随机数为前提的。由此可见,随机数是我们实现蒙特卡罗模拟的基本工具。 建立各种估计量: 一般说来,构造了概率模型并能从中抽样后,即实现模拟实验后,我们就要确定一个随机变量,作为所要求的问题的解,我们称它为无偏估计。 (3) 建立各种估计量,相当于对模拟实验的结果进行考察和登记,从中得到问题的解。 例如:检验产品的正品率问题,我们可以用1表示正品,0表示次品,于是对每个产品检验可以定义如下的随机变数Ti,作为正品率的估计量: 于是,在N次实验后,正品个数为: 显然,正品率p为: 不难看出,Ti为无偏估计。当然,还可以引入其它类型的估计,如最大似然估计,渐进有偏估计等。但是,在蒙特卡罗计算中,使用最多的是无偏估计。 用比较抽象的概率语言描述蒙特卡罗方法解题的手续如下:构造一个概率空间(W ,A,P),其中,W 是一个事件集合,A是集合W 的子集的s 体,P是在A上建立的某个概率测度;在这个概率空间中,选取一个随机变量q (w ),w Icirc; W ,使得这个随机变量的期望值 正好是所要求的解Q ,然后用q (w )的简单子样的算术平均值作为Q 的近似值。 三 本方法特点 直接追踪粒子,物理思路清晰,易于理解。 采用随机抽样的方法,较真切的模拟粒子输运的过程,反映了统计涨落的规律。 不受系统多维、多因素等复杂性的限制,是解决复杂系统粒子输运问题的好方法。 MC程序结构清晰简单。 研究人员采用MC方法编写程序来解决粒子输运问题,比较容易得到自己想得到的任意中间结果,应用灵活性强。 MC方法主要弱点是收敛速度较慢和误差的概率性质,其概率误差正比于,如果单纯以增大抽样粒子个数N来减小误差,就要增加很大的计算量。 另一类形式与Monte Carlo方法相似,但理论基础不同的方法-拟蒙特卡罗方法(Quasi-Monte Carlo方法)-近年来也获得迅速发展。我国数学家华罗庚、王元提出的华-王方法即是其中的一例。这种方法的基本思想是用确定性的超均匀分布序列(数学上称为Low Discrepancy Sequences)代替Monte Carlo方法中的随机数序列。对某些问题该方法的实际速度一般可比Monte Carlo方法提出高数百倍,并可计算精确度。 蒙特卡罗方法在金融工程学,宏观经济学,计算物理学(如粒子输运计算、量子热力学计算、空气动力学计算)等领域应用广泛。 四 Monte Carlo方法的计算程序 关于蒙特卡罗方法的计算程序已经有很多,如:EGS4、FLUKA、ETRAN、ITS、MCNP、GEANT等。这些程序大多经过了多年的发展,花费了几百人年的工作量。除欧洲核子研究中心(CERN)发行的GEANT主要用于高能物理探测器响应和粒子径迹的模拟外,其它程序都深入到低能领域,并被广泛应用。就电子和光子输运的模拟而言,这些程序可被分为两个系列: 1.EGS4、FLUKA、GRANT 2.ETRAN、ITS、MCNP 这两个系列的区别在于:对于电子输运过程的模拟根据不同的理论采用了不同的算法。 EGS4和ETRAN分别为两个系列的基础,其它程序都采用了它们的核心算法。 ETRAN(for Electron Transport)由美国国家标准局辐射研究中心开发,主要模拟光子和电子,能量范围可从1KeV到1GeV。 ITS(The integrated TIGER Series of Coupled Electron/Photon Monte Carlo Transport Codes )是由美国圣地亚哥(Sandia)国家实验室在ETRAN的基础上开发的一系列模拟计算程序,包括TIGER 、CYLTRAN 、ACCEPT等,它们的主要差别在于几何模型的不同。 TIGER研究的是一维多层的问题,CYLTRAN研究的是粒子在圆柱形介质中的输运问题,ACCEPT是解决粒子在三维空间输运的通用程序。 NCNP(Monte Carlo Neutron and Photo Transport Code)由美国橡树林国家实验室(Oak Ridge National Laboratory)开发的一套模拟中子、光子和电子在物质中输运过程的通用MC 计算程序,在它早期的版本中并不包含对电子输运过程的模拟,只模拟中子和光子,较新的版本(如MCNP4A)则引进了ETRAN,加入了对电子的模拟。 FLUKA 是一个可以模拟包括中子、电子、光子和质子等30余种粒子的大型MC计算程序,它把EGS4容纳进来以完成对光子和电子输运过程的模拟,并且对低能电子的输运算法进行了改进。 五 Monte Carlo方法相关的一些资料 一个网站: http://csep1.phy.ornl.gov/mc/mc.html 《蒙特卡罗方法》 徐钟济著 上海科学技术出版社 《科学计算中的蒙特卡罗策略》(当代科学前沿论丛)(Monte Carlo Strategies in Scientific Computing) 作者:刘军 译者:唐年胜 周勇 徐亮 统计物理学中的蒙特卡罗模拟方法 ( 德) 宾德(Binder,K.),赫尔曼(Heermann,D.W.) 著 北京大学出版社 1994.2 小尺寸半导体器件的蒙特卡罗模拟 叶良修编著 科学出版社 1997.2 蒙特卡罗方法及其在粒子输运问题中的应用 裴鹿成, 张孝泽著 科学出版社 1980.10 统计试验法:( 蒙特卡罗法) 及其在电子数字计算机上的实现 (苏) 布斯连科( Н. П. Бусленко), (苏) 施 上海科学技术出版社 若干本书:人大经济论坛 http://www.pinggu.org/bbs/thread-445802-1-1.html 高分子科学中的Monte Carlo方法 杨玉良 复旦大学出版社 1993.12 7-309-01361-1 Monte Carlo simulation of semiconductor devices C. Moglestue. Chapman Hall, 1993. 041247770X Monte Carlo methods in statistical physics with contributions by K. Binder ... ; edi Springer-Verlag, 1979. guide to Monte Carlo simulations in statistical physics David P. Landau, Kurt Binder. Cambridge University Press, c2000. Monte Carlo methods in statistical physics edited by K. Binder ; with contributions by K. Bin Springer-Verlag, c1986. Applications of the Monte Carlo method in statistical physics edited by K. Binder. Springer, 1984. Monte Carlo Device Simulation Karl Hess Kluwer Acadmic 参考资料 :1、 http://baike.baidu.com/view/1675475.htm?fr=ala0_1 2、 http://baike.baidu.com/view/42460.htm?fr=ala0_1_1 3、 http://gorilla.blogbus.com/logs/4669.html 4、 http://blog.sina.com.cn/s/blog_5e8154170100cgc4.html 5、 http://www.charlesgao.com/?p=121
 标签: Monte
标签: Monte