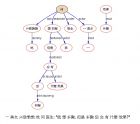
【置顶:立委科学网博客NLP博文一览(定期更新版)】 2008-09-20 我们教机器理解语言(Natural Language Understanding),基本的一条就是通过句法分析 (parsing) 解析出句子的意义。什么是一个句子的意义呢?举个例子: John loves Mary. 上述句子有三个构句成分:约翰,玛丽,爱。认识这些词不难,一部词典就成,但这不等于能听懂这个句子,因为句子的意义不是其成分词汇意义的简单相加。同样的词汇,不同的组合,构成不同的句子,就有不同的意义,说明了句子结构分析对于语言理解具有决定性的作用。比较下列各组句子: 1a. John loves Mary. 1b. Mary is loved by John. 1c. John’s love for Mary (is amazing) 1d. Mary’s love by John (is amazing). 2a. Mary loves John. 2b. John is loved by Mary. 2c. Mary’s love for John (is amazing) 2d. John’s love by Mary (is amazing) 3a. John’s Mary is loved. 3b. the love for John’s Mary (is amazing) 4a. Mary’s John is loved. 4b. the love for Mary’s John (is amazing). 以上各组句子里面,虚词和词缀(如is,-ed,’s,the)有所不同,词序排列不同,而基本实词成分是相同的。句式各不相同,有主动态句型,有被动态句型,有用动词love,也有名词love,但是每组的句子中心意义是相同的。句法分析(parsing)的最终目的就是把语言中意义相同但说法不同的句式解码成相同的表达形式(称为逻辑形式 logical form),达成理解。以上述4组句子为例,怎么才叫理解了这些句子呢?如果解析出下列逻辑关系,就可以认为理解了。 1组:约翰是“爱”的的施予者,玛丽是“爱”的对象。 2组:玛丽是“爱”的的施予者,约翰是“爱”的对象。 3组:(约翰的)玛丽是(某人)“爱”的对象。 4组:(玛丽的)约翰是(某人)“爱”的对象。 我们自然语言工作者编制机器语法,为的就是教会机器自动分析(parse)句子,把语言不同句式的种种说法(所谓表层结构 surface structures)解码成如上例所示的能表达结构意义的逻辑关系(所谓深层结构 deep structure)。其重点就是解析动作行为(love)及其施(如约翰)受(如玛丽)关系,即,逻辑主谓宾(logical subject-verb-object SVO)的解构。上述4组句子解构后的形式表达如下: 1组:LOVE: Subj=JOHN; Obj=MARY. 2组:LOVE: Subj=MARY; Obj=JOHN. 3组:LOVE: Obj= 4组:LOVE: Obj= 除了主谓宾的主干以外,句子的意义当然还包括枝节意义,譬如实体的修饰语(e.g. the “beautiful” Mary),行为动作的时间地点条件方式等状语 (e.g. John loves Mary “dearly”),但是,逻辑主谓宾总是句子意义的核心。严格地说,句子的主干应该是“主谓宾补” (S-V-O-C) 四项,因为有些行为动作还需要第二个宾语或者宾语补足语意义才完整。 教会电脑自动理解句子意义有什么用处呢?用处大得很,用处之一是使搜索智能化,直接得到你想要的答案,而不像牵狗一样搜索的结果是成千上万个网页。比如,你有一个疑问:微软收购了哪些公司?你只要告诉带有语言智能的搜索器,Subj=Microsoft, Verb=acquire/buy, Obj=? 逻辑主谓宾武装起来的智能搜索就可以轻易搜得所有媒体报道过的微软兼并过的公司,给你列出一长列来。这是传统搜索引擎 Google, Yahoo, 和 MSN 无法做到的。 下面是笔者开发的英语自动分析机的一个运行实例。输入是英语句子,输出是逻辑主谓宾补。笔者用汉语简单加了一些注解。 这是输入: A U.N. cease-fire resolution has authorized up to 15,000 U.N. peacekeepers to help an equal number of Lebanese troops extend their authority into south Lebanon as Israel withdraws its soldiers. 这是 S-V-O-C 输出: name=”SubjPred” has authorized 动词 A U.N. cease-fire resolution 主语 name=”PredObj” has authorized 动词 up to 15,000 U.N. peacekeepers 宾语 name=”PredInf” has authorized 动词 to help 补语 name=”LSubjPred” to help 动词 up to 15,000 U.N. peacekeepers 主语 name=”PredObj” to help 动词 an equal number of Lebanese troops 宾语 name=”PredComp” to help 动词 extend 补语 name=”LSubjPred” extend 动词 an equal number of Lebanese troops 主语 name=”PredObj” extend 动词 their authority 宾语 name=”PredPrep” extend 动词 into south Lebanon 补语 name=”SubjPred” withdraws 动词 Israel 主语 name=”PredObj” withdraws 动词 its soldiers 宾语 笔者的目标就是制造一台世界上最善解人意的智能机器,大家说的鬼子话它大多听得懂。教机器学人话是既刺激好玩又具有实用价值的干活,笔者教了十几年了,乐此不疲。 Comments (2) yechq 12月 6th, 2008 at 11:18 am edit “笔者的目标就是制造一台世界上最善解人意的智能机器,大家说的鬼子话它大多听得懂。” 好大口气,目前成果如何? liwei 12月 6th, 2008 at 2:19 pm edit 原来是关门吹牛的帖子,出来见光时忘记删改了,不能当真的。 关门在老友中间吹牛基本上与夜行怕鬼吹口哨壮胆类似。呵呵。 谢谢,我去修改一下。
 标签: 自动分析
标签: 自动分析