After I showed the benchmarking results of SyntaxNet and our rule system based on grammar engineering, many people seem to be surprised by the fact that the rule system beats the newest deep-learning based parser in data quality . I then got asked many questions, one question is: Q: We know that rules crafted by linguists are good at precision, how about recall? This question is worth a more in-depth discussion and serious answer because it touches the core of the viability of the forgotten school: why is it still there? what does it have to offer? The key is the excellent data quality as advantage of a hand-crafted system, not only for precision, but high recall is achievable as well. Before we elaborate, here was my quick answer to the above question: Unlike precision, recall is not rules' forte, but there are ways to enhance recall; To enhance recall without precision compromise, one needs to develop more rules and organize rules in a hierarch y, and organize grammars in a pipeline , so r ecall is a function of time; To enhance recall with limited compromise in precision, one can fine-tune the rules to loosen conditions. Let me address these points by presenting the scene of action for this linguistic art in its engineering craftsmanship. A rule system is based on compiled computational grammars. A grammar is a set of linguistic rules encoded in some formalism. What happens in grammar engineering is not much different from other software engineering projects. As knowledge engineer, a computational linguist codes a rule in a NLP-specific language, based on a development corpus. The development is data-driven, each line of rule code goes through rigid unit tests and then regression tests before it is submitted as part of the updated system. Depending on the design of the architect, there are all types of information available for the linguist developer to use in crafting a rule's conditions, e.g. a rule can check any elements of a pattern by enforcing conditions on (i) word or stem itself (i.e. string literal, in cases of capturing, say, idiomatic expressions), and/or (ii) POS (part-of-speech, such as noun, adjective, verb, preposition), (iii) and/or orthography features (e.g. initial upper case, mixed case, token with digits and dots), and/or (iv) morphology features (e.g. tense, aspect, person, number, case, etc. decoded by a previous morphology module), (v) and/or syntactic features (e.g. verb subcategory features such as intransitive, transitive, ditransitive), (vi) and/or lexical semantic features (e.g. human, animal, furniture, food, school, time, location, color, emotion). There are almost infinite combinations of such conditions that can be enforced in rules' patterns. A linguist's job is to use such conditions to maximize the benefits of capturing the target language phenomena, through a process of trial and error. Given the description of grammar engineering as above, what we expect to see in the initial stage of grammar development is a system precision-oriented by nature. Each rule developed is geared towards a target linguistic phenomenon based on the data observed in the development corpus: conditions can be as tight as one wants them to be, ensuring precision. But no single rule or a small set of rules can cover all the phenomena. So the recall is low in the beginning stage. Let us push things to extreme, if a rule system is based on only one grammar consisting of only one rule, it is not difficult to quickly develop a system with 100% precision but very poor recall. But what is good of a system that is precise but without coverage? So a linguist is trained to generalize. In fact, most linguists are over-trained in school for theorizing and generalization before they get involved in software industrial development. In my own experience in training new linguists into knowledge developers, I often have to de-train this aspect of their education by enforcing strict procedures of data-driven and regression-free development. As a result, the system will generalize only to the extent allowed to maintain a target precision, say 90% or above. It is a balancing art. Experienced linguists are better than new graduates. Out of explosive possibilities of conditions, one will only test some most likely combination of conditions based on linguistic knowledge and judgement in order to reach the desired precision with maximized recall of the target phenomena. For a given rule, it is always possible to increase recall at compromise of precision by dropping some conditions or replacing a strict condition by a loose condition (e.g. checking a feature instead of literal, or checking a general feature such as noun instead of a narrow feature such as human ). When a rule is fine-tuned with proper conditions for the desired balance of precision and recall, the linguist developer moves on to try to come up with another rule to cover more space of the target phenomena. So, as the development goes on, and more data from the development corpus are brought to the attention on the developer's radar, more rules are developed to cover more and more phenomena, much like silkworms eating mulberry leaves. This is incremental enhancement fairly typical of software development cycles for new releases. Most of the time, newly developed rules will overlap with existing rules, but their logical OR points to an enlarged conquered territory. It is hard work, but recall gradually, and naturally, picks up with time while maintaining precision until it hits long tail with diminishing returns. There are two caveats which are worth discussing for people who are curious about this seasoned school of grammar engineering. First, not all rules are equal. A non-toy rule system often provides mechanism to help organize rules in a hierarchy for better quality as well as easier maintenance: after all, a grammar hard to understand and difficult to maintain has little prospect for debugging and incremental enhancement. Typically, a grammar has some general rules at the top which serve as default and cover the majority of phenomena well but make mistakes in the exceptions which are not rare in natural language. As is known to all, naturally language is such a monster that almost no rules are without exceptions. Remember in high school grammar class, our teacher used to teach us grammar rules. For example, one rule says that a bare verb cannot be used as predicate with third person singular subject, which should agree with the predicate in person and number by adding -s to the verb: hence, She leaves instead of *S he leave . But soon we found exceptions in sentences like The teacher demanded that she leave. This exception to the original rule only occurs in object clauses following certain main clause verbs such as demand , theoretically labeled by linguists as subjunctive mood. This more restricted rule needs to work with the more general rule to result in a better formulated grammar. Likewise, in building a computational grammar for automatic parsing or other NLP tasks, we need to handle a spectrum of rules with different degrees of generalizations in achieving good data quality for a balanced precision and recall. Rather than adding more and more restrictions to make a general rule not to overkill the exceptions, it is more elegant and practical to organize the rules in a hierarchy so the general rules are only applied as default after more specific rules are tried, or equivalently, specific rules are applied to overturn or correct the results of general rules. Thus, most real life formalisms are equipped with hierarchy mechanism to help linguists develop computational grammars to model the human linguistic capability in language analysis and understanding. The second point that relates to the topic of recall of a rule system is so significant but often neglected that it cannot be over-emphasized and it calls for a separate writing in itself. I will only present a concise conclusion here. It relates to multiple levels of parsing that can significantly enhance recall for both parsing and parsing-supported NLP applications . In a multi-level rule system, each level is one module of the system, involving a grammar. Lower levels of grammars help build local structures (e.g. basic Noun Phrase), performing shallow parsing. System thus designed are not only good for modularized engineering, but also great for recall because shallow parsing shortens the distance of words that hold syntactic relations (including long distance relations) and lower level linguistic constructions clear the way for generalization by high level rules in covering linguistic phenomena. In summary, a parser based on grammar engineering can reach very high precision; in addition, there are proven effective ways of enhancing its recall too. High recall can be achieved if enough time and expertise are invested in its development. In case of parsing, as shown by test results , our seasoned English parser is good at both precision (96% vs. SyntaxNet 94%) and recall (94% vs. Syntax 95%, only 1 percentage point lower than SyntaxNet) in news genre, and with regards to social media, our parser is robust enough to beat SyntaxNet in both precision (89% vs. SyntaxNet 60%) and recall (72% vs. SyntaxNet 70%). Is Google SyntaxNet Really the World’s Most Accurate Parser? It is untrue that Google SyntaxNet is the “world’s most accurate parser” R. Srihari, W Li, C. Niu, T. Cornell. InfoXtract: A Customizable Intermediate Level Information Extraction Engine. Journal of Natural Language Engineering, 12(4), 1-37, 2006 K. Church: “A Pendulum Swung Too Far” , Linguistics issues in Language Technology, 2011; 6(5) Pros and Cons of Two Approaches: Machine Learning vs Grammar Engineering Introduction of Netbase NLP Core Engine Overview of Natural Language Processing Dr. Wei Li’s English Blog on NLP
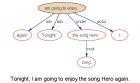
我们知道,语句呈现的是线性的字符串,而语句 结构却是二维的。我们之所以能够理解语句的意思,是因为我们的大脑语言处理中枢能够把线性语句解构(decode)成二维的结构:语法学家常常用类似下列的上下颠倒的树形图来表达解构的结果(所谓 parsing)。 上面这个树形图叫作依从关系树形图(dependency tree,常常用来表达词或词组之间的逻辑语义关系,与此对应的还有一种句法树,叫短语结构树 phrase structure tree,更适合表达语句单位之间的边界与层次关系)。直观地说,所谓理解了一句话,其实就是明白了两种意义:(1)节点的意义(词汇意义);(2)节点之间的关系意义(逻辑语义)。譬如上面这个例子,在我们的自动语句分析中有大小六个节点:【Tonight】 【I】 【am going to enjoy】 【the 【song】 Hero】 【again】,分解为爷爷到孙儿三个层次,其中的逻辑语义是:有一个将来时态的行为【am going to enjoy】,结构上是老爷爷,他有两个亲生儿子,两个远房侄子。长子是其逻辑主语(Actor) 【I】,此子是其逻辑宾语(Undergoer)【the song Hero】,父子三人是语句的主干(主谓宾,叫做 argument structure),构成语句意义的核心。 两个远房侄子,一个是表达时间的状语(adverbial)【Tonight】,另一个表达频次的状语(adverbial)【again】。最后,还有一个孙子辈的节点【song】,他是次子的修饰语(modifier,是同位语修饰语),说明【Hero】的类别。 从句法关系角度来看,依从关系遵从一个原则:老子可以有n(n=0)个儿子(图上用下箭头表示),而儿子只能有一个老子:如果有一个以上的老子,证明有结构歧义,说明语义没有最终确定,语言解构(decoding)没有最终完成。虽然一个老子可以有任意多的下辈传人,其亲生儿子是有数量限制的,一般最多不超过三个,大儿子是主语,次子是宾语,小儿子是补足语。比如在句子 “I gave a book to her” 中,动词 gave 就有三个亲儿子:主语 【I】, 宾语【a book】,补足语 【to her】. 很多动词爷爷只有两个儿子(主语和宾语,譬如 John loves Mary),有的只有一个儿子(主语,譬如 John left)。至于远房侄子,从结构上是可有可无的,在数量上也是没有限量的。他们的存在随机性很强,表达的是伴随一个行为的边缘意义,譬如时间、地点、原因、结果、条件等等。 自然语言理解(Natural Language Understanding)的关键就是要模拟人的理解机制,研制一套解构系统(parser),输入的是语句,输出的是语法结构树。在这样的结构树的基础上,很多语言应用的奇迹可以出现,譬如机器翻译,信息抽取,自动文摘,智能搜索,等等。 在结束本文前,再提供一些比较复杂一些的语句实例。我把今天上网看到的一段英文输入给我们研制的parser,其输出的语法结构树如下(未经任何人工编辑,分析难免有小错)。 说明:细心的读者会发现下列结构树中,有的儿子有两个老子,有的短语之间互为父子,这些都违反了依存关系的原则。其实不然。依存关系的原则针对的是句法关系,而句法后面的逻辑关系有时候与句法关系一致,有时候不一致。不一致的时候就会出现两个老子,一个是与句法关系一致的老子,一个是没有相应的显性句法关系的老子。最典型的情形是所谓的隐性(逻辑)主语或宾语。 譬如第一个图示中的右边那棵结构树中,代词「I」就有两个老子:其句法老子是谓语动词「have learned」,它还有一个非谓语动词(ING形式)的隐性的逻辑老子「(From) reading」,也做它的逻辑主语 (who was reading? I)。再如第二个图示中的语法结构树中,定语从句的代表动词「were demonstrating」的句法老子是其所修饰的名词短语「students」,但逻辑上该名词短语却是定语从句动词「were demonstrating」的主语(actor)。有些纯粹的句法分析器(parser)只输出句法关系树,而我们研制的parser更进一步,深入到真正的逻辑语义层次。这样的深层分析为自然语言理解提供了更为坚实的基础,因为显性和隐性的关系全部解构,语义更为完整。 我们每天面对的就是这些树木构成的语言丛林。在我的眼中,它们形态各异,婀娜多姿,变化多端而不离其宗(“语法”)。如果爱因斯坦在时空万物中看到了造物主的美,如果门捷列夫在千姿百态的物质后面看到了元素表的简洁,语言学家则是在千变万化的语言现象中看到了逻辑结构之美。这种美的体验伴随着我们的汗水,鼓励我们为铲平语言壁垒而愚公移山,造福人类。 后记:When I showed the above trees to my daughter today, she was amazed, pretty! She asked, is this what you made the machine to do in diagramming sentences? Yes. Wow, incredible. I don't think I can diagram the sentences as nice as these. Can some day the machine be smarter than you the creator? Is the machine learning by itself? I said, it is not self-learning at this point and the self-learning system is too research oriented to put into a real life system now. But I do observe from time to time that the machine we made for parsing sometimes generate results of very complicated sentences way beyond our expectation, better than most human learners at times. This is because I encode the linguistics knowledge piece by piece, and machine is super good at memory. Once taught, it remembers every piece of knowledge we programmed into the system. Over the years of the development cycle, the accumulation of the knowledge is incredibly powerful. We humans are easy to forget things and knowledge, but machine has no such problems. In this sense, it is not impossible that a machine can beat his creator in practical performance of a given task. 回答: I don't think tree is the way my mind thinks 1窃以为,句法树迄今仍是大脑黑箱作业的最好的模拟和理论 2 does not really matter 作者: 立委 (*) 日期: 06/03/2011 04:30:20 As long as subtree matching is a handy and generalized way of info extraction. Tree is not the goal but a means to an end. The practical end is to extract knowledge or facts or sentiments from language. In practice, our goal is not to simulate the human comprehension per se , the practical goal is: Quote 在这样的结构树的基础上,很多语言应用的奇迹可以出现,譬如机器翻译,信息抽取,自动文摘,智能搜索,等等。 【相关博文】 《泥沙龙笔记:漫谈自动句法分析和树形图表达》 【 科普小品:文法里的父子原则 】 【立委科普:语法结构树之美(之二)】 《新智元:有了deep parsing,信息抽取就是个玩儿》 泥沙龙笔记:parsing 是引擎的核武器,再论NLP与搜索 乔氏 X 杠杠理论 以及各式树形图表达法 【 立委随笔:创造着是美丽的 】 【 科研笔记:开天辟地的感觉真好 】 【立委科普:美梦成真的通俗版解说】 【征文参赛:美梦成真】 【立委科普:自然语言parsers是揭示语言奥秘的LIGO式探测仪】 【置顶:立委科学网博客NLP博文一览(定期更新版)】
 标签: parser
标签: parser