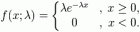广义 Kulback-Leibler 语义信息公式和最大似然法的一致性 鲁晨光 (这是一篇长文的摘要,删除了部分哲学讨论,保留了和统计及信息论相关的内容,目的是让研究最大似然法的学者看看。我相信文中广义信息公式可以比Kullback-Leibler公式更方便表达和解决最大似然问题,并能解决最大似然学派和贝叶斯学派的矛盾。文中公式(15)是一个重要结论,应该能给最大似然估计供极大方便。笔者研究估计问题时间不长, 不妥之处欢迎指正。) 1. 引言 Shannon ( 1948 ) 发表文章:《通信的数学理论》 ,随后 Weaver 提出语义信息 研究方向, Bar-Hillel, Y. 和 Carnap ( 卡尔纳普 ) 提出用逻辑概率代替统计概率度量语义学信息 . 公式是 inf( i )=-log m p ( i ) 。其中 i 是命题, m p 是逻辑概率。不过最早提出概率和信息反相关的却是 Popper ( 波普尔 ) 。 Popper 早在 1935 年的著作《科学发现的逻辑》 ( , 96,269 ) 中就提出用可检验性,或可证伪性,或信息作为科学理论划界和评价的准则,并且明确提出,概率越小,信息量越大。后面谈到, Popper 提出的检验的严厉性公式 ( ,526) 稍加改善,就可以用作语义信息计算。 在 Barhillel , Carnap 和 Popper 之后, 西方语义信息测度的研究总结见 , 关于信息哲学的研究总结见 。西方最有代表性的研究者是 Floridi 。中国最著名的语义信息倡导者和研究者是钟义信 . 另外也有其他学者研究广义信息 或多或少联系到语义信息。但是根据上述研究,我们仍然不能计算一个简单预测比如 “ 明天有大雨 ” 或 “ 小偷大约 20 岁 ” 的信息;或 GPS 箭头、手表指针、温度表和秤的读数提供的信息。 另一方面,自从 Akaike 把 Fisher 的最大似然度方法和 Kullback-Leibler ( 后面简记为 KL ) 公式联系起来讨论估计的优化,越来越多的归纳问题研究者意识到,最大似然度方法信息方法相结合可以同时解释证伪和归纳 。他们的研究已经把我们带到迷宫入口附近。但是如何根据事实发生的样本序列确证一个预测,比如 “ 明天有大雨 ” , “ 所有天鹅是白的 ” ,并算出它们的确证度? 依然众说纷纭,没有一致结论 。 笔者以为,流行的语义信息和归纳问题研究的困难都是由于:统计概率,逻辑概率,命题真值,真值函数等没有很好区分,比如同时用 P 表示统计概率和逻辑概率,同时用 E 表示个体和变量,因而使得分析的框架不清晰。 笔者曾提出和 Shannon 及 Popper 理论兼容的广义信息论 ,它能很好解释证伪。笔者最近研究发现,可以通过降低对假设的信任度,减少预测失误带来的信息损失,提高平均信息。这样,平均语义信息公式就可以同时用于计算 Popper 的信息和优化现代归纳主义研究的确证度。和流行的做法不同,这个公式同时使用了逻辑概率 ( 用 T 表示 ) 和统计概率 ( 用 P 表示,反映证据和背景知识 ) 。重要的是,公式还使用了模糊真值函数 ( 即条件逻辑概率 ) 以及信任度 c ( 它在 -1 和 1 之间变化 ) 。本文继承或关系到 Popper , Shannon , Barhil and Carnap, Zadeh , Kulback and Leibler , Fisher , Akaike 等人的研究结果。 下面首先讨论谓词的真值函数和逻辑概率,以及它们和统计概率之间的关系。然后通过推广经典信息公式得到平均语义信息公式和广义 Kullback-Leibler 公式,说明它们如何用于预测的信息评价,如何符合 Popper 用于检验或证伪的信息准则。文中最后讨论,如何优化假设,包括优化信任度 c ,从而提高平均语义信息,使之达到其上限: KL 信息。 2. 真值函数和逻辑概率 2.1 命题的真值和谓词的真值函数 日常语言中,语句真假往往是模糊的。比如猜测 “ 小偷大约 20 岁 ” ,这话的真假是模糊的,该在 0 和 1 之间变化。如果小偷真的 20 岁,预测真值就是 1 ,如果有偏差, 比如是 25 岁, 真值就变小, 比如说是 0.5 ;如果是 30 岁,真值就更小。所以日常语言的真值函数取值于实数区间 而不是二值集合 {0,1}. 后面讲到的真值函数都是模糊真值函数。 我们用大写字母 E 表示一个变量, 代表一个个体 ( individual ) 或证据,它是个体 e 1 , e 2 ,… , e m 中的一个,这些个体构成集合 A , 于是有 E ∈ A ={ e 1 , e 2 , … , e m } 。 E = e i 表示 e i 发生。类似地, 预测或假设是 H ∈ B ={ h 1 , h 2 , …, h n }. 一个预测 h j 发生后, E = e i ,预测就变为命题 h j ( e i ). 用经典信息论的语言来说, P ( E ) 是信源或先验概率分布, P ( H ) 是信宿。条件概率矩阵 P ( H | E ) 是信道。对于语义通信来说,在 Shannon 信道之外还存在语义信道 T ( H | E ) 。 一个典型的语义通信例子是天气预报, E 表示降水量,比如 15mm. H 表示降水量预报。 比如 h 1 = “ . 无雨 ” ( 比如 “ 明天无雨 ” , 其他类推 ) , h 2 = “ . 有雨 ” , h 3 = “ . 小雨 ” , h 4 = “ . 中雨 ” , h 5 = “ . 小到中雨 ” … H = h j 表示 h j 被选择。类似的例子是关于年龄 ( E ) 的一组陈述 ( H ) : “ . 是小孩 “ , “ . 是年轻人 ” , “ . 是中年人 ” , “ . 是老年人 ” 。 另一个典型的语义通信方式是数值预测或估计 ( 后面简称估计,数学上通常记为 e^ j , e^ j = h j = h j ( E )= “ E ≈ e j ”= “ E 大约是 e j ” 。不光是语言表达的估计, GPS 的箭头, 手表的指针,甚至一种色觉, 都可以看做是一个估计 . 估计的例子参看表 1. 表 1 估计 h j = e^ j = “ E ≈ e j ” 举例 例子 预测或假设 h j = “ E ≈ e j ” 事实或证据 E e i h j ( e i ) 的真值 T ( A j | e i ) 大约是 日常语言 “ 小偷大约 20 岁 ” 小偷实际年龄 18 岁 0.9 经济预测 “ 今年股市可能涨 20% ” 实际涨幅 0 0.1 秤 秤的读数 “ 1KG ” 实际重量 0.9KG 0.3 GPS 地图上箭头 ↖ 实际位置 偏右 5 米位置 0.9 色觉 一种色觉比如黄色觉 实际色光,带有某种主波长 主波长是 660nm 的色光 0.7 用 Zadeh 开创的模糊数学的语言说,相对 h j = h j ( E ), A 中有一个使 h j 为真的模糊子集 A j , 一个元素 E 在 A j 上的隶属度函数 m Aj ( E ) 就是就是 h j 的真值函数, 记为 T ( h j ( E ))= T ( h j | E )= T ( A j | E )= m Aj ( E ) (1 ) 当 E = e i 时,真值函数就变为真值 T ( A j | e i ). 天气预报等自然语言的真值函数来自习惯用法,后面将证明它们来自过去的条件概率函数 P ( h j | E ) 。如果不知道过去的 P ( h j | E ) ,也可以采用随机集合的统计方法得到 。而估计 h j = “ E ≈ e j ” 的真值函数来自人工定义和实际误差概率分布 —— 也取决于过去的条件概率 P ( h j | E ) ,可以近似地用指数函数 ( 没有系数的正态分布 ) T ( A j | E )=exp ( 2 ) 表示,其最大值是 1 。其中 d 表示标准差, 反映估计的模糊程度, d 越大,估计就越模糊 , 函数波形覆盖面积越大。这里我们假设这些估计都是无偏估计,有些非无偏估计可以通过对 E 的转换得到, 比如用 E 0.5 代替 E ,使估计成为无偏估计。 假设相对每个 h j 或 A j , 存在一个 e j ( 相当于柏拉图的理念和我让通常说的典型 ) 使得 T ( A j | e j )=1, 那么, h j ( e i ) 的真值 T ( A j | e i ) 就可以理解为 e i 和 e j 的相似度或混淆概率。 2.2 逻辑概率 T ( A j ) 及其和真值函数 T ( A j | E ) 及信源 P ( E ) 的关系 后面内容见附件 语义信息最大似然度理论-short博文.pdf
今天本来在试用PHYML中的最大似然法来构建系统发育树,后来与人交流,他要对一些序列进行比对,我推荐他用Mega软件,就让它从网上下载,他下载后,我发现Mega4已升级到5.0版本了。再一看,发现它居然支持最大似然法来构建系统发育树了,而以前的4.0版是不支持的。我赶紧自己也下载了一个,安装运行后,发现确实能用。不过美中不足的是,在该软件的主界面上有一个提示,说:This is a beta test release. Please do not use results generated in publications。哎,不管怎么说,以前大家都用装在苹果机上的PAUP中的ML法来构建系统发育树,而操作起来十分困难,现在好了,有MEGA5了。我试着用自己的16S序列数据,用ML法建了个树,发现所需时间不是很长,我在写帖子的时候,运行了17分钟了,完成了69%的任务。看来速度不会象苹果机上运行PAUP那么长的时间了。喜欢尝鲜的人赶紧下载下来试试。 除了这个ML法的大改进外,Mega5还有其它方面的改进,看起来和使用起来都比以前的mega4要好用。期待正式版的早日诞生! Mega5的下载地址为: http://www.megasoftware.net/beta/index.php ,需要填上姓名和email地址,然后从email中确认一下即可以下载了。
 标签: 最大似然法
标签: 最大似然法