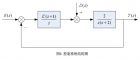
最近给本科生上《自动控制理论》(双语),使用的教材是 J. David Powell 和 Abbas Emami-Naeini 合著的 Feedback Control of Dynamic Systems (Fifth Edition) ,参考文献 。该教材有其特色。下面对一些基本概念做一些探讨,希望能和同行一起交流,共同提高。 1、 什么是控制系统的输出 这是自动控制理论的一个基本问题。我们称被控制的量为控制系统的输出,如图 1 中 Y ( s ) (以后就简称为系统的输出或者输出)。系统的输出又称为控制系统对输入信号的响应。 可能是为了简化问题,参考文献 都没有考虑测量噪声。如果要考虑被控制量的测量噪声时,如何定义输出呢?文献 和文献 有不同的定义。文献 定义 Y N ( s ) 为输出,如图 2 所示。 文献 仍旧定义 Y ( s ) 为输出,如图 3 所示。 我觉得,相对来说,图 3 的定义可能更为合理,毕竟图 2 所定义的输出是已经被噪声所污染过的,不是我们想要的量。 按文献 的定义,反馈控制可以降低系统相对于参考输入信号和扰动输入信号的敏感度,但无法同时降低系统相对于噪声输入信号的敏感度(两者是有矛盾的)。 2、 什么是系统的误差 如果按图 1 的情形,一般都定义为 E ( s )= R ( s )- H ( s ) Y ( s ) ( 1 ) 这里不会有什么异议。对于图 3 的情形,我们仍然应该按上式定义。 但是,要注意的是,此时的误差已经不是控制器的输入信号了。 如果有什么疑惑,不妨先假设 H ( s )=1 ,一切就都好理解了。 3、 如何定义系统类型 除了文献 ,参考文献 中,,都是按开环传递函数 C ( s ) G ( s ) H ( s ) 中包含的积分环节的个数来定义系统类型。即,如果不包含积分环节,称为 0 型系统,如果包含一个积分环节,称为 1 型系统,依此类推。 而文献 的定义如下: A stable system can be classified as a system type, defined to be the degree of the polynomial for which the steady-state system error is a nonzero finite constant. 需要解释一下,这里的 polynomial 是指输入时间函数的多项式。 该定义的好处:一是只针对稳定的系统定义系统类型,对于不稳定的系统,由于不存在稳态误差,就不定义系统类型了。二是,系统的类型是和输入信号的位置有关的。例如,对于图 4 所示的系统: 按一般教材的定义,该系统是 2 型系统。而按文献 的定义,对于参考输入 R ( s ) ,系统是 2 型系统;对于扰动输入 D ( s ) ,系统是 1 型系统。 按文献 的定义,我们可以有以下的结论了: 0 型系统不能消除稳态误差; 1 型系统可以消除阶跃输入信号带来的稳态误差,而对于斜坡输入信号的稳态误差是一个有限的常值,其余依此类推,不管输入信号作用在何处。 顺便说一下,一般不会讨论噪声引起的稳态误差。正确的做法是,在反馈通道加滤波器将其滤除。 4 、 稳态误差常数如何定义 我们都知道,所有的教材,稳态误差常数定义如下: 稳态位置误差系数:K p =Lim 稳态速度误差系数:K v =lim 稳态加速度误差系数:K a =Lim 既然只有稳定系统才有稳态误差, 建议最好在定义这些系数之前加一个条件 ,即 1+ C ( s ) G ( s ) H ( s )=0 ( 2 ) 的根都位于 LHP (左半平面)。也就是说,对于不稳定的系统,我们就不讨论稳态误差系数了,没有意义! 参考文献 J. David Powell, Abbas Emami-Naeini. Feedback Control of Dynamic Systems (Fifth Edition) . 北京:人们邮电出版社, 2007 年 B. C. Kuo. Automatic Control Systems (7 th Edition) . New York: John Wiley Sons, INC 李友善 . 自动控制原理 . 北京:国防工业出版社, 2005 年 吴麒,王诗宓 . 自动控制原理(上册)(第二版) . 北京:清华大学出版社, 2006 年 胡寿松 . 自动控制原理(第四版) . 北京:科学出版社, 2001 年 卢子广,林靖宇,周永华 . 自动控制理论 . 北京:机械工业出版社, 2009 年
曾经参与科学网博客的一个讨论,话题是一些生物活性数据的难于重复性。有位某生物类期刊的工作人员跟我是有不同意见的,那是可以理解的。 美国化学会的药物化学杂志有篇新文章,基本上回答了一些我很多年前就想知道的问题: 《 The Experimental Uncertainty of Heterogeneous Public K i Data》 http://pubs.acs.org/doi/abs/10.1021/jm300131x 注意,文章摘要里面给的图有点误导,图中没有给出单位:摘要里面把Ki和pKi混在一起,而根据文章图中的单位应该是pKi, 即平衡常数Ki的负对数。如,6就是一个微摩尔,9就是一个纳摩尔。下面是来自正文里面有单位的图 基本上,这篇文章收集了大量的生物活性数据,通过统计分析来说明即使是对于同样体系的实验测量,得到的结果都是有一定误差的(pKi1 和 pKi2之间的差别)。统计上说,平均的误差大约是3倍,显然很多数据间的差别是大于3的。这从上图也可以看出,甚至很多差别是多于2个对数单位的,即100倍以上,那是蛮可怕的,这基本上不是正常的误差,而可能是来自某种错误因素了,否则,那啥生物学家的工作也太不靠谱了。 对于此类的数据挖掘,最好还是给一些具体的实例,看看问题到底在哪里? 否则,还是有点云中漫步的感觉。 另外,文章也建议用那个平均误差作为理论计算的上限。这个是有点问题的。一方面,上面那个3倍是各种胡乱数据的一个平均,而实际是对不同体系,可重复性就可能不太一样。比如,通常细胞活性数据就比酶的活性数据更不可重复。另一方面,有些时候理论计算的精度是可能强于实验的。这个不太好理解,但是有些时候计算预测出来的相对活性确实是比较精确的,因为很多可能的误差都被抵消了。
 标签: 误差
标签: 误差