云计算的虚实 Ø 新闻回顾 目前仍在向个体用户提供网络存储服务的知名品牌还有腾讯微云和百度网盘。 Ø 云计算的前生 分布式计算研究如何把一个大问题分解成若干个小问题,以及如何把这些小问题分配出去,让若干终端计算资源分别求解这些小问题,最后再把有关结果综合起来得到原问题的解。其构想来自于计算机学科中基本方法 --- 分治法 (divide-and-conquer) 。分布式计算的历史可以追溯到半个世纪前,现代电子计算机的发展初期。 网格计算 (Grid computing) 是利用互联网上闲置的计算资源来解决大型问题的一种计算模式,这就意味着应用程序不再受限于具体的物理系统和平台软件,数据和程序能够在各个计算节点间“流动起来”。网格计算主要被各大学和实验室用于高性能计算项目。关于网格的定性和发展前景,有如下一些说辞。 “网格是继传统因特网、 Web 之后的第三次互联网浪潮,可以称之为第三次因特网的应用。传统因特网实现了计算机硬件的连通, Web 实现了网页的连通,而网格则试图实现互联网上所有资源的全面连通,其中包括计算资源、存储资源、通信资源、软件资源、信息资源、知识资源等。”美国《福布斯》杂志预测,网格技术将在 2004 年至 2005 年出现一个高峰,推动信息产业市场的持续高速发展,在2020年将产生一个年产值为20万亿美元的大产业。 在网格计算上发力最狠的是大名鼎鼎的 Sun 公司,其主要产品是工作站及服务器。目前最流行的编程语言 Java 就是该公司在研发中产生的副产品。但该公司没能熬到瓜熟蒂落的时候, 2009 年 4 月 20 日甲骨文公司收购了 Sun 公司。 Ø 云计算的今生 云计算 (cloud computing) 的正式定义,且看下面截图 : 与网格计算不同,云计算更多的是由工业界主导发展的一套技术和标准。云计算和网格计算都能够提高 IT 资源的利用率,但是云计算依靠 IT 资源供给的灵活性,革新了 IT 产业的商业模式,侧重于资源与技术的 外包服务 。网格计算是拥有计算能力的节点自发形成联盟,共同解决涉及大规模计算的问题,侧重于资源与技术的 联合共享 。 1996 年,康柏公司的一群技术主管在讨论计算业务的发展时首次使用了 Cloud Computing 这个词,他们认为商业计算会向 Cloud Computing 转移。 1997 年,美国的 Chellappa 教授把“ Cloud Computing ”这个词定义为:“计算边界由经济而并非完全由技术决定的计算模式”。 2000 年, Sun 公司发布了太阳云 ( Sun cloud) 。 2006 年,贝索斯发表了关于云计算的著名演讲,并向世界宣布亚马逊将投资和创立云计算 AWS 的宏大计划。同一年, Google 首席执行官施密特在搜索引擎大会上,首次正式提出“云计算”的概念。将计算、服务和应用作为一种公共设施提供给公众,这正是“云计算”的初衷和动力。 2007 年, IBM 推出蓝云 (Blue Cloud) 服务。 2008 年,微软在其开发者大会上发布了一个全新的云计算平台── Azure Service Platform 。 2010 年,华为公司正式公布了云计算战略。华为表示:“要让全世界所有的人,像用电一样享用信息的应用与服务”。 2013 年 9 月,就在阿里云宣布突破 5K 测试的三个月后,腾讯云宣布正式面向全社会开放。 Ø 外包计算 云计算侧重于外包服务,而不是资源共享, 它必须追求利润,那么这种商业服务的模式是啥呢?是百度的竞价排名、超速下载,淘宝的竞价推广,网易的云音乐?这些面向市民的商业模式与外包计算有什么关系呢? 严格说来,计算机表示的底层数据只有两种形式,一是数值型的,二是字符型的。这两种数据在计算机内部的表示方法是不一样的,为此键盘上也分出两部分,数字键和字符键。数值的表示范围取决于浮点数系统,字符的表示范围取决于编码方法 ( 如通常的 Unicode 编码 ) 。因此计算机处理的实际对象可分为两种,一是数值计算 ,二是文本处理。 最初计算机的设计目的就是为了数值计算,但现在几乎所有的家用电脑都是用来做信息处理的,写文章、 P 图像、听音乐、看视频。即便是理工类的大学生,也只习惯于用计算器来做些数值计算。 学术界讨论的云外包计算有哪些内容呢? 2015 年秋天,笔者针对这一问题做了些功课,研读了一些文献。归纳起来主要有: l 大规模的数值计算 --- 矩阵乘法,矩阵求逆,线性回归,线性规划,这些都涉及到数值误差,但至今还没有切实可行的外包方案。这类问题面向的应该是团体用户。相关文献中常见的错误 ( 见后面已经发表的系列论文 ) 包括: 2 在加密时忽视了相容性,把一个可解的问题变换成一个不可解的外包问题; 2 忽视了浮点数系统和有限域的差别,错误地把有限域上的运算当成了数值运算; 2 混淆了计算任务的复杂性,把一个自身就能完成的任务强行外包出去; 2 加壳、脱壳时忽视了数值误差分析; 2 忽视了外包交互过程的通讯成本; 2 应用场景过于理想化,很难产生实际需求。 l 文件的安全存储、匿名访问等,这些可能会涉及到数值误差。这类问题面向的可以是个体用户。 l 一些特殊的计算任务,如密码学上的模指数及双线性映射计算,这些不涉及误差问题。面向的只是一些假想的客户。顺便说一下,公钥密码算法主要利用模指数运算来混淆和扩散冗余,不是普通的数值计算,本质上做的是文本变换。 外包计算可以帮助客户完成自身不可能完成的任务,还能保护客户的隐私,但应用场景真的有学术论文描述的那么多吗?一些科研机构或许会有这样的需求,但实际外包成本还涉及到主、客之间的交互问题、信任问题,这是无法用计算复杂度来衡量的。 Ø 云计算的来生 免费的面向个体用户的 360 网盘和 163 网盘的相继关闭,说明云存储服务没有企业当初设想的那么美好。那些还在收费的云服务项目发展结果又将如何呢?云计算的来生是充塞了大数据的物联网?是正在孕育中的某个概念? We are not sure. ----------------------------------------------------------------------------------------- 相关工作: Zhengjun Cao, Lihua Liu: Comment on “Harnessing the Cloud for Securely Outsourcing Large-Scale Systems of Linear Equations”. IEEE Transactions on Parallel and Distributed Systems , Vol.27, No.5, 1551-1552 (2016) Zhengjun Cao, Lihua Liu, Zhenzhen Yan: An Improved Lindell-Waisbard Private Web Search Scheme. International Journal of Network Security , Vol.18, No.3, 538-543 (2016) Zhengjun Cao, Lihua Liu, Olivier Markowitch: On Two Kinds of Flaws in Some Server-aided Verification Schemes. International Journal of Network Security , Vol.18, No.6, 1054-1059 (2016) Zhengjun Cao, Lihua Liu: A Note on Two Schemes for Secure Outsourcing of Linear Programming. International Journal of Network Security , Vol.19, No.2, 323-326 (2017) Zhengjun Cao, Lihua Liu: The Paillier's Cryptosystem and Some Variants Revisited. International Journal of Network Security , Vol.19, No.1, 89-96 (2017) Lihua Liu, et al.: Anonymity and Certificateless Property Could Not Be Acquired Concurrently, International Journal of Electronics and Information Engineering , Vol.7, No.2, 61-67 (2017) Lihua Liu, Zhengjun Cao, Chong Mao: A Note on One Outsourcing Scheme for Big Data Access Control in Cloud, International Journal of Electronics and Information Engineering , Vol.9, No.1, 29-35 (2018) Zhengjun Cao, et al.: Analysis of One Dynamic Multi-Keyword Ranked Search Scheme over Encrypted Cloud Data, International Journal of Network Security , Vol.20, No.4,683-688 (2018) Zhengjun Cao, et al.: Ruminations on Fully Homomorphic Encryption in Client-server Computing Scenario, International Journal of Electronics and Information Engineering , Vol.8, No.1, 32-39 (2018) Lihua Liu, et al.: A Note on One Secure Data Self-Destructing Scheme in Cloud Computing, International Journal of Network Security , First Online June 14, 2019 (Doi: 10.6633/IJNS.881) Zhengjun Cao, Lihua Liu, Olivier Markowitch: Comment on Highly Efficient Linear Regression Outsourcing to a Cloud, IEEE Transactions on Cloud Computing , Vol.7, No.3, pp.893 (2019) 曹正军,刘丽华 : 现代密码算法概论 , 哈尔滨工业大学出版社, 2019/5.
5 月18日,IJAC小编参加了如火如荼的中国云计算技术大会(以下简称CCTC,Cloud Computing Technology Conference), CCTC由国内最大开发者社区CSDN主办,是业内极具影响力的云计算和大数据技术年度盛会,会议解读本年度国内外云计算技术发展最新趋势,深度剖析云计算与大数据核心技术和架构,聚焦云计算技术在金融、电商、制造、能源等垂直领域的深度实践和应用。 会议具体日程和信息参见 http://cctc.csdn.net/ IJAC 在云计算方面不仅发表过 Special Issue on Cloud Computing,近期也发表了系列云相关的论文,具体下载信息如下,欢迎阅读! Recent Articles on Cloud Computing The Interaction between Control andComputing Theories: New Approaches MagdiS. Mahmoud, Yuanqing Xia FullText: https://link.springer.com/article/10.1007/s11633-017-1070-2 Or: http://www.ijac.net/EN/abstract/abstract1920.shtml Security Analysis Model, System Architectureand Relational Model of Enterprise Cloud Services Dang-Dang Niu, Lei Liu, Xin Zhang, Shuai Lü, Zhuang Li FullText: https://link.springer.com/article/10.1007/s11633-016-1014-2 Or: http://www.ijac.net/EN/abstract/abstract1841.shtml Hybrid Collaborative Management Ring onMobile Multi-agent for Cloud-P2P Xiao-Long Xu, Nik Bessis, Peter Norrington FullText: https://link.springer.com/article/10.1007/s11633-016-1002-6 http://www.ijac.net/EN/abstract/abstract1837.shtml Optimal Content Placement and RequestDispatching for Cloud-based Video Distribution Services Zheng-Huan Zhang, Xiao-Fen Jiang, Hong-Sheng Xi FullText: https://link.springer.com/article/10.1007/s11633-016-1025-z http://www.ijac.net/EN/abstract/abstract1837.shtml Special Section on Cloud Computing ( IJAC , August2011 ) IC Cloud: Enabling Compositional Cloud Yi-Ke Guo (帝国理工大学郭毅可教授) , Li Guo 10.1007/s11633-011-0582-4 https://link.springer.com/article/10.1007/s11633-011-0582-4 http://www.ijac.net/EN/abstract/abstract817.shtml A Method for Trust Management in Cloud Computing: Data Coloring byCloud Watermarking Yu-Chao Liu, Yu-TaoMa, Hai-Su Zhang, De-Yi Li ( 李德毅院士 ) , Gui-Sheng Chen https://link.springer.com/article/10.1007/s11633-011-0583-3 http://www.ijac.net/EN/abstract/abstract818.shtml An Automatic Intrusion Diagnosis Approach for Clouds Junaid Arshad ( University of Leeds ) , Paul Townend, JieXu https://link.springer.com/article/10.1007/s11633-011-0584-2 http://www.ijac.net/EN/abstract/abstract820.shtml Trustworthy Assurance of Service Interoperation in Cloud Environment Bing Li, Bu-QingCao, Kun-Mei Wen, Rui-Xuan Li https://link.springer.com/article/10.1007/s11633-011-0585-1 http://www.ijac.net/EN/abstract/abstract821.shtml
【编者按】一直以来,物联网都被无数人追捧,已经火热到无法回转的地步。人们预计到2020年物联网中连接的设备将超过500亿。依托于射频识别技术,全球设备互联的构思从诞生之初就产生了各种能够与现实环境进行互动的物品的设想。从某种意义上来说,物联网为联网的物品带来了视觉和表达能力。而移动技术、大数据与云计算对物联网有哪些影响和利弊呢? 以下为英文原文。 随着物联网不断发展,今天我们再来讲讲移动技术、大数据与云计算对物联网的影响。 移动技术 说到移动技术,我想大家跟我一样对移动设备与移动应用在21世纪的创造记忆犹新。 据估计2015年底移动设备数量将超过全球人口总数。 “物联网对移动领域是仙丹还是毒药?” 移动技术是物联网未来的重要一环,它改变了我们生活的方方面面。 对已经使用了物联网的机构所做的分析显示用户更偏好于享受现成的移动应用。事实上开发者应着力于为用户提供更强有力的控制,以便用户可以随意操控家里、车里以及办公室里的一切设备。 还有一个悬而未决的大问题。那就是物联网与移动产业趋向是否一致,以及物联网是否会摧毁整个通信、宽带行业或是互联网本身? 关于这个问题的辩论仍在继续。有人认为移动设备将会成为用户与物联网设备交互的平台。也有人认为物联网的万物互联特性将减低移动设备与移动应用的重要性。 这场辩论使我们迷惑:物联网崛起之日,二十亿智能手机将何去何从? 大数据 与物联网有关的另一个重要方面是大数据。时至今日仅仅收集数据已经远远不够,对数据进行处理分析并将分析结果迅速转化为行动的指导才是至关重要的。 每天都有数以百万计的新设备加入物联网,如何处理这些设备所产生的各式数据是一个巨大的挑战。传统的数据分析系统面对如此海量的数据已经无能为力。 数据无处不在,对数据的处理是企业必须面对的问题。很多企业已经转向了诸如Hadoop和集群计算这样的新技术来减少处理数据所花费的时间。即使面对海量数据,这些技术也可能在很短时间内就完成处理。 数据处理的即时性也取得了长足的进步。现在有些医院已经开始监测危重病人的实时数据以便了解病人情况。 大数据分析对于物联网最重要的意义在于对数据的实时采集和实时分析并根据分析采取合适的行动。在设计分析解决方案时,也要考虑到从多种设备采集信息并产生一定的反馈。 云计算 时至今日云计算已经成为主流,但我们心中一直存有疑虑那就是物联网的云端化会产生怎样的结果。 企业更偏好云计算平台以便享受云计算所提供的扩展性,效率以及高可用性。 有分析显示调查的企业中有93%已经在使用或测试基础设计即服务IaaS。使用混合云策略的企业也从2014年的74%增加到了82%。 在即将来临的创新浪潮中,物联网将会以更快的速度发展。得力于云计算对地理分散的各种设备协同合作的良好支持,物联网的云端化也成为了一个重要的发展点。将各种设备所提供的服务结合起来并可靠地支持大量用户应是物联网应用的核心要求,而这正是云计算所擅长的。 云计算在万物互联的世界中显示出了它的灵活性、扩展性和高性能。事实上云计算有着解决物联网应用架构方面问题的潜力。 云计算使不同的用户分享计算资源,但它也同时带来了数据泄露的风险。有了物联网,更是将无数的个人信息暴露在了危险之中。 所以疑虑仍在:物联网的云端化到底是有益还是有害? 在争议与问题中,物联网在过去几年取得了标志性的创新和技术进步。大部分的进展是在移动技术、大数据与云计算领域。这三个领域的发展融合一定能为企业提供更好的综合IT架构平台并在企业中大放异彩。 英文原文: Impact of Cloud, Mobile and Big Data on IoT Will IoT make or break? (译/刘旭坤 审校/朱正贵 责编/仲浩)
2009年有个学期作业,做了一个关于云计算的调研,自Google2006年提出云计算这个概念后,引起了广泛关注,后来IaaS,PaaS, SaaS, 大数据,分布式计算,无联网,深度学习.....这些关键词逐步火热了起来。对这些概念有了一定的认识,在班上讨论时,突然冒出了云计算和机器人结合的想法,随后就经常关注云计算的发展,想办法跟自己的爱好-机器人结合起来,还把这个想法告诉一些老师和朋友。有老师说,我想得太大太宽泛了,这个主题不适合做研究。虽然后来做了关于护理机器人的研究,但是没有放弃云机器人 (Cloud Robotics),时刻关注着方面的发展动向。现在 云机器人是已经成为机器人领域的一个新的热点新方向,将机器人技与云计算相结合,以增强单个机器人的能力,同时将广泛扩展机器人的应用领域,加速和简化机器人系统的开发过程,降低机器人的构造和使用成本,无论是家庭机器人,工业机器人,医疗机器人,都具有极其深远的意义。比如,在云端可以建立知识库,深度学习,云辅助的图像识别和语音识别,移动机器人 导航(如 Google 街景,语义环境模型,水下 环境模型库), 大规模协作机器人,模块化机器人,职业机器人,等等。 https://sites.google.com/site/ruijiaoli/blogs/page The concept of cloud robotics attempts to invoke cloud computing technology in robotics. Cloud computing is computing in which large groups of remote servers are networked to allow centralized data storage and online access to computer services or resources. Clouds can be classified as public, private or hybrid . Robots can benefit from the powerful computational, storage, and communications resources of modern data centers in the cloud. In addition, it removes overheads for maintenance and updates, and reduces dependence of local computing. Robots can take advantage of the rapid increase in data transfer rates to offload tasks without hard real time requirements from cloud. We can develop ubiquitous system for robots with powerful capability but reduce the cost of computing with cloud computing. And it possible to build robots have intelligent brain in cloud- knowledge base, virtual world environment model (may like Google street view), image processing and querying, large scale robots collaboration, augmented human~robot interaction (remote communication and reasoning). Such robot systems are capable of adapting variety of situations and providing different service from human‘s delegation. With regard to this concept, We can propose a various functional cloud robotics based system such as intelligent healthcare system, smart home with domestic robots, education robots, intelligent robot workers/ professionals....... In 2012, robotics celebrated its 50 year anniversary in terms of deployment of the first industrial robot at a manufacturing site. Since then, significant progress has been achieved. Robots are being used across the various domains of manufacturing, services, healthcare/medical, defense, and space. Robotics was initially introduced for dirty, dull, and dangerous tasks. Today, robotics are used in a much wider set of applications, and a key factor is to empower people in their daily lives across work, leisure, and domestic tasks. Three factors drive the adoption of robots: i) improved productivity in the increasingly competitive international environment; ii) improved quality of life in the presence of a significantly aging society; and iii) removing first responders and soldiers from the immediate danger/action. Economic growth, quality of life, and safety of our first responders continue to be key drivers for the adoption of robots. Robotics is one of a few technologies that has the potential to have an impact that is as transformative as the Internet. Robotics is already now a key technology for inshoring of jobs by companies such as Apple, Lenovo, Tesla, Foxconn, and many others and citizens who used to have to rely on family or nurses for basic tasks such as shaving, preparing a meal, or going to the restroom are having a higher degree of independence. In the aftermath of the earthquake in Fukushima, it was evident that it would be a challenge to get an actual sense of the resulting destruction without the deployment of robots for assessment of the magnitude of the damage and assessment of the environmental impact. Currently, many small factories in East China employe robot to work for some repeated work to reduced their product cost, which is their only chance to keep competitive in the market as a several factory managers said. On the other hand, with the increasing demand of robots, the development and manufacture of robots has been becoming a large market, Google has acquired more than ten robotics company to enlarge its business in robot. Other traditional robot companies such as KUKA, ABB robot, iRobot, SIASUN etc. have notable growth of markets from their financial reports. To fully evaluate the potential of using robotics across the set of available applications, a group of more than 160 people came together in five workshops to identify: i) business/application drivers; ii) the current set of gaps to provide solutions to end users; and iii) RD priorities to enable delivery on the business drivers. The meetings were topical across manufacturing, healthcare/medical robotics, service robotics, defense, and space. The workshops took place during the second half of 2012. At each workshop, there was a mixture present of industry users, academic researchers, and government program managers to ensure a broader coverage of the topics discussed. Robotics is one of a few technologies capable of near term building new companies, creating new jobs, and addressing a number of issues of national importance. Mailing list and group: http://robotics-worldwide.1046236.n5.nabble.com/ http://www.linkedin.com/groups/Cloud-Robotics-6922112 http://groups.google.com/forum/#!forum/cloud-robotics-list Literature tracking: Cloud robotics on Wikipedia ,Ruijiao Li, December 2014 Cloud Robotics and Automation A special issue of the IEEE Transactions on Automation Science and Engineering. Robots with Their Heads in the Clouds. Medium.com, from Aspen Ideas Festival Talk. Posted Aug 2014. New Research Center Aims to Develop Second Generation of Surgical Robots. John Markoff, NY Times, Oct, 2014 The Robot in the Cloud: A Conversation With Ken Goldberg. Quentin Hardy, NY Times, Oct, 2014 RoboBrain marks the dawn of cloud robotics . August 2014 The RoboBrain Project. August 2014. CoTeSys (Cognition for Technical Systems) TUM, DLR, LMU 2012-~2014 . Innovations in Cloud Robotics (Technical Insights) , Industrial report. June 2014 Cloud Robotics. The Atlantic, by Megan Garber. June 2014. DARPA on Cloud Robotics. April 2014. Big Push in Robotics Now Seems Imminent. The Economist. 29 March 2014. (Cloud Robotics discussed in last section). Robot Roundup. NPR Science Friday by Jordan Davidson. 26 March 2014. (Cloud Robotics discussed in last section) Open Call for References for new Survey Paper on Cloud Robotics and Automation. Moments that Stood out at SXSW: Panel on Cloud Robotics and Automation. Wall Street Journal, 11 March 2014. Panel on Cloud Robotics and Automation with James Kuffner of Google, Ayorkor Korsah of Ashesi Univ in Ghana, and Ken Goldberg, UC Berkeley. SXSW. Austin, TX, US. Mar 9, 2014. A Roadmap for U.S. Robotics From Internet to Robotics Cloud-based human activity monitoring. C hristian I. Penaloza etc. 2013 Robot Reinforcement Learning using Crowdsourced Rewards . C hristian I. Penaloza, Sonia Chernova, Yasushi Mae and Tatsuo Arai. November 2013. IROS Workshop on Cloud Robotics. Tokyo. November 2013. Cloud Robotics in Why We Love Robots. Short Documentary Film including section on Cloud Robotics. (Nominated for Emmy Award and winner of Botscar Award at Robot Film Festival), Oct 2013. CASE 2013 Workshop on Cloud Manufacturing and Automation. Aug 2013. Cloud-Based Robot Mapping. June 2013. Vlad Usenko, Markus Waibel, Mohanarajah Gajamohan, Dominique Hunziker, Dhananjay Sathe, Mayank Singh. Cloud-Based Robot Grasping with the Google Object Recognition Engine. Ben Kehoe, Akihiro Matsukawa, Sal Candido, James Kuffner, and Ken Goldberg. IEEE International Conference on Robotics and Automation. Karlsruhe, Germany. May 2013. US National Science Foundation Workshop on Cloud Robotics: Challenges and Opportunities, Feb 2013. Cloud Robotics and Automation: A Survey of Related Work. K. Goldberg and B. Kehoe. EECS Department, University of California, Berkeley, Technical Report UCB/EECS-2013-5. January 2013. Robot-App Store. Romo: $150 cloud-enabled robot from Romotive. Towards Cloud Robotic System: A Case Study of Online Co-localization for Fair Resource Competence . Lujia Wang, Ming Liu, Max Q.-H, Meng. IEEE International Conference on Robotics and Biomimetics (ROBIO) 2012 USD 10 Robot Design Challenge Winners. Results of an open design competition for an affordable robot for K-12 education, 2012. Organized by the African Robotics Network. Toward Cloud-Based Grasping with Uncertainty in Shape: Estimating Lower Bounds on Achieving Force Closure with Zero-Slip Push Grasps. Ben Kehoe, Dmitry Berenson, Ken Goldberg. IEEE International Conference on Robotics and Automation. May 2012. Cloud Robotics: Connected to the Cloud, Robots Get Smarter Erico Guizzo. IEEE Spectrum. 2011. In June 2011, President Obama announced the U.S. National Robotics Initiative, earmarking over $70M for new research. CloudRobotics.com: ROS in Java for Robots using Android phones and tablets by Damon Kohler (Google Munich), 2011. RoboEarth - A World Wide Web for Robots Markus Waibel, Raffaello D'Andrea et al. , ETHZ, TUM, TU/e, 2011. Willow Garage and Google announce ROS Java Library for Cloud Robotics, 2011. Cloud-Enabled Humanoid Robots , James J. Kuffner. IEEE-RAS International Conference on Humanoid Robotics. 2010.
Cloud Computing, which is a new type of computing model, although doesn’t have a long history, is being developed and promoted by megascale IT companies as Google, Apple, IBM, Microsoft and various institutions at a tremendous pace. As a new kind of technology being shaped, the development and standardization of Cloud Computing has caused broad attention and debate among academia, business world, as well as government. How do we understand the heart of the debate? Traditional technology determinism presumes that as a result of research, the development of technology itself follows a predictable, traceable path largely beyond cultural and political influence. But take a look at the issue of Cloud Computing, apart from technical difficulties, many problems lie in social dimension surrounding the concept of Cloud Computing. The concept of “Cloud Computing” is somehow obscure to users. For example, according to Google, Could Computing is an online data storage platform and telecommuting infrastructure displayed in the form of webpages. But when it comes to Apple, “cloud” becomes invisible to users. By creating an account, documents and files are synchronized unconsciously among devices as iPhone, iPad and Mac. In other cases, it means a certain kind of online document-sharing applications like “Dropbox”, etc. Almost all of these main promoters of cloud computing have their unique understanding of this technology under their own perspective. The process of standardization directly points to the profit of the companies. Besides, State policy and administration might be involved as well. Early during the birth of the Internet, the internet society demonstrated a character of decentralizing. With the development of new internet technology, users come to realize that although the information and communication power is still widely separated by individual units, the data itself show a trend of centralizing, large amount of data are stored in the server (you can also say cloud). Francis Bacon has a famous saying that “Knowledge is power”. In the era of “big data”, the centralizing of data enhances the systemization of the whole society. We can conclude that those who commands data also holds power. New technology is serving not merely as tools, but rather public utilities and infrastructure of the society. The relationship between technology and society cannot be reduced to a simplistic cause-and-effect formula, which is new forms of technology are created in the labs, and then it comes to market and influence the society. It is rather an intertwining. In many cases, the leading force of technology development might no longer be merely researchers; Users, companies and even the state all take part in the formation of new technology, thus rises an important question, to whom should we give the right of leading the development of a new technology? We should not neglect the political value imbedded in the formation of new technology. This may lead to the new perspective in technology and innovation management to acquire the dynamic balance in future relationship between technology and society.
1 、大数据、云计算与科研数据 ² 什么是大数据? n 引发大数据热的几个因素(技术成熟、应用推动) n 大数据的特征( 4V 论 VS 周涛论) ² 大数据与云计算的关系 n 一个硬币的两面 n 大数据与云计算的“惺惺相惜” ² 大数据对科研范式的影响 n 微软的预言:第四范式 n 数据密集型科学的三个基本活动 n 大数据与科研数据关系 n 科研数据的困惑 2 、科研数据共享服务实践与挑战 ² 科研数据共享的意义 ² 科研数据共享的价值所在 ² 数据堂的科研数据共享实践 n 科研数据云计算 n 科研机构数据专区 n 科研数据直通车 n 数据挖掘竞赛 3 、科研数据 / 研发数据的处理应用 ² 大数据应用跑到了科研前面 ² 大数据处理一般流程 ² 科研数据处理应用案例 n 图片、视频、语音、文本等非结构化数据的处理 n 应用场景及学科相关 4 、结语 ² 大数据生态环境 ² 不仅仅是进化 报告于2013年3月25日中国科学院国家科学图书馆智慧信息中心
无意间发现了一个好东西, 想了解学习云计算的朋友可以看看。 Reading list Datacenters form the backbone of cloud-based systems. Barroso et al. introduced the Google search system, which provides a good starting point for understanding Internet-scale systems and datacenters: Luiz Barroso, Jeffrey Dean, Urs Hoelzle. Web Search for a Planet: The Google Cluster Architecture. IEEE Micro, Vol. 23, No. 2, pp. 22-28, Mar./Apr. 2003. http://baijia.info/showthread.php?tid=133 The datacenter software builds on techniques in distributed computing. Among these techniques, Paxos plays an important role in many core services in cloud systems. The following papers describe Paxos and a few systems using it: Lamport, L. The part-time parliament. ACM Trans. Comput. Syst. 16, 2 (May. 1998), 133-169. http://baijia.info/showthread.php?tid=188 L. Lamport. Paxos made simple. ACM SIGACT News, 32(4:(18-25, 2001. http://baijia.info/showthread.php?tid=414 Burrows, M. The Chubby lock service for loosely-coupled distributed systems. In Proceedings of the 7th Symposium on Operating Systems Design and Implementation (Seattle, Washington, November 06 - 08, 2006). 335-350. http://baijia.info/showthread.php?tid=59 The MapReduce framework is a pioneer of large-scale data-intensive computing in datacenters: Dean, J. and Ghemawat, S. 2004. MapReduce: simplified data processing on large clusters. In Proceedings of the 6th Conference on Symposium on Opearting Systems Design Implementation - Volume 6 (San Francisco, CA, December 06 - 08, 2004). http://baijia.info/showthread.php?tid=2 Our recent development, DVM, shows an efficient way to extend instruction-level virtualization to a large number of physical hosts, and can potentially provide an abstraction of a "single computer" for a datacenter: Zhiqiang Ma, Zhonghua Sheng, Lin Gu, Liufei Wen and Gong Zhang. DVM: Towards a Datacenter-Scale Virtual Machine. In Proc. of ACM VEE'12, London, UK, Mar. 3-4, 2012. http://baijia.info/showthread.php?tid=1114 The foundation of a series of recent large-scale file systems in datacenters is the GFS system, which provides a systematic solution to scalability, consistency, and software fault tolerance: Ghemawat, S., Gobioff, H., and Leung, S. The Google file system. In Proceedings of the Nineteenth ACM Symposium on Operating Systems Principles (SOSP'03), Bolton Landing, NY, USA, October 19 - 22, 2003. 29-43. http://baijia.info/showthread.php?tid=1 Above the file system abstraction, researchers have constructed key value stores and databases. Often not supporting the full ACID semantics, the database design is often referred to as a NoSQL database. DeCandia, G., Hastorun, D., Jampani, M., Kakulapati, G., Lakshman, A., Pilchin, A., Sivasubramanian, S., Vosshall, P., and Vogels, W. 2007. Dynamo: amazon's highly available key-value store. In Proceedings of Twenty-First ACM SIGOPS Symposium on Operating Systems Principles (Stevenson, Washington, USA, October 14 - 17, 2007). SOSP '07. ACM, New York, NY, 205-220. http://baijia.info/showthread.php?tid=120 Chang, F., Dean, J., Ghemawat, S., Hsieh, W. C., Wallach, D. A., Burrows, M., Chandra, T., Fikes, A., and Gruber, R. E. Bigtable: a distributed storage system for structured data. In Proceedings of the 7th Symposium on Operating Systems Design and Implementation (Seattle, Washington, November 06 - 08, 2006). 205-218. http://baijia.info/showthread.php?tid=4 As the technology evolves, it becomes clear that reasonably strong semantics cannot be entirely ignored. While it is relatively easy to provide atomicity on single records, it is a tremendous technical challenge to support distributed transactions in high throughput, at affordable cost and in a large distributed system. Recent systems have made certain progress in this direction. Megastore: Providing Scalable, Highly Available Storage for Interactive Services, Jason Baker, Chris Bond, James C. Corbett, JJ Furman, Andrey Khorlin, James Larson, Jean-Michel Leon, Yawei Li, Alexander Lloyd, Vadim Yushprakh, Proceedings of the Conference on Innovative Data system Research (CIDR), 2011, pp. 223-234. http://baijia.info/showthread.php?tid=805 An earlier system, PNUTS, showcases another design with several similar goals. Cooper, B. F., Ramakrishnan, R., Srivastava, U., Silberstein, A., Bohannon, P., Jacobsen, H., Puz, N., Weaver, D., and Yerneni, R. PNUTS: Yahoo!'s hosted data serving platform. Proc. VLDB Endow. 1, 2 (Aug. 2008), 1277-1288. http://baijia.info/showthread.php?tid=126
研究云计算与大数据分析处理领域建议看的学术论文列表 (2011-10-07 21:10:59) var $tag='杂谈'; var $tag_code='4dec86f4688bfa6a9c3675ce2bfe749a'; var $r_quote_bligid='46d817650100urjq'; var $worldcup='0'; var $worldcupball='0'; 标签: 杂谈 Zhou AY. Data intensive computing-challenges of data management techniques. Communications of CCF, 2009,5(7):50.53 (in Chinese with English abstract). Cohen J, Dolan B, Dunlap M, Hellerstein JM, Welton C. MAD skills: New analysis practices for big data. PVLDB, 2009,2(2): 1481.1492. Schroeder B, Gibson GA. Understanding failures in petascale computers. Journal of Physics: Conf. Series, 2007,78(1):1.11. Dean J, Ghemawat S. MapReduce: Simplified data processing on large clusters. In: Brewer E, Chen P, eds. Proc. of the OSDI. California: USENIX Association, 2004. 137.150. Pavlo A, Paulson E, Rasin A, Abadi DJ, Dewitt DJ, Madden S, Stonebraker M. A comparison of approaches to large-scale data analysis. In: Cetintemel U, Zdonik SB, Kossmann D, Tatbul N, eds. Proc. of the SIGMOD. Rhode Island: ACM Press, 2009. 165.178. Chu CT, Kim SK, Lin YA, Yu YY, Bradski G, Ng AY, Olukotun K. Map-Reduce for machine learning on multicore. In: Scholkopf B, Platt JC, Hoffman T, eds. Proc. of the NIPS. Vancouver: MIT Press, 2006. 281.288. Wang CK, Wang JM, Lin XM, Wang W, Wang HX, Li HS, Tian WP, Xu J, Li R. MapDupReducer: Detecting near duplicates over massive datasets. In: Elmagarmid AK, Agrawal D, eds. Proc. of the SIGMOD. Indiana: ACM Press, 2010. 1119.1122. Liu C, Guo F, Faloutsos C. BBM: Bayesian browsing model from petabyte-scale data. In: Elder JF IV, Fogelman-Soulié F, Flach PA, Zaki MJ, eds. Proc. of the KDD. Paris: ACM Press, 2009. 537.546. Panda B, Herbach JS, Basu S, Bayardo RJ. PLANET: Massively parallel learning of tree ensembles with MapReduce. PVLDB, 2009,2(2):1426.1437. Lin J, Schatz M. Design patterns for efficient graph algorithms in MapReduce. In: Rao B, Krishnapuram B, Tomkins A, Yang Q, eds. Proc. of the KDD. Washington: ACM Press, 2010. 78.85. Zhang CJ, Ma Q, Wang XL, Zhou AY. Distributed SLCA-based XML keyword search by Map-Reduce. In: Yoshikawa M, Meng XF, Yumoto T, Ma Q, Sun LF, Watanabe C, eds. Proc. of the DASFAA. Tsukuba: Springer-Verlag, 2010. 386.397. Stupar A, Michel S, Schenkel R. RankReduce—Processing K-nearest neighbor queries on top of MapReduce. In: Crestani F, Marchand-Maillet S, Chen HH, Efthimiadis EN, Savoy J, eds. Proc. of the SIGIR. Geneva: ACM Press, 2010. 13.18. Wang GZ, Salles MV, Sowell B, Wang X, Cao T, Demers A, Gehrke J, White W. Behavioral simulations in MapReduce. PVLDB, 2010,3(1-2):952.963. Gunarathne T, Wu TL, Qiu J, Fox G. Cloud computing paradigms for pleasingly parallel biomedical applications. In: Hariri S, Keahey K, eds. Proc. of the HPDC. Chicago: ACM Press, 2010. 460−469. Delmerico JA, Byrnesy NA, Brunoz AE, Jonesz MD, Galloz SM, Chaudhary V. Comparing the performance of clusters, hadoop, and active disks on microarray correlation computations. In: Yang YY, Parashar M, Muralidhar R, Prasanna VK, eds. Proc. of the HiPC. Kochi: IEEE Press, 2009. 378−387. Das S, Sismanis Y, Beyer KS, Gemulla R, Haas PJ, McPherson J. Ricardo: Integrating R and hadoop. In: Elmagarmid AK, Agrawal D, eds. Proc. of the SIGMOD. Indiana: ACM Press, 2010. 987−998. Wegener D, Mock M, Adranale D, Wrobel S. Toolkit-Based high-performance data mining of large data on MapReduce clusters. In: Saygin Y, Yu JX, Kargupta H, Wang W, Ranka S, Yu PS, Wu XD, eds. Proc. of the ICDM Workshop. Washington: IEEE Computer Society, 2009. 296−301. Kovoor G, Singer J, Lujan M. Building a Java Map-Reduce framework for multi-core architectures. In: Ayguade E, Gioiosa R, Stenstrom P, Unsal O, eds. Proc. of the HiPEAC. Pisa: HiPEAC Endowment, 2010. 87−98. De Kruijf M, Sankaralingam K. MapReduce for the cell broadband engine architecture. IBM Journal of Research and Development, 2009,53(5):1−12. Becerra Y, Beltran V, Carrera D, Gonzalez M, Torres J, Ayguade E. Speeding up distributed MapReduce applications using hardware accelerators. In: Barolli L, Feng WC, eds. Proc. of the ICPP. Vienna: IEEE Computer Society, 2009. 42−49. Ranger C, Raghuraman R, Penmetsa A, Bradski G, Kozyrakis C. Evaluating MapReduce for multi-core and multiprocessor systems. In: Dally WJ, ed. Proc. of the HPCA. Phoenix: IEEE Computer Society, 2007. 13−24. Ma WJ, Agrawal G. A translation system for enabling data mining applications on GPUs. In: Zhou P, ed. Proc. of the Supercomputing (SC). New York: ACM Press, 2009. 400−409. He BS, Fang WB, Govindaraju NK, Luo Q, Wang TY. Mars: A MapReduce framework on graphics processors. In: Moshovos A, Tarditi D, Olukotun K, eds. Proc. of the PACT. Ontario: ACM Press, 2008. 260−269. Stuart JA, Chen CK, Ma KL, Owens JD. Multi-GPU volume rendering using MapReduce. In: Hariri S, Keahey K, eds. Proc. of the MapReduce Workshop (HPDC 2010). New York: ACM Press, 2010. 841−848. Hong CT, Chen DH, Chen WG, Zheng WM, Lin HB. MapCG: Writing parallel program portable between CPU and GPU. In: Salapura V, Gschwind M, Knoop J, eds. Proc. of the PACT. Vienna: ACM Press, 2010. 217−226. Jiang W, Ravi VT, Agrawal G. A Map-Reduce system with an alternate API for multi-core environments. In: Chiba T, ed. Proc. of the CCGRID. Melbourne: IEEE Press, 2010. 84−93. Liao HJ, Han JZ, Fang JY. Multi-Dimensional index on hadoop distributed file system. In: Xu ZW, ed. Proc. of the Networking, Architecture, and Storage (NAS). Macau: IEEE Computer Society, 2010. 240−249. Zou YQ, Liu J, Wang SC, Zha L, Xu ZW. CCIndex: A complemental clustering index on distributed ordered tables for multi- dimensional range queries. In: Ding C, Shao ZY, Zheng R, eds. Proc. of the NPC. Zhengzhou: Springer-Verlag, 2010. 247−261. Zhang SB, Han JZ, Liu ZY, Wang K, Feng SZ. Accelerating MapReduce with distributed memory cache. In: Huang XX, ed. Proc. of the ICPADS. Shenzhen: IEEE Press, 2009. 472−478. Dittrich J, Quian′e-Ruiz JA, Jindal A, Kargin Y, Setty V, Schad J. Hadoop++: Making a yellow elephant run like a cheetah (without it even noticing). PVLDB, 2010,3(1-2):518−529. Chen ST. Cheetah: A high performance, custom data warehouse on top of MapReduce. PVLDB, 2010,3(1-2):1459−1468. Iu MY, Zwaenepoel W. HadoopToSQL: A MapReduce query optimizer. In: Morin C, Muller G, eds. Proc. of the EuroSys. Paris: ACM Press, 2010. 251−264. Blanas S, Patel JM, Ercegovac V, Rao J, Shekita EJ, Tian YY. A comparison of join algorithms for log processing in MapReduce. In: Elmagarmid AK, Agrawal D, eds. Proc. of the SIGMOD. Indiana: ACM Press, 2010. 975−986. Zhou MQ, Zhang R, Zeng DD, Qian WN, Zhou AY. Join optimization in the MapReduce environment for column-wise data store. In: Fang YF, Huang ZX, eds. Proc. of the SKG. Ningbo: EEE Computer Society, 2010. 97−104. Afrati FN, Ullman JD. Optimizing joins in a Map-Reduce environment. In: Manolescu I, Spaccapietra S, Teubner J, Kitsuregawa M, Léger A, Naumann F, Ailamaki A, Ozcan F, eds. Proc. of the EDBT. Lausanne: ACM Press, 2010. 99−110. Sandholm T, Lai K. MapReduce optimization using regulated dynamic prioritization. In: Douceur JR, Greenberg AG, Bonald T, Nieh J, eds. Proc. of the SIGMETRICS. Seattle: ACM Press, 2009. 299.310. Hoefler T, Lumsdaine A, Dongarra J. Towards efficient MapReduce using MPI. In: Oster P, ed. Proc. of the EuroPVM/MPI. Berlin: Springer-Verlag, 2009. 240.249. Nykiel T, Potamias M, Mishra C, Kollios G, Koudas N. MRShare: Sharing across multiple queries in MapReduce. PVLDB, 2010, 3(1-2):494.505. Kambatla K, Rapolu N, Jagannathan S, Grama A. Asynchronous algorithms in MapReduce. In: Moreira JE, Matsuoka S, Pakin S, Cortes T, eds. Proc. of the CLUSTER. Crete: IEEE Press, 2010. 245.254. Polo J, Carrera D, Becerra Y, Torres J, Ayguade E, Steinder M, Whalley I. Performance-Driven task co-scheduling for MapReduce environments. In: Tonouchi T, Kim MS, eds. Proc. of the IEEE Network Operations and Management Symp. (NOMS). Osaka: IEEE Press, 2010. 373.380. Zaharia M, Konwinski A, Joseph AD, Katz R, Stoica I. Improving MapReduce performance in heterogeneous environments. In: Draves R, van Renesse R, eds. Proc. of the ODSI. Berkeley: USENIX Association, 2008. 29.42. Xie J, Yin S, Ruan XJ, Ding ZY, Tian Y, Majors J, Manzanares A, Qin X. Improving MapReduce performance through data placement in heterogeneous hadoop clusters. In: Taufer M, Rünger G, Du ZH, eds. Proc. of the Workshop on Heterogeneity in Computing (IPDPS 2010). Atlanta: IEEE Press, 2010. 1.9. Polo J, Carrera D, Becerra Y, Beltran V, Torres J, Ayguade E. Performance management of accelerated MapReduce workloads in heterogeneous clusters. In: Qin F, Barolli L, Cho SY, eds. Proc. of the ICPP. San Diego: IEEE Press, 2010. 653.662. Papagiannis A, Nikolopoulos DS. Rearchitecting MapReduce for heterogeneous multicore processors with explicitly managed memories. In: Qin F, Barolli L, Cho SY, eds. Proc. of the ICPP. San Diego: IEEE Press, 2010. 121.130. Jiang DW, Ooi BC, Shi L, Wu S. The performance of MapReduce: An in-depth study. PVLDB, 2010,3(1-2):472.483. Berthold J, Dieterle M, Loogen R. Implementing parallel Google Map-Reduce in Eden. In: Sips HJ, Epema DHJ, Lin HX, eds. Proc. of the Euro-Par. Delft: Springer-Verlag, 2009. 990.1002. Verma A, Zea N, Cho B, Gupta I, Campbell RH. Breaking the MapReduce stage barrier. In: Moreira JE, Matsuoka S, Pakin S, Cortes T, eds. Proc. of the CLUSTER. Crete: IEEE Press, 2010. 235.244. Yang HC, Dasdan A, Hsiao RL, Parker DS. Map-Reduce-Merge simplified relational data processing on large clusters. In: Chan CY, Ooi BC, Zhou AY, eds. Proc. of the SIGMOD. Beijing: ACM Press, 2007. 1029.1040. Seo SW, Jang I, Woo KC, Kim I, Kim JS, Maeng S. HPMR: Prefetching and pre-shuffling in shared MapReduce computation environment. In: Rana O, Tang FL, Kosar T, eds. Proc. of the CLUSTER. New Orleans: IEEE Press, 2009. 1.8. Babu S. Towards automatic optimization of MapReduce programs. In: Kansal A, ed. Proc. of the ACM Symp. on Cloud Computing (SoCC). New York: ACM Press, 2010. 137.142. Olston C, Reed B, Srivastava U, Kumar R, Tomkins A. Pig Latin: A not-so-foreign language for data processing. In: Wang JTL, ed. Proc. of the SIGMOD. Vancouver: ACM Press, 2008. 1099.1110. Isard M, Budiu M, Yu Y, Birrell A, Fetterly D. Dryad: Distributed data-parallel programs from sequential building blocks. ACM SIGOPS Operating Systems Review, 2007,41(3):59.72. Isard M, Yu Y. Distributed data-parallel computing using a high-level programming language. In: Cetintemel U, Zdonik SB, Kossmann D, Tatbul N, eds. Proc. of the SIGMOD. Rhode Island: ACM Press, 2009. 987.994. Chaiken R, Jenkins B, Larson P, Ramsey B, Shakib D, Weaver S, Zhou JR. SCOPE: Easy and efficient parallel processing of massive data sets. PVLDB, 2008,1(2):1265.1276. Condie T, Conway N, Alvaro P, Hellerstein JM, Gerth J, Talbot J, Elmeleegy K, Sears R. Online aggregation and continuous query support in MapReduce. In: Elmagarmid AK, Agrawal D, eds. Proc. of the SIGMOD. Indianapolis: ACM Press, 2010. 1115.1118. Thusoo A, Sarma JS, Jain N, Shao Z, Chakka P, Anthony S, Liu H, Wyckoff P, Murthy R. Hive a warehousing solution over a MapReduce framework. PVLDB, 2009,2(2):938.941. Ghoting A, Pednault E. Hadoop-ML: An infrastructure for the rapid implementation of parallel reusable analytics. In: Culotta A, ed. Proc. of the Large-Scale Machine Learning: Parallelism and Massive Datasets Workshop (NIPS 2009). Vancouver: MIT Press, 2009. 6. Yang C, Yen C, Tan C, Madden S. Osprey: Implementing MapReduce-style fault tolerance in a shared-nothing distributed database. In: Li FF, Moro MM, Ghandeharizadeh S, Haritsa JR, Weikum G, Carey MJ, Casati F, Chang EY, Manolescu I, Mehrotra S, Dayal U, Tsotras VJ, eds. Proc. of the ICDE. Long Beach: IEEE Press, 2010. 657.668. Abouzeid A, Bajda-Pawlikowski K, Abadi D, Silberschatz A, Rasin A. HadoopDB: An architectural hybrid of MapReduce and DBMS technologes for analytical workloads. PVLDB, 2009,2(1):922.933. Abouzied A, Bajda-Pawlikowski K, Huang JW, Abadi DJ, Silberschatz A. HadoopDB in action: Building real world applications. In: Elmagarmid AK, Agrawal D, eds. Proc. of the SIGMOD. Indiana: ACM Press, 2010. 1111.1114. Friedman E, Pawlowski P, Cieslewicz J. SQL/MapReduce: A practical approach to self describing, polymorphic, and parallelizable user defined functions. PVLDB, 2009,2(2):1402.1413. Stonebraker M, Abadi D, DeWitt DJ, Maden S, Paulson E, Pavlo A, Rasin A. MapReduce and parallel DBMSs: Friends or foes? Communications of the ACM, 2010,53(1):64.71. Dean J, Ghemawat S. MapReduce: A flexible data processing tool. Communications of ACM, 2010,53(1):72.77. Xu Y, Kostamaa P, Gao LK. Integrating hadoop and parallel DBMS. In: Elmagarmid AK, Agrawal D, eds. Proc. of the SIGMOD. Indianapolis: ACM Press, 2010. 969.974. Thusoo A, Shao Z, Anthony S, Borthakur D, Jain N, Sarma JS, Murthy R, Liu H. Data warehousing and analytics infrastructure at facebook. In: Elmagarmid AK, Agrawal D, eds. Proc. of the SIGMOD. Indianapolis: ACM Press, 2010. 1013.1020. Mcnabb AW, Monson CK, Seppi KD. MRPSO: MapReduce particle swarm optimization. In: Ryan C, Keijzer M, eds. Proc. of the GECCO. Atlanta: ACM Press, 2007. 177.185. Kang U, Tsourakakis CE, Faloutsos C. PEGASUS: A peta-scale graph mining system—Implementation and observations. In: Wang W, Kargupta H, Ranka S, Yu PS, Wu XD, eds. Proc. of the ICDM. Miami: IEEE Computer Society, 2009. 229.238. Kang S, Bader DA. Large scale complex network analysis using the hybrid combination of a MapReduce cluster and a highly multithreaded system. In: Taufer M, Rünger G, Du ZH, eds. Proc. of the Workshops and Phd Forum (IPDPS 2010). Atlanta: IEEE Presss, 2010. 11.19. Logothetis D, Yocum K. AdHoc data processing in the cloud. PVLDB, 2008,1(1):1472.1475. Olston C, Bortnikov E, Elmeleegy K, Junqueira F, Reed B. Interactive analysis of WebScale data. In: DeWitt D, ed. Proc. of the CIDR. Asilomar: Online www.crdrdb.org , 2009. Bose JH, Andrzejak A, Hogqvist M. Beyond online aggregation: Parallel and incremental data mining with online Map-Reduce. In: Tanaka K, Zhou XF, Zhang M, Jatowt A, eds. Proc. of the Workshop on Massive Data Analytics on the Cloud (WWW 2010). Raleigh: ACM Press, 2010. 3. Kumar V, Andrade H, Gedik B, Wu KL. DEDUCE: At the intersection of MapReduce and stream processing. In: Manolescu I, Spaccapietra S, Teubner J, Kitsuregawa M, Léger A, Naumann F, Ailamaki A, Ozcan F, eds. Proc. of the EDBT. Lausanne: ACM Press, 2010. 657.662. Abramson D, Dinh MN, Kurniawan D, Moench B, DeRose L. Data centric highly parallel debugging. In: Hariri S, Keahey K, eds. Proc. of the HPDC. Chicago: ACM Press, 2010. 119.129. Morton K, Friesen A, Balazinska M, Grossman D. Estimating the progress of MapReduce pipelines. In: Li FF, Moro MM, Ghandeharizadeh S, et al., eds. Proc. of the ICDE. Long Beach: IEEE Press, 2010. 681.684. Morton K, Balazinska M, Grossman D. ParaTimer: A progress indicator for MapReduce DAGs. In: Elmagarmid AK, Agrawal D, eds. Proc. of the SIGMOD. Indianapolis: ACM Press, 2010. 507.518. Lang W, Patel JM. Energy management for MapReduce clusters. PVLDB, 2010,3(1-2):129.139. Wieder A, Bhatotia P, Post A, Rodrigues R. Brief announcement: Modeling MapReduce for optimal execution in the cloud. In: Richa AW, Guerraoui R, eds. Proc. of the PODC. Zurich: ACM Press, 2010. 408.409. Zheng Q. Improving MapReduce fault tolerance in the cloud. In: Taufer M, Rünger G, Du ZH, eds. Proc. of the Workshops and Phd Forum (IPDPS 2010). Atlanta: IEEE Presss, 2010. 1.6. Groot S. Jumbo: Beyond MapReduce for workload balancing. In: Mylopoulos J, Zhou LZ, Zhou XF, eds. Proc. of the PhD Workshop (VLDB 2010). Singapore: VLDB Endowment, 2010. 7.12. Chatziantoniou D, Tzortzakakis E. ASSET queries: A declarative alternative to MapReduce. SIGMOD Record, 2009,38(2):35.41. Bu YY, Howe B, Balazinska M, Ernst MD. HaLoop: Efficient iterative data processing on large clusters. PVLDB, 2010,3(1-2): 285−296. Wang HJ, Qin XP, Zhang YS, Wang S, Wang ZW. LinearDB: A relational approach to make data warehouse scale like MapReduce. In: Yu JX, Kim MH, Unland R, eds. Proc. of the DASFAA. Hong Kong: Springer-Verlag, 2011. 306−320.
2012 IEEE World Congress on Services 在夏威夷檀香山(Honolulu)召开,共有5个主题会议,除了名声已经鹊起的 ICWS , SCC , Cloud 之外,今年又新增了两个主题会议: International Conference on Mobile Services (MS 2012) 和 International Conference on Services Economics (SE 2012 ) 。今年有4篇文章(包括合作的)被该系列会议录用为research track论文,运气还算不错,其中国内实验室论文3篇,美国这边实验室论文1篇。根据晚宴时的人数推算,参会人数约有300多人。国内来参会的约有二三十人,包括北邮的陈俊亮院士和哈工大的徐晓飞教授等。从论文数量,听报告人数和录取比例来看,ICWS和SCC有所降温,而CLOUD更加火爆。其它两个主题会议由于刚刚创立,其势尚未起来。
在网格和云环境下,地理空间信息服务,不管你见,或者不见,她就在那里。 你见,或者不见我, it does't matter if you see me or not, 基础设施就在那里 , infrastructure is standing right there, 不悲不喜; with no emotion; 你念,或者不念我, it doesn't matter if you miss me or not, 平台就在那里, the Platform is right there, 不来不去; and it isn't going anywhere 你爱,或者不爱我, it doesn't matter if you love me or not, 软件就在那里, software is right there, 不增不减; and it is not going to change 你跟,或者不跟我, it doesn't matter if you are with me or not, 我的服务就在你应用里, my service is in your application, 不舍不弃; and i am not going to let go 来我的怀里, let me embrace you, 或者, or, 让我住进你的心里 let me live in your heart eternity 默然 相爱, silence love 寂静 欢喜 calmness joy
1. SCA2012 - The 2nd International Conference on Social Computing and Its Applications, Nov. 1-3, 2012, Xiangtan, Hunan, China. http://kpnm.hnust.cn/confs/sca2012/ 2. CGC 2012 - The 2nd International Conference on Cloud and Green Computing,1-3 Nov. 2012, Xiangtan, Hunan, China. http://kpnm.hnust.cn/confs/cgc2012/ 征稿截止时间为7月13日,优秀论文将推荐到领域重要SCI期刊发表。尽管近年来国际学术会议有点泛滥,但我认为这两个会议是值得领域研究人员参加的,从程序委员会构成和Keynote演讲者的身份可见一般。
COMMAG2011七月号是下一代互联网专刊,没想到综述力作竟然出自剑利之手,剑利出国,终成利剑,就从剑利的大作开始吧。 A Survey of the Research on Future Internet Architectures用排比的手法把所有和下一代互联网研究有关的项目梳理了一遍,对于入门者而言,是个很好的教材。文中以简短的文字介绍了各国耗资巨万投入此领域的原因:在安全、移动性、内容分发等方面涌现出的新情况、新需求已经超出了传统互联网的处理能力,因此,需要另起炉灶,从根本上改变互联网的基本设计理念和原则,改天换地。而实现这一目标需要两方面的基本保证:第一是制定统一的架构和规则,不能各自为战;第二是需要足够真实和规模的测试环境。 至于下一代互联网研究的焦点,剑利列举了五点:内容分发、移动泛在接入、云计算、安全、试验床。我认为这种划分的方式过分关注纵向的块而忽视了横向的条,自主控制作为一种方法论研究已经被关注了多年,很多项目里都涉及到自主控制的思想。从架构和原则上来讲,不谈自主控制很难把这些零散的技术领域捏合起来。 文中列举的项目达数十项之多,如果把这些项目的子项目和孙项目都算上,大概要达到数以百计的规模。但这些项目都有一个致命的弱点,即对现实问题语焉不详,缺少令人信服的数据作为支撑。每个项目都在侃侃而谈新需求与现有技术的冲突,但是,这种冲突到底有多严重,却缺少详尽的案例和数据,或者干脆没有。这不能不让人怀疑这一领域已经进入类似大跃进的阶段,两脚离了地。 对于互联网经典设计原则的辩论,见于下一代互联网研究的初期,双方争论的焦点,不是互联网是否应该革命,而是应该采用何种革命的路径。大部分人坚持应该采用断层路线,坚决破四旧,打到一切牛鬼蛇神,而仅有少部分人认为互联网应该采用渐进模式,小步慢跑,自然生长。互联网的祖师爷DAVID D CLARK并没有参与争论,但他写了一篇对互联网设计原则进行重新审视的文章Rethinking the design of the Internet: The end to end arguments vs. the brave new world,以非常谨慎和严谨的态度对四十年前设立的原则进行了讨论。和那些一味革命的同行不同,CLARK更关注引起变革的原因以及互联网基本设计原则变更之后可能带来的问题:We discuss a set of principles that have guided the design of the Internet, called the end to end arguments, and we conclude that there is a risk that the range of new requirements now emerging could have the consequence of compromising the Internet’s original design principles. Were this to happen, the Internet might lose some of its key features, in particular its ability to support new and unanticipated applications。和那些只见其利,不见其弊的同行相比,CLARK更值得尊敬。 旗帜鲜明地反对CLEAN SLATE路线的代表人物是佐治亚理工的Constantine Dovrolis,他在Future Internet Architecture: Clean-Slate Versus Evolutionary Research一文中,认真探讨了两种演进路线的利弊。不过看的出来,他更倾向于逐步演进的模式。 无论是严谨的CLARK 还是辩证的DOVROLIS,都没有在下一代互联网的狂潮中分到大羹,看起来,在研究领域,有时候离谱和创新也会被简单地划上等号。 CLARK在他的大作中,重申了端到端协议的优势,如此精辟的表述,令我不认翻译: •The complexity of the core network is reduced, which reduces costs and facilitates future upgrades to the network. •Generality in the network increases the chances that a new application can be added without having to change the core of the network. •Applications do not have to depend on the successful implementation and operation of application-specific services in the network, which may increase their reliability. 这些优势其实都来自一个谁都无法回避的问题,即互联网是一个没有统一管理、结构松散而随意、复杂性超乎寻常的庞然大物。按照杰夫、凯尔斯的理论,在应对这样一个复杂不确定环境时,内部控制模型的复杂性应该保持低于外部环境,从而获得不断自适应的可能性。反之则会使看起来很美的复杂控制模型走向死亡。我想只要互联网的本质特性没有发生变化,只要CLARK所强调的优势仍然重要,那么互联网的演进路线就应该是不断修正核心的简单规则,而不是不断向网络中注入复杂的控制模式。 但CLARK的眼界和格局远远超出了技术的层面,他认为,所谓的对互联网基本设计原则以及体系结构的各种改进,事实上是互联网利益相关各方在经济、政治、意识形态这些非技术层面诉求的体现。政府、大运营商、有雄厚资本支撑的投资人希望更多的管理和控制,并倾向于大跃进式的创新模式,而端到端原则体现的是自由开放精神,允许各色人等以小步快跑模式进行多样化创新。在互联网草创之时,互联网的参与者成分单一,并且相互之间信任度很高,因此端到端原则所秉承的思想就是任何人都可以自由地和任何人沟通。但现在互联网的复杂性已经远远超过了40年前,信任、安全都成为大问题,而政府和大财团的介入这让情势变得更为复杂。 CLARK列举了当前互联网中已经采用的一些和端到端原则相悖的技术,他并不评价这些技术时候合理,但仍然道出了自己的隐忧。他认为这些技术和服务的引入,有可能会对互联网的健康发展造成潜在的危害。为了让这个听起来比较晦涩的观点易于理解,CLARK举了一个网络缓存的例子。网络缓存通过在本地缓存数据减少传输时延,但同时也使用户对缓存备份的依赖性增强,反而有可能削弱运营商提升网络整体能力的意愿。 在文章的最后CLARK委婉地对那些热衷于扮演下一代互联网总设计师角色的家伙泼了一盆冷水。他认为,互联网中各方利益博弈的结果,不可能是赢者通吃,只会是不断地寻求新的平衡点。因此,任何对终极技术形态的预测都过于幼稚。但有一点是毋庸置疑的,那就是由端到端原则衍生出的开放和通用属性,在任何时候都是创新精神得以滋生的必要条件,不应被草率丢弃(This pattern suggests that the balance 1096 of power among the players is not a winner-take-all outcome, but an evolving balance. It 1097 suggests that the outcome is not fixed by specific technical alternatives, but the interplay of the 1098 many features and attributes of this very complex system. And it suggests that it is premature to 1099 predict the final form. What we can do now is push in ways that tend toward certain outcomes. 1100 We argue that the open, general nature of the Net, which derived from the end to end arguments, 1101 is a valuable characteristic that encourages innovation, and this flexibility should be preserved.)。 CLARK一生著述不多,远远谈不上著作等身,但CLARK所创立的端到端原则,为互联网的发展奠定了基石。看过CLARK的这篇文章,我终于理解CLARK在四十年前的远见卓识绝非偶然,他对于人类社会以及人性的深刻理解,远远超出了科学家或工程技术人员的层面。任何人与成功之间的距离,即他与社会的距离,此言不虚。 看过CLARK的文章,在去读那些在技术层面纠缠的论文,顿时有一览众山小之感。 Constantine Dovrolis在圈子里名气不大,或者说根本没什么名气,但他和我的研究方向一致性最强,而且很有自己的想法,是少有的头脑清醒的科学家。现在这家伙已经当了爹, 但文章还是写得那么好。 Constantine Dovrolis在很多场合表达了他对断层式发展模式的不屑,但最精彩的部分出现在一篇带有争鸣性质的文章中: Future Internet Architecture---Clean-Slate Versus Evolutionary Research。在这篇文章中,Jennifer Rexford和Constantine Dovrolis旗帜鲜明地表达了对断层式发展模式和渐进式发展模式的态度。前者乏善可陈,而后者的论证之严密和精彩,堪比17世纪苏格兰弓弩存废之争。 Jennifer Rexford的观点非常具有代表性,她认为互联网到目前为止都没有什么通用的自顶向下设计法则或普适的经验,完全是一堆杂乱无章的技术和协议的大杂烩,而且问题成堆,漏洞百出。而断层式的设计则可以摆脱这些混乱的羁绊,轻装上阵,令那些附着在现有体系中的安全、管理、业务等方面的问题迎刃而解。Jennifer Rexford并不否认现有的互联网体系为底层传输技术和上层应用提供了极大地灵活性,但同时也认定这种体系过于僵化和难以改变,因此应该从增加网络的可编程属性入手,允许各种相互独立的体系结构并存。她所说的这个僵硬的ARCHITECHTURE,其实就是TCP/IP。GENI和OPENFLOW再次作为新型体系结构的成功典范被提及,但事实上我完全看不出来OPENFLOW能在体系结构的革命大业中充当旗手或马前卒。在结尾处,Jennifer Rexford满怀激情地写道,既然当年互联网能够成功地将基于电路交换的电话网挤进历史的暗角,为什么我们就不能憧憬互联网被另一个全新的事物扫进故纸堆? Constantine Dovrolis的陈词没有那么多革命的激情,但分析的严密性和逻辑性远非那些鼓吹断层式发展的专家所能及。如果说DAVID D CLARK只是用温婉的语气表达自己对眼下大跃进热潮的忧虑的话,那么Constantine Dovrolis则是针锋相对地展开论战。 首先,Constantine Dovrolis对两种发展模式的差异进行了界定。渐进式路线的特点是在分析互联网现有行为特征以及存在问题的基础上,遵循向后兼容以及累进发展的原则解决问题。而断层式路线的特点则是在不受现有技术体制制约的条件下设计全新和优越的体系结构。Constantine Dovrolis坚信断层式发展不是什么新鲜事物,这东西的历史几乎和互联网一样长,主动网络、XCP、CLNP、NIMROD都曾经耀眼一时,但随即烟消云散。而那些多少带有向后兼容属性却不具备增量部署特性的技术,例如IPV6、RSVP, IntServ, IPsec,S-BGP,到目前为止都没有得到大规模应用。与之形成鲜明对比的是,现实世界采用了大量符合演进特性的技术,例如NAT、入侵检测和DIFFSERVE。之所以出线这些看似不合理的现象,是因为所谓革命性新技术的升级成本太高,以致远远超过了这些技术可能带来的好处,注意,是可能的好处。这句话可谓一语中的。 在后面的章节中,Constantine Dovrolis逐一反驳了断层式发展派所持的观点: 第一,断层式发展派认为GENI这些试验床的部署足以证明他们不是在纸上谈兵,而Constantine Dovrolis则认为早在20年前人们就已经在试验床上对断层式技术进行过实验,问题的关键不在于实验时候充分,而在于新技术所能给现实世界带来的好处以及升级成本永远都不可能在试验床上测试出来。尽管ARPANET也被认为是试验床,但它同时也是一个承载实际应用的运营网络,这一点和GENI有本质的差别。 第二,断层式发展派认为互联网本身就是上世纪6、70年代技术上的一次断代式发展的结果。而Constantine Dovrolis则认为TCP/IP技术完全不是无中生有,而是从同步复用、异步复用、包交换一步步演进发展出来的。而且TCP/IP体系结构也是在逐步发展演进中才击败了众多对手(例如SNA,DECNET)逐步成为主流。这和石头里蹦出个孙猴子完全不是一个概念。 第三,断层式发展派认为互联网体系结构的核心,TCP/IP技术已经僵化不堪,完全不能容纳任何形式的革新。Constantine Dovrolis则认为这种流行的观点完全颠倒是非,纯属扯淡。底层链路技术和上层应用之所以能够衍生出无限的多样性和灵活性,恰恰受益于一个简单、稳定的中间层的存在。在The Evolution of Layered Protocol Stacks Leads to an Hourglass-Shaped Architecture以及Ten Years in the Evolution of the Internet Ecosystem中,Constantine Dovrolis的学生们对这一点进行了更为详细的阐述。 第四,断层式发展派把互联网视为一个可以随意改动的物件,因此视体系结构这等大事如掌中之物。而Constantine Dovrolis则完全认同CLARK的观点,即互联网已经是一个与政治、经济以及亿万用户密不可分的复杂生态系统(详细的论述见于What would Darwin Think about Clean-Slate Architectures),而互联网的发展方向和方式,也绝不是一个简单地技术问题。 如果你觉得阅读文献过于不便,也可以通过幻灯片Four myths about GENI来快速了解Constantine Dovrolis的观点。 作为渐进发展派的支持者,Constantine Dovrolis同时提出了富有建设性的建议。他认为当务之急不是建立所谓的测试床,而是通过建立系统性的监测体系去深入观察和分析现有互联网的行为特征,并在此基础上建立一个带有实验性质的运营网络,通过现实环境检验新技术的可行性。 如果是CLARK,说到这里也就该及时打住了。但Constantine Dovrolis还保持这年轻人的冲劲,宜将剩勇追穷寇,在文章的结尾对断代发展派所津津乐道的所谓网络科学给予了致命的一击。因为断代发展派时常把跳跃式发展和富有哲理的科学混为一谈,并抨击渐进式发展不过是头疼医头脚疼医脚的庸医。对此,Constantine Dovrolis对科学的定义可谓再次集中要害,颇有方舟子之风: A domain of knowledge does not become science because it is based on clean optimization frameworks or because it proves deep results about toy models. Good science requires relevance to the real world, measurements and experimental validation, testable hypotheses, and models with predictive power. Constantine Dovrolis是一个严谨的人,他在阐述自己的论点之后,更进一步提出了一个很多人想问却不敢问的问题:那么多学术领域的泰斗,为什么会像中了魔障一样,不顾客观规律,狂热地追捧空中楼阁一般的所谓新型体系架构? 作为愤青,我的反应是这帮家伙是为了拿到项目经费才做出屁股决定脑袋的行为。但Constantine Dovrolis认为不尽然,除了钱的因素以外,草创新世界的乐趣和成就感或许更具魔力,这魔力之大,足够让一群天才集体做出不理智的行为。能把问题看得如此透彻,正是Constantine Dovrolis的过人之处。 在有关体系结构的激烈争论之外,还有一些比较中立的派别,把关注的焦点放在能够对互联网形态产生深刻影响的技术上,Content, Connectivity, and Cloud---Ingredients for the Network of the Future_COMMAG2011就属于这一类。在这篇文章中,作者认为内容分发、泛在接入以及云计算、虚拟网络是互联网发展过程中具有里程碑意义的三项技术,而这三项技术的现状仍然差强人意。 首先,互联网中内容的分发仍然依赖于内容及其存储位置之间的绑定关系,没有建立起真正面向内容的命名、查询和路由体系。其次,虚拟网络技术仍然不够灵活,对人工干预的依赖性太强。按照作者的理解,真正的虚拟网络应该能够容纳数据、应用、服务,不受运营商管理域以及底层网络技术体制的束缚,能够为用户提供随时随地和个性化的接入服务。而云计算资源应该具有分布特征,便于用户就近接入和使用,而不是像现在这样集中放置在服务提供商的机房里。 上面这张图是文章作者对开放式连接服务的构想。按照这一设想,网络的各个层面,包括虚拟网络,需要为用户和其他层次提供开发和可扩展的全新接口,利用这些接口,将能够更加充分地利用多接入、多路径等多样化的服务以及底层网络的传输服务。这里面渗透了跨层的思想,但核心是对网络资源进行更加充分和灵活的运用。 这篇文章的作者并没有讨论体系结构方面的问题,也没有表达自己的倾向性,其中隐含的意思,是作者认为现有的网络体系结构并不会对新技术的采用形成障碍,虚拟化和云技术只是为新技术提供了一个更大的舞台,而不是以颠覆者的面目出现。 在COMMUNICATIONS MAGAZINE 2011年的三月号上,专门对以内容为中心的网络技术进行了讨论。我认为以内容为中心的网络技术将是驱动互联网发展的火车头,为云计算、虚拟网络等等支撑性技术提供动力,而火车运行的路基,仍然会是TCP/IP技术。
不好意思,很久没来写。争取最近接着写一些我做研究的体会。 这里先贴个广告,帮我自己招2博士后。 Postdoctoral Opportunities in Cloud Computing at NTU We are looking to hire up to 2 self-motivated research fellows, working in the area of cloud computing in the school of computer engineering at Nanyang Technological University, Singapore. Topics of interest include, but not limited to Green Data Center Architecture Media Streaming with Cloud Support Data Analytics in Cloud Cyber Security in Cloud Computing Elastic Computing Model in cloud Duties involve theoretical research and system prototype, in collaboration with top-level universities and centers, such as Carnegie Mellon University, Stanford University, MIT, Bell-Laboratories, China Mobile Research and IBM Research. Applicants for these positions must satisfy the following requirements PhD degree in computer science, computer engineering, electrical engineering or a related discipline Research experience with publications in international conferences and prestigious journals Competency in Linux programming and application development Excellent communication and writing skills The successful candidate will receive a competitive remuneration package commensurate with his/her qualification and experience. The appointment can start any time and will be initially for one year, with possibility for extension up to two additional years. To apply, please submit by email, a letter of application , current Curriculum Vitae , reprints of one to three recent publications, and three references (name, position and email address of referee) before January 31, 2012, to ygwen@ntu.edu.sg . Screening of applicants for this call will be completed by February 15th, 2012, or until the position is filled. We regret that only short-listed candidates will be notified.
November 14, 2011 — Adolescent vaccination coverage is increasing but could be improved, according to a study published online November 14 in Pediatrics . Potential strategies include simultaneously administering all vaccines during checkups, improving clinician counseling and recommendation of vaccines, and increasing parental awareness and acceptance of recommendations from the Advisory Committee on Immunization Practices. During 2005 to 2007, the Advisory Committee on Immunization Practices expanded the recommended vaccination schedule for teenagers aged 13 to 17 years, adding a meningococcal conjugate vaccine (MenACWY), an acellular pertussis vaccine given in combination with the tetanus and diphtheria toxoids (TdaP), and for girls, 3 inoculations with the human papillomavirus vaccine (HPVV). An analysis of data from the provider-verified, random-digit-dial National Immunization Survey–Teen since its inception in 2006 reveals that vaccine administration is on the rise, but is not meeting full coverage potential. " urrent vaccination rates are still below target levels and are lower than levels achieved for vaccines routinely administered to children aged 19 to 35 months," the authors write, noting that Healthy People 2010 goals include achieving 80% coverage for 1 or more doses of TdaP vaccine, 1 or more doses of MenACWY vaccine, and 3 or more doses of HPVV. Between 2006 and 2009, 1 or more doses of TdaP vaccine and 1 or more doses of MenACWY vaccine coverage increased from 11% to 56% and 12% to 54%, respectively. Between 2007 and 2009, 1 or more doses of HPVV vaccine coverage among girls increased from 25% to 44%, with 3 or more doses of HPVV vaccine increasing from 18% to 27% between 2008 and 2009. The proportion of fully vaccinated teenagers increased from 10% in 2006 to 42% in 2009. Because infrequent healthcare visits are a major barrier when vaccinating teenagers, the authors used 2009 data to calculate potential coverage rates, had all recommended agents been administered simultaneously. They found that coverage could have been higher than 80% for the tetanus booster and meningitis shot, and as high as 74% for the first dose of HPVV. Total coverage could have been achieved for 76% of teenagers. The authors note that clinician counseling strongly influences parental acceptance of vaccines, and that providing a weak recommendation or delaying vaccination often signals that the inoculation is not needed or is not important. Top reported reasons for lack of TdaP and MenACWY vaccination included ignorance of the vaccine, lack of clinician recommendation, and a feeling that the vaccine was not necessary. With HPVV, belief in the teenager's lack of sexual activity proved to be an additional factor. Study limitations include the random-digit-dialed nature of the survey, which limits its scope to households with a landline, despite the high number of wireless-only households (25.9%), and potential underestimation of vaccination rates when health records could not be verified by a clinician. 来源: http://www.medscape.com/viewarticle/753511
Contents 1 周涛 个性化推荐的十大挑战 推荐引擎:信息暗海的领航员 Tag-Aware Recommender Systems: A State-of-the-Art Survey 1 周涛 个性化推荐的十大挑战 周涛 CCF通讯 第 8 卷 第 7 期 2012 年 7 月 关键词:个性化推荐 挑站 应用的算法和技术: 推荐项亮和陈义合著的《推荐系统实践》 挑战一:数据稀疏性问题 挑战二:冷启动问题 标签系统(tagging systems) 挑战三:大数据处理与增量计算问题 (latent dirichlet allocation, LDA)算法 挑战四:多样性与精确性的两难困境 挑战五:推荐系统的脆弱性问题 挑战六:用户行为模式的挖掘和利用 挑战七:推荐系统效果评估 图5总结了文献中曾经出现过的几乎所有的推荐系统指标 挑战八:用户界面与用户体验 挑战九:多维数据的交叉利用 网络与网络之间的相互作用 挑战十:社会推荐 个性化推荐的十大挑战.pdf 推荐引擎:信息暗海的领航员 Terry Lau 张韶峰 周 涛 CCF通讯 第 8 卷 第 6 期 2012 年 6 月 关键词:推荐引擎 电子商务 海量数据 1 引言 推荐引擎 - 信息过载 2 系统架构 如图1所示,百分点推荐引擎分为存储层、业务层、算法层和管理层四大功能组件 推荐引擎 信息暗海的领航员.pdf Tag-Aware Recommender Systems: A State-of-the-Art Survey Zi-Ke Zhang(张子柯), Tao Zhou (周涛), and Yi-Cheng Zhang JOURNAL OF COMPUTER SCIENCE AND TECHNOLOGY 26(5): 767{777 Sept. 2011. Abstract In the past decade, Social Tagging Systems have attracted increasing attention from both physical and computer science communities. Besides the underlying structure and dynamics of tagging systems, many efforts have been addressed to unify tagging information to reveal user behaviors and preferences, extract the latent semantic relations among items, make recommendations, and so on. Specifically, this article summarizes recent progress about tag-aware recommender systems, emphasizing on the contributions from three mainstream perspectives and approaches: network-based methods, tensor-based methods, and the topic-based methods. Finally, we outline some other tag-related studies and future challenges of tag-aware recommendation algorithms. Keywords social tagging systems, tag-aware recommendation, network-based/tensor-based/topic-based methods 1 Introduction an information overload: an urgent problem: how to automatically find out the relevant items for us? personalization = recommender system collaborative filtering (CF) obstacles confronted by CF: the sparsity of data reason: (i) the huge number of items are far beyond users' ability to evaluate even a small fraction of them; (ii) users do not incentively wish to rate the purchased/viewed items Q: User profiles vs. personal privacy. A: Attribute-aware method content-based algorithms vs. its limitation: the items contain rich content information that can be automatically extracted out network theory = complex networks. = folksonomy = social tags user-defined tags 2 Overview of Tag-Based Recommender Systems the influence of social tag on recommendation algorithms. -- FolkRank some open issues in tagging systems: (i) singularity vs. plurality: (ii) polysemy vs. synonymy: (iii) different online tagging systems allow users to give different formats of the tags Solutions: -- Firstly, clustering-based methods are proposed to alleviate the word reduction problem. -- Secondly, semantic methods are discussed to use ontology-based algorithms to organize the tags and reveal the semantic relations among them -- Thirdly, dimension reduction and topic-based methods are put forward to discover the latent topics, and graph-based methods are proposed to solve the sparsity problem in large-scale datasets. the orgnization of this paper: -- firstly give the evaluation metrics measured in this survey. -- Secondly we summarize some of the most recent and prominent tag-aware recommendation algorithms, showing and discussing how they make use of the aforementioned representations to address some unresolved issues in recommender systems. three kinds of recommendations in social tagging systems: (i) predicting friends to users; (ii) recommending items to users; (iii) pushing interesting topics (tags) to users. the most challenges in RS: filter irrelevant items for individuals the purpose of this paper: mainly discuss the second case, 3 Tag-Aware Recommendation Models a social tagging network consists of three different kinds of communities: users, items and tags, personomy: an entry set of personalized folksonomy, a full folksonomy can be considered in two ways to be: (i) three sets described by an adjacent matrix (ii) a ternary or hypergraph-based structure: 3.1 Evaluation Metrics each dataset,E: -- the training set -- the testing set 3.1.1 Metrics of Accuracy 1) Ranking Score (RS) 2) The Area under the ROC Curve 3) Recall recall: 3.1.2 Metrics of Diversity 1) Inter Diversity (InterD): measures the differences of different users' recommendation lists, 2) Inner Diversity (InnerD): measures the differences of items within a user's recommendation list 3.2 Network-Based Models mathematical modeling: tag-based network can be viewed as a tripartite graph which consists of three integrated bipartite graphs or a hypergraph. two underlying network-based methods: probability spreading (ProbS) and heat spreading (HeatS) ProbS: -- random walk (RW) in computer science -- mass diffusion (MD) in physics. HeatS: Table 1 shows the corresponding AUC results for three datasets: 3.3 Tensor-Based Models the tensor factorization (TF)-based method a ternary relation Fig.3 shows the illustration of the above two definitions. Y can be represented: The tensor factorization is based on singular value decomposition (SVD): 3.4 Topic-Based Models the core challenge of recommender systems: to estimate the likelihood between users and items. -- latent semantic analysis (LSA) -- the probability latent semantic analysis (PLSA) -- latent dirichlet allocation (LDA) 4 Conclusion and Outlook three aspects: (i) network-based methods; (ii) tensor-based methods; (iii) topic-based methods. 2011JCST-Tag_aware_recommender_systems.pdf
从数据中心到知识中心——优化云计算 邹顺鹏 1,2 ; 邹晓辉 1 北京市海淀区学院路 29 号,中国地质大学(北京) 100083 1 高等教育研究所研究生 2 英语系大学英语任课教师 ; 1 高等教育研究所研究员 本文 旨在 从数据到知识推进云计算。其要点如下:首先,指出当前的云计算,即大规模计算机集群的云计算,实质上是依托数据中心所存储的海量数据而进行的云计算;同时,还进一步指出:那种通过大规模采集海量数据,然后,通过 PageRank 、 MapReduce 乃至 Hadoop 等工具软件,可提高其搜索效率的方式,虽然可行,但是,仍然存在缺陷或不足。从数据到知识,是其进一步发展之必然。本文的意义就在于:探讨从数据到知识的进一步发展过程中存在的两类云计算。 关键词:数据中心;知识中心;云计算 From Data Center to Knowledge Center -- optimization of Cloud Computing Shunpeng, Zou 1, 2 ; Xiaohui, Zou 1, 2 College Road, Haidian District, No. 29, 100 083 1.China University of Geosciences (Beijing), Institute of Higher Education; 2.Sino-US Project qhkjy@yahoo.com.cn 15300239971 This article aims to advance cloud computing from data center to knowledge center. The main points are as follows: Firstly , it points out that the current cloud computing, which is the cloud computing of large-scale computer cluster, is essentially the cloud computing relying on the data center for storage of massive amounts of data; At the same time, it further points out that the existing method by gathering mass data in large scale and then by using tool software, such as PageRank, MapReduce and Hadoop, to improve the search efficiency turns out to be feasible though, but still flawed or inadequate. It is inevitable for its further development from data center to knowledge center. The significance of this paper lies in exploring two types of cloud computing that exist in the process of further development from data center to knowledge center. Keywords : data center; knowledge center; cloud computing
Title: “云”概念的分析研究——协同智能计算系统的一个特例 Paper: PDF Keywords: 云计算理论 云计算技术 云计算服务 Abstract: 自2006谷歌101项目公开提出云计算(cloud computing)至今,信息产业界说它是一种新的商业模式,信息技术界说它是软件服务(SaaS)、平台服务(PaaS)和基础设施服务(IaaS)三个不同层次的互联网技术的融合,通信与计算机科学界则说它是一种有别于既有范式的新的计算模式,另外还有各种各样的具体说法。可就是缺乏一个系统周全而又简明扼要的理论描述或定义,尤其缺乏英汉双语对照的解释。笔者认为,这对云计算理论与技术的普及和提高均为不利。为此,本文拟从云计算提出的源头及其可能的新发展两个方面来对它做一个系统的分析和展望。旨在为云计算理论与技术的普及和提高开辟新途径。 Time: May 20, 22:31 GMT Fax: Address: Authors Authors: Name Email Country Affiliation Zou Xiaohui qhkjy@yahoo.com.cn China ✔ Zou Shunpeng China “ 云 ” 概念的分析研究 —— 协同智能计算系统的一个特例 邹晓辉 1 , 2 , 邹顺鹏 1 摘 要 : 自 2006 谷歌 101 项目公开提出云计算( cloud computing )至今,信息产业界说它是一种新的商业模式,信息技术界说它是软件服务( SaaS )、平台服务( PaaS )和基础设施服务( IaaS )三个不同层次的互联网技术的融合,通信与计算机科学界则说它是一种有别于既有范式的新的计算模式,另外还有各种各样的具体说法。可就是缺乏一个系统周全而又简明扼要的理论描述或定义,尤其缺乏英汉双语对照的解释。笔者认为,这对云计算理论与技术的普及和提高均为不利。为此,本文拟从云计算提出的源头及其可能的新发展两个方面来对它做一个系统的分析和展望。旨在为云计算理论与技术的普及和提高开辟新途径。 关键词 : 云计算理论;云计算技术;云计算服务 Analysis on the Concept of "Cloud" ——A Special Case of the Collaborative Intelligence Computing System Xiaohui, Zou 1, 2 ; Shunpeng, Zou 1 qhkjy@yahoo.com.cn 15300239971 (1.China University of Geosciences, Beijing 100083, China; 2.Sino-US Berkeley Project) Abstract: Since Google advanced “cloud computing” openly in its “101 project” in 2006, the information industry sector has said that it is a new business model and information technology sector has qualified it as an integration of three different levels of Internet technology, namely software as a services (SaaS), platform as a services (PaaS) and infrastructure as a services (IaaS), while communications and computer science sector has constructed it as a new computing model that is different from the existing paradigm. Besides these, there are also a variety of specific statements. Nevertheless, what we lack is a comprehensive yet concise theoretical description or definition on it, especially the lack of English-Chinese bilingual Comparison interpretation, which in the author’s opinion has a negative impact on the popularization and improvement of “cloud computing” theory and technology. To this end, this paper attempts to make a systematic analysis and outlook on “cloud computing” from two aspects, namely the source of the proposed “cloud computing” and its possible development, aiming to open up new ways for the popularization and improvement of “cloud computing” theory and technology. Key words: Cloud Computing Theory, Cloud Computing Technology, Cloud Computing Service
云计算世界(cloud computing environment)的合适的安全保障( proper security measures ) 附录1: Data Security in the World of Cloud Computing July/August 2009 (vol. 7 no. 4) pp. 61-64 Lori M. Kaufman , BAE Systems DOI Bookmark: http://doi.ieeecomputersociety.org/10.1109/MSP.2009.87 Today, we have the ability to utilize scalable, distributed computing environments within the confines of the Internet, a practice known as cloud computing. In this new world of computing, users are universally required to accept the underlying premise of trust. Within the cloud computing world, the virtual environment lets users access computing power that exceeds that contained within their own physical worlds. Typically, users will know neither the exact location of their data nor the other sources of the data collectively stored with theirs. The data you can find in a cloud ranges from public source, which has minimal security concerns, to private data containing highly sensitive information (such as social security numbers, medical records, or shipping manifests for hazardous material). Does using a cloud environment alleviate the business entities of their responsibility to ensure that proper security measures are in place for both their data and applications, or do they share joint responsibility with service providers? The answers to this and other questions lie within the realm of yet-to-be-written law . As with most technological advances, regulators are typically in a "catch-up" mode to identify policy, governance, and law. Cloud computing presents an extension of problems heretofore experienced with the Internet . To ensure that such decisions are informed and appropriate for the cloud computing environment, the industry itself should establish coherent and effective policy and governance to identify and implement proper security methods. 1. L. Wang et al., "Scientific Cloud Computing: Early Definition and Experience," Proc. 10th Int'l Conf. High-Performance Computing and Communications (HPCC 08), IEEE CS Press, 2008, pp. 825–830. 2. J. Urquhart, "The Biggest Cloud-Computing Issue of 2009 is Trust," C-Net News, 7 Jan. 2009; http://news.cnet.com8301-19413_3-10133487-240.html . 3. J.B. Horrigan, "Cloud Computing Gains in Currency,"12 Sept. 2008, http://pewresearch.org/pubs/948cloud-computing-gains-in-currency . 4. S. Singh, "Different Cloud Computing Standards a Huge Challenge," The Economic Times, 4 June 2009; http://economictimes.indiatimes.com/Infotech/ Different-cloud-computing-standards/ articleshow4614446.cms . 5. "US Federal Cloud Computing Market Forecast 2010–2015," tabular analysis, publication: 05/2009. Index Terms: cloud computing, security, governance, it all depends Citation: Lori M. Kaufman, "Data Security in the World of Cloud Computing," IEEE Security and Privacy , vol. 7, no. 4, pp. 61-64, July/Aug. 2009, doi:10.1109/MSP.2009.87 http://www.computer.org/portal/web/csdl/doi/10.1109/MSP.2009.87 附录2 : SURVEY BY IEEE AND CLOUD SECURITY ALLIANCE DETAILS IMPORTANCE AND URGENCY OF CLOUD COMPUTING SECURITY STANDARDS Enterprises Eager to Adopt Cloud Computing, but Regulatory Requirements Demand Security Standards Compliance Contact: Karen McCabe, IEEE-SA Marketing Director +1 732-562-3824, k.mccabe@ieee.org Robert Nachbar, ZAG Communications for the Cloud Security Alliance +1 206-427-0389, robert@zagcommunications.com RSA CONFERENCE, SAN FRANCISCO, CALIF., USA, 1 March 2010 - IEEE, the world's leading professional association for the advancement of technology, and the Cloud Security Alliance (CSA), a not-for-profit organization formed to promote the use of best practices for providing security assurance within cloud computing, today announced results of a survey of IT professionals that reveals overwhelming agreement on the importance and urgency of cloud computing security standards. "It's clear from the survey's findings that enterprises across sectors are eager to adopt cloud computing - but that security standards are needed both to accelerate cloud adoption on a wide scale and to respond to regulatory drivers , - said Jim Reavis, founder and executive director of the Cloud Security Alliance. - Cloud computing is shaping the future of IT , but, as this study shows in a variety of ways, the absence of a compliance environment is having dramatic impact on cloud computing's growth." Hundreds of IT professionals, many of whom are actively involved in implementing cloud-related projects, participated in the joint IEEE/CSA survey. Among the survey's findings: Ninety-three percent of respondents said the need for cloud computing security standards is important ; 82 percent said the need is urgent. Forty-four percent of respondents said they are already involved in development of cloud computing standards, and 81 percent said they are somewhat or very likely to participate in development of cloud security standards in the next 12 months. Data privacy, security and encryption comprise the most urgent area of need for standards development. The ISO 27001/27002 Information Security Management Standard is a key regulatory driver of standards compliance, as are Data Breach Notification, PCI/DSS (Payment Card Industry Standard), EU Data Privacy Legislation, SOX (Sarbanes-Oxley Act) and HIPAA (Health Insurance Portability and Accountability Act). The use of public, private and hybrid clouds will rise over the next 12 months. The survey found that, while public clouds are most popular, private and hybrid implementations are quickly gaining in adoption. The rate of using and providing software, platform and infrastructure as a service (SaaS, PaaS and IaaS) will increase consistently in the next 12 months. The survey showed that PaaS and IaaS are set for the sharpest growth. "The Cloud Security Alliance, as the world's leading organization focused on cloud security, and IEEE, as a global leader in standards development across an unmatched range of industries, are the obvious partners to establish the baseline on the current and intended usage of cloud computing services, as well as the needs, attitudes and behaviors around cloud security standards," said Judy Gorman, Managing Director, IEEE-SA. "The insights revealed in this survey will prove valuable in informing how the cloud community moves forward." In addition to the announcement today at the Cloud Security Alliance Summit at the RSA Conference in San Francisco, the Computer Security Alliance and IEEE will also present the survey's findings March 16 at SecureCloud 2010 in Barcelona. About the Cloud Security Alliance The Cloud Security Alliance is a not-for-profit organization with a mission to promote the use of best practices for providing security assurance within Cloud Computing, and to provide education on the uses of Cloud Computing to help secure all other forms of computing. The Cloud Security Alliance is led by industry practitioners and supported by more than 25 corporate members . For further information, see the Cloud Security Alliance website . About the IEEE Standards Association The IEEE Standards Association, a globally recognized standards-setting body within the IEEE, develops consensus standards through an open process that engages industry and brings together a broad stakeholder community. IEEE standards set specifications and best practices based on current scientific and technological knowledge. The IEEE-SA has a portfolio of over 900 active standards and more than 600 standards under development. For more information see the IEEE-SA website . About IEEE IEEE is the world's largest technical professional association. Through its more than 375,000 members in 160 countries, IEEE is a leading authority on a wide variety of areas ranging from aerospace systems, computers and telecommunications to biomedical engineering, electric power and consumer electronics. Dedicated to the advancement of technology, IEEE publishes 30 percent of the world's literature in the electrical and electronics engineering and computer science fields, and has developed over 900 active industry standards. The organization annually sponsors more than 850 conferences worldwide. For more information see the IEEE website . http://standards.ieee.org/news/2010/cloudcomp.html
说到这里,我们需要看一下目前“云计算”的几种使用方式了。先列个清单吧,以英文名为准,中文的翻译除了“软件即服务”之外,都是根据统一模式“硬”译的: · 软件即服务( Software as a Service, SaaS ) · 平台即服务( Platform as a Service, PaaS ) · 基础设施即服务( Infrastructure as a Service, IaaS ) · 存储即服务( Storage as a Service, DaaS ) · 通讯即服务( Communication as a Service, CaaS ) · 设备即服务( Hardware as a Service, HaaS ) 软件即服务( Software as a Service, SaaS )大概是最早从云端出现的服务概念。在美国提起 SaaS ,业界里的人首先想到的可能是 Salesforce.com 与其 CEO 贝尼奥夫。事实上,谷歌的 Gmail 以及 Google Doc 等服务都是 SaaS 。 微软推出的, Microsoft Live 也是。 SaaS 其实就是“云计算”的最高层面,应用程序层面,给用户提供的一种应用程序服务。象 Hotmail.com 这样的基于网络的大型商业电子邮件系统应该可以看作是早期的 SaaS ,只不过我们基于传统习惯没有意识到而已。 贝尼奥夫创立 Salesforce.com 的起因要追溯到他在甲骨文公司给总裁埃里森做副手时所受到的启发。据他自己讲,是在一次去北京的飞机上,埃里森跟他谈到:甲骨文数据库应该通过网络让用户使用,这样可以随时维护不用担心不同版本的问题。又有一次,他在负责关于销售人员自动化(也就是 CRM 的前身)的软件开发过程中发现,这种软件需求量很大但费用很高,最便宜的单人使用版本费用也要 1500 美元。与此同时,作为使用者的销售人员们则时常抱怨软件缺少这样或那样的功能,结果,维护、修改、升级费用常常是使用费用的十倍甚至更高。可是公司为了销售不得不忍痛付出。为此他不断思考研究,终于发现如果以甲骨文数据库为基础,搞一个低廉使用价格(每人 50 美元)的网上 CRM 系统应该是一个有前途的主意。因为,这首先可以让销售人员随时上网使用该系统,不必担心没有装软件,其次,如果出现了有好的和新的功能,可以被很快编入系统,立即使用,而一旦被编入系统,其他销售人员也可以使用。这样系统的价值会不断增加, 于是 Salesforce.com 就诞生了。
数据海者,海量数据也。数据海波澜壮阔,可以让你在任何地方都能看到海浪的痕迹并通过网络使用之,海洋是假、数据是真。 云计算者,知其在计算而不知其如何计算也。云计算天高云浓,可以让你腾云驾雾,就是不让你搞清机理和结构,你可以通过网络把自己的数据和工作交付云里雾里,那里会有计算机为你效力,资源是实、比喻为虚。 计算机行业总是制造新名词新术语来推动产品升级换代,这是其盈利机制,如果你甘愿把自己的一切放进海里云里,无妨跟风尝试。不过记得当年曾经鼓吹的公网存储式的 Web PC 后来销声匿迹,其原因之一就是用户不愿意把所有个人数据和资源存到公网上,于是每人一台自己的 PC 成就了如今的技术格局 …
论文“互联网与神经学的交叉对比研究”。详细阐述了五年来的研究成果,并补充上互联网的神经反射弧,人脑中的搜索引擎,维基百科,IPv4/v6地址编码,路由系统等方面的实验设计。发表在“复杂系统与复杂性科学”2010年9月的网络科学专刊。 互联网与神经学的交叉对比研究 刘锋1 2 1.中国科学院虚拟经济与数据科学研究中心,北京(100190) 2. 北京交通大学计算机与信息技术学院,北京(100044) 摘要: 随着互联网的发展,越来越多的迹象表明互联网与神经学具有很强的对比性,本文首先就互联网和神经学交叉对比的猜想提出过程进行介绍。然后通过神经学对互联网研究的启发,分别从互联网虚拟神经元,虚拟感觉和运动系统,虚拟自主神经系统,虚拟中枢神经系统,虚拟神经反射弧对互联网虚拟大脑的结构和功能进行阐述。利用互联网对神经学研究的启发,从路由系统,搜索引擎应用,维基百科应用,IP地址应用等方面介绍了人脑中类互联网结构功能的研究方法和实验设计。同时本文也对其他研究者观点以及云计算,物联网,智慧地球等相关概念进行了介绍。 关键词:互联网 大脑 神经学 互联网虚拟大脑 互联网进化 中图分类号:TP393.4 ; Q42 文献标识码:A Crossover comparative study on the Internet and Neurologyn Liu Feng1 2 1.Research Centre on Fictitious Economy and Data Science, Chinese Academy of Sciences, Beijing (100190) 2. School of Computer and Information Technology,beijing jiaotong unversity Beijing (100044) Abstract: Following the development of the internet, more and more phenomena show that there are strong relative properties between the Internet and Neurology. The article first makes a review on the developing process of idea on crossover comparation of the Internet and Neurology, then based on the enlightment by Neurology on the internet research, elaborates the structure and functions of Internet virtual brain from aspects of virtual nerve cell, virtual sensory and locomotor system, virtual autonomic nervous system, virtual central nervous system, virtual neural arc, and makes introduction on the research methods and experimental designs of structures and functions similar to Internet in human brains from aspects of router system, search engine, Wikipedia, IP address etc. The article also makes introduction on the views of other relative researchers and related concepts of " cloud computing" ,"the internet of things", "smarter planet" etc . Keyword: Internet,brain,internet virtual brain,neurolog,evolution of Internet 0引言 一般认为互联网诞生与1969 年的美国,从那时到现在的41年里,互联网取得了迅猛的发展,连接线路从最初的电话线发展到现在的光纤,无线通讯,电缆等多种类型,应用从最初的电子邮件,ftp, BBS发展到现在的博客,视频,搜索引擎,SNS等数千种种类,据中国通信信息研究所“2008-2009年度全球互联网发展研究”报告称“截至2008年底,全球互联网用户数已经达到15.74亿,较2007年增长19.2%,普及率达到23.5%“。各个国家在科技,军事,文化,娱乐,商业等各个领域都受到互联网越来越强大和深入的影响。 面对互联网的迅猛发展,有二个问题需要确定和解决,第一,互联网的发展有没有规律;第二,互联网发展的最终结构是什么。从2005年开始,我们对互联网的结构和应用进行了大量观测,发现互联网和大脑的结构和功能具有很强的相似性。因此提出通过互联网与神经学的交叉对比,一方面可以预测互联网未来的发展动向和最终结构,另一方面可以逐步解开神经学中人脑的未知领域。本文将对这一观点的起源,相关研究以及其他研究者的进展进行阐述。 1互联网与神经学交叉对比的猜想 1.1提出互联网的新定义 无论是1995年10月24日,“联合网络委员会”(FNC)关于“互联网定义”的决议,还是计算机网络的七层结构,一般认为,互联网是由计算机,通讯线路,以及在它们中传输和运行的信息,数据,资料和应用组成。 传统的互联网和网络定义往往忽略了”人“和“人脑中的数据”这两个要素。纵观人类的发展历史和互联网诞生后的进化过程,我们可以看到人类进步就是一部包含了其感觉和运动器官不断延长的历史。棍棒延伸了双臂,石头延伸了拳头,汽车、火车延伸了双腿,望远镜、显微镜延伸了眼睛,传递信号的锣、鼓、电话线延伸了耳朵,大工业革命后出现的公路网、铁路网、飞机航线、海运航线的出现最终使人类四肢实现联网。 与此同时,人类大脑的延伸也一刻没有停止。结绳、算盘、数筹的出现就是早期的例证。1946年,在美国诞生的电子计算机使人类大脑实现质的延伸。1969年互联网诞生后,台式机,笔记本电脑,3G手机的出现无一不是增加人脑与互联网的连接时间。人脑中的信息和知识不断与互联网里的信息和知识进行交互。人类和互联网的发展史告诉我们,互联网不仅仅是机器的联网,它更是为了加强人脑之间的连接。 综上所述,我们在2007年的论文中提出了新的互联网定义,即互联网是由网络线路、计算机节点、人脑和在它们之间储存,流动和运行的数据等四个部分组成的网络结构 ,这个定义最大的特点是把人脑,和人脑中的数据也作为互联网的一部分。它将是我们进行下列问题探讨的重要基础。 1.2电子公告牌功能分裂现象的发现 1983年Capital PC User Group(CPCUG)通过努力,完成了个人计算机的第1版BBS系统——RBBS-PC,这个系统一般认为是电子公告牌的鼻祖,2005年,我们在编写网站程序时,发现使用一个BBS原程序可以任意变形为类新闻,类电子商务,类维基百科,类SNS和类搜索引擎的应用。通过进一步观测我们提出,电子公告牌在诞生之后,开始逐渐发生分裂现象,其功能一个个的分离出去,形成互联网众多应用。这些应用包括新闻类网站,电子商务类网站。博客类网站。智力互动问答类网站,热点点评(DIGG类网站),维基WIKI类网站,SNS类网站.换客类网站.搜索引擎网站 (图 1)。 图1 电子公告牌功能分离现象图 我们将其中的网络互动问答方向与知识管理的知识价值化概念结合,提出威客witkey的概念和商业模式图形。威客模式就是互联网用户通过解答科学,技术,工作,生活中的问题,获得经济报酬 (图2)。 图2 威客模式运行模型 1.3互联网类神经元现象的发现 在研究的过程中, 我们发现从2007年开始,BBS分离出来的博客、互动问答(威客)与电子邮件、远程网络软件又开始融合起来,相关的应用在雅虎,新浪等门户类网站的个人空间系统中已经得到体现。结合互联网得新定义,我们对这种现象进行思考,我们知道在知识管理领域,知识有这样一种划分,显性知识和隐性知识。对这种划分方法进行了扩充,可以将人脑的功能从知识层面划分成1)共享知识区,例如免费给人指路的信息。2)可交易知识区,例如医生的专业知识必需等病人挂号后才能表达。3)问题区,例如学生不知道答案的数学难题。4)隐私区,例如个人或几个朋友之间的隐私信息。5)运动控制功能区,例如人用筷子夹菜的能力或者用手指打键盘的能力。把这些区域组合起来就形成图3左边的人脑知识功能区。 图3 人脑知识功能区与互联网个人空间的对应关系图 如果我们将人脑知识功能区与互联网个人空间进行对比,可以看到共享知识区对应了博客,可交易知识区和问题区对应了智力互动问答,隐私区对应了电子邮箱,运动控制功能对应了网络软件(图3)。前面我们提到互联网进化的目标是使人类的大脑充分联网,但是目前互联网不可能通过物理手段直接将线路和信号接驳到人的大脑中,通过上述对应关系的描述,我们可以看出人脑的知识功能区通过互联网个人空间被映射到互联网中。 在互联网中,电子邮件和网络远程软件需要通过光纤,电话线里的数据通道与其他人或设备进行联系。我们把这个数据线路也描绘出来(图4左图),可以看出它与图4右图中真实的神经元十分相似。在神经学中,神经元的胞体是信息处理中心,树突和轴突负责与外界进行信息沟通。因此可以这样类比,互联网个人空间对应了神经元的胞体,电子邮件和网络软件的远程数据线路对应了神经元的树突和轴突。我们将互联网这一结构命名为互联网的映射型神经元 。 图4 互联网虚拟神经元与人类大脑神经元 1.4互联网类躯体感觉和类运动系统的出现 2007年7月本文作者参加中国水利部举办的研讨会,了解到中国水利部部门开始在土壤,河流,空气中安放传感器,及时将气温,湿度,风速等数据通过互联网传输到信息处理中心,形成报告供防汛抗旱决策使用。环境部门在自然界安置联网的传感器供环境监测系统使用,这启发我们联想到了大脑中的躯体感觉神经系统。 2007年开始,Google推出了“街景“服务,即在城市中安装安装多镜头摄像机,互联网用户可以实时观看丹佛、拉斯维加斯、迈阿密、纽约和旧金山等城市的风貌,这些项目使我们联想到了大脑中的视觉和听觉系统。 从20世纪90年代,通过局域网或城域网远程操控打印机,复印机的应用已经出现,到21世纪前十年,医生通过远程网络进行手术的案例已经十分普遍,这些远程操控机器设备的应用启发我们联想到人脑中的运动神经系统 。 1.5互联网与神经学交叉对比猜想的提出 2008年7月我们在论文“从人脑的机理看互联网的进化“提出,互联网正在从一个原始的,不完善,相对分裂的网络进化成一个统一的,与人类大脑结构高度相似的组织结构,它将同样具备自己的虚拟神经元,虚拟感觉、视觉、听觉、运动,中枢,自主和记忆神经系统。我们将互联网这一结构命名为互联网虚拟大脑。互联网虚拟大脑的不断成熟将对神经学产生重大的启发式影响,通过对比成熟的互联网结构和应用功能,我们将可能不断发现人类大脑中未知的领域”,在这篇论文中我们也第一次绘制出互联网虚拟大脑结构图 (图5) 图5 互联网虚拟大脑简要结构图 1.6互联网进化的其他相关研究者情况 历史上很多人独立的揭示了社会可以看作为带有自己的神经系统的有机体的概念。例如认为国王是头,农夫是脚的观点,至少可以追溯到古希腊人和中世纪。这个类推为19世纪社会学的创始人提供了灵感。赫伯特•斯宾塞(Herbert Spencer)提出他的《社会是一个有机体》)。进化论神学家德日进(Pierre Teilhard De Chardin)关注社会有机体的精神组织,称之为“心智界(noosphere)”。科幻小说作家赫伯特•乔治•威尔斯(H. G. Wells)提出“世界脑”的概念,当作知识的联合系统,所有人可以访问。1983年彼得•罗素(P. Russell)撰写的《地球脑的觉醒——进化的下一次飞跃》从哲学的层面探讨地球存在的本源和意义中,他提出人类社会通过政治,文化,技术等各种联系使地球成为一个类人脑的组织结构,也就是地球脑 。 总体上看这些思考和理论还局限在科幻,社会学,哲学甚至神学的层面。由于受到当时互联网技术发展水平的局限,不能全面的了解互联网的结构和最新应用,无法从科学研究的视角,将互联网的功能结构与神经学做交叉对比研究。他们往往把人作为神经元本身进行探讨,而没有发现人脑功能通过映射,在互联网中出现的类神经元现象,这个重要的区别导致上述这些思考一直无法将研究推进到科学实证研究的方向。事实上,直到2008年,即使是主流科学意见对互联网和神经学的关系依然抱有怀疑的看法。美国计算机期刊ACM对互联网与神经学交叉对比论文"The Discovery and Analysis on the Law of Internet Evolution"的评审意见就十分具有代表性"the brain evolved over millions of years and the brain evolved under natural selection in which many millions of individual designs were tried and abandoned. The internet is a single entity and is designed by humans.” 2互联网虚拟大脑提出和研究情况 2.1互联网虚拟大脑的结构组成 根据互联网与神经学交叉对比猜想的启发,2009年7月我们在论文“互联网虚拟大脑的结构与功能”中提出了更为详细的互联网虚拟大脑的结构图示(图6)。,将互联网从低端到高端划分为硬件层,软件层,和信息层。其中互联网硬件层包括互联网核心硬件层,互联网远程传感和运动设备。互联网个人终端,互联网网络线路等四个组成部分。互联网软件层包含互联网操作系统和互联网应用软件,其中互联网的应用软件根据其特点又被划分为人脑映射型虚拟神经元,数据整理和挖掘虚拟神经元,感觉和运动虚拟神经元,特异类虚拟神经元,互联网的信息层包含文字,二维图片,文档,视频,声音,三维图像等,分布在互联网的服务器,路由器,交换机,用户终端和互联网虚拟神经系统里。我们将这些分布在互联网中的信息统称为互联网数据海洋 。 图6 互联网虚拟大脑复杂结构图 对于互联网虚拟大脑的研究,我们认为主要包含如下几个问题,存在几种互联网神经元?互联网的感觉,听觉,视觉,运动等虚拟神经系统如何运转?虚拟神经元与互联网中的数据,信息和资料如何交互?互联网虚拟大脑中存在多少种虚拟神经反射弧? 2.2互联网的虚拟神经元 根据互联网应用程序的特点,我们提出四种互联网的虚拟神经元,它们分别是: 第一,融合博客,威客(智力互动问答),电子邮件的互联网应用,如新浪,雅虎的用户系统,我们将这种与互联网用户交互的应用定义为人脑映射型虚拟神经元。 第二,对互联网的信息,数据和资料进行整理,挖掘和知识发现的互联网应用程序,如谷歌的搜索引擎,ANGOSS软件公司的KnowledgeSTUDIO,Comshare公司的Comshare Decision and Decision Web等,我们将这些软件定义为数据整理和挖掘虚拟神经元。 第三,控制互联网远程传感和运动设备,并且将他们产生的数据传输给互联网信息层的应用软件,我们将它们定义为感觉和运动虚拟神经元。 第四,其他类型的互联网应用软件,如网络游戏,防病毒软件等。我们将它们定义为特异类虚拟神经元 2.3互联网虚拟感觉和运动神经系统 我们提出互联网虚拟感觉和运动神经系统在成熟后,主要有两种运行模式,第一种是互联网用户直接操控模式(图7),流程为(1)互联网用户登陆个人终端(2)个人终端运行个人空间应用程序(映射型虚拟神经元)(3)个人空间相关应用程序与远方传感器,工作设备的驱动程序进行接驳(4)互联网用户通过个人空间界面直接操控传感器,视频,音频和办公设备进行活动。 图7 互联网用户直接操控的虚拟感觉和运动系统机构图 第二种是互联网用户的间接获取模式(图8),流程为(1)传感器,视频,音频采集器,工作设备在本身的程序(或在数据整理和挖掘虚拟神经元)的驱动下,自动运行(2)传感器,视频,音频采集器,工作设备在运行中得到的相关数据进入到互联网的数据海洋中。(3)互联网用户通过个人终端的个人空间应用程序(映射型虚拟神经元)与数据整理和挖掘虚拟神经元接驳并获取数据。 图8 互联网用户间接获取虚拟感觉和运动系统机构图 2.4互联网虚拟自主神经系统 互联网软件层包含了一种虚拟神经元---数据整理和挖掘虚拟神经元,这种神经元应用了人工智能,知识发现和数据挖掘领域的算法,针对互联网中的信息,数据和资料进行处理。其处理的结果通过互联网供个人用户和机构用户查阅和研究。因为这一类神经元包含了预先存放的算法和知识,在运行时并不需要人的主动控制。 数据整理和挖掘虚拟神经元与互联网虚拟感觉,视觉,听觉,运动系统的结合。设计者可以将算法和规则放入到数据整理和挖掘虚拟神经元(或直接放入到感觉或运动神经元)中,当从互联网虚拟感觉,视觉,听觉系统获得信号触发,数据整理和挖掘虚拟神经元便开始驱动互联网虚拟运动系统或其他系统完成特定功能(图9)。例如连结到互联网的传感器将气压,湿度,温度等参数发送给互联网的特定应用程序(数据整理和挖掘虚拟神经元),经过运算如果符合下雨的条件设定,程序受到触发,激活互联网虚拟运动神经元,远程控制野外设备如收割机,挖掘机打开防雨设备。上述互联网现象,我们将其归纳为互联网的类自主神经系统。 图9 互联网虚拟自主神经系统示意图 从图5我们可以看到互联网自主神经系统主要有两种运行模式:1)对互联网的数据海洋数据进行整理和挖掘,并将结果根据需求传递给映射型虚拟神经元2)数据整理和挖掘神经元用内置的算法和规则控制运动虚拟神经元,感觉虚拟神经元,并最终控制机器设备. 2.5互联网虚拟中枢神经系统 互联网中枢神经系统的硬件基础是互联网的核心服务器以及联结他们的路由器和交换机,在这些硬件设备上统一运行的虚拟感觉神经元,听觉神经元,视觉神经元,运动神经元,数据整理和挖掘神经元,映射型神经元等互联网应用程序将构成互联网中枢神经系统的软件基础,包含文字,音频,视频,文档等信息的数据海洋将组成互联网中枢神经系统的信息基础( 4 )(图10)。 图10 互联网虚拟中枢神经系统示意图 从2007年开始,互联网的核心服务器和应用也开始出现集中化的趋势,2007年9月Google和IBM提出和推广的云计算就代表了这种趋势。通俗的讲,云计算就是将传统上分散在个人计算机上的应用集中在若干个大型服务器中,互联网用户通过终端使用大型服务器提供的互联网服务。从云计算的这些特点看,它具备了互联网虚拟中枢神经系统的雏形。 2.6互联网的虚拟神经反射弧现象 反射弧是实现反射活动的神经结构。由感受器、传入神经、神经中枢、传出神经、效应器五个部分组成。神经系统的活动是各种各样简单或复杂的反射活动,反射弧的结构也有简有繁,复杂的反射弧有许多中间神经元。在最简单的反射弧中,传入神经元和传出神经元直接在中枢内接触,称为单突触反射 。 膝跳反射是一种最为简单的反射类型,它仅包含两个神经元感觉神经元(输入)和运动神经元(输出)。膝跳反射的神经中枢是低级神经中枢,位于脊髓内。但是,在完成膝跳反射的同时,脊髓中通向大脑的神经会将这一神经冲动传往大脑,使人感觉到膝盖被叩击了 (图11)。 图11 膝跳反射示意图 从图7和图8的互联网虚拟感觉和运动结构图中,我们可以看到互联网也同样存在神经反射现象。例如,当互联网中的传感器通过测量空气中的温度,湿度和风速,经过预制程序的运算,发现达到符合下雨的条件参数,于是传感器向互联网中枢神经系统发出信号,互联网中枢神经系统经过简单运算,向该地区联网的野外机械设备发出指令,打开防雨设备,实现互联网的防雨神经反射弧功能(图12)。互联网除了这种简单的反射现象之外,和人类神经系统一样,也同样存在复杂的神经反射现象,这个问题将在未来的论文中专门进行阐述。 图12 互联网神经反射弧示意图 2.7关于互联网研究的相关概念综述 从2007年开始,互联网出现了云计算,物联网,智慧地球,这些概念与互联网神经系统的观点都有一定关联,分别介绍如下。 云计算由Google提出,2007年10月Google与IBM开始在美国大学校园,包括卡内基美隆大学、麻省理工学院、斯坦福大学、加州大学柏克莱分校及马里兰大学等,推广云计算的计划,一般来讲,就是传统我们在个人计算机里安装的办公软件,游戏软件,杀毒软件,财务软件等,都集中放入互联网中的巨型服务器中,无数用户通过更为简单的客户端接受巨型服务器的“服务“ 。 物联网普遍公认的是MIT Auto-ID中心Ashton教授1999年在研究RFID时最早提出来的。物联网的英文名称为"The Internet of Things” ,简称:IOT。物联网通过传感器、射频识别技术、全球定位系统等技术,实时采集任何需要监控、连接、互动的物体或过程,采集其声、光、热、电、力学、化学、生物、位置等各种需要的信息,通过各类可能的网络接入,实现物与物、物与人的泛在链接,实现对物品和过程的智能化感知、识别和管理 。 2009年1月28日,IBM首席执行官彭明盛在奥巴马举办的美国工商业领袖圆桌会议上,提出“智慧地球”这一概念,建议新政府投资新一代的智慧型基础设施。IBM的智慧地球主要内容是“物联网和互联网整合起来,实现人类社会与物理系统的整合。把感应器嵌入和装备到电网、铁路、桥梁、隧道、公路、建筑、供水系统、大坝、油气管道等各种物体中,并且被普遍连接,形成所谓“物联网,通过超级计算机和云计算将“物联网”整合起来 。 从本文描述的互联网虚拟大脑结构看,云计算相当于互联网的中枢神经系统,物联网相当于互联网的虚拟感觉神经系统,而智慧地球的概念从结构上与互联网虚拟大脑结构类似,但仍然没有很好的解决云计算,物联网与传统互联网的关系,迄今为止没有形成完整的结构图示。从互联网进化的观点看,云计算,物联网和智慧地球仍然是互联网(虚拟大脑)的组成部分,并不是脱离互联网出现的新独立事物。 3人脑中的互联网应用 我们曾经在论文“互联网虚拟大脑的结构和功能” 中提出5个人脑中类互联网应用,连同本文新提出的6个新互联网应用,形成11个互联网虚拟大脑与人脑结构的对比应用,(表1)。 表1互联网与人脑功能结构对比表 互联网的结构 人脑的结构 SNS 类SNS应用 电子商务 类电子商务应用 twitter 类twitter 威客(witkey) 类威客(witkey) 博客应用 类博客应用 维基百科应用 类维基百科应用 互联网的地址编码系统(ipv4,ipv6) 人脑的地址编码系统 互联网的搜索引擎(google.,百度) 人脑的搜索引擎 互联网网络的路由协议(Tcp,rip,bgp)人脑的路由协议 互联网的信用体系 人脑的信用体系 互联网的信息筛选,整理和推荐机制 人脑的信息筛选,整理和推荐机制 对于上述对比象,我们认为应该从神经心理学和神经生理学等层面进行研究,一方面提炼和总结互联网相关应用的运行特征,以此为启发和索引,设计神经心理学和神经生理学实验,在人脑或其他生物大脑中寻找对应结构,本文将从4各方面对人脑中类互联网应用进行阐述。 3.1人脑中类搜索引擎应用 搜索引擎(search engine)是指根据一定的策略、运用特定的计算机程序搜集互联网上的信息,在对信息进行组织和处理后,并将处理后的信息显示给用户,是为用户提供检索服务的系统。目前互联网使用最为广泛的是Google(英文)和baidu(中文)。主要工作原理有三个环节。第一,每个独立的搜索引擎都有自己的网页抓取程序(spider)。Spider顺着网页中的超链接,连续地抓取网页。由于互联网中超链接的应用很普遍,理论上,从一定范围的网页出发,就能搜集到绝大多数的网页。第二,搜索引擎抓到网页后,还要做大量的预处理工作,才能提供检索服务。其中,最重要的就是提取关键词,建立索引文件。第三,用户输入关键词进行检索,搜索引擎从索引数据库中找到匹配该关键词的网页 。 根据搜索引擎的工作原理,我们可以设计如下神经心理学层面的实验。第一.准备10张志愿者照片,实验参与者逐次查看照片。第二.实验者处于实验房间内静默思考。第三,分别让在10张照片内的一名志愿者和不在10张照片内的一名志愿者进入实验房间,让实验参与者辨认是否是10张照片出现过的人。实验参与者填写表格如下(表2): 表2 人脑类搜索引擎试验记录表 照片 是否出现 备注 A志愿者照片 B志愿者照片 C志愿者照片 D志愿者照片 E志愿者照片 F志愿者照片 G志愿者照片 H志愿者照片 I志愿者照片 如果试验参与者能够直接辨识或通过重复上述过程辨识志愿者是否为照片中出现的人,则说明该实验者大脑中存在扫描信息,索引信息,检索信息的类搜索引擎功能,当试验者数目不断增加,而完成上述功能的试验者比例超过95%,则可以证明人脑中存在类搜索引擎功能。 3.2人脑中的类维基百科应用 维基百科是一个自由、免费、内容开放的互联网百科全书协作计划,参与者来自世界各地。这个站点使用Wiki,任何人都可以编辑维基百科中的任何文章及条目。从技术的角度看维基百科起源于1983年诞生的电子公告牌功能,传统上在BBS中,只有文章的发布者或管理员能够修改文章内容,维基百科对这一功能进行了创新,它允许每一个访问者(或者必须是维基百科的注册用户)可以对一个词条的内容进行修改,无论这个词条的内容是谁创建和发布的。 维基百科应用的工作原理和工作流程是这样的,用户A创建词条abc,并撰写abc的解释和说明文字,形成版本1。用户B看到词条abc和它的说明文字,认为解释不完整或者有错误,于是用户B在用户A文字的基础上进行修改,形成版本2。,不断有用户进行修改,abc的版本号不断增加。在修改的过程中,如果一个用户发现最新的版本整体质量不如前面的版本,则他可以将前面的版本置为最新版本。虽然有国界,信仰,情绪,知识范围的不同,会产生修改意见的争执。但总体上看,维基百科的工作流程还是会使各词条的说明质量不断提高。 根据维基百科的工作原理,我们可以在神经心理学层面设计如下实验。参与实验者A和志愿者B最初共同处于一个实验房间内,要求参与实验者A观察志愿者B衣服的颜色,然后志愿者B离开房间,实验者A纪录B的衣服颜色,B更换不同颜色服装进入实验室,重复上述过程5次,在五次试验结束后,收回A填写的纪录表,更换同样内容的新表,请A回忆B从第一次到最后一次穿着颜色并按顺序重新纪录(表3)。 表3 人脑中类维基百科应用试验记录表 次数 志愿者B衣服的颜色 备注 第一次 第二次 第三次 第四次 第五次 如果参与者A能够完成上述过程并正确纪录B不断更新的颜色,则说明A根据一个物体的变化,不断更新该物体属性的说明和纪录,并保留原有属性的纪录,而这恰恰是维基百科的运行原理。通过对大量人员的测试,如果95%(色盲导致的错误除外)的试验者能够完成实验,则说明人脑大脑存在类维基百科的应用是成立的。 3.3人脑中的类ip地址应用 目前的全球因特网所采用的协议族是TCP/IP协议族。IP是TCP/IP协议族中网络层的协议,是TCP/IP协议族的核心协议。目前IP协议的版本号是4(简称为IPv4),发展至今已经使用了30多年。 IPv4的地址位数为32位,也就是可以为连接到Internet上的设备提供2^32-1个地址。随着互联网的蓬勃发展,IP位址的需求量愈来愈大,使得IP位址的发放愈趋严格。 IPv6是下一版本的互联网协议,也可以说是下一代互联网的协议,它的提出最初是因为随着互联网的迅速发展,IPv4定义的有限地址空间将被耗尽,地址空间的不足必将妨碍互联网的进一步发展。为了扩大地址空间,拟通过IPv6重新定义地址空间。IPv6采用128位地址长度,可以为互联网中的设备提供2^128-1个地址 。 检验在人脑中是否存在类ipv4/ipv6的应用,这个地址编码系统究竟是存在于神经元层面,或者人脑中的记忆信息层面,这是一个深入涉及神经生理学的实验设计,已经超出了本文作者的知识范围,但是本文作者提供了ipv4/ipv6的设计原理,希望能作为神经生理学家设计相关实验的参考,需要回答的有两个问题第一,在人脑的哪个结构层面会出现类ipv4/ipv6应用。第二,互联网的地址编码系统正在经历从ipv4/向ipv6进化的阶段,那么在生物大脑进化的过程中,是否也出现过类似的地址编码扩充现象。 3.4人脑中的类路由器功能应用 工作在OSI参考模型第三层——网络层的数据包转发设备。路由器通过转发数据包来实现网络互连,路由器工作包含两个基本的动作:第一,根据维护的路由表确定最佳路径,第二,通过网络传输信息路由器。 具体工作流程如下路由器的某一个接口接收到一个数据包时,会查看包中的目标网络地址以判断该包的目的地址在当前的路由表中是否存在。如果发现包的目标地址与本路由器的某个接口所连接的网络地址相同,就将数据转发到相应接口;如果发现包的目标地址不是自己的直连网段,路由器会查看自己的路由表,查找包的目的网络所对应的接口,并从相应的接口转发出去;如果路由表中记录的网络地址与包的目标地址不匹配,则根据路由器配置转发到默认接口,在没有配置默认接口的情况下会给用户返回目标地址不可达的信息 。 正是因为互联网存在大量的路由器,以及它们维护的路由表,因此互联网出现一个在它诞生之初就有的特性具备的特性,当局部的网络出现故障无法进行通讯时,数据包或信息流可以通过互联网的其他路经绕行,从起点传达给终点。 人类大脑中存在与互联网路由高度相似的功能,目前这个方向的研究有了初步的突破,美国一项新研究发现,老鼠大脑一小块区域中的神经系统类似互联网结构。美国南加州大学神经系统科学家拉里•斯旺森和理查德•汤普森隔离起老鼠大脑中与愉悦和奖励相关的伏核区,在同一点同时注入两枚“示踪剂”,分别用于显示信号去向和来源。“示踪剂”跟随信号移动,但不会干扰信号移动,能发光,可在显微镜下观察到。他们发现,信号在一个个圈组成的网络中移动,这个网络“不是一个有上下之分的等级架构”。 斯旺森2010年8月11日对英国广播公司(BBC)说,大脑中互联网式结构的存在可以解释大脑能克服局部损伤的现象,“你可以拿掉互联网任何一个单独部分,但网络其他部分照常工作”,神经系统同样,没法说某一部分绝对不可或缺。拉里•斯旺森和理查德•汤普森的研究成果已经发表在2010年8月《国家科学院院刊》(PNAS) 。 4总结与展望 从2007年我们正式开始互联网进化的研究以来,越来越多的证据表明互联网和神经学具备很强的交叉对比研究的可能性。我们相信随着研究的深入,互联网和神经学的交叉对比将会对两个领域同时带来更多的启发和成果。 正如东南大学科技与社会研究中心主任吕乃基教授评价的那样,这个方向 “关系到互联网的发展、对人脑及思维的认识、人与互联网,从根本上说是人与技术的关系,以及对于进化的理解等一系列重大问题。有必要从IT、网络理论、科学技术哲学、神经心理学,以及认知科学等不同角度加以研究” 。 References . Feng Liu,Ling ling zhang,Ji fa gu. The Application of Knowledge Management in the Internet--- Witkey Mode in China .International Journal of Knowledge and Systems Sciences. 2008,4(4). 12~17 .Fengliu gengpeng yingliu. From the Structure of The Human Brain to See the Evolution of the Internet . CHINESE JOURNAL OF ERGONOMICS ,2009,15(1). 11~14 Peter • Russell. Earth Awakening Brain . Heilongjiang People Publishing House. 2004.2~4 Fengliu gengpeng. The structure and function of internet virtual brai . sciencepaper online. 2009.4 Ben greenstein,Adam greenstein. Color Atlas of Neuroscience Neuroanatomy and Neurophysiology . Thieme. 2003.56~60 Baidu Encyclopedia. cloud computing . . http://baike.baidu.com/view/1316082.htm?fr=ala0_1 Baidu Encyclopedia. The Internet of things . . http://baike.baidu.com/view/1136308.htm?fr=ala0_1_1 IBM. Smarter Planet . .http://www.ibm.com Baidu Encyclopedia. search engine .2010. http://baike.baidu.com/view/1154.htm Carl Timm Wade Edwards. CCNP:building Scalable Cisco Internetworks Study Guide . Sybex. 2002.13~16 BBC. Brain works more like internet than 'top down' company . . http://www.bbc.co.uk/news/science-environment-10925841 .Naijilv. Discussion of the Evolution of the Internet ]. . http://www.sciencenet.cn/m/user_content.aspx?id=248826
由于最近正准备一篇云计算在电力系统分析中应用的文章,看了有一定数量的云计算的文章,主要是介绍性的,有几篇具体某一学科上应用的,但在国内的实际应用还罕见。由于目前学术研究才刚起步,更多是网上的新闻报道,推荐一个我们国内的网站,由刘鹏老师组织搭建的 中国云计算 http://www.chinacloud.cn/default.aspx ,站里内容丰富。 但从目前看来,云计算,主要是指公共云计算,虽说是 pay-as-you-go 的商业模型,还很难为普同科研人员所用,只是美国等少数得到政府支持的研究人员,在 MS,IBM , Google 这些大公司的配合下,开展一定的测试性研究。同样的事情,在国内没有硬件平台缺乏,软件重视更不足情况下,实是比较难开展的。相比之下,云计算显得更适合于数据的处理 ( 当然,我也希望学术界能在其他领域也利用好 CC ,自己也争取努力做出些成绩 ) ,基于 MapReduce 分布式性数据存储和处理已经得到大规模应用和实际的肯定。 下面主要想谈一下海量数据的处理问题,这也是最近一段时间所看的资料和与计算科学专家 Savas( http://savas.me/ ) 的邮件交流后的体会,特别是他推荐的几篇文章,让我这个学术 小孩子 和计算机领域的 ,门外汉 了解到学术发展的新动态,计算机科学的发展为大规模数据的处理提供了可能,这将开始科学发现的新模式 基于大规模密集数据处理的科学发现( data-intensive scientifc discovery ),更详细的分析可见 Savas 推荐的,他与 Jim Gray 、 Tony Hey 等合著的一本新书 The Fourth Paradigm: Data-Intensive Scientific Discovery (文后附下载地址) 在经历实验式、理论式、仿真式后,科学研究和发现将进入基于大规模数据处理的模式 (the following is quoted from Savass site : Amongst the many things that Jim talked about was the Fourth Paradigm in Science, the fact that scientific research has transitioned from experimental (thousands of years go), to theoretical (few hundreds years ago), to computational (last few decades), to data-intensive (today) 在这样的一个大的趋势下,我们该思考如何结合自己学科上、研究项目中的特点,更好地利用计算科学的计算和资源,对研究中的大规模数据进行处理是十分必要的。结合我自己的电力学科,云计算将是未来应对智能电网大量数据处理和用户互动的基础,而云计算的动态优化计算资源的配置将是电网调度和控制中心的计算平台基础,当然这需要 EMS 和底层的数据库系统支持分布式的并行计算。而地区变电站将可能面对大量分布式电源的接入的调度问题,这是解决问题的云计算将是优先选择;另一个我关注的领域复杂网络也会是这一趋势下的突出的学科,基于数据分析的复杂网络在更强大的数据处理平台和技术帮助下,将有可能对系统工程产生深远影响。此外,对于学术科研合作, e-Science 和 Science as a Service 的理念和具体实施将改变传统的小范围群体的研究,当然,目前这情况已经在慢慢发生,正如复杂网络这个圈子的成立和壮大,希望后面会越来越好。 More can be found here: Savas: http://savas.me/ Jim Gray : http://research.microsoft.com/en-us/um/people/gray/ Tony Hey : http://www.microsoft.com/presspass/exec/tonyhey/default.aspx 【Book】:The Fourth Paradigm: Data-Intensive Scientific Discovery : http://research.microsoft.com/en-us/collaboration/fourthparadigm/http://research.microsoft.com/en-us/collaboration/fourthparadigm/
JGI-联合基因组研究中心,美国能源部的一个基因组研究中心,也许是世界上最大的非动物基因组测序研究中心了,预计今年其基因组数据量将到达4-5Tb,这样庞大的数据,他们感到已经难以承受数据的存储、分析所需计算设备的压力了,这促使JGI寻求更专业的计算设备维护和管理中心。 从这点来看,以后,测序中心将不会关注数据存储、分析所需要的计算能力,这样的计算能力可以使用别家的计算中心,比如云计算中心。那么测序中心很重要的一点就是如何快速的把测序获得的数据传输到云计算中心上以进行处理。可以预计,随着测序费用的下降,和基因组测序的广泛应用,测序服务中心和云计算中心的合作将会成为一种趋势! JGI Consolidates High-Performance Computing Operations into NERCS April 20, 2010 By Alex Philippidis NEW YORK (GenomeWeb News) – The Joint Genome Institute says the torrent of sequencing data it has generated, and plans to generate this year, explains its decision to consolidate its high-performance scientific computing operations into the US Department of Energy's National Energy Research Scientific Computer Center (NERSC). JGI has agreed to transfer to NERSC six Lawrence Berkeley National Laboratory employees specializing in scientific computing, including computer and network security and instrumentation computer systems. JGI's desktop support services will remain under the control of the institute, which is located in Walnut Creek, Calif. The consolidation, announced April 12, follows JGI's expectation this year that it will multiply the quantity of data it expects to generate through its sequencing of plant, microbe, fungal, and metagenomes. That quantity surpassed 1 terabase, or 1 trillion bases, in 2009, an eight-fold increase over 2008 — with "maybe 4 to 5 trillion this year" expected to be sequenced, JGI spokesman David Gilbert told GenomeWeb Daily News. "In that alone, you can tell why we need that computational horsepower that we could handle on our own, but now it's getting to the point where it's just crazy. Why build something in house when we've got a partnership where all the folks who are, in effect, being transferred over to NERSC? They've been Lawrence Berkeley people anyhow, so it's not a major change from their perspective," Gilbert said. The institute's current data center lacks the capacity to store the exponentially higher amount of data projected, and JGI staff did not have the same breadth of experience with running very large-scale systems that staffers at the computer center have, Jeff Broughton, systems department head at NERSC, told GWDN. Under the consolidation, NERSC will be responsible for existing JGI scientific computing equipment and new equipment to be procured, which will be housed about 16 miles southwest of Walnut Creek, at the computer center's Oakland facility. Broughton said the new equipment will include 500 dual-socket, quad-core Nehalem processor nodes from SGI — of which 160 nodes are in place, with the remaining 340 nodes "expected to arrive within the next six weeks, by the end of May" — as well as a 120 nodes from the IBM iDataPlex system already in use at NERSC's "Magellan" cloud computing cluster, part of a joint research effort between NERSC and the Argonne Leadership Computing Facility, funded with $32 million from the $862 billion American Recovery and Reinvestment Act. "In general, genomics is a pretty good fit for cloud computing, and they were able to take advantage of that," Broughton said. "The new sequencers are producing ever-increasing flows of data, and it's important to make sure that the computational infrastructure scales appropriately to match it," he added. He said NERSC runs "in excess of" 50,000 cores for high-performance computing now, a figure expected to quadruple by the end of the year. JGI would account for about 10 percent of NERSC's total computing power, based on core count. By teaming with NERSC, JGI can enjoy access to a dedicated 10 Gbps-per-second link between both institutions on the Science Data Network of the Energy Sciences Network, as well as other benefits, such as redundant cooling systems, an uninterruptible source of power, environmental and energy-use monitoring, and a central help desk.
最近一直在思考关于social computing 的方面问题,并想把它作为10年后的研究方向和重点,恰巧老板发来一片science上的文章《reCAPTCHA: Human-Based Character Recognition via Web Security Measures》,深感云计算太远,人计算开来更实际。简单介绍一下。 路易斯.凡.安(Luis Von Ahn),卡耐基梅隆(CMU)的研究者,28岁那年,获得麦克阿瑟(MacArthur)天才奖金,或许大家并不熟悉,但他的发明机会所有的网站所有的网民都要引用得到。2000年还是学生的他在导师的指导下,发明了验证码(CAPTCHA)使用机制,就是我们在网站登录时,需要添加的校验码。当初的发明初衷,是防止密码被盗用或者反垃圾邮件(anti-spamming),这项技术发明后短短五年内,每天就有2亿个检验码在被使用,十年之后的今天,几乎所有的网站都采用这个技术来校验用户身份,保证信息安全。 然而Luis Von Ahn并没有在安全认证领域止步,一方面将校验码的模式与程序公布在自己的网站上,供更多的网站使用,另外,Luis进一步拓展这个发明背后的实际上是一门新的学科,叫做Human Computation或者Human-based Computation。有人称之为人本计算或者人计算。即利用网络的分众性和协同性,可以轻易完成很多计算机不可能完成的事情。这门学科正是研究如何把人的这个优势发挥出来,与计算机互动,达到一个最佳结果。当所有的人都在思考如果是计算机替代人的时候,Luis Von Ahn却在想利用互联网,利用社会化的协同工作模式,实现计算机根本不可能完成的事情,以达成群体智能的效果。这就是《科学》上的另一个伟大实现,reCaptchas,与检验码身份验证如出一辙,却是另外一番天地的创造性应用。 《纽约时报》创刊与1851年,158年的历史,作为传统传媒业的需求是简单的,就是想把所有的报纸电子化,对于电子化出版之后的工作相对简单,但过往故纸堆上的文字就显得十分困难,传统OCR的技术不能实现百分之百的准确,如果如果人工录入的方式,整个工作耗时耗力不说,一个字一个字的打印录入,校对,短期内基本上是不可完成的任务。Luis Von Ahn的校验码2005年已经得到了广泛的使用,两者之间有什么联系吗?Luis给出的解决方案,当时互联网上每天有2亿个校验码被使用,虽然每个用户在录入校验码的时候只需要10秒钟,但如果把这些时间全部利用起来,就是20亿秒,相当于50多万个小时。Luis Von Ahn把这些事件利用起来,实现不可想象的伟大实践。现在看来,方法很简单,把扫描的《纽约时报》通过简单的分词形成,然后入库编码,作为校验码的素材提供给用户,用户每一次填注校验码的过程就是对文字的一次录入,通过众多用户的协同,当所有的人都对一个图片给出相同的单词结果时,这个结果就是正确的。无数的用户输入的内容整合链接起来,就是一个完整的数字化的《纽约时报》。 Luis Von Ahn的脚步依然没有停止,通过reCaptchas,他利用人的群体智慧和集体计算的模式,做了很多开创性的事情。他最常用的实现模式就是利用SNS的互动游戏的模式,来实现传统模式识别与计算科学中。他的主要应用成果在 www.gwap.com 上可以体验获得(Game With A Purpose)。 基于内容的图像识别与搜索中,样本的标注是一个很繁琐的问题,为了让计算机内识别图片里的内容,必须要用到许多标注好的图像样本来训练识别核,传统的方式只能通过人工进行大量的手工标准。2006年,Luis推出了一个著名的游戏,叫ESP Game。这一游戏的玩法其实很简单:进入游戏,网站会给你随机配一个伙伴,两人同时看一张图,让你在两分钟内给图片写出关键词,如天空、鸟、足球、奔跑等等。如果你们两人写的关键词一样,就可以得分。通过积分的方式激发用户参与的积极性,网站每天公布得分最高的游戏者,Luis通知这种方式收集的关键字超过了5000万。这个发明已经被谷歌所采用,在谷歌推出的产品Google Image Labeler中,使用的方式就是通过游戏互动的方式来实现图像标注,之后用户谷歌的图片检索引擎。人们在游戏中,已经为科学与商业过程做出来贡献。 Luis一招鲜,吃遍天,他又将这种思想用到了歌曲识别的样本标注上。一首歌曲,听到的人可以在上面进行标注,如摇滚迈克尔杰克逊颤栗这样进行音乐搜索的时候,标注的人越多,搜索识别结果越精确。之后的游戏还有用于计算机视觉的Squigl(涂鸦)的游戏,还有用于收集语言网语料的Verbosity(唠叨)的游戏。Luis在他的研究中总结了三种常见的GWAP方式: Output-agreement games. Inversion-problem games. Input-agreement games. 这三种方式,都是通过互动游戏的方式,利用协同计算或者人本计算的模式,解决了计算机不可能准确实现的问题。Luis Von Ahn利用人擅长做而计算机不擅长的能力,并通过游戏把这方面的资源尽可能开发收集起来,服务与科学过程。 当我们都在考虑云计算的时候,基于人的互动协同计算其实离我们很近,每天的校验码的登录填注,百度知道与维基网的点击阅读我们可能都在不知不觉中,贡献了自己的力量。 附: 对我们的启示: 1、 自由的、不受束缚的思想更容易产生创新的智慧。看似废话,如果Luis Von Ahn接受了老师的安排,只停留在校验码的安全机制研究上,就不可能产生今天的人本计算(Human Computation)。如果瓦茨(小世界理论的发现者)只是授意与导师,研究昆虫共鸣的理论,没有与人类社会对应,就不会有今天的小世界模型。 2、 科学需要开放的胸怀,互联网的本质就是回归人原始本性的共享与开放。Luis Von Ahn将校验码的研究成果与源码在自己的网站上与人共享,也是今天所有的网站都在使用校验码模式的原因。倘若当初,Luis Von Ahn通过专利控制这项技术的扩散与使用,估计今天他也就是一篇学术论文而已。 3、 科研与实践需要持续积累。Luis Von Ahn在2000年开始做检验码方面的研究与实践,并在之后提出Human Computation的概念。之后的9年里,他将这种思想与理论应用到了极致,从文本识别,图像内容识别,语音识别,语义网等传统模式识别与机器学习领域,都有他的尝试。实践积累非一日之功,虽然没有复杂的公式推导与理论,但利用互联网的大量实践工作也同样证明了协同计算与演进式学习的有效性。 4、 结合中国的实践还有哪些应用。中国是人口大国,拥有最多的互联网用户与手机上网用户,这些人口资源与上网资源如何有效的利用与收集起来,服务科学上的突破,将会是中国学者需要深入思考和探讨的。比如淘宝网上将会有世界上最大的商品图片库与用户商品标注信息,这些信息将用于商品搜索;维基网与百度知道上有最全面的常识与词语解释,这个将成为语义网学习的语料,而这个语料是通过协同工作的方式,保证了语料的准确性和有效性。抛砖引玉,从事机器学习、模式识别、数据挖掘、web搜索的学者可以沿着这条思路,看看还有哪些需要人与机器互动来实现的过程。 转载自( http://blog.sina.com.cn/s/blog_5e718bc90100g6ei.html )
十一月二至四日,美国第二届云计算与虚拟化会议及产品展示(Cloud Computing and Virtulization Conference and Expo) 在硅谷腹地的Santa Clara举行。 在与互联网相关的技术中,云计算和虚拟化是最近几年炒得比较热的概念。云计算不同于许多搞科学的人熟悉的网格计算(Grid Computing),虽然网格计算也被列为云计算的一个方面。云计算也许是互联网技术发展到商品化后的自然演化,如同工业化初期,工业生产从家庭作坊向工厂化,专业化,大规模生产的方向发展和集中。 云计算的中心概念是 *aaS (everything as a service), 即把与IT有关的许多技术,如电子邮件,资料存储,网站服务等等,由集中化,专业化的服务商通过互联网以订购的方式提供给企业或个人,就像你现在每月付电费水费使用水电一样。 在计算机和互联网技术诞生后的这些年,人们在使用计算机和互连网的方式上也在慢慢地改变。人们最早熟悉的方式是购买硬件,安装软件,并不断地更新。大小企业都有一个IT部门,负责企业内部的电邮,网站,资料共享等服务器的硬件设备和软件产品的安装,维护和升级等等。这就有点像工业化初期的家庭作坊:许许多多的IT工程师在不同的公司中做着大体上相似的事情,服务于各自的内部部门。 这两年的经济下滑在某种程度上促进了云计算概念的发展。经济低迷迫使企业寻找降低成本的方式,设法把越来越多的工作外包到劳动力成本更低的地方去做。大规模集中化带来的低成本就给企业接受云计算的概念提供了动力。 从另一方面看,互联网的相关技术经过几十年的发展已逐渐成熟。比如电子邮件技术早已经社会化。我们使用了多年的公共邮箱,如雅虎,gmail,用的就是SaaS的概念。同时,虚拟技术的出现使得集成化和低成本成为可能。 现在,云计算*aaS的概念包括三个方面: IaaS (Infrastructure as a service) 作为服务的架构 Paas (Platform as a service) 作为服务的平台 SaaS (Software as a service) 作为服务的软件 其中,IaaS和PaaS多是针对于企事业用户,SaaS的概念更为广泛。我们每天使用的雅虎电邮,谷歌搜索,都是SaaS。这种将IT的硬软件资源,以及有关的服务以订购方式提供给用户,对用户来讲是一种极大的简化。用户企业不必付出一次性的投资来买硬软件设备,甚至不必再设IT部门,只需要与专业的提供商签订服务协议(SLA, 既 Service Level Agreement), 定期交服务费就可以了。这给中小企业的发展降低了成本,带来了很大的灵活性。现在,Amazon EC2 已经有了最大的出租虚拟服务器的业务,Google Apps 向小企业和非盈利的院校提供免费的网站和邮件服务,许多网络安全公司也已开始提供基于SaaS的邮件和网页过滤服务。 从社会效益来说,IT服务专业化集中化能降低总体成本,使数据中心的服务器能够最充分的使用。因此,人们还喜欢在云计算之前加上一个绿色的定语。可是在实现的过程中,还有许多问题需要解决。 对于企业用户,接受云计算概念的第一个障碍就是关于安全性的问题。从传统的IT到云计算,从数据安全的角度看,最大的变化就是要把自己的数据交给运营商来管理。怎样才能保障保密数据在储存和传递过程中的安全性?怎样才能保障只有据有合法授权的人才能看到和更改数据?如果出了同安全性有关的问题,其中的法律问题应该怎么处理?这些现在还没有很好的解决办法。于是,对安全性要求高的大企业,银行,医疗部门,和政府机构等,又提出了私有云(Private Cloud)的概念--这些云计算的服务商不是面向全社会,而是服务设备和服务对象都限制在一个大企业内部。
一 云计算定义 云计算是一个提供便捷的通过互联网访问一个可定制的IT资源共享池能力的按使用量付费模式(IT资源包括网络,服务器,存储,应用,服务),这些资源能够快速部署,并只需要很少的管理工作或很少的与服务供应商的交互。云计算提高了可用性,由五个主要特点,三个交付模式 ,和四个部署模式组成。 二 主要特点 按需自助服务。消费者可以单方面部署资源,如服务器和网络存储,资源时按需部署而不需要服务供应商进行人工交互。 通过互联网获取。资源可以通过互联网获取, 并可以通过标准方式访问,以通过瘦客户端或富客户端推广使(例如移动电话,笔记本电脑,PDA)等。 独立于地点的资源池。供应商的资源被池化,以便以多用户租用模式被所有客户使用,同时不同的物理和虚拟资源可根据客户需求动态分配和重新分配。客户一般无法控制或知道资源的确切位置。这些资源包括存储、处理器、内存、网络带宽和虚拟机器。 快速伸缩。资源可以迅速和弹性地部署,以便快速扩展和快速释放。对客户来说,可以获取的资源看起来似乎是无限的,并且可在任何时间购买任何数量的资源。 按使用付费。对资源的收费是基于计量的一次一付,或基于广告的收费模式,以促进资源的优化利用。比如计量存储,带宽和计算资源的消耗,按月根据用户实际使用收费。在一个组织内的云可以在部门之间计算费用,但不一定使用时机货币。 注:云计算软件通过着重于无国界、低耦合、模块化和语义互操作性的面向服务来充分利用云计算模式的优势。 三 交付模式 云计算软件即服务。提供给客户的服务是服务商运行在云计算基础设施上的应用程序,可以在各种客户端设备上通过瘦客户端界面访问,比如浏览器。消费者不需要管理或控制的底层的云计算基础设施,包括网络、服务器、操作系统、存储,甚至单个应用程序的功能,可能的例外就是需要设置一些有限的客户可定制的配置设置。 云计算平台即服务。提供给消费者的是将客户用供应商提供的开发语言和工具(例如Java,python,.Net)创建的应用程序部署到云计算基础设施上去。客户不需要管理或控制的底层的云基础设施,包括网络、服务器、操作系统、存储,但消费者能控制部署的应用程序,也可能控制应用的托管环境配置。 云基础设施即服务。提供给消费者的是出租处理能力、存储、网络和其它基本的计算资源,用户能够部署和运行任意软件,包括操作系统和应用程序。消费者不管理或控制的底层的云计算基础设施,但能控制操作系统、储存、部署的应用,也有可能选择网络组件(例如,防火墙,负载均衡器)。 四 部署模式 私有云。云基础设施是被一个单一的组织拥有或租用,该基础设施完全该组织管理。 社区云。基础设施被一些组织共享,并为一个有共同关注点的社区服务(例如,任务,安全要求,政策和遵守的考虑)。 公共云。基础设施是被一个销售云计算服务的组织所拥有,该组织将云计算服务销售给一般大众或广泛的工业群体。 混合云。基础设施是由两种或两种以上的云(私有,社区或公共)组成,每种云仍然保持独立,但用标准的或专有的技术将它们组合起来,具有数据和应用程序的可移植性(例如,可以用来处理突发负载)。 每个部署模型实例有两种类型:内部或外部。内部云存在于组织的网络安全边界之内,外部云存在于网络安全边界之外。 原文: Peter Mell and Tim Grance -- National Institute of Standards and Technology, Information Technology Laboratory Note 1: Cloud computing is still an evolving paradigm. Its definitions, use cases, underlying technologies, issues, risks, and benefits will be refined in a spirited debate by the public and private sectors. These definitions, attributes, and characteristics will evolve and change over time. Note 2: The cloud computing industry represents a large ecosystem of many models, vendors, and market niches. This definition attempts to encompass all of the various cloud approaches. Definition of Cloud Computing: Cloud computing is a pay-per-use model for enabling available, convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, services) that can be rapidly provisioned and released with minimal management effort or service provider interaction. This cloud model promotes availability and is comprised of five key characteristics, three delivery models, and four deployment models. Key Characteristics: On-demand self-service. A consumer can unilaterally provision computing capabilities, such as server time and network storage, as needed without requiring human interaction with each services provider. Ubiquitous network access. Capabilities are available over the network and accessed through standard mechanisms that promote use by heterogeneous thin or thick client platforms (e.g., mobile phones, laptops, and PDAs). Location independent resource pooling. The providers computing resources are pooled to serve all consumers using a multi-tenant model, with different physical and virtual resources dynamically assigned and reassigned according to consumer demand. The customer generally has no control or knowledge over the exact location of the provided resources. Examples of resources include storage, processing, memory, network bandwidth, and virtual machines. Rapid elasticity. Capabilities can be rapidly and elastically provisioned to quickly scale up and rapidly released to quickly scale down. To the consumer, the capabilities available for rent often appear to be infinite and can be purchased in any quantity at any time. Pay per use. Capabilities are charged using a metered, fee-for-service, or advertising based billing model to promote optimization of resource use. Examples are measuring the storage, bandwidth, and computing resources consumed and charging for the number of active user accounts per month. Clouds within an organization accrue cost between business units and may or may not use actual currency. Note: Cloud software takes full advantage of the cloud paradigm by being service oriented with a focus on statelessness, low coupling, modularity, and semantic interoperability. Delivery Models: Cloud Software as a Service (SaaS). The capability provided to the consumer is to use the providers applications running on a cloud infrastructure and accessible from various client devices through a thin client interface such as a Web browser (e.g., web-based email). The consumer does not manage or control the underlying cloud infrastructure, network, servers, operating systems, storage, or even individual application capabilities, with the possible exception of limited user-specific application configuration settings. Cloud Platform as a Service (PaaS). The capability provided to the consumer is to deploy onto the cloud infrastructure consumer-created applications using programming languages and tools supported by the provider (e.g., java, python, .Net). The consumer does not manage or control the underlying cloud infrastructure, network, servers, operating systems, or storage, but the consumer has control over the deployed applications and possibly application hosting environment configurations. Cloud Infrastructure as a Service (IaaS). The capability provided to the consumer is to rent processing, storage, networks, and other fundamental computing resources where the consumer is able to deploy and run arbitrary software, which can include operating systems and applications. The consumer does not manage or control the underlying cloud infrastructure but has control over operating systems, storage, deployed applications, and possibly select networking components (e.g., firewalls, load balancers). Deployment Models: Private cloud. The cloud infrastructure is owned or leased by a single organization and is operated solely for that organization. Community cloud. The cloud infrastructure is shared by several organizations and supports a specific community that has shared concerns (e.g., mission, security requirements, policy, and compliance considerations). Public cloud. The cloud infrastructure is owned by an organization selling cloud services to the general public or to a large industry group. Hybrid cloud. The cloud infrastructure is a composition of two or more clouds (internal, community, or public) that remain unique entities but are bound together by standardized or proprietary technology that enables data and application portability (e.g., cloud bursting). Each deployment model instance has one of two types: internal or external. Internal clouds reside within an organizations network security perimeter and external clouds reside outside the same perimeter.
维基百科(Wikipedia.org)对云计算的定义: 云计算是分布式计算技术的一种,其最基本的概念,是通过网络将庞大的计算处理程序自动分拆成无数个较小的子程序,再交由多部服务器所组成的庞大系统进行搜寻和计算分析,最后将处理结果回传给用户.通过这项技术,网络服务提供者可以在数秒内,处理数以千万计甚至亿计的信息,达到和超级计算机同样强大效能的网络服务. 加州大学伯克利分校(University of California at Berkeley)的Michael Armbrust等对云计算的定义: 云计算包括互联网上各种服务形式的应用以及这些服务所依托数据中心的软硬件设施,这些应用服务一直被称作软件即服务(SaaS),而数据中心的软硬件设施就是所谓的云, 云计算就是SaaS和效用计算.云分为公共云(Public Cloud)和私有云(Private Cloud). 云计算(Cloud computing)是一种基于互联网的超级计算模式,其原理非常类似于网格计算.它是把存储在大量分布式计算机产品中的大量数据和处理器资源整合在一起协同工作.作为一种新兴的共享基础架构的方法,它可以将巨大的系统池连接在一起以提供各种IT 服务.这使得企业能够将资源切换到需要的应用上,根据需求访问计算机和存储系统. 云安全联盟(Cloud Security Alliance, CSA)的研究报告提出的SPI模型(SPI Model)把云计算的服务形式分为基础架构即服务(Infrastructure as a Service,IaaS),平台即服务(Platform as a Service,PaaS)和软件即服务(Software as a Service,SaaS)三大类。开放云宣言组织(Open Cloud Manifesto)则根据研究的需要把云计算细分成终端用户―云、企业―云―终端用户、企业―云(综合)、企业―云―企业、企业―云(便携式)、私有(内部)云等6种模式。 作为网络时代的新计算形式,云计算是以数据、用户和服务为三大中心为导向的.在功能方面,真正的云计算平台应该能具备以下三方面的功能特性. ⑴提供资源――包括计算、存储及网络资源,需要服务提供者架设出规模巨大的全球化的数据库及存储中心,能够实现海量的存储、出色的安全性和高度的隐私性和可靠性.此外,它还应是高效的、低价的、节省能源的. ⑵提供动态的数据服务――包括原始数据、半结构化数据和经过处理的结构化数据,一个优秀的云计算架构一定要有提供大规模数据存储、分享、管理、挖掘、搜索、分析和服务的智能. ⑶提供云计算平台――包括软件开发API、环境和工具.云计算需要真正形成一个有生命力、有黏性、可持续发展的生态系统.
信息来源于: http://en.wikipedia.org/wiki/Cloud_computing Cloud computing is a style of computing in which dynamically scalable and often virtualized resources are provided as a service over the Internet. Users need not have knowledge of, expertise in, or control over the technology infrastructure in the cloud that supports them. The concept incorporates infrastructure as a service (IaaS), platform as a service (PaaS) and software as a service (SaaS) as well as other recent (ca. 20072009) technology trends that have the common theme of reliance on the Internet for satisfying the computing needs of the users. Cloud computing services usually provide common business applications online that are accessed from a web browser , while the software and data are stored on the servers. The term cloud is used as a metaphor for the Internet, based on how the Internet is depicted in computer network diagrams , and is an abstraction for the complex infrastructure it conceals. 1 Brief 1.1 Comparisons 1.2 Characteristics 1.3 Economics 1.4 Companies 1.5 Architecture 2 History 3 Vendor lock-in concerns 4 Political issues 5 Legal issues 6 Risk mitigation 7 Key characteristics 8 Components 8.1 Application 8.2 Client 8.3 Infrastructure 8.4 Platform 8.5 Service 8.6 Storage 9 Architecture 10 Types 10.1 Public cloud 10.2 Hybrid cloud 10.3 Private cloud 11 Roles 11.1 Provider 11.2 User 11.3 Vendor 12 Standards 13 See also 14 References 15 External links
 标签: 云计算
标签: 云计算



![[转载]ArcGIS for Server 10.1智能支持云的架构](http://image.sciencenet.cn/album/201112/28/0818021l3fo1fcfcfrlmcr.jpg.thumb.jpg)

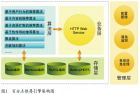

![[转载]云计算让每个单位以及个人都能以低成本接触到顶尖 IT 技术](http://image.sciencenet.cn/album/201106/28/103018urim464rmy9y6913.jpg.thumb.jpg)




![[转载]点评未来十大战略信息技术:云计算最令人期待](http://image.sciencenet.cn/album/201105/29/231409mynfjxjgsrx1n7zn.jpg.thumb.jpg)