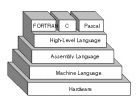
http://www.webopedia.com/TERM/A/assembly_language.html Programming language Last updated 1 day ago From Wikipedia, the free encyclopedia Jump to: navigation , search Programming language lists Alphabetical Categorical Chronological Generational v · t · e A programming language is an artificial language designed to communicate instructions to a machine , particularly a computer . Programming languages can be used to create programs that control the behavior of a machine and/or to express algorithms precise ly . The earliest programming languages predate the invention of the computer , and were used to direct the behavior of machines such as Jacquard looms and player pianos . Thousands of different programming languages have been created , mainly in the computer field, with many more being created every year. Most programming languages describe computation in an imperative style, i.e., as a sequence of commands , although some languages , such as those that support functional programming or logic programming , use alternative forms of description . The description of a programming language is usually split into the two components of syntax (form) and semantics (meaning). Some languages are defined by a specification document (for example, the C programming language is specified by an ISO Standard), while other languages, such as Perl 5 and earlier, have a dominant implementation that is used as a reference . Contents 1 Definitions 2 Elements 2.1 Syntax 2.2 Semantics 2.2.1 Static semantics 2.2.2 Dynamic semantics 2.2.3 Type system 2.2.3.1 Typed versus untyped languages 2.2.3.2 Static versus dynamic typing 2.2.3.3 Weak and strong typing 2.3 Standard library and run-time system 3 Design and implementation 3.1 Specification 3.2 Implementation 4 Usage 4.1 Measuring language usage 5 Taxonomies 6 History 6.1 Early developments 6.2 Refinement 6.3 Consolidation and growth 7 See also 8 References 9 Further reading 10 External links Definitions A programming language is a notation for writing programs , which are specifications of a computation or algorithm . Some, but not all, authors re strict the term "programming language" to those languages that can express all possible algorithms. Traits often considered important for what constitutes a programming language include: Function and target : A computer programming language is a language used to write computer programs , which involve a computer performing some kind of computation or algorithm and possibly control external devices such as printers , disk drives , robots , and so on. For example PostScript programs are frequently created by another program to control a computer printer or display. More generally, a programming language may describe computation on some, possibly abstract, machine. It is generally accepted that a complete specification for a programming language includes a description, possibly idealized, of a machine or processor for that language. In most practical contexts, a programming language involves a computer; consequently, programming languages are usually defined and studied this way. Programming languages differ from natural languages in that natural languages are only used for interaction between people, while programming languages also allow humans to communicate instructions to machines. Abstractions : Programming languages usually contain abstractions for defining and manipulating data structures or controlling the flow of execution . The practical necessity that a programming language support adequate abstractions is expressed by the abstraction principle ; this principle is sometimes formulated as recommendation to the programmer to make proper use of such abstractions. Expressive power : The theory of computation classifies languages by the computations they are capable of expressing. All Turing complete languages can implement the same set of algorithms . ANSI/ISO SQL and Charity are examples of languages that are not Turing complete, yet often called programming languages. Markup languages like XML , HTML or troff , which define structured data , are not generally considered programming languages. Programming languages may, however, share the syntax with markup languages if a computational semantics is defined. XSLT , for example, is a Turing complete XML dialect. Moreover, LaTeX , which is mostly used for structuring documents, also contains a Turing complete subset. The term computer language is sometimes used interchangeably with programming language. However, the usage of both terms varies among authors, including the exact scope of each. One usage describes programming languages as a subset of computer languages. In this vein, languages used in computing that have a different goal than expressing computer programs are generically designated computer languages. For instance, markup languages are sometimes referred to as computer languages to emphasize that they are not meant to be used for programming. Another usage regards programming languages as theoretical constructs for programming abstract machines, and computer languages as the subset thereof that runs on physical computers, which have finite hardware resources. John C. Reynolds emphasizes that formal specification languages are just as much programming languages as are the languages intended for execution. He also argues that textual and even graphical input formats that affect the behavior of a computer are programming languages, despite the fact they are commonly not Turing-complete, and remarks that ignorance of programming language concepts is the reason for many flaws in input formats. Elements All programming languages have some primitive building blocks for the description of data and the processes or transformations applied to them (like the addition of two numbers or the selection of an item from a collection). These primitives are defined by syntactic and semantic rules which describe their structure and meaning respectively. Syntax Parse tree of Python code with inset tokenization Syntax highlighting is often used to aid programmers in recognizing elements of source code. The language above is Python . Main article: Syntax (programming languages) A programming language's surface form is known as its syntax . Most programming languages are purely textual; they use sequences of text including words, numbers, and punctuation, much like written natural languages. On the other hand, there are some programming languages which are more graphical in nature, using visual relationships between symbols to specify a program. The syntax of a language describes the possible combinations of symbols that form a syntactically correct program. The meaning given to a combination of symbols is handled by semantics (either formal or hard-coded in a reference implementation ). Since most languages are textual, this article discusses textual syntax. Programming language syntax is usually defined using a combination of regular expressions (for lexical structure) and Backus–Naur Form (for grammatical structure). Below is a simple grammar, based on Lisp : expression ::= atom | list atom ::= number | symbol number ::= ? + symbol ::= .* list ::= '(' expression* ')' This grammar specifies the following: an expression is either an atom or a list ; an atom is either a number or a symbol ; a number is an unbroken sequence of one or more decimal digits, optionally preceded by a plus or minus sign; a symbol is a letter followed by zero or more of any characters (excluding whitespace); and a list is a matched pair of parentheses, with zero or more expressions inside it. The following are examples of well-formed token sequences in this grammar: '12345', '()', '(a b c232 (1))' Not all syntactically correct programs are semantically correct. Many syntactically correct programs are nonetheless ill-formed, per the language's rules; and may (depending on the language specification and the soundness of the implementation) result in an error on translation or execution. In some cases, such programs may exhibit undefined behavior . Even when a program is well-defined within a language, it may still have a meaning that is not intended by the person who wrote it. Using natural language as an example, it may not be possible to assign a meaning to a grammatically correct sentence or the sentence may be false: " Colorless green ideas sleep furiously ." is grammatically well-formed but has no generally accepted meaning. "John is a married bachelor." is grammatically well-formed but expresses a meaning that cannot be true. The following C language fragment is syntactically correct, but performs operations that are not semantically defined (the operation *p 4 has no meaning for a value having a complex type and p-im is not defined because the value of p is the null pointer ): complex * p = NULL ; complex abs_p = sqrt ( * p 4 + p - im ) ; If the type declaration on the first line were omitted, the program would trigger an error on compilation, as the variable "p" would not be defined. But the program would still be syntactically correct, since type declarations provide only semantic information. The grammar needed to specify a programming language can be classified by its position in the Chomsky hierarchy . The syntax of most programming languages can be specified using a Type-2 grammar, i.e., they are context-free grammars . Some languages, including Perl and Lisp, contain constructs that allow execution during the parsing phase. Languages that have constructs that allow the programmer to alter the behavior of the parser make syntax analysis an undecidable problem , and generally blur the distinction between parsing and execution. In contrast to Lisp's macro system and Perl's BEGIN blocks, which may contain general computations, C macros are merely string replacements, and do not require code execution. Semantics The term Semantics refers to the meaning of languages, as opposed to their form ( syntax ). Static semantics The static semantics defines restrictions on the structure of valid texts that are hard or impossible to express in standard syntactic formalisms. For compiled languages, static semantics essentially include those semantic rules that can be checked at compile time. Examples include checking that every identifier is declared before it is used (in languages that require such declarations) or that the labels on the arms of a case statement are distinct. Many important restrictions of this type, like checking that identifiers are used in the appropriate context (e.g. not adding an integer to a function name), or that subroutine calls have the appropriate number and type of arguments, can be enforced by defining them as rules in a logic called a type system . Other forms of static analyses like data flow analysis may also be part of static semantics. Newer programming languages like Java and C# have definite assignment analysis , a form of data flow analysis, as part of their static semantics. Dynamic semantics Main article: Semantics of programming languages Once data has been specified, the machine must be instructed to perform operations on the data. For example, the semantics may define the strategy by which expressions are evaluated to values, or the manner in which control structures conditionally execute statements . The dynamic semantics (also known as execution semantics ) of a language defines how and when the various constructs of a language should produce a program behavior. There are many ways of defining execution semantics. Natural language is often used to specify the execution semantics of languages commonly used in practice. A significant amount of academic research went into formal semantics of programming languages , which allow execution semantics to be specified in a formal manner. Results from this field of research have seen limited application to programming language design and implementation outside academia. Type system Main articles: Data type , Type system , and Type safety A type system defines how a programming language classifies values and expressions into types , how it can manipulate those types and how they interact. The goal of a type system is to verify and usually enforce a certain level of correctness in programs written in that language by detecting certain incorrect operations. Any decidable type system involves a trade-off: while it rejects many incorrect programs, it can also prohibit some correct, albeit unusual programs. In order to bypass this downside, a number of languages have type loopholes , usually unchecked casts that may be used by the programmer to explicitly allow a normally disallowed operation between different types. In most typed languages, the type system is used only to type check programs, but a number of languages, usually functional ones, infer types , relieving the programmer from the need to write type annotations. The formal design and study of type systems is known as type theory . Typed versus untyped languages A language is typed if the specification of every operation defines types of data to which the operation is applicable, with the implication that it is not applicable to other types. For example, the data represented by "this text between the quotes" is a string . In most programming languages, dividing a number by a string has no meaning. Most modern programming languages will therefore reject any program attempting to perform such an operation. In some languages, the meaningless operation will be detected when the program is compiled ("static" type checking), and rejected by the compiler, while in others, it will be detected when the program is run ("dynamic" type checking), resulting in a runtime exception . A special case of typed languages are the single-type languages. These are often scripting or markup languages, such as REXX or SGML , and have only one data type—most commonly character strings which are used for both symbolic and numeric data. In contrast, an untyped language , such as most assembly languages , allows any operation to be performed on any data, which are generally considered to be sequences of bits of various lengths. High-level languages which are untyped include BCPL and some varieties of Forth . In practice, while few languages are considered typed from the point of view of type theory (verifying or rejecting all operations), most modern languages offer a degree of typing. Many production languages provide means to bypass or subvert the type system (see casting ). Static versus dynamic typing In static typing , all expressions have their types determined prior to when the program is executed, typically at compile-time. For example, 1 and (2+2) are integer expressions; they cannot be passed to a function that expects a string, or stored in a variable that is defined to hold dates. Statically typed languages can be either manifestly typed or type-inferred . In the first case, the programmer must explicitly write types at certain textual positions (for example, at variable declarations ). In the second case, the compiler infers the types of expressions and declarations based on context. Most mainstream statically typed languages, such as C++ , C# and Java , are manifestly typed. Complete type inference has traditionally been associated with less mainstream languages, such as Haskell and ML . However, many manifestly typed languages support partial type inference; for example, Java and C# both infer types in certain limited cases. Dynamic typing , also called latent typing , determines the type-safety of operations at runtime; in other words, types are associated with runtime values rather than textual expressions . As with type-inferred languages, dynamically typed languages do not require the programmer to write explicit type annotations on expressions. Among other things, this may permit a single variable to refer to values of different types at different points in the program execution. However, type errors cannot be automatically detected until a piece of code is actually executed, potentially making debugging more difficult. Lisp , Perl , Python , JavaScript , and Ruby are dynamically typed. Weak and strong typing Weak typing allows a value of one type to be treated as another, for example treating a string as a number. This can occasionally be useful, but it can also allow some kinds of program faults to go undetected at compile time and even at run-time . Strong typing prevents the above. An attempt to perform an operation on the wrong type of value raises an error. Strongly typed languages are often termed type-safe or safe . An alternative definition for "weakly typed" refers to languages, such as Perl and JavaScript , which permit a large number of implicit type conversions. In JavaScript, for example, the expression 2 * x implicitly converts x to a number, and this conversion succeeds even if x is null, undefined, an Array, or a string of letters. Such implicit conversions are often useful, but they can mask programming errors. Strong and static are now generally considered orthogonal concepts, but usage in the literature differs. Some use the term strongly typed to mean strongly, statically typed , or, even more confusingly, to mean simply statically typed . Thus C has been called both strongly typed and weakly, statically typed. Standard library and run-time system Main article: Standard library Most programming languages have an associated core library (sometimes known as the 'standard library', especially if it is included as part of the published language standard), which is conventionally made available by all implementations of the language. Core libraries typically include definitions for commonly used algorithms, data structures, and mechanisms for input and output. A language's core library is often treated as part of the language by its users, although the designers may have treated it as a separate entity. Many language specifications define a core that must be made available in all implementations, and in the case of standardized languages this core library may be required. The line between a language and its core library therefore differs from language to language. Indeed, some languages are designed so that the meanings of certain syntactic constructs cannot even be described without referring to the core library. For example, in Java , a string literal is defined as an instance of the java.lang.String class; similarly, in Smalltalk , an anonymous function expression (a "block") constructs an instance of the library's BlockContext class. Conversely, Scheme contains multiple coherent subsets that suffice to construct the rest of the language as library macros, and so the language designers do not even bother to say which portions of the language must be implemented as language constructs, and which must be implemented as parts of a library. Design and implementation Programming languages share properties with natural languages related to their purpose as vehicles for communication, having a syntactic form separate from its semantics, and showing language families of related languages branching one from another. But as artificial constructs, they also differ in fundamental ways from languages that have evolved through usage. A significant difference is that a programming language can be fully described and studied in its entirety, since it has a precise and finite definition. By contrast, natural languages have changing meanings given by their users in different communities. While constructed languages are also artificial languages designed from the ground up with a specific purpose, they lack the precise and complete semantic definition that a programming language has. Many programming languages have been designed from scratch, altered to meet new needs, and combined with other languages. Many have eventually fallen into disuse. Although there have been attempts to design one "universal" programming language that serves all purposes, all of them have failed to be generally accepted as filling this role. The need for diverse programming languages arises from the diversity of contexts in which languages are used: Programs range from tiny scripts written by individual hobbyists to huge systems written by hundreds of programmers . Programmers range in expertise from novices who need simplicity above all else, to experts who may be comfortable with considerable complexity. Programs must balance speed, size, and simplicity on systems ranging from microcontrollers to supercomputers . Programs may be written once and not change for generations, or they may undergo continual modification. Finally, programmers may simply differ in their tastes: they may be accustomed to discussing problems and expressing them in a particular language. One common trend in the development of programming languages has been to add more ability to solve problems using a higher level of abstraction . The earliest programming languages were tied very closely to the underlying hardware of the computer. As new programming languages have developed, features have been added that let programmers express ideas that are more remote from simple translation into underlying hardware instructions. Because programmers are less tied to the complexity of the computer, their programs can do more computing with less effort from the programmer. This lets them write more functionality per time unit. Natural language processors have been proposed as a way to eliminate the need for a specialized language for programming. However, this goal remains distant and its benefits are open to debate. Edsger W. Dijkstra took the position that the use of a formal language is essential to prevent the introduction of meaningless constructs, and dismissed natural language programming as "foolish". Alan Perlis was similarly dismissive of the idea. Hybrid approaches have been taken in Structured English and SQL . A language's designers and users must construct a number of artifacts that govern and enable the practice of programming. The most important of these artifacts are the language specification and implementation . Specification Main article: Programming language specification The specification of a programming language is intended to provide a definition that the language users and the implementors can use to determine whether the behavior of a program is correct, given its source code . A programming language specification can take several forms, including the following: An explicit definition of the syntax, static semantics, and execution semantics of the language. While syntax is commonly specified using a formal grammar, semantic definitions may be written in natural language (e.g., as in the C language ), or a formal semantics (e.g., as in Standard ML and Scheme specifications). A description of the behavior of a translator for the language (e.g., the C++ and Fortran specifications). The syntax and semantics of the language have to be inferred from this description, which may be written in natural or a formal language. A reference or model implementation , sometimes written in the language being specified (e.g., Prolog or ANSI REXX ). The syntax and semantics of the language are explicit in the behavior of the reference implementation. Implementation Main article: Programming language implementation An implementation of a programming language provides a way to execute that program on one or more configurations of hardware and software. There are, broadly, two approaches to programming language implementation: compilation and interpretation . It is generally possible to implement a language using either technique. The output of a compiler may be executed by hardware or a program called an interpreter. In some implementations that make use of the interpreter approach there is no distinct boundary between compiling and interpreting. For instance, some implementations of BASIC compile and then execute the source a line at a time. Programs that are executed directly on the hardware usually run several orders of magnitude faster than those that are interpreted in software. One technique for improving the performance of interpreted programs is just-in-time compilation . Here the virtual machine , just before execution, translates the blocks of bytecode which are going to be used to machine code, for direct execution on the hardware. Usage Thousands of different programming languages have been created, mainly in the computing field. Programming languages differ from most other forms of human expression in that they require a greater degree of precision and completeness. When using a natural language to communicate with other people, human authors and speakers can be ambiguous and make small errors, and still expect their intent to be understood. However, figuratively speaking, computers "do exactly what they are told to do", and cannot "understand" what code the programmer intended to write. The combination of the language definition, a program, and the program's inputs must fully specify the external behavior that occurs when the program is executed, within the domain of control of that program. On the other hand, ideas about an algorithm can be communicated to humans without the precision required for execution by using pseudocode , which interleaves natural language with code written in a programming language. A programming language provides a structured mechanism for defining pieces of data, and the operations or transformations that may be carried out automatically on that data. A programmer uses the abstractions present in the language to represent the concepts involved in a computation. These concepts are represented as a collection of the simplest elements available (called primitives ). Programming is the process by which programmers combine these primitives to compose new programs, or adapt existing ones to new uses or a changing environment. Programs for a computer might be executed in a batch process without human interaction, or a user might type commands in an interactive session of an interpreter . In this case the "commands" are simply programs, whose execution is chained together. When a language is used to give commands to a software application (such as a shell ) it is called a scripting language . Measuring language usage Main article: Measuring programming language popularity It is difficult to determine which programming languages are most widely used, and what usage means varies by context. One language may occupy the greater number of programmer hours, a different one have more lines of code, and a third utilize the most CPU time. Some languages are very popular for particular kinds of applications. For example, COBOL is still strong in the corporate data center, often on large mainframes ; Fortran in scientific and engineering applications; and C in embedded applications and operating systems. Other languages are regularly used to write many different kinds of applications. Various methods of measuring language popularity, each subject to a different bias over what is measured, have been proposed: counting the number of job advertisements that mention the language the number of books sold that teach or describe the language estimates of the number of existing lines of code written in the language—which may underestimate languages not often found in public searches counts of language references (i.e., to the name of the language) found using a web search engine. Combining and averaging information from various internet sites, langpop.com claims that in 2008 the 10 most cited programming languages are (in alphabetical order): C , C++ , C# , Java , JavaScript , Perl , PHP , Python , Ruby , and SQL . Taxonomies For more details on this topic, see Categorical list of programming languages . There is no overarching classification scheme for programming languages. A given programming language does not usually have a single ancestor language. Languages commonly arise by combining the elements of several predecessor languages with new ideas in circulation at the time. Ideas that originate in one language will diffuse throughout a family of related languages, and then leap suddenly across familial gaps to appear in an entirely different family. The task is further complicated by the fact that languages can be classified along multiple axes. For example, Java is both an object-oriented language (because it encourages object-oriented organization) and a concurrent language (because it contains built-in constructs for running multiple threads in parallel). Python is an object-oriented scripting language . In broad strokes, programming languages divide into programming paradigms and a classification by intended domain of use . Traditionally, programming languages have been regarded as describing computation in terms of imperative sentences, i.e. issuing commands. These are generally called imperative programming languages. A great deal of research in programming languages has been aimed at blurring the distinction between a program as a set of instructions and a program as an assertion about the desired answer, which is the main feature of declarative programming . More refined paradigms include procedural programming , object-oriented programming , functional programming , and logic programming ; some languages are hybrids of paradigms or multi-paradigmatic. An assembly language is not so much a paradigm as a direct model of an underlying machine architecture. By purpose, programming languages might be considered general purpose, system programming languages, scripting languages, domain-specific languages, or concurrent/distributed languages (or a combination of these). Some general purpose languages were designed largely with educational goals. A programming language may also be classified by factors unrelated to programming paradigm. For instance, most programming languages use English language keywords, while a minority do not . Other languages may be classified as being deliberately esoteric or not. History A selection of textbooks that teach programming, in languages both popular and obscure. These are only a few of the thousands of programming languages and dialects that have been designed in history. Main articles: History of programming languages and Programming language generations Early developments The first programming languages predate the modern computer. The 19th century saw the invention of "programmable" looms and player piano scrolls, both of which implemented examples of domain-specific languages . By the beginning of the twentieth century, punch cards encoded data and directed mechanical processing. In the 1930s and 1940s, the formalisms of Alonzo Church 's lambda calculus and Alan Turing 's Turing machines provided mathematical abstractions for expressing algorithms ; the lambda calculus remains influential in language design. In the 1940s, the first electrically powered digital computers were created. The first high-level programming language to be designed for a computer was Plankalkül , developed for the German Z3 by Konrad Zuse between 1943 and 1945. However, it was not implemented until 1998 and 2000. Programmers of early 1950s computers, notably UNIVAC I and IBM 701 , used machine language programs , that is, the first generation language (1GL). 1GL programming was quickly superseded by similarly machine-specific, but mnemonic , second generation languages (2GL) known as assembly languages or "assembler". Later in the 1950s, assembly language programming, which had evolved to include the use of macro instructions , was followed by the development of "third generation" programming languages (3GL), such as FORTRAN , LISP , and COBOL . 3GLs are more abstract and are "portable", or at least implemented similarly on computers that do not support the same native machine code. Updated versions of all of these 3GLs are still in general use, and each has strongly influenced the development of later languages. At the end of the 1950s, the language formalized as ALGOL 60 was introduced, and most later programming languages are, in many respects, descendants of Algol. The format and use of the early programming languages was heavily influenced by the constraints of the interface . Refinement The period from the 1960s to the late 1970s brought the development of the major language paradigms now in use, though many aspects were refinements of ideas in the very first Third-generation programming languages : APL introduced array programming and influenced functional programming . PL/I (NPL) was designed in the early 1960s to incorporate the best ideas from FORTRAN and COBOL. In the 1960s, Simula was the first language designed to support object-oriented programming ; in the mid-1970s, Smalltalk followed with the first "purely" object-oriented language. C was developed between 1969 and 1973 as a system programming language, and remains popular. Prolog , designed in 1972, was the first logic programming language. In 1978, ML built a polymorphic type system on top of Lisp, pioneering statically typed functional programming languages. Each of these languages spawned an entire family of descendants, and most modern languages count at least one of them in their ancestry. The 1960s and 1970s also saw considerable debate over the merits of structured programming , and whether programming languages should be designed to support it. Edsger Dijkstra , in a famous 1968 letter published in the Communications of the ACM , argued that GOTO statements should be eliminated from all "higher level" programming languages. The 1960s and 1970s also saw expansion of techniques that reduced the footprint of a program as well as improved productivity of the programmer and user. The card deck for an early 4GL was a lot smaller for the same functionality expressed in a 3GL deck . Consolidation and growth The 1980s were years of relative consolidation. C++ combined object-oriented and systems programming. The United States government standardized Ada , a systems programming language derived from Pascal and intended for use by defense contractors. In Japan and elsewhere, vast sums were spent investigating so-called "fifth generation" languages that incorporated logic programming constructs. The functional languages community moved to standardize ML and Lisp. Rather than inventing new paradigms, all of these movements elaborated upon the ideas invented in the previous decade. One important trend in language design for programming large-scale systems during the 1980s was an increased focus on the use of modules , or large-scale organizational units of code. Modula-2 , Ada, and ML all developed notable module systems in the 1980s, although other languages, such as PL/I , already had extensive support for modular programming. Module systems were often wedded to generic programming constructs. The rapid growth of the Internet in the mid-1990s created opportunities for new languages. Perl , originally a Unix scripting tool first released in 1987, became common in dynamic websites . Java came to be used for server-side programming, and bytecode virtual machines became popular again in commercial settings with their promise of " Write once, run anywhere " ( UCSD Pascal had been popular for a time in the early 1980s). These developments were not fundamentally novel, rather they were refinements to existing languages and paradigms, and largely based on the C family of programming languages. Programming language evolution continues, in both industry and research. Current directions include security and reliability verification, new kinds of modularity ( mixins , delegates , aspects ), and database integration such as Microsoft's LINQ . The 4GLs are examples of languages which are domain-specific, such as SQL , which manipulates and returns sets of data rather than the scalar values which are canonical to most programming languages. Perl , for example, with its ' here document ' can hold multiple 4GL programs, as well as multiple JavaScript programs, in part of its own perl code and use variable interpolation in the 'here document' to support multi-language programming. http://en.wikipedia.org/wiki/Programming_language
如何从数以亿计的文献中,挖掘自己所需要的信息是一件十分复杂的事情。尽管,我们可以通过编程语言的处理就可达到目的,但是互联网中各种不同格式的网页或文本,其字段、关键词、数据、表格、链接抓取等并不是那么容易,特别是pdf文献中那些各种版式的表格、图片、关键语句的获取更是不太容易。这里首推SciMiner。 SciMiner是一个基于网页服务的生物文献挖掘工具。具体可从这个站点了解: http://jdrf.neurology.med.umich.edu/SciMiner/ 。这个工具采用lighttpd驱动,结合数据库Mysql,进行文献的批量挖掘。要下载它,需要使用学术单位邮件地址向进行申请。当前,这个软件包有两种类型,一种可以自行安装配置的核心包,大小145M,而另一种则是预配置好的VmwarePlayer包(即是说,可以利用虚拟机VmwarePlayer直接使用),大小1.1G。核心包的安装需要以下组件或库文件支持(来自SciMiner安装手册): MySQL database ImageMagick Web-server (如Lighttpd) CGI Perl Perl模组: Boulder::Medline;YAML;Text::NSP;CGI::Debug;CGI::Simple;CGI::Session;CGI::Application; HTML::Template;Data::Dumper;Unicode::String;XML::XPath;Spreadsheet::WriteExcel 这个工具推荐使用Linux系统来安装使用,比如可使用 BioInfoServ 4.0 来安装使用,可省去windows中不必要的麻烦。至于具体的安装配置教程,有空找个时间写个文档出来,供大家参考。 其他的挖掘工具还有很多,下面 这个网页 就值得参考: Tools for Literature-based Discovery Sites that Augment the Standard PubMed Search Service. Sites that are, or Contain Lists of, Search Engines that include Biomedical Topics Sites that are devoted to genes, proteins, and other bioinformatic resources Knowledge Environments (Information Portals, Online Communities) Resources and Tools for Text representation and Visualization General Data Mining and Knowledge Discovery Sites Listservs
 标签: 编程语言
标签: 编程语言