Resources and tools for bioinformatics study. Please contribute this document if you have new recommendations or some commments on current collections Some small tools are also provided under ./small_tools/, such as file merge, gene list merge, gene list comparison, etc. Created, Oct 6, 2011 Latest update, Oct 28, 2013 *************************************************************************** --------------------------------------------------------------------------- *************************************************************************** 1. Data resources 1.1 Protein-protein interaction HPRD (recommended for initial study; download the binary interaction file if you do not concern the quality; pay attention to the evidence codes, if you want to focus on the PPI detected by low-throughput experiments) BioGRID MINT IntAct MIPS BIND (Note: some protein-DNA interactions are also included) STRING (Note: they are many functional associations rather than physical interactions) 1.2 Pathways KEGG (You can download raw data files from its FTP site. Please look at the map_title.tab and hsa_gene_map.tab for GeneID mapping) BioCarta (No source file... Only include the core genes related to the signaling pathway) Reactome (Many more species avaliable) NetPath NCBI PID 1.3 Gene regulations TargetScan (predicted miRNA targets; tool is also avaliable) RNA22 (miRNA target prediction tool) miRBase (microRNA database) TarBase (experimentally verified microRNA target database) miR2Disease (a manually curated database, aims at providing a comprehensive resource of miRNA deregulation in various human diseases) TRED (transcription regulation database; curated from literature) TRANSFAC (TFBS PWMs; many useful information; Please pay attention to the quality of the PWMs;need license.....) JASPAR (Open-access PWMs) ENCODE (Huge number of data....) 1.4 Gene function Gene Ontology (A review paper is recommended: Rhee et al. Use and misuse of the gene ontology annotations. Nat Rev Genet 2008, 9:509-515.) NCBI Gene Database 1.5 Gene expression NCI-60 project (gene miRNA expressions from 60 cancer cell lines) Connectivity Map (gene expressions from many cell lines treated by different drugs under different dosages) NCBI GEO (you can download .CEL raw data for further processing) EBI ArrayExpress (I do not like the file format of ArrayExpress....) ENCODE (many resources including RNA-seq data) TCGA (http://cancergenome.nih.gov/ the cancer genome atlas) CCLE (http://www.broadinstitute.org/software/cprg/?q=node/11 cancer cell line encyclopedia) 1.6 Drug related DrugBank PubChem ATC code SIDER 1.7 Disease related HPO SIDER OMIM miR2Disease (a manually curated database, aims at providing a comprehensive resource of miRNA deregulation in various human diseases) TCGA (http://cancergenome.nih.gov/ the cancer genome atlas) CCLE (http://www.broadinstitute.org/software/cprg/?q=node/11 cancer cell line encyclopedia) 1.8 Standard vocabulary HNGC (mapping many IDs/Names to standard IDs; EntrezGeneID is recommended;http://www.genenames.org;a sample code is given ./id_mapper/) UMLS (Unified Medical Language System) MeSH (Medical Subject Headings) *************************************************************************** --------------------------------------------------------------------------- *************************************************************************** 2 Tools 2.1 Integrated portals and platforms UCSC Genome Browser (please learn how to use Table Browser and how to add Custom Track) IPA (Read documents from http://www.ingenuity.com/; a commercial integrated functional annotating systems) Expander Cytoscape (Network visualization and small scale network analysis) BioConductor (a R platform, including many packages for bioinformatics analysis; please read its documents) 2.2 Sequence analysis BLAST BLAT (compare similar and long sequence) Bowtie (recommended for deep sequencing analysis) ClustalX (local multiple alignment) Sim4 2.3 Literature mining Literature mining scripts written by Jun Yuan (Please refer to the dir ./literature_mining/) 2.4 Statistical packages fdrtool (calculate the q-values based on p-value, z-score, t-score and correlation) 2.5 Functional annotation or gene set analysis GSEA (gene set enrichment analysis package) DAVID web tools Ontologizer (gene set analysis for GOs with hierarchical information and visualization) 2.6 Gene regulation TargetScan (miRNA target prediction) RNA22 (miRNA target prediction;easy for use) DME/STORM (motif analysis package first written by Andrew Smith, recommended; many other tools in the same package) MEME (for small scale motif analysis, very slow) MINDy (modulator inference by network dynamics) miRHiC (regulatory inference from hierarchical gene co-experessed signatures) ARCANE (gene regulatory inference from large-scale gene expression data) 2.7 Microarray processing dChip (easy to use; please refer to the documents and some scripts under ./microarray_dchip/; Combat for adjusting batch effects) RMA (similar usage as dChip) SAM (Significance analysis of microarray, to detect differentially expressed genes; EXCEL plugin/R scripts; I recommend write your own code (t-test + fdr adjustment) to identify differentially expressed genes...) EDGE (Identify differentially expressed genes in time-course datasets; the sample size should be more than 10 according to my experience) STEM (Identify gene expression patterns from time-course datasets with limited number of time points; easy to use, java platform) FastDMA (analyzer for illumina humanmethylation450 beadchip) *************************************************************************** --------------------------------------------------------------------------- *************************************************************************** 3 Conferences and Journals 3.1.1 Bioinformatics 3.1.2 PLoS Computational Biology 3.1.3 BMC Bioinformatics/Genomics/Systems Biology 3.1.4 PLoS ONE 3.1.5 Nucleic Acids Research (Computational Biology/Webserver Issue/Database Issue) 3.1.6 Nature Biotechnology/Method (Computational Biolgy) 3.1.7 Quantitative Biology 3.2.1 ISMB/ECCB (Intelligent Systems for Molecular Biology) *** 3.2.2 RECOMB (Research in Computational Molecular Biology) *** 3.2.3 APBC (Asia Pacific Bioinformatics Conference) ** 3.2.3 InCOB (International Conference on Bioinformatics) ** 3.2.4 BIBM (IEEE International Conference on Bioinformatics and Biomedicine) 3.2.5 PSB (Pacific Symposium on Biocomputing)
熊荣川 xiong rongchuan 六盘水师范学院生物信息学实验室 xiongrongchuan@126.com http://blog.sciencenet.cn/u/Bearjazz 生物信息学可以根据已有的数据对蛋白质的信息进行预测. 再此介绍一个运行速度很快而且也比较权威的在线工具 ProtParam 网址: http://web.expasy.org/protparam/ 其网站上功能介绍如下: ProtParam ( References / Documentation ) is a tool which allows the computation of various physical and chemical parameters for a given protein stored in Swiss-Prot or TrEMBL or for a user entered sequence. The computed parameters include the molecular weight, theoretical pI, amino acid composition, atomic composition, extinction coefficient, estimated half-life, instability index, aliphatic index and grand average of hydropathicity (GRAVY) ( Disclaimer ). 只要在数据框中粘贴你的氨基酸序列并提交, 即可预测该该蛋白质的相关信息. 如等电点、分子量、分子式、不稳定系数(instability index, 40为稳定, 40为不稳定) 预测蛋白质功能作用位点的在线工具 http://myhits.isb-sib.ch/cgi-bin/motif_scan 在数据框中输入一定格式的氨基酸序列(具体可以先观察其带的例子),在数据框下面复选参考数据库,然后搜索. 可以查看类似蛋白激酶磷酸化位点之类的信息.
DIGITAL HUMANITIES TOOLS DELICIOUS Delicious is a Social Bookmarking service, whereby one may save bookmarks online, share them with others, and see what other people are bookmarking. DIIGO Diigo is two services in one --a research/collaborative research tool, and a knowledge-sharing community/social content site. TWITTER Twitter is a real-time short messaging service that works over multiple networks and devices. In countries all around the world, people follow the sources most relevant to them and access information via Twitter as it happens-from breaking world news to updates from friends. WORDLE Wordle is a toy for generating word clouds from text that you provide. The clouds give greater prominence to words that appear more frequently in the source text. You can tweak your clouds with different fonts, layouts, and color schemes. The images you create with Wordle are yours to use however you like. You can print them out, or save them to the Wordle gallery to share with your friends. WORDPRESS WordPress is a state-of-the-art publishing platform with a focus on aesthetics, web standards, and usability. WordPress is both free and priceless at the same time. More simply, WordPress is what you use when you want to work with your blogging software, not fight it. OPEN SOURCE SOFTWARE FEDORA Fedora is a Linux-based operating system that showcases the latest in free and open source software. Fedora is always free for anyone to use, modify, and distribute. It is built by people across the globe who work together as a community: the Fedora Project. The Fedora Project is open and anyone is welcome to join. KUALI Kuali is a growing community of universities, colleges, businesses, and other organizations that have partnered to build and sustain open-source administrative software for higher eduction, by higher education. Kuali software is released under the Educational Community License. MIT OPEN COURSE WARE MIT OpenCourseWare (OCW) is a web-based publication of virtually all MIT course content. OCW is open and available to the world and is a permanent MIT activity. PHILOMINE PhiloMine is a drop-in extension to current releases of PhiloLogic, to support a variety of machine learning, text mining, and document clustering tasks. It is designed to work with databases currently loaded under PhiloLogic without further modification. Like PhiloLogic, PhiloMine is a Free Software implementation designed to support research and development activities at the ARTFL Project and the Digital Library Developement Center and the at the University of Chicago. SILVERLIGHT Microsoft Silverlight helps you create rich web applications that run on Mac OS, Windows, and Linux, providing a new level of engaging, rich, safe, secure, and scalable cross-platform experience. SOFTWARE ENVIRONMENT FOR THE ADVANCEMENT OF SCHOLARLY RESEARCH The Software Environment for the Advancement of Scholarly Research (SEASR), funded by the Andrew W. Mellon Foundation, provides a research and development environment capable of powering leading-edge digital humanities initiatives. SOPHIE 2.0 Sophie 2.0 is open source software for writing, reading and visualizing rich media documents in an interactive, networked environment. The program emerged from the desire to create an easy-to-use application that would allow authors to combine text, images, video, and sound quickly and simply, but with precision and sophistication. Sophie's users are interested in creating robust, elegant, networked, texts and multimedia works without having programming knowledge or training in the use of more complex and costly tools such as Flash.Sophie 2.0 was initially designed and developed by the Institute for the Future of the Book. In 2008, the University of Southern California's School of Cinematic Arts assumed sponsorship of Sophie 2.0 and, with a generous grant from the The Andrew W. Mellon Foundation, is significantly revising and improving a new 2.0 version to be released in the Fall of 2009. The Sophie 2.0 Project is being developed by Astea Solutions AD and additional contributors using a Java code base contributed to the project by Astea Solutions. TEXT CODING INITIATIVE The Text Encoding Initiative (TEI) is a consortium which collectively develops and maintains a standard for the representation of texts in digital form. Its chief deliverable is a set of Guidelines which specify encoding methods for machine-readable texts, chiefly in the humanities, social sciences and linguistics. Since 1994, the TEI Guidelines have been widely used by libraries, museums, publishers, and individual scholars to present texts for online research, teaching, and preservation. In addition to the Guidelines themselves, the Consortium provides a variety of supporting resources, including resources for learning TEI, information on projects using the TEI, TEI-related publications, and software developed for or adapted to the TEI. THOUGHTARK An open source, free web application and collaborative space that utilizes the search behaviors of the users to determine the value of various bibliographic resources. RESEARCH ENVIRONMENTAL SYSTEMS RESEARCH Founded as the Environmental Systems Research Institute, ESRI is built on the philosophy that a geographic approach to problem solving ensures better communication and collaboration. Geographic information system (GIS) technology leverages this geographic insight to address social, economic, business, and environmental concerns at local, regional, national, and global scales. HISTORY ENGINE The History Engine is an educational tool that gives students the opportunity to learn history by doing the work-researching, writing, and publishing-of a historian. The result is an ever-growing collection of historical articles or episodes that paints a wide-ranging portrait of life in the United States throughout its history and that is available to scholars, teachers, and the general public in our online database. OPEN JOURNAL SYSTEMS Open Journal Systems (OJS) is a journal management and publishing system that has been developed by the Public Knowledge Project through its federally funded efforts to expand and improve access to research. OJS assists with every stage of the refereed publishing process, from submissions through to online publication and indexing. Through its management systems, its finely grained indexing of research, and the context it provides for research, OJS seeks to improve both the scholarly and public quality of refereed research. PHILOLOGIC PhiloLogic™ is the primary full-text search, retrieval and analysis tool developed by the ARTFL Project and the Digital Library Development Center (DLDC) at the University of Chicago. This is a Free Software implementation of PhiloLogic for large TEI-Lite document collections. The wide array of XML data specifications and the recent deployment of basic XML processing tools provides an important opportunity for the collaborative development of higher-level, interoperable tools for Humanities Computing applications. The sophistication and power of the TEI-XML encoding specification supports the development of extremely rich textual data representations. WORLDCAT WorldCat connects you to the collections and services of more than 10,000 libraries worldwide. CITATION MANAGEMENT CONNOTEA Connotea: Free online reference management for clinicians and scientists. ZOTERO Zotero is a free, easy-to-use Firefox extension to help you collect, manage, and cite your research sources. It lives right where you do your work-in the web browser itself. ANALYTICAL RESEARCH METADATA OFFER NEW KNOWLEDGE (MONK) MONK is a digital environment designed to help humanities scholars discover and analyze patterns in the texts they study. The MONK project has been generously supported by the Andrew W. Mellon Foundation, from 2007-2009, and InCommon integration has been supported in 2009 by the CIC Library Directors. All code produced by the project is open source. MONK has a publicly available instance with texts contributed by Indiana University, the University of North Carolina at Chapel Hill, the University of Virginia, and Martin Mueller at Northwestern University. NEOFORMIX Discovering and Illustrating Patterns in Data: Blog editor who enjoys discovering the patterns in the apparent chaos of real life data and exploring new techniques for communicating in a visually compelling manner. Includes analytical project results, reviews of tools or techniques, and links to related resources. NVIVO Different than statistical or quantitative software, which analyze data using numbers, QSR software helps you to access, manage, shape and analyze detailed textual, audio and visual information. The NVivo 8 software product allows you to import, sort and analyze audio files, videos, digital photos, Word, PDF, rich text and plain text documents. WOLFRAM|ALPHA Wolfram|Alpha's long-term goal is to make all systematic knowledge immediately computable and accessible to everyone. We aim to collect and curate all objective data; implement every known model, method, and algorithm; and make it possible to compute whatever can be computed about anything. Today's Wolfram|Alpha is the first step in an ambitious, long-term project. Enter your question or calculation and Wolfram|Alpha uses its built-in algorithms and a growing collection of data to compute the answer. COURSE SUPPORT DEVELOPMENT CENTER FOR DIGITAL STORYTELLING An international not-for-profit community arts organization rooted in the craft of personal storytelling. We assist youth and adults around the world in using media tools to share, record, and value stories from their lives, in ways that promote artistic expression, health and well being, and justice. MOODLE Moodle is a Course Management System (CMS), also known as a Learning Management System (LMS) or a Virtual Learning Environment (VLE). It is a Free web application that educators can use to create effective online learning sites. Moodle.org is our community site where Moodle is made and discussed. Please explore and join in! PACHYDERM 2.0 Multimedia authoring for peanuts. Pachyderm is an easy-to-use multimedia authoring tool. Designed for people with little multimedia experience, Pachyderm is accessed through a web browser and is as easy to use as filling out a web form. Authors upload their own media (images, audio clips, and short video segments) and place them into pre-designed templates, which can play video and audio, link to other templates, zoom in on images, and more. Once the templates have been completed and linked together, the presentation is published and can then be downloaded and placed on the authora€™s website or on a CD or DVD ROM. Authors may also leave their presentations on the Pachyderm server and link directly to them there. The result is an attractive, interactive Flash-based multimedia presentation. PREZI Prezi is a living presentation tool... visualization and storytelling without slides. SAKAI The Sakai Collaboration and Learning Environment is developed by a community that strives to enable exceptional teaching, learning and research. Sakai collaborators - ranging from educators to engineers - share in their successes and challenges, honing the community's collective expertise to drive rapid development of this enterprise-ready platform. While Sakai is typically used for teaching and learning (similar to products like Blackboard and Moodle) we call it a Collaboration and Learning Environment (CLE) because it embraces uses beyond the classroom. Sakai is distributed as free and open source software under the Educational Community License. VISUAL UNDERSTANDING ENVIRONMENT The Visual Understanding Environment (VUE) is an Open Source project based at Tufts University. The VUE project is focused on creating flexible tools for managing and integrating digital resources in support of teaching, learning and research. VUE provides a flexible visual environment for structuring, presenting, and sharing digital information. WILLAMETTE INSTRUCTIONAL SUPPORT ENVIRONMENT WISE, the Willamette Instructional Support Environment, is a learning and collaboration system that provides course sites for official university courses and project sites for committee work, student organizations, collaborative research projects and other university-related activities. MULTIMEDIA THEORA Theora is a free and open video compression format from the Xiph.org Foundation. Like all our multimedia technology it can be used to distribute film and video online and on disc without the licensing and royalty fees or vendor lock-in associated with other formats. Theora scales from postage stamp to HD resolution, and is considered particularly competitive at low bitrates. It is in the same class as MPEG-4/DiVX, and like the Vorbis audio codec it has lots of room for improvement as encoder technology develops. Theora is in full public release as of November 3, 2008. UNESCO UNESCO : For Young Creators. A selection of free editing software for use in creative projects. Tools for editing audio, images and web pages.
2011年4月20日的电脑世界沙龙上,介绍了22款免费的数据分析相关工具,他们有关于数据清洗的、有关于数据展现的还有关于数据分析的;他们或是来自IBM,谷歌。雅虎这样的互联网企业,或是出自麻省理工,斯坦福这样的高校,有在线的也有离线的。如果你正为一些地理分析图片而赶到焦虑,或是为做不出漂亮的社交网络关系图而烦恼,或许下面这些工具可以帮到你。 数据清理类工具 DataWrangler Google Refine 统计分析类工具 The R Project for Statistical Computing TimeFlow 数据展现类工具 Google Fusion Tables Impure Tableau Public Many Eyes VIDI Zoho Reports 代码帮助类工具 Choosel Exhibit 地图相关数据展示工具 Quantum GIS (QGIS) OpenHeatMap OpenLayers 文本类相关处理工具 IBM Word-Cloud Generator 社交网络类工具 Gephi NodeXL
曾经安排学生研究过HSPICE下的这些模型和工具,但是效果都不是很好,学生学习的结果与其它人文章上的内容相距甚远。还是要参考KRISH说的鸟和兔子的故事,没有好的环境,就要自己来做吧。 MOSRA工具 摘要: 在MOS集成电路中,器件老化主要是由于 栅极绝缘层 ,以及 栅极绝缘层和硅之间界面 的随时间退化所引起的。主要的两类退化效应主要是热载流子注入(HCI)和偏置温度不稳定性(BTI)。这些退化机制随着栅氧化层的厚度不断变小,以及高介电常数金属栅(high-K metal-gate)晶体管的使用而变得更加的显著。 These mechanisms are more prominent in advanced process nodes in which the gate oxide is scaled to only a few molecules in equivalent thickness, and with the use of high-K metal-gate transistors. 由于这些效应的影响,需要长时间,并且非常昂贵的测试来衡量电路性能的退化程度,并且要及时的发现电路失效情况,造成生产成本的急剧增加。而作为一种替代手段,设计者开始使用保守的策略来对关键电路进行超安全标准的过设计(简单说,即设计时序余量),这样会造成芯片成本的增大(Problem:难道仅仅是芯片成本增大吗?对性能也会造成不良的影响!)。因此,以较低成本对电路的生命周期(此生命周期可不是剩余寿命预测那样花里胡哨的,是真实的,可验证的!)进行预测,特别是对于一些可靠性要求极高的领域,是非常必要的。 HSPICE和CustomSim(是两种不同的工具?)中的MOS可靠性分析(MOSRA)工具提供了一种可靠的,经济的方法来进行时序余量设计和广义寿命测试(extensive lifetime testing)。利用内置模型或者用户自定义老化模型,MOSRA能够准确预测HCI和BTI所引起的电路性能上的老化情况。MOSRA使设计者能够在设计的早期检测到可靠性失效情况,从而可以显著的减小寿命测试的时间和成本。通过HSPICE与CustomSim的集成应用,老化分析可以与标准的瞬态仿真一样快速的运行。 介绍: 由于老化引起的MOS器件的退化情况已经成为45nm及以下器件可靠性的一个重要的衡量指标。它使得电路性能随时间发生退化,减小电路的寿命,并且可能会引入潜在的故障。一个影响器件老化的主要机制是HCI现象。在高电场环境下,载流子从沟道的耗尽层注入到栅极绝缘层,改变了它的电特性。另外一个重要的退化现象是p沟道MOSFET的NBTI效应和n沟道MOSFET的PBTI效应。PBTI效应在高介电常数金属栅(high-K metal-gate)层叠中有非常显著的影响。在两类BTI效应中,栅极绝缘层中的电荷的数量随着栅极偏置电压的改变而改变,由于电荷的捕获和释放作用。在恒定偏置电压的作用下,捕获的电荷不断地增加,进一步增大门限电压,并减小沟道载流子的移动性(mobility)。这个效应与器件工作温度有非常强烈的联系。当栅极电压是随时间变化的,一些捕获的电荷可以被释放,这取决于捕获的位置,以及捕获/释放的时间常数,这会引起退化效应的部分恢复特性现象的发生。 HSPICE与CustomSim中MOSRA已经被成功的应用于45nm及以下器件可靠性问题的识别和调试中。它可以提供: (1)准确的,并且是可以度量的HCI和BTI的模型,特别的,可以对BTI效应中特有的部分恢复特性进行建模。 (2)与HSPICE与CustomSim中的功率仿真引擎进行无缝的连接,在特定的操作条件下,进行电应力计算,在指定的时间范围内进行应力和退化的计算。 (3)可以很简单的与其它器件模型进行集成。 (4)可以对应力积累效应进行解释,例如MOS器件老化,漏电流减小等现象,从而减小可能由此引起的器件退化现象。 MOSRA老化模型 器件老化是器件参数在一定电应力条件作用下持续退化的一种现象。而MOSRA模型被用来将这些电应力条件转换为器件的实际退化情况。一般来说,这样的模型是器件工作条件,例如电压、电流、温度、以及器件拓扑特性等参数的函数。而得到的退化效应可以以以下两种方式进行使用: 1. 将电应力参数转化为关键的MOSFET集成模型参数的退化情况,例如门限电压、载流子迁移速率(mobility)等; 2. 另外一种方式是将应力直接转换为器件特性的退化程度,例如直接转换为漏电流,以及其导电率的退化百分比; 两种方法各具优势,第一种方法直观简单,而第二种方法可以将不同的退化效应分开考虑,进而在一个较宽的偏置电压的范围内,得到一个更为精确电流、导电率等参数的退化模型。(个人理解,一个是更为精确,另外一个更为直观) MOSRA模型通过基于物理参量的公式建立,并且通过参数系数的调整来增大模型的准确性,并使参数提取变得更加方便。 对于NBTI/PBTI模型,主要考虑两个物理机制:一是与退化对于界面陷阱(interface traps)的影响程度,另外一个是与绝缘层中陷阱相关。其实这里说的主要就是NBTI/PBTI效应对于MOS物理特性的影响。 For N/PBTI models, two principal physical mechanisms are considered: One related to the contribution of the (Equation 1) and the other related to the traps deep inside the dielectric layer (Equation 2). 在上式中,E(V GS ,V DS )表示绝缘体中的电场强度。器件门限电压的退化情况被用来表示BTI模型。 最近的亚深纳米器件数据表明NBTI和PBTI效应与沟道的长度有直接的关连,而依赖的趋势随着工艺条件的变化而变化。根据这些观察结果,我们得到了灵活的与沟道长度和宽度相关的数学公式。此外,我们的BTI模型中允许一个装箱方法(类似于集成方法,binning approach),the geometry scaling equations embedded in the model provide for accurate global modeling. 通过考虑应力激励的占空比,可以对部分恢复特性进行建模。当部分恢复特性被考虑的时候,整体的延迟特性能够变小。 图1 环形振荡器(最高)频率退化问题中的部分恢复效应,虚线表示没有考虑部分恢复特性时的退化情况 这个方法允许我们将BTI效应的部分恢复特性建模为电路工作时间的一个函数。 MOSRA HCI模型 HCI模型应该对宽范围内的漏电流、栅极和衬底的偏置电压以及不同温度之间的依赖关系进行准确的解释。这个准确性应该对于多种沟道长度和不同的氧化层厚度都是适用的。MOSRA HCI模型的基本公式是: 这个公式里的第一项对应于幸运电子模型(Lucky Electron Model),而第二项则是在高电场(大电流)环境下,让该模型变得更为准确。 为了说明MOSRA里面的模型非常准确,作者还比较了MOSRA HCI模型与BSIM4 模型
研究发现黑猩猩能看录像学习制造工具 据英国媒体报道,研究人员发现,黑猩猩通过观看录像演示,可以学会制造工具。在实验中,研究人员给黑猩猩们演示一段录像,在录像中,一只训练有素的猩猩把两部分工具组成一个工具,用这个工具够取食品。 看过录像后,研究人员递给这些黑猩猩相同的两部分工具,黑猩猩学会把两部分组成工具,并使用工具够取美食。该研究发表在英国《皇家学会学报B》( Proceedings of the Royal Society B )上,科学家称,该研究验证了社会学习对灵长类的有效作用。负责这项研究的苏格兰圣安德鲁斯大学的伊丽莎白·普利斯解释说:“通过录像,我们能准确控制动物看到的信息量,这样我们能准确理解它们需要学习的如何执行任务的信息量。” 在实验中,普利斯博士和她的同事把黑猩猩分成5组。一组被演示全部录像,在录像中,研究人员递给一只黑猩猩一根杆和一个管,是可对接在一起的两部分,然后演示者使用较长的组合工具从笼子外的平台够取得到一串葡萄。其他组被演示越来越少的信息,其中一组的黑猩猩只看到录像中黑猩猩吃葡萄的一幕。接下来,研究人员为这些受试者重新创造了这一情境。他们在每只黑猩猩笼子外的一个平台上放一串葡萄,然后递给这些动物一根杆和一个塑料管。普利斯说:“那些看完全部录像的黑猩猩学习制造够取食品的必要工具的情况较好。它们能学会如何为特定任务制造工具,这让我们感到非常兴奋。这种习性在野外非常罕见,这是人类工具使用的必要部分。” 普利斯说:“少数没有看完全部录像的黑猩猩学会了自己制造工具。对于这一组,更有趣的是,当我们把葡萄放在距离它们的不同位置,它们也能制造合适的工具够到葡萄。”并非简单模仿,这些动物还会依据距离葡萄的远近,在使用管或者杆和使用组合工具之间切换。普利斯博士说:“那些看过全部录像并学会制造长工具的猩猩即使在葡萄离它们很近很难使用工具的情况下仍继续制造工具。”可能,社会学习对黑猩猩来说是一种很强的力量以致它们应用“遵循你看到的”的规则,而不是最适合解决任务的规则。 现在,研究组正计划对幼儿进行同样的测试以检测他们依赖社会学习的状况。研究仍不清楚为什么这类工具建造在野外较为不常见的原因。普利斯博士说:“我们发现,它们非常聪明,所以这一定有什么原因,可能是黑猩猩的年龄到达能执行那些更高水平技能的时候或许它们太老了无法通过演示学习。” 更多阅读 苏格兰圣安德鲁斯大学相关报道(英文)
RNA 结构预测工具 PPfold 3.0 熊荣川 译 六盘水师范学院生物信息学实验室 xiongrongchuan@126.com http://blog.sciencenet.cn/u/Bearjazz 随着物理方法测定的 RNA 结构数据越来越丰富,以及 RNA 初级、高级结构之间关系研究的深入,现在涌现出一大批基于系统发生和已有 RNA 结构数据库来预测未知 RNA 结构的生物信息学方法,相应也产生了学多软件工具,下面简单的介绍其中一款软件 PPfold 3.0 。 PPfold 3.0 一款基于 Pfold 算法的 RNA 二级结构预测工具软件,是 PPfold 的升级,更丰富了既有 RNA 结构的参考和算法的优化。该软件为 java 程序,不依赖任何操作系统,可以到以下地址下载安装使用。 http://birc.au.dk/software/ppfold. 原文: PPfold 3.0: Fast RNA secondary structure prediction using phylogeny and auxiliary data Zsuzsanna S¨uk¨osd 1 ; 2 ; 3 _ , Bjarne Knudsen 4 , Jrgen Kjems 1 ; 2 , and Christian NS Pedersen 3 ; 5 ABSTRACT PPfold is a multithreaded implementation of the Pfold algorithm for RNA secondary structure prediction. Here we present a new version of PPfold, which extends the evolutionary analysis with a exible probabilistic model for incorporating auxiliary data, such as data from structure probing experiments. Our tests show that the accuracy of single-sequence secondary structure prediction using experimental data in PPfold 3.0 is comparable to RNAstructure. Furthermore, alignment structure prediction quality is improved even further by the addition of experimental data. PPfold 3.0 therefore has the potential of producing more accurate predictions than it was previously possible. Availability and Implementation PPfold 3.0 is available as a platform-independent Java application, and can be downloaded from http://birc.au.dk/software/ppfold. Contact Zsuzsanna S¨uk¨osd, zs@birc.au.dk.
【论文阅读笔记,Leiting, Jun 27, 2012】 A decade of web server updates at the bioinformatics links directory: 2003–2012 Nucl. Acids Res. (2012) 40 (W1): W3-W12. doi: 10.1093/nar/gks632 因为数量的大量增加,对于生物信息学的研究人员来说,跟踪生物信息学工具和数据库变得越来越困难,因此,根据内容和用途建立一个生物信息学算法、数据库和文献的索引变得越来越重要。 而 Bioinformatics Links Directory 的建立便是用于解决这个问题。这个目录收集了序列资源(Molecular resources)、工具和数据库的链接,并分成了 11 个大类,和若干小类,共 134 个资源 (Resources),455 个数据库 (Databases),和 1205 个网络服务器工具 (Web server tools)。 11 个大类是: Computer Related DNA Education Expression Human Genome Literature Model Organisms Other Modules Protein RNA Sequence Comparison
晶体结构数据工具网页 http://www.cryst.ehu.es/ 包括用对称群给出原子坐标( WYCKPOS Wyckoff Positions of Space Groups ), 布里渊区高对称点( KVEC The k-vector types and Brillouin zones of Space Groups ), 等数据库。
来源 1 http://emuch.net/bbs/viewthread.php?tid=3748553 1.StyleWriter (润色首推) 嵌入 word 使用。主要功能:检查拼写、语法等错误,润色文章。 本软件的诱人之处在于润色文章,可以有提示你对同义词做选择,让你的文章更地道。 http://www.editorsoftware.com/downloads/DWSWT.html 另外还有统计文章特征的功能,详见李泳老师的博文:从 Stylewriter 看英文写作 2.Triivi (检查首选) 英文输入软件,免费开源,具备词频调整、智能纠错,根据已经输入的字母猜出想写点词或短语,提高英文输入速度!标准版具有 50 万词汇量 , 专业词库 ( 约 20 万词汇 ). http://www.triivi.com/ 3.Intellicomplete( 推荐 ) 虽没有 triivi 专业词汇丰富,但定义性较强,且自定义语库方便,只需要一个快捷键 Ctrl+Alt+J 。 http://www.download.com/IntelliComplete/3000-2079_4-10062169.html 4.As-U-Type 是一款英文输入单词自动校正软件,根据软件自带的和自定义的校正词典,当你编辑文档输入的单词有误是,它会自动帮你校正。 此软件是在输入后按空格键后给出提示,没有实时提醒功能,这个很遗憾。 http://www.asutype.com/files/asutype-setup.exe 5.TypeTip 与 As-U-Type 功能雷同的辅助录入软件,具有实时提示及校正功能,但不能输入词组 phrase, 不过兼容性较好。 http://www.sharewareconnection.com/typetip.htm 6. 金山写作助手 金山词霸自带工具。编写英文文档时,常常会遭遇当前语境不知该用哪个单词的尴尬,这时你会怎么办?打开词霸查找一通?哦,那太麻烦了。其实最简单的方法,是快速按动两下 Alt 键。这时词霸将自动弹出一个特别设计的 “ 写作助手 ” 模块,试着输入一下中文词汇吧。看到了吗?软件将自动弹出一组与搜索词对应的英文单词,如果感觉片面的解释无法帮助判断,还可以继续输入一个 “ 分号 ” ,这时 “ 写作助手 ” 将会在翻译结果中自动加入精选例句。 7.Bullfighter 可用作微软 Word 和 PowerPoint 的插件 ( www.fightthebull.com/bullfighter.asp) ,不过它只能在 Windows 操作系统中运行。 Bullfighter 的目标是找到并且删除你文章中那些难懂的部分。 8.whitesomke, WriteExperss 虽然 WhiteSmoke 也向中国和印度的母语非英语者推销这款产品,但公司表示他们最大的目标客户群仍是那些想让自己的文笔变得典雅一些的以英语为母语者。 http://www.jz5u.com/Soft/teach/waiyu/13557.html 来源 2 http://emuch.net/bbs/viewthread.php?tid=3669411 各位虫友们,各位科研工作者们大家好,对于大家来说成果最后都是要通过文章来表现出来,为了让更多的人了解自己的成果,所以科研论文写作,尤其是外文科研论文的写作显得尤为重要。下面由我向大家推荐本版关于论文写作的一些优秀的帖子,其中包括中外大牛或大数据库机构对论文写作的经验和建议。 1 ,首先是国外的一些大牛们的宝贵的经验和建议,帖子如下: 【教程】大牛教你写论文(哈佛大学); http://emuch.net/bbs/viewthread.php?tid=3514631fpage=1 【素材】从科研到写作(国外教授教你如何写论文); http://emuch.net/bbs/viewthread.php?tid=3484927fpage=1 【课件】如何写科技论文(哈佛大学); http://emuch.net/bbs/viewthread.php?tid=3390211fpage=1 【素材】如何写论文(剑桥大学); http://emuch.net/bbs/viewthread.php?tid=3572060fpage=1 2 ,接下来是一些著名的论坛和数据库们的经验和建议,帖子如下: 【教程】 Secrets to Writing Better Scientific Articles ( ACP ); http://emuch.net/bbs/viewthread.php?tid=3665940fpage=1 【素材】 Paper 论文实用手册(上海交大 BBS ); http://emuch.net/bbs/viewthread.php?tid=3663948fpage=1 【课件】 Writing for Success ; http://emuch.net/bbs/viewthread.php?tid=3227958fpage=2 3 ,然后就是一些关于论文写作的分步解析和常见问题解析,帖子如下: 【课件】如何写好一篇 SCI 论文的题名 SCI 高被引论文题名分析; http://emuch.net/bbs/viewthread.php?tid=3437674fpage=1 【素材】科技论文写作分步解析; http://emuch.net/bbs/viewthread.php?tid=3538342fpage=1 【课件】论文常见问题及成因辨析; http://emuch.net/bbs/viewthread.php?tid=3637978fpage=2 4 ,然后就是关于英语写作和翻译方面的一些心得和建议,帖子如下: 【素材】科技英语翻译和写作; http://emuch.net/bbs/viewthread.php?tid=3568684fpage=1 【教程】中国人英文可以论文最容易犯的 200 个错误; http://emuch.net/bbs/viewthread.php?tid=1094989fpage=2 【素材】英文论文写作 - 很不错的; http://emuch.net/bbs/viewthread.php?tid=1651857fpage=2 【教程】英文文章的写作心得分享; http://emuch.net/bbs/viewthread.php?tid=3420259fpage=2 5 ,最后是一些英语论文写作的惯用句式句型和一个英语写作的润色软件,帖子如下: 【素材】写外文论文的一些惯用句式; http://emuch.net/bbs/viewthread.php?tid=3437640fpage=1 【素材】写英文论文常用句型; http://emuch.net/bbs/viewthread.php?tid=3482914fpage=2 【原创】强烈推荐一款英文润色软件 WhiteSmoke2010 带破解方法; http://emuch.net/bbs/viewthread.php?tid=2290563fpage=2 以上内容仅为个人推荐,想要获取更多更好的科研素材精华资源,请链接到下面的地址: http://emuch.net/bbs/forumdisplay.php?fid=300view=digest 。 来源 3 http://emuch.net/bbs/viewthread.php?tid=1329206fpage=1 小弟不才,迄今才撰写了三篇英文文章,但写作过程中也积累了一点经验,不敢敝帚自珍,今天也斗胆向各位虫友贡献一下。我这几篇文章,不论内容如何,但每次审稿人对于语言的评价都是还不错的, well written ,总结起来不外有三个小窍门: 一是平时多积累。我在日常读文献的时候,如果发现很好的句子句式,都会记录在一个文档里面,如下面的一段话,就是我在一篇文章的摘要中发现的: This paper describes the concept of sensor networks which has been made viable by the convergence of microelectro-mechanical systems technology, wireless communications and digital electronics. First, the sensing tasks and the potential sensor networks applications are explored, and a review of factors influencing the design of sensor networks is provided. Then, the communication architecture for sensor networks is outlined, and the algorithms and protocols developed for each layer in the literature are explored. Open research issues for the realization of sensor networks are also discussed. 文章用词忌重复,中文如此,英文亦然。特别是动词的使用,如在一段话中出现了几个相同的动词,感觉文章就跌价不少,而如果用了几个意思相近而又贴切的词,自然就会增色几分。如上文中的 describe , explore , provide , outline 和 discuss ,就使得文章有了文采,值得学习和收藏。坚持收集例句,素材多了,自然自己的造句的时候就有底子了。此外,还要注意,在收集例句的过程,随着例句的增多,也需要对例句进行整理和分类,方便学习和检索。 二是注意行文中 Transition words 的使用。 Transition words 就是在行文过程中,连接意义相关句子的词,如 Therefore , thus , in particular 等等。使用这些词,会使得文章连贯性好,逻辑性强,读起来一气呵成,自然会给审稿人好印象。下面是一个关于 Transition words 的一个总结,供各位虫友参考: Transitions Study Sheet Transitions for time: before, afterward, after, next, then, as soon as, later, until, when, finally, last, meanwhile, during, at times, sometimes, oftentimes Example: WWII broke out in Europe in 1939. During this time the United States remained neutral. It wasn’t until 1941, after Japan bombed Pearl Harbor, that the United States entered the war. After its entry, it was only a matter of time before the Allies defeated Germany and the Axis powers. Transitions for place: in the background, in the distance, beyond, behind, above, below, in front of, elsewhere, in the middle, to the left, to the right Example: My favorite painting is Botticelli’s Birth of Venus. In the middle of the painting stands Venus, the Roman goddess of love, standing on a seashell. She floats majestically above the beautiful water below her. To her left a figure representing wind blows fierce clouds of wind in her direction. To her right a figure behind her attempts to cover her with a blanket and protect her. It is a truly breath-taking piece of art. Transitions for examples: for example, for instance, as an example, like, specifically, consider as an illustration, that is, such as, similar, similarly Example: Oftentimes people who study from history fail to learn from the mistakes of the past. For example, during WWII Hitler decided to invade Russia just before wintertime. This decision was the same decision Napoleon made over a hundred years earlier, and Hitler’s army met a similar fate. Had he learned from his history, Hitler might have avoided making this costly mistake and the outcome for the war might have been different. For instance, if Hitler had decided to invade England by sea rather than Russia by land, he might well have won the war. Transitions for emphasis: chiefly, equally, indeed, even more important, in particular, most important, without a doubt, indubitably, unquestionably, definitely Example: Without a doubt, Chinese food is one of my favorite cuisines. Although I find Japanese and Thai food equally delicious at times, Chinese food is definitely my favorite Asian cuisine. In particular I enjoy the spicy Szechuan style of cooking commonly found in Chinese food. Transitions for restatement: in short, that is, in effect, in other words Example: When I asked my girlfriend to marry me she said, in effect, that she wouldn’t be ready for marriage until after she completed her PhD program. At first I was crushed, that is, I felt like she said no because she didn’t love me anymore. However, after she explained her reasons to me I felt better and agreed with her. In other words, I came away feeling better than I had anticipated. Transitions for comparison: similarly, likewise, also, the same as, different than, opposite, unlike, instead Example: When my older brother was deciding where to go to college he spoke to my father about where he should go. Not surprisingly he went to the same school my father did, MIT. When it was time for me to choose a college I did the exact opposite. I didn’t ask my father where I should go, and as a result, I didn’t also go to MIT like he and my brother did. Instead I went to UCLA. Transitions for concession: although, of course, admittedly, true, doubtless, granted that, no doubt, indubitably, without a doubt, definitely, certainly Example: Some people might be surprised to learn that the two most successful NBA teams of all-time are the Boston Celtics and the Los Angeles Lakers. Although neither of these teams is very good right now, they are the two teams with the most champions in NBA history. The Celtics definitely had the best streak of these two teams; winning eight championships in a row at one point. Admittedly there is always the chance that some future team could break this record, but this seems unlikely. Of course no one can predict the future with any certainty. Transitions for consequence: thus, so, then, it follows, as a result, therefore, hence, consequently, accordingly, because Example: I’m sorry, but I can’t let you turn in your homework late because it wouldn’t be fair to the other students. As a result your grade has dropped lower and you are now failing the class. Consequently you need to get 100% on the final so you can pass the class and then graduate from CAS. Therefore, I suggest you study very hard so I don’t have to fail you. Good luck! Transitions for conclusion: to sum up, in summary, finally, therefore, thus, in conclusion, to conclude Example: Finally, Beijing has a lot of nice places to shop that appeal to tourists. To sum up then, Beijing is a wonderful place to visit because it has beautiful parks and historical monuments, friendly people and lots of nice places to shop. Thus any travelers who are planning to come to China should definitely visit Beijing during their stay. Transitions for addition: furthermore, in addition, besides, next, first, second, moreover Example: UCLA is a wonderful university to attend as an undergraduate. First, it is respected academically and is well-known for its high standards of education. Furthermore, UCLA has a strong network of alumni who often recruit students to come work for them. Moreover students who do such work as undergraduates often receive jobs with these same companies once they graduate. In addition to these two benefits, UCLA also has exciting sports teams that are fun to watch. Besides, with so many good reasons to go to UCLA, why would you want to go anywhere else? 我的第三条经验就是句酷网站, www.jukuu.com ,一个专门找例句的网站,也许有些虫友也知道。我们写文章的时候,很自然会想到一些中文的表达方法,但是常常苦于找不到贴切的英文表达,查电子词典,往往凑出来的句子也是面目全非。句酷网站提供了一个很好的查找例句的渠道(不是广告奥,呵呵),你可以通过中英文关键字,找到很多例句。比如,我想说 “ 值得指出的是 ” ,在句酷里面查了一下,找到了如下几个句子: It is worth emphasizing that... it is worth pointing out that ... A point worth emphasizing is that... 感觉都还不错,都可以选用。更为关键的是,这些例句一般都会有出处,这样就可以根据例句内容和出处来选择比较地道的表述了。我的一个经验是,对于来自 cnki.net 的例句就得小心点,这些都是国内兄弟写的文章中的句子,常常不是很合适。 今天起得早,又睡不着,写这点东西,希望能对大家有一点点启发。上个月自己的第一篇 trans 的 minor revision 刚刚投出去,这些天一直在焦急的等待中,写点东西与大家分享,也顺便给自己祈祈福。第一次在小木虫写帖子,希望大家能喜欢,欢迎大家一起讨论,批评指正,谢谢!
http://www.autohotkey.com/ AutoHotkey is a free, open-source utility for Windows. With it, you can: Automate almost anything by sending keystrokes and mouse clicks. You can write a mouse or keyboard macro by hand or use the macro recorder. Create hotkeys for keyboard, joystick, and mouse. Virtually any key, button, or combination can become a hotkey. Expand abbreviations as you type them. For example, typing "btw" can automatically produce "by the way". Create custom data-entry forms, user interfaces, and menu bars. See GUI for details. Remap keys and buttons on your keyboard, joystick, and mouse. Respond to signals from hand-held remote controls via the WinLIRC client script . Run existing AutoIt v2 scripts and enhance them with new capabilities . Convert any script into an EXE file that can be run on computers that don't have AutoHotkey installed. Getting started might be easier than you think. Check out the quick-start tutorial . 下面的脚本可以在ctrl+alt+n时,拷贝当前选中文本,然后启动记事本。。方法是先发ctrl-C,实现拷贝文本到剪贴板,然后启动自己的程序。(里面的粘贴部分不起作用,以后再研究。。。) ^!n:: send, ^c IfWinExist Untitled - Notepad { WinActivate Send, ^v } else { Run Notepad WinActivate Send, ^v } return
一、 绪论 1 .三大检索工具简介 科技部下属的"中国科学技术信息研究所"从1987年起,每年以国外四大检索工具SCI、ISTP、Ei、ISR为数据源进行学术排行。由于ISR(《科学评论索引》)收录的论文与SCI有较多重复,且收录我国的论文偏少;因此,自1993年起,不再把ISR作为论文的统计源。而其中的SCI、ISTP、Ei数据库就是图书情报界常说的国外三大检索工具。 SCI,即《科学引文索引》,是自然科学领域基础理论学科方面的重要的期刊文摘索引数据库。它创建于1961年,创始人为美国科学情报研究所所长Eugene Garfield(1925.9.15)。利用它,可以检索数学、物理学、化学、天文学、生物学、医学、农业科学以及计算机科学、材料科学等学科方面自1900年以来重要的学术成果信息;SCI还被国内外学术界当做制定学科发展规划和进行学术排名的重要依据。 ISTP,即《科学技术会议录索引》,创刊于1978年,由美国科学情报研究所编制,主要收录国际上著名的科技会议文献。它所收录的数据包括农业、环境科学、生物化学、分子生物学、生物技术、医学、工程、计算机科学、化学、物理学等学科。从1990-2003年间,ISTP和ISSHP(后文将要讲到ISSHP)共收录了60,000个会议的近300万篇论文的信息。2008年,ISTP更名为CPCI-S(Conference Proceedings Citation Index-Science)。 Ei,即《工程索引》,创刊于1884年,由Elsevier Engineering Information Inc.编辑出版。主要收录工程技术领域的论文(主要为科技期刊和会议录论文),数据覆盖了核技术、生物工程、交通运输、化学和工艺工程、照明和光学技术、农业工程和食品技术、计算机和数据处理、应用物理、电子和通信、控制工程、土木工程、机械工程、材料工程、石油、宇航、汽车工程等学科领域。 2.与三大检索工具相关的其它数据库介绍 SSCI,即《社会科学引文索引》,创刊于1969年,收录数据从1956年至今;是社会科学领域重要的期刊文摘索引数据库。数据覆盖了历史学、政治学、法学、语言学、哲学、心理学、图书情报学、公共卫生等社会科学领域。 AHCI,即《艺术与人文科学引文索引》,创刊于1976年,收录数据从1975年至今;是艺术与人文科学领域重要的期刊文摘索引数据库。数据覆盖了考古学、建筑学、艺术、文学、哲学、宗教、历史等社会科学领域。 ISSHP,即《社会科学和人文会议录索引》,创刊于1979年,收录数据从19?年至今;数据涵盖了社会科学、艺术与人文科学领域的会议文献。这些学科包括:哲学、心理学、社会学、经济学、管理学、艺术、文学、历史学、公共卫生等领域。2008年,ISSHP更名为CPCI-SSH(Conference Proceedings Citation Index-Social Science Humanities)。 3.三大检索工具在索引体系中的位置 (1) 目录和索引的概念及关系 目录是著录一批相关文献(图书、期刊等),并按照一定的次序编排而成的一种揭示与报导文献的工具。目,指文献的篇目名称;录,指文献的内容简介。例如:图书馆的联机公共书目、全国期刊联合目录,OCLC WorldCat、Ulrich's International Periodicals Directory 。 索引是将文献(图书、期刊等)中的篇目、语词、主题、人名、地名、事件及其它事物名称,按照一定的方式编排,并指名出处的一种检索工具。 例如:《十三经索引》、《全国报刊索引》、SCI、Ei等。目录与索引均属二次文献的范畴,都是用来帮助读者利用一次文献(又称"原始文献")的;细微的区别在于:目录揭示文献的整体,索引揭示文献的局部。 (2) 索引的分类 按照索引的编排方式可以分为:形式索引(著者索引、机构索引、号码索引)、内容索引(分类索引、主题索引、语词索引)和关系索引(引文索引、再版索引)。 按照索引的对象(即索引所揭示的原始文献)来可以分为:可以将索引分为:专著索引、报刊索引、会议录索引等。 (3) 三大检索工具在索引体系中的位置 从索引的编排方式来看,SCI属于关系索引,同时兼具形式索引和内容索引的特征;ISTP和Ei具有形式索引和内容索引的特征。 从索引的对象来看,SCI揭示的是期刊中的论文;ISTP揭示的是会议录中的论文;Ei则兼而有之。 二、 如何利用三大检索工具等数据库检索相关主题文献 1.利用SCI、SSCI、AHCI数据库检索相关主题文献 (1) 通过往TOPIC检索入口输入检索主题词获得相关主题文献 (2) 通过往TOPIC检索入口输入检索主题词,然后对检索结果进一步分析获得相关主题文献 (3) 通过往TOPIC和SOURCE TITLE检索入口同时输入检索主题词获得相关主题文献 例子:往TOPIC中输入"nano*",同时往SOURCE TITLE 中输入"ARTIFICIAL CELLS BLOOD SUBSTITUTES AND IMMOBILIZATION BIOTECHNOLOGY or BIO-MEDICAL MATERIALS AND ENGINEERING or BIOMATERIALS or CELLULAR POLYMERS or DENTAL MATERIALS or JOURNAL OF BIOACTIVE AND COMPATIBLE POLYMERS or JOURNAL OF BIOMATERIALS SCIENCE-POLYMER EDITION or JOURNAL OF BIOMATERIALS APPLICATIONS or JOURNAL OF BIOMEDICAL MATERIALS RESEARCH or JOURNAL OF MATERIALS SCIENCE-MATERIALS IN MEDICINE or MACROMOLECULAR BIOSCIENCE", 利用上面的检索式,可以检索出SCI网络版2002年数据库收录"MATERIALS SCIENCE, BIOMATERIALS"类的文章102篇。 2.利用ISTP数据库检索相关主题文献 可以通过TOPIC、SOURCE TITLE、CONFERENCE相结合的方式来检索 3.利用Ei数据库检索相关主题文献 例子:检索医学领域中含有"pipe"的文献 如果仅仅用"pipe"检索在所有字段中检索,会命中4万多条记录;即使同时限制在TITLE中检索,结果也有1万多条,数据冗余太大。这时,可以考虑从学科的角度进行限制检索: 先检索到从Ei Thesaurus中检索医学类目: Medicine:461.6, Medical care:461.7, Medical imaging:461.1,Medical problems, Medical supplies:462.1,Medical computing:723.5,Medical diagnosis, Medical education, Medical equipment,Medical monitoring:462.2 利用"Expert Search":(461.1 wn CL OR 461.6 wn CL OR 461.7 wn CL OR 462.1 wn CL OR 723.5 wn CL) AND (pipe wn TI) 命中500多条记录,因723.5类与计算机应用有关,命中记录中有许多看不出是与医学有关的,可以考虑将该类去掉检索。结果就比较令人满意。 4.利用SCOPUS数据库检索相关主题文献 该数据库提供了学科限制,因而相对容易。 三、 如何利用三大检索工具等数据库检索论文收录情况 1. 利用三大检索工具等数据库检索单位/集体论文收录情况 以清华大学为例: (1) 利用SCI数据库检索单位/集体论文收录情况 (tsinghua univ or tsing hua univ or qinghua univ or qing hua univ or 100084) same (peoples r china or beijing or bei jing) (2) 利用ISTP数据库检索单位/集体论文收录情况 (tsinghua univ or tsing hua univ or qinghua univ or qing hua univ or 100084) same (peoples r china or beijing or bei jing) (3) 利用Ei数据库检索单位/集体论文收录情况 利用作者索引或用复杂检索,但效果均不好。 (4) 利用SCOPUS数据库检索单位/集体论文收录情况 AFFIL(100084 AND tsinghua) (5) 利用CSSCI、《中国期刊网》、《中文科技期刊数据库》检索单位/集体论文收录情况 三个数据库均提供机构检索入口,可以查找单位/集体论文收录情况。 2. 利用三大检索工具等数据库检索个人论文收录情况 以周远翔老师的论文为例子(见附录): (1) 利用SCI数据库检索个人论文收录情况 作者的文献(文章或报告)共有104篇,在这些文章中,他的合作者包括以下八人:N. Yoshimura, 关志成,H. Katoh, 严萍,梁曦东,李光范,M. Nifuku, Atsushi Satake 构建检索式:(zhou yx or yunxiang z) and (Yoshimura n or guan zc or zhicheng g or Katoh h or yan p or ping y or liang xd or xidong l or li gf or guangfan l or Nifuku m or Satake a or Atsushi S) 在AUTHOR字段中输入上述检索式,命中9条记录。与作者提供的论文核对后发现:这9条记录全是作者本人的论文。 还有几篇文献是作者单独完成的,对于这些文献,需要单独处理。 (2) 利用ISTP数据库检索个人论文收录情况 与检索SCI数据库类似,用同样的检索式和同样的方法即可。 在AUTHOR字段中输入上述检索式,命中14条记录。与作者提供的论文核对后发现:这14条记录全是作者本人的论文。比作者事先查好的12篇还多2篇。 (3) 利用Ei数据库检索个人论文收录情况 在高级检索中输入(Ei数据库作者标引与SCI有很大不同:Ei一般要将姓和名写全,而SCI是要求姓写全,名用第一个字母): (zhou, y.x. wn AU OR zhou, yuanxiang wn AU OR yuanxiang, z. OR yuanxiang, zhou OR zhou, y.-x. wn AU OR zhou, yx wn AU) AND (Yoshimura wn AU OR guan, z.c. wn AU OR guan, z.-c. wn AU OR zhicheng, g wn AU OR guan, zhicheng wn AU OR guan, zc wn AU OR Katoh wn AU OR yan, p wn AU OR yan, ping wn AU OR ping, y. wn AU OR ping, yan wn AU OR liang, x.-d. wn AU OR liang, x.d. wn AU OR liang, xd wn AU OR xidong, liang wn AU OR liang, xidong wn AU OR xidong, l. wn AU OR li, gf wn AU OR li, g.f. wn AU OR li, g.-f. wn AU OR guangfan, l. wn AU OR guangfan, li wn AU OR li, guangfan wn AU OR Nifuku wn AU OR Satake wn AU OR Atsushi wn AU) 命中19条记录,这与读者自己检索的27条记录相差8条。 后经检查,发现漏检的8条记录中,有7条作者是"zhou, y",有一条是"zhou, yuanxing"。所以,用上述检索式会漏掉一部分记录;因而我们应再修改一下检索式: 把上述检索式修改为:(zhou, y* wn AU OR yuanxiang, z. OR yuanxiang, zhou) AND (Yoshimura wn AU OR guan, z.c. wn AU OR guan, z.-c. wn AU OR zhicheng, g wn AU OR guan, zhicheng wn AU OR guan, zc wn AU OR Katoh wn AU OR yan, p wn AU OR yan, ping wn AU OR ping, y. wn AU OR ping, yan wn AU OR liang, x.-d. wn AU OR liang, x.d. wn AU OR liang, xd wn AU OR xidong, liang wn AU OR liang, xidong wn AU OR xidong, l. wn AU OR li, gf wn AU OR li, g.f. wn AU OR li, g.-f. wn AU OR guangfan, l. wn AU OR guangfan, li wn AU OR li, guangfan wn AU OR Nifuku wn AU OR Satake wn AU OR Atsushi wn AU)命中34条记录,从中找出了读者有27篇文献被Ei数据库收录。 需要说明的是:利用第一个检索式基本上可以比较准确地检索到作者的文献。只所以利用第二个检索式,是考虑到Ei数据库在数据标引过程中可能出现的小的差错,可以基本上没有遗漏地检索出作者所有被Ei数据库收录的文献。 (4) 利用SCOPUS数据库检索个人论文收录情况 (5) 利用CSSCI、《中国期刊网》、《中文科技期刊数据库》检索个人论文收录情况 四、 如何检索论文被引用情况 1. 检索单位/集体论文被引用情况 (1) 利用SCI、SSCI、AHCI检索论文被引用情况 从收录的角度检索,例子: (tsinghua univ or tsing hua univ or qinghua univ or qing hua univ or 100084) same (peoples r china or beijing or bei jing) (2) 利用SCOPUS检索论文被引用情况 (3) 利用《中国期刊网》检索论文被引用情况 备注:CSSCI、《中国科技论文引文统计分析数据库》均没有提供按单位/集体检索论文被引用情况的入口。 2. 检索个人论文被引用情况 (1) 利用SCI、SSCI、AHCI检索论文被引用情况 从收录的角度检索,例子: (2) 利用SCOPUS检索论文被引用情况 (3) 利用CSSCI、《中国科技论文引文统计分析数据库》、《中国期刊网》检索论文被引用情况 五、 核心期刊投稿导引 1. 期刊评价及评价工具 期刊评价目前已经成为国内外学术界的一个研究热点。在不久前刚刚结束的“第四届大学评价与科研评价国际学术研讨会”上,还将期刊评价同大学评价和科研评价一起作为大会研讨的主题。可见期刊评价的重要性。 关于期刊评价,目前国内学术界有两种观点:一是核心期刊评价法,二是期刊综合评价梯度法。前者简称"0/1法则",后者简称"综合法则"。两种法则都是以传统的情报学文献离散定律、引文分析定律等为理论依据的。只是"综合法则"涵盖了"0/1法则",更加强调梯度的概念。 期刊评价的工具,国外以JCR(Journal Citation Reports)为代表,国内以《中文核心期刊要目总览》、《中国科技期刊引证报告》和《中国学术期刊综合引证报告》为代表。《中文核心期刊要目总览》和《中国科技期刊引证报告》是"0/1法则"评价的结果,《中国学术期刊综合引证报告》是"综合法则"评价的结果。目前我校在研究生培养、科研管理和人事管理工作中以《中文核心期刊要目总览》和《中国科技期刊引证报告》为参考依据。 2. 核心期刊的内涵及国内、国际核心期刊外延的界定 核心期刊的概念可以用一句话来概括:某一学科中高水平、高影响力的期刊。不难看出,核心期刊有两个主要特性:一是学科性,二是学术性。 一般情况下,核心期刊都是在某一个学科范围内来界定的某一个学科的核心期刊,到另一个学科就不一定是核心期刊(当然,综合性学科的核心期刊,如NATURE、SCIENCE等例外)。 核心期刊的学术性主要要是以期刊影响因子来测定的。关于影响因子,有两种统计方法:一种是三年统计法,一种是中期统计法。按三年统计法得出的结果就是目前我们常说的影响因子(IF: Impact Factor:某一种期刊在第三年得到的引文数与该刊前两年的总论文数之比。),按中期统计法得出的结果叫"中期影响因子"(MIF: Median Impact Factor某一种期刊的引文累计达到1/2时,引文数与此时的总论文数之比。)。 目前我校承认的、国际核心期刊主要是指SCI、SSCI、AHCI、Ei数据库收录的期刊;国内核心期刊主要是指《中文核心期刊要目总览》和《中国科技期刊引证报告》收录的期刊(CSSCI 收录的期刊在《中文核心期刊要目总览》中基本上都有)。详细信息参考图书馆 SCI咨询中心 相关栏目。 3. 如何向国内、国际核心期刊投稿? 投国际刊物,请参考 JCR (包括科技版和社科版),选择自己想要找的学科类目,按照影响因子排序,挑选适合的刊物。然后上 《乌利希国际期刊指南》数据库 查找刊物的地址或网站信息,登陆刊物的网站,查找在线投稿信息。 投国内刊物,请参考《中文核心期刊要目总览》和《中国科技期刊引证报告》,从中选择自己想要找的学科类别,然后按照影响力,挑选适合的刊物。投稿地址信息可以参考工具书《中文核心期刊要目总览》,也可以登录" 中国期刊网 ",查找刊物的投稿信息。 在向核心期刊投稿的过程中,需要注意的事项: (1) 尽量不要投增刊。 (2) 单位署名要规范。写清华大学要同时写上Beijing, Peoples Republic of China. 这在SCI中尤其要注意。
刚一看到这个题目,您马上就会提出这样一个问题:有非基于工具的设计吗? 人类是先进工具的创造者和使用者;人类的发展历史也就是发明生产工具的发展史;子曰:工欲善其事,必先利其器(《论语 . 卫灵公篇》)。例如,如果有一种或一组十分有效的工具能够容易地解决在系统仿真及相关领域的教学与研究遇到的问题,它可以将使用者从繁琐、无谓的底层编程中解放出来,把有限的宝贵时间更多地花在解决科学问题中,这无疑会提高工作效率。 据我所知,基于工具的设计( Tool-based Design )思想最早见于 Hanselmann 博士的论文 。 实际上其就是工具的集成,它是一体化设计思想(或者叫集成优化设计思想)的充分体现。路甬祥曾提出五化一新的概念来概括机械电子技术的发展趋势。五化一新包括集成化、智能化、网络化、绿色化、多样化和持续创新。持续创新包括突破性创新和集成化创新。他特别强调:集成化创新: 根据应用的需要,把已有的技术、最适合的技术集成起来,组成一个新的技术,这也是创新,而且是非常有作为的创新。中国航空工业发展研究中心的赵群力 指出集成设计包括技术的集成、系统的集成、过程的集成、人员的集成和管理信息的集成。我想还应该包括工具的集成,而基于工具的设计正是这种集成的体现。 那么什么才算是先进的基于工具的设计过程?产品的设计或开发过程实际上就是设计信息被加工传递的过程,如何正确快速地加工信息,并使其完整顺畅地流向下个设计阶段呢?最好的解决办法就是,在开发过程的各个阶段,都采用先进的工具,组成一个接口一致的工具链,从而形成流线化设计,达到快速、高质量地完成产品开发的目的。这里的要点就是 工具链与接口一致性 。工具之间要匹配,包括 功能、性能和接口的匹配 。 我们不仅要发明单一的先进工具,而且要发明易于集成的工具,这正是我们最应该投入资源去做的。 参考文献: H. Hanselmann, Development Speed-Up for Electronic Control Systems,Distributed on the occasion of Convergence 98, October 1921, 1998, Dearborn, USA 赵群力,飞机一体化设计技术,航空科学技术,2004,3
 标签: 工具
标签: 工具

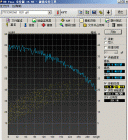
![[转载]分析类工具 3](http://image.sciencenet.cn/album/201301/21/161338edhfozzened5dhf1.jpg.thumb.jpg)
![[转载]分析类工具 2](http://image.sciencenet.cn/album/201208/13/110107ni850uggba5g3532.jpg.thumb.jpg)
![[转载]分析类工具 1](http://image.sciencenet.cn/album/201208/13/105252j3233vjj00u23jjh.jpg.thumb.jpg)
![[转载]管理类工具 2](http://image.sciencenet.cn/album/201207/24/1532267e848qof734ef874.jpg.thumb.jpg)
![[转载]管理类工具 1](http://image.sciencenet.cn/album/201207/24/15235491st19t1or6ols71.jpg.thumb.jpg)
![[转载]计划类工具](http://image.sciencenet.cn/album/201207/24/1425431odd1ndke2mo6nrr.jpg.thumb.jpg)
![[转载]又出现一个“汤森路透 ”和“新版3.1” ?](http://image.sciencenet.cn/album/201206/14/140613em6rvae0zqexeurt.jpg.thumb.jpg)