# 编者信息 熊荣川 明湖实验室 xiongrongchuan@126.com http://blog.sciencenet.cn/u/Bearjazz An approximately unbiased (AU) test that uses a newly devised multiscale bootstrap technique was developed for general hypothesis testing of regions in an attempt to reduce test bias. It was applied to maximum-likelihood tree selection for obtaining the confidence set of trees. The AU test is based on the theory of Efron et al. (Proc. Natl. Acad. Sci. USA 93:13429-13434; 1996), but the new method provides higher-order accuracy yet simpler implementation. The AU test, like the Shimodaira-Hasegawa (SH) test, adjusts the selection bias overlooked in the standard use of the bootstrap probability and Kishino-Hasegawa tests. The selection bias comes from comparing many trees at the same time and often leads to overconfidence in the wrong trees. The SH test, though safe to use, may exhibit another type of bias such that it appears conservative. Here I show that the AU test is less biased than other methods in typical cases of tree selection. These points are illustrated in a simulation study as well as in the analysis of mammalian mitochondrial protein sequences. The theoretical argument provides a simple formula that covers the bootstrap probability test, the Kishino-Hasegawa test, the AU test, and the Zharkikh-Li test. A practical suggestion is provided as to which test should be used under particular circumstances. 为了减少 多区域通用假设检验偏差 ,近无偏检验( AU test )这一多尺度自举检验技术被开发了出来。它应用于最大似然树选择,以得到树的置信集。 AU 检验基于 Efron 等人的理论( Proc. Natl. Acad. Sci. USA 93:13429-13434; 1996 ),但新方法精度更高,操作更简便。 AU 检验,像 Shimodaira-Hasegawa ( SH )检验一样,调整了选择偏差,而这些偏差是被标准自举检验概率方法和 Kishino-Hasegawa 检验所忽略的。选择偏差来自于同时比较多棵树,并且常常导致错误树的过度自信。虽然使用 SH 检验较为保险,但它可能会显示出另一种类型的偏差,即偏保守。在这里,我证明了在典型的树选择情况下, AU 检验比其他方法的偏差更小。这些观点在模拟研究和哺乳动物线粒体蛋白序列分析中得到了说明。理论论证提供了一个简单的公式,涵盖了自举概率检验、 Kishino-Hasegawa 检验、 AU 检验和 Zharkikh-Li 检验。本研究还提出了在特殊情况下应采用何种检验的实用建议。 Shimodaira H . An Approximately Unbiased Test of Phylogenetic Tree Selection . Systematic Biology, 2002, 51(3):492-508.
偶然看到了一个杂志的 Instructions for Authors - Specific requirements , 比较细致地罗列出了 “常用统计检验结果”的写作格式, 如下。 各大期刊的数据统计结果的描述其实也都大同小异,下述格式较为通用,希望对科技论文写作新手有所帮助。 --------------------------------------------- Give means and standard errors/standard deviations with their associated sample size in the format: X ± SE = 35.09 ± 0.07 km, n = 15. When standard deviation/error is shown in an illustration, n should be given as well. Statistical tests use the following formats: (ANOVA, F (1,25) = 8.56, P = 0.035) (Kruskal-Wallis test, H 25 = 123.7, P = 0.001) (Chi-square test, X 22 = 0.23, P = 0.57) (Paired t test, t 24 = 2.33, P = 0.09) (Linear regression, r 2 = 0.94, F 1,66 = 306.87, P 0.001) (Spearman rank correlation, r s = 0.60, N = 33, P 0.01) (Wilcoxon signed-ranks test, T = 7, N = 33, P 0.05) (Mann-Whitney U test, U = 44, N 1 = 7, N 2 = 24, P 0.02) Please either give the exact P-value of a statistical test, or state P0.0xxx, if this is not possible. P=0 is not valid. 上述最后一点我的理解:一定 不能写 P = 0.0000,不管软件统计结果中P值后面是否全是零 ;根据实际情况可以写成 P 0.0001。 ---------------------------------------------------------------
用数据说话系列(4): 独立样本、配对样本及单样本 t 检验 样本数 至少每组多少为宜 梅卫平 Basic knowledge worth spreading! 姑且先不说 t检验前提要求数据服从正态分布,以下两点需要注意: # 注意点一:一般来讲,希望有 80% 以上的统计功效 (Statistical Power Level)假设检验才有效。 # 注意点二: 另外, 效应量(Effect Size,或R语言中为delta),反映处理效应大小的度量。即,两样本 平均数的差异,一般 delta=1 。 # n : number of observations (per group). 结果显示:一般情况(即达到80%以上统计功效的前提下), 两独立样本 双尾 t检验至少需要每组 17 个样本, 两独立样本 单尾 t 检验最少需要每组 13 个样本。 补充: power.t.test(power = 0.8,delta = 1,type = paired) # n= 9.937864 # 双尾 配对样本 t 检验 至少每组 10 个样本 power.t.test(power = 0.8,delta =1,type = paired,alternative = one.side) # n = 7.727622 # 单尾 配对样本 t 检验至少每组 8 个样本 power.t.test(power = 0.8,delta =1,type = one.sample) # n = 9.937864 # 双尾 单样本 t 检验 至少每组 10 个样本 power.t.test(power = 0.8,delta =1,type = one.sample,alternative = one.side) # n = 7.727622 # 单尾 单样本 t 检验至少每组 8 个样本 When delta=1,power against n for independent two-sample t-test(n indicates sample number per group) n 1 2 3 4 5 6 7 8 9 10 Power Na 0.09131 0.1572 0.2224 0.2859 0.3471 0.4056 0.4611 0.5133 0.5619 n 11 12 13 14 15 16 17 18 19 20 Power 0.6070 0.6486 0.6867 0.7214 0.7529 0.7813 0.8070 0.830 0.850 0.8689 n 21 22 23 ... 50 100 1000 10000 … Power 0.8852 0.8997 0.9124 0.9986 0.9999 1 1 Note : two - side t-test. # 计算过程(在R软件中运行)如下: #---------------------------------------------------------- power.t.test(n = 4, delta = 1) Two-sample t test power calculation n = 4 delta = 1 sd = 1 sig.level = 0.05 power = 0.2224633 # 样本数为4的话,统计功效very bad alternative = two.sided NOTE: n is number in *each* group power.t.test(n = 20, delta = 1) Two-sample t test power calculation n = 20 delta = 1 sd = 1 sig.level = 0.05 power = 0.8689528 # 样本数为20 的话,统计功效 good alternative = two.sided NOTE: n is number in *each* group power.t.test(power = 0.80, delta = 1) Two-sample t test power calculation n = 16.71477 # very important # 两样本双尾t test,至少每组17个样本 delta = 1 sd = 1 sig.level = 0.05 power = 0.8 alternative = two.sided NOTE: n is number in *each* group power.t.test(power = 0.80, delta = 1, alternative = one.sided) Two-sample t test power calculation n = 13.09777 # very important # 两样本单尾t test,至少每组13个样本 delta = 1 sd = 1 sig.level = 0.05 power = 0.8 alternative = one.sided NOTE: n is number in *each* group # -------------------------------------------------- # 特定情况,比如:效用值(Effect Size或曰 delta)为2的时候 power.t.test(power = 0.80, delta = 2) Two-sample t test power calculation n = 5.090008 # 特定条件,效用值=2 的情况, 双尾只需要至少每组 5个样本 delta = 2 sd = 1 sig.level = 0.05 power = 0.8 alternative = two.sided NOTE: n is number in *each* group power.t.test(power = 0.80, delta = 2, alternative = one.sided) Two-sample t test power calculation n = 3.987012 # 特定条件,效用值=2 的情况, 单尾只需要至少 每组 4 个样本 delta = 2 sd = 1 sig.level = 0.05 power = 0.8 alternative = one.sided NOTE: n is number in *each* group 参考博文: 1. 李淼新 : 您的t检验显著结果只是因为你的 运气吗? 2. Power calculations for one and two sample t tests 3. Statistical power 4. 统计功效和效应值 5. t.test with varying delta 纰漏和错误之处在所难免,恳请您批评指正! 系列文章 用数据说话系列(1): 样本数,数据顺序对 t test 的影响 用数据说话系列(2): 样本数,数据顺序对聚类分析的影响 用数据说话系列(3): 样本数,数据顺序对方差分析ANOVA的影响 用数据说话系列(4): 各种 t 检验 样本数 至少每组多少为宜 用数据说话系列(5): 非参数检验SteelDwass test和 Dunn test选谁
偏相关系数显著性的检验假设 : Null Hypothesis H 0 : PR =0 , Alternative Hypothesis H 1 : PR ≠ 0. Under the null hypothesis this test statistic will be approximately t-distributed, also with n-2-k degrees of freedom. k为被固定的 解释变量个数。 We would reject H 0 if the absolute value of the test statistic exceeded the critical value from the t-table evaluated at α over 2: 举例: PR =0.711879 , n =37 ,代入得到 t =5.823 ,检验显著性水平 α =0.01 。 查询 t 分布临界表 ,自由度是 37-2-2=33 ,表中没有自由度为 33 的对应数值,选择临近且不大于 33 的 30 , 0.005 对应 2.750 ,意味着 t ( df , 1- α /2) = t (33, 0.995) 临界值是 2.750 。因为 t =5.823 > 2.750 ,拒绝原假设, PR 在 0.01 显著性水平上两种变量具有显著相关性。
rank sum test 秩和检验 秩和检验方法最早是由维尔克松(Wilcoxon)提出,叫维尔克松两样本检验法。后来曼—惠特尼将其应用到两样本容量不等(n1不等于n2)的情况,因而又称为曼—惠特尼U检验。这种方法主要用于比较两个独立样本的差异。 1、假设中的等价问题 设有两个连续型总体, 它们的概率密度函数分别为: f 1 ( x ), f 2 ( x )(均为未知) 已知 f 1 ( x ) = f 2 ( x − a ),a为末知常数,要检验的各假设为: H 0 : a = 0, H 1 : a 0. H 0 : a = 0, H 1 : a 0. H0:a=0,H1, a0. 设两个总体的均值存在,分别记为μ 1 ,μ 2 ,由于 f 1 , f 2 最多只差一平移,则有μ 2 = μ 1 − a 。此时, 上述各假设分别等价于: H 0 :μ 1 = μ 2 , H 1 :μ 1 μ 2 H 0 :μ 1 = μ 2 , H 1 :μ 1 μ 2 H 0 :μ 1 = μ 2 , H 1 :μ 1 μ 2 2、秩的定义 设X为一总体,将容量为n的样本观察值按自小到大的次序编号排列成 x (1) x (2) Λ x ( n ) ,称 x ( i ) 的足标i为 x ( i ) 的秩, i = 1,2,Λ, n 。 例如: 某施行团人员的行李重量数据如表: 重量(kg) 34 39 41 28 33 写出重量33的秩。 因为2833343941,故33的秩为2。 特殊情况: 如果在排列大小时出现了相同大小的观察值, 则其秩的定义为足标的平均值。 例如: 抽得的样本观察值按次序排成0,1,1,1,2,3,3, 则3个1的秩均为(2+3+4)/3=3. 两个3的秩均为(6+7)/2=6.5. 3、秩和的定义 现设1,2两总体分别抽取容量为 n 1 , n 2 的样本,且设两样本独立。这里总假定 n1n2。 我们将这 n 1 + n 2 个观察值放在一起,按自小到大的次序排列,求出每个观察值的秩,然后将属于第1个总体的样本观察值的秩相加,其和记为 R 1 ,称为第1样本的秩和,其余观察值的秩的总和记作 R 2 ,称为第2样本的秩和。 显然, R 1 和 R 2 是离散型随机变量,且有 R 1 + R 2 =( (n1+n2)(n1+n2+1) )/2. 4、秩和检验法的定义 秩和检验是一种非参数检验法, 它是一种用样本秩来代替样本值的检验法。 用秩和检验可以检验两个总体的分布函数是否相等的问题 秩和检验的适用范围 如果两个样本来自两个独立的但非正态获形态不清的两总体,要检验两样本之间的差异是否显著,不应运用参数检验中的 T检验 ,而需采用秩和检验。 秩和检验的方法 1、两个样本的容量均小于10的检验方法 检验的具体步骤: 第一步:将两个样本数据混合并由小到大进行等级排列(最小的数据秩次编为1,最大的数据秩次编为 n 1 + n 2 )。 第二步:把容量较小的样本中各数据的等级相加,即秩和,用T表示。 第三步:把T值与秩和检验表中某α显著性水平下的临界值相比较,如果 T 1 T T 2 ,则两样本差异不显著;如果TT1或T=T2, 则表明两样本差异显著。 例: 某年级随机抽取6名男生和8名女生的英语考试成绩如表1所示。问该年级男女生的英语成绩是否存在显著差异? 男、女生英语考试成绩表 解: 检验步骤: (1)建立假设: H 0 :男女生的英语成绩不存在显著差异 H 1 :男女生的英语成绩存在显著差异 (2)编排秩次,求秩和: T= 13 + 7 + 14 + 12 + 5.5 + 11= 62.5 (3)统计推断:根据 n 1 = 6, n 2 = 8,α = 0.05, 查秩和检验表,T的上、下限分别为 T 1 = 29, T 2 = 61,有 T T 2 ,结论是:男女生的英语成绩存在显著差异。 3、两个样本的容量均大于10的检验方法 当两个样本容量都大于10时,秩和T的分布接近于正态分布,因此可以用Z检验,其基本公式为: 式中:T为较小的样本的秩和。 例: 某校演讲比赛后随即抽出两组学生的比赛成绩如表2,问两组成绩是否有显著差异? 解: 检验步骤: (1)建立假设: H 0 :两组成绩不存在显著差异 H 1 :两组成绩存在显著差异 (2)编排秩次,求秩和: n 1 = 12, n 2 = 14, T = 144.5,代入公式,有: (3)统计推断:因为|Z|1.96,则应保留虚无假设,拒绝备择假设。结论是:两组的演讲比赛成绩不存在显著差异。
Probability and Stochastic Process Tutorial (1) Probability is often characterized as “ a precise way to deal with our ignorance or uncertainty ”. Everyone has an intuitive understanding of the question “what are the chance of (something happening)?”. Stochastic process is then dealing with probabilities over time (or over some independent and indexed variable such as distance). There exist a number of excellent or classic textbooks on probability and stochastic processes. It is one of my favorite oral examine question which I always tell student beforehand to prepare as well as in my opinion the most useful tools of an applied mathematician and/or engineer. http://blog.sciencenet.cn/home.php?mod=spaceuid=1565do=blogid=13708 and http://blog.sciencenet.cn/home.php?mod=spaceuid=1565do=blogid=656455 Yet in my experience it is also one of the most confusing subjects for many students to learn. Why? In this series of blog articles (of which this is the first) I shall try to explain the subject in my own way and my experience in learning the subject. It is NOT my intention to replace the excellent textbooks . The main purpose of these articles, I hope, is that by reading the articles will make the subject matter more approachable and less imposing. They are NOT meant toreplace the many excellent textbook on the subject . I write this article not in the rigorous style required for a scholastic textbook but more in the spirit of a teacher who is engaged in a face-to-face session with a student. It will be highly informal but will make the big picture come across easier. Hopefully, it will even make it possible to read and gain insight to textbooks and articles written in measure-theoretic language. My approach will be strictly from a user point of view requiring nothing beyond freshman calculus and ability to visualize n-dimensional space as a natural generalization of our familiar 3-D space. So here goes . . . Let us start by making one simplifying assumption which for people interested in practical application is not at all important or restrictive. This is the Finiteness Assumption (FA) – We assume there is no INFINITLY large number, i.e., no infinity but there can be very large numbers, e.g. 10^100 (a number estimated to be larger than the total number of atoms in the universe.) If one deals only with real computation on digital computers, this assumption is automatically satisfied. By making this assumption we assume away all the measure-theoretic terminologies that populate theoretical probability literature and confuse the uninitiated. With the FA assumption we now define what is a random variable. Random Variable (r.v.) – a random variable is a variable that may take on any number of finite values when sampled (i.e. looked at). We characterize ar.v. by specifying its histogram. A histogram spells out which sampled values in a range of values the r.v. may take on what percentage of the time. Fig. 1 it a typical histogram. It is actually a histogram of a random variable which is the readership (or hits) of my blog articles for the pastfour years. 23 % 6% 5% 2% 300 1500 2700 3600 4800 6000 7200 8400 9600 Fig. 1 histogram of readership of my blog articles (2009-2013): x-axis is #of hits, y-axis is #of article in this hit range Note each bar of the histogram is expressed as a percentage so that the total sum of bars adds up to one or 100%, i.e., with probability one (for sure) the r.v. takes on values somewhere in the total range. While the range of values this r.v. may take on is finite by virtue of assumption FA , to completely specify a r.v. still can take a great deal of data. (In fact, it took me about 3 hours to collect data and make this graph which is why I did not compile the data for all 5+ year of my blog life) This is inconvenient in computation. To simplify the description (specification) we develop two common rough characterizations. The Mean of a r.v. – Intuitively, if you imagine a cardboard cutout of the shape of the histogram, then the value along the x-axis at which a knife edge placed perpendicular to the x-axis that will balance this cardboard shape is the mean of this r.v..Mathematically, it is simply the average of the value of hits for each article, the ScienceNet in fact compute this value for all bloggers and displays the top-100 bloggers. My own current average happens to be 4130 per article and ranks 26th on the list. Variance of ar.v. - This is a measure of the spread of the histogram. A small variance roughly mean the histogram is mostly spread over a small range of numbers around its mean and vice versa for a large variance. It is a measure of the variability of the values of the r.v.. In stock marketterminology, the b of a stock is simply the variance of the daily value of the stock and a measure of its volatility. Mathematically variance is called the second central moments of the histogram Now we can develop further rough characterization of the histogram by defining what are called its higher central moments, such as skewness of the histogram, which is the third central moment . But in practice such higher moment are rarely needed nor data on these moments often available. So much for a single r.v.. But we often have to deals with more than one random variable. Let us consider two r.v.s, x and y. Now the histogram of the random variables x-y becomes a 3D object. Graphically it looks like a multi-peak terrain map (think of Quilin in the Kwangxi province of south China or the skyscrapers of the Manhattan island of NY). But here a new concept intrudes. It is called “ joint probability ” or “ correlation/covariance (in case of an approximate specification)” between the r.v.s x and y. It captures relationship, if any, between the r.v.s. We are all familiar with notion that smart parents tends to produce smart children. If we represent the intelligence of parents as r.v. x and that of the child is .r.v y, then mathematically we say y is positively correlated with x. If we look down on the 3D histogram of x and y, then we shall see the peaks scatter along a northeast to southwest direction as illustrated in Fig.2 y x Fig.2 bird’s eye view of 3D histogram with correlation In other words, knowing the value of y will give a different idea about the probable value of x. More generally we say x and y are NOT independent but correlated . Mathematically we denote the joint probability p(x,y) (i.e., the histogram) as a general 3D function. We also define conditional probability of x given the value of y as p(x/y) p(x,y)/p(y) or p(y/x) p(x,y)/p(x) Where p(y) and p(x) , called marginally probability of y and x respectively are simply the resultant 2D histograms when we collapse the 3D histogram onto the y or x axis respectively. Graphically, the conditional probability p(x/y) is simply the 2D histogram one sees if we take a cross sectional view of the 3D histogram at the particular value of y. Mathematically we need to divide p(x,y) by p(y) to normalize the values so that p(x/y) will still have area equal to one (100%) satisfying the definition of a histogram. Now it is possible that the bird’s eye view of the 3D histogram is a rectangle (vs. the view of Fig. 2). In other word p(x/y)=p(x) no matter which value of y we choose. In this case, by definition of p(x/y), we have p(x,y)=p(y)p(x). We say the r.v.s x and y are independent . Intuitively this satisfies the notion that knowing y does not tell us anything new about the probable values of x and vice versa about y when knowing x. Computationally, this simplifies a function of 2 variables into product of single variable functions, a great computational simplification when n random variables are involved. To roughly characterize the two generalr.v.s we have a mean vector and a 2x2 covariance matrix with diagonal element the variance of x and y and the symmetrical covariance in the off-diagonal position s x 2 s xy s yx s y 2 To summarize. We have so far introduced concepts 1. Random variable characterized by histograms 2. Rough characterization of histograms by mean and variance 3. Joint probability (3D histogram) of two r.v.s 4. Independence and conditional probability 5. Covariance matrix Now suppose we have n r.v.s instead of two, everything I said about the two r.v.s apply. We merely have to change 2D and 3D to n and n+1 dimensions. The mean of n r.v.s becomes a n-vector and the covariance matrix is a nxn matrix. In your mind’s eye you can visualize everything in n dimension the same way as Fig.1 and 2. The joint probability (histogram) p(x 1 , x 2 , . . . , x) is a n variable function. And if the n variables are independent from each other, we write p(x 1 , x 2 , . . . , x n )=p(x 1 )p(x 2 ). . . p(x n ). No new concepts are involved. Concept-wise, believe it or not, these in my opinion are all you need to know about probability and stochastic processes to function in the engineering world even if your interest is academic and theoretical . In my 46 years of active research and engineering consulting in stochastic control and optimization, I never had to go beyond the knowledge described above. The following articles will simply illustrate and explain how to apply these ideas to more practical uses. Computationally, because of exponential growth, to deal with arbitrary n-variable function is impossible. http://blog.sciencenet.cn/blog-1565-26889.html . Data-wise, it also involve astronomically large amount of data. To simplify notations at least theoretically, we make a continuous approximation of these discrete data and introduce continuous variables and functions. To emphasize, for our purpose, this is only a convenient approximation and simplification. No new ideas are involved. This will be the content of next article. Beyond introducing continuous variables, we also need to develop carious special cases of joint probability structures to simplify description and calculations, subsequent articles will address these issues. Once again, let me emphasize that from my view point these simplifications and special cases are need for computational feasibility and practicality. Nothing conceptually new is involved.
原文地址:http://blog.sina.com.cn/s/blog_5ecfd9d90100cigp.html 在统计学中,柯尔莫可洛夫-斯米洛夫检验基于累计分布函数,用以检验两个经验分布是否不同或一个经验分布与另一个理想分布是否不同。 In statistics , the Kolmogorov – Smirnov test (K–S test) is a form of minimum distance estimation used as a nonparametric test of equality of one-dimensional probability distributions used to compare a sample with a reference probability distribution (one-sample K–S test), or to compare two samples (two-sample K–S test). The Kolmogorov–Smirnov statistic quantifies a distance between the empirical distribution function of the sample and the cumulative distribution function of the reference distribution, or between the empirical distribution functions of two samples. The null distribution of this statistic is calculated under the null hypothesis that the samples are drawn from the same distribution (in the two-sample case) or that the sample is drawn from the reference distribution (in the one-sample case). In each case, the distributions considered under the null hypothesis are continuous distributions but are otherwise unrestricted. The two-sample KS test is one of the most useful and general nonparametric methods for comparing two samples, as it is sensitive to differences in both location and shape of the empirical cumulative distribution functions of the two samples. The Kolmogorov–Smirnov test can be modified to serve as a goodness of fit test. In the special case of testing for normality of the distribution, samples are standardized and compared with a standard normal distribution. This is equivalent to setting the mean and variance of the reference distribution equal to the sample estimates, and it is known that using the sample to modify the null hypothesis reduces the power of a test. Correcting for this bias leads to the Lilliefors test . However, even Lilliefors' modification is less powerful than the Shapiro–Wilk test or Anderson–Darling test for testing normality. Kolmogorov–Smirnov statistic The empirical distribution function F n for n iid observations X i is defined as where is the indicator function , equal to 1 if X i ≤ x and equal to 0 otherwise. The Kolmogorov–Smirnov statistic for a given cumulative distribution function F ( x ) is img class="tex" alt="D_n=\sup_x |F_n(x)-F(x)|," src="http://upload.wikimedia.org/math/3/b/8/3b8599f003f2a131d8084621b1c39640.png" real_src="http://upload.wikimedia.org/math/3/b/8/3b8599f003f2a131d8084621b1c39640.png" title="Kolmogorov–Smirnov test" style="margin:0px;padding:0px;border:0px;list-style:none;" / where sup S is the supremum of set S . By the Glivenko–Cantelli theorem , if the sample comes from distribution F ( x ), then D n converges to 0 almost surely . Kolmogorov strengthened this result, by effectively providing the rate of this convergence (see below). The Donsker theorem provides yet stronger result. Kolmogorov distribution The Kolmogorov distribution is the distribution of the random variable img class="tex" alt="K=\sup_{t\in }|B(t)|," src="http://upload.wikimedia.org/math/1/b/7/1b7fd8f556e7382d973cb6bf95a245ea.png" real_src="http://upload.wikimedia.org/math/1/b/7/1b7fd8f556e7382d973cb6bf95a245ea.png" title="Kolmogorov–Smirnov test" style="margin:0px;padding:0px;border:0px;list-style:none;" / where B ( t ) is the Brownian bridge . The cumulative distribution function of K is given by img class="tex" alt="\operatorname{Pr}(K\leq x)=1-2\sum_{i=1}^\infty (-1)^{i-1} e^{-2i^2 x^2}=\frac{\sqrt{2\pi}}{x}\sum_{i=1}^\infty e^{-(2i-1)^2\pi^2/(8x^2)}." src="http://upload.wikimedia.org/math/2/8/9/2899bf257fc0aa1f48b3ffcff8f783ae.png" real_src="http://upload.wikimedia.org/math/2/8/9/2899bf257fc0aa1f48b3ffcff8f783ae.png" title="Kolmogorov–Smirnov test" style="margin:0px;padding:0px;border:0px;list-style:none;" / Kolmogorov–Smirnov test Under null hypothesis that the sample comes from the hypothesized distribution F ( x ), img class="tex" alt="\sqrt{n}D_n\xrightarrow{n\to\infty}\sup_t |B(F(t))|" src="http://upload.wikimedia.org/math/8/4/2/842d0b1d85ca11aa30ccc90a09936fa4.png" real_src="http://upload.wikimedia.org/math/8/4/2/842d0b1d85ca11aa30ccc90a09936fa4.png" title="Kolmogorov–Smirnov test" style="margin:0px;padding:0px;border:0px;list-style:none;" / in distribution , where B ( t ) is the Brownian bridge . If F is continuous then under the null hypothesis img class="tex" alt="\sqrt{n}D_n" src="http://upload.wikimedia.org/math/1/e/c/1ec425f3720cd63ffabd65504c798972.png" real_src="http://upload.wikimedia.org/math/1/e/c/1ec425f3720cd63ffabd65504c798972.png" title="Kolmogorov–Smirnov test" style="margin:0px;padding:0px;border:0px;list-style:none;" / converges to the Kolmogorov distribution, which does not depend on F . This result may also be known as the Kolmogorov theorem ; see Kolmogorov's theorem for disambiguation. The goodness-of-fit test or the Kolmogorov–Smirnov test is constructed by using the critical values of the Kolmogorov distribution. The null hypothesis is rejected at level α if img class="tex" alt="\sqrt{n}D_nK_\alpha,\," src="http://upload.wikimedia.org/math/8/9/1/891bbf7487bdbedcc202cb47bee880ac.png" real_src="http://upload.wikimedia.org/math/8/9/1/891bbf7487bdbedcc202cb47bee880ac.png" title="Kolmogorov–Smirnov test" style="margin:0px;padding:0px;border:0px;list-style:none;" / where K α is found from img class="tex" alt="\operatorname{Pr}(K\leq K_\alpha)=1-\alpha.\," src="http://upload.wikimedia.org/math/b/b/4/bb4772bb6ae01da6b6a3d1d6b3b43097.png" real_src="http://upload.wikimedia.org/math/b/b/4/bb4772bb6ae01da6b6a3d1d6b3b43097.png" title="Kolmogorov–Smirnov test" style="margin:0px;padding:0px;border:0px;list-style:none;" / The asymptotic power of this test is 1. If the form or parameters of F ( x ) are determined from the X i , the inequality may not hold. In this case, Monte Carlo or other methods are required to determine the rejection level α .
aLRT (parametric bootstrap)和 standard bootstrap(nonparametric bootstrap)的区别,aLRT 是phyML计算支持率的另外一种方法,其中Chi2-based aLRT (approximate Likelihood-Ratio Test) for branches 得到的支持率比较松散,SH-like 得到的比较相近 -b (or --bootstrap) int int = -1 : approximate likelihood ratio test returning aLRT statistics. int = -2 : approximate likelihood ratio test returning Chi2-based parametric branch supports. int = -3 : minimum of Chi2-based parametric and SH-like branch supports. int = -4 : SH-like branch supports alone. aLRT is a statistical test to compute branch supports. It applies to every (internal) branch and is computed along PhyML run on the original data set. Thus, aLRT is much faster than standard bootstrap which requires running PhyML 100-1,000 times with resampled data sets. As with any test, the aLRT branch support is significant when it is larger than 0.90-0.99. With good quality data (enough signal and sites), the sets of branches with bootstrap proportion 0.75 and aLRT0 aLRT (approximate Likelihood-Ratio Test) for branches -b (or --bootstrap) int int = -1 : approximate likelihood ratio test returning aLRT statistics. int = -2 : approximate likelihood ratio test returning Chi2-based parametric branch supports. int = -3 : minimum of Chi2-based parametric and SH-like branch supports. int = -4 : SH-like branch supports alone. aLRT is a statistical test to compute branch supports. It applies to every (internal) branch and is computed along PhyML run on the original data set. Thus, aLRT is much faster than standard bootstrap which requires running PhyML 100-1,000 times with resampled data sets. As with any test, the aLRT branch support is significant when it is larger than 0.90-0.99. With good quality data (enough signal and sites), the sets of branches with bootstrap proportion 0.75 and aLRT0.9 (SH-like option) tend to be similar. Perform bootstrap and number of resampled data sets -b (or --bootstrap) int int 0 : int is the number of bootstrap replicates. int = 0 : neither approximate likelihood ratio test nor bootstrap values are computed. When there is only one data set you can ask PhyML to generate resampled bootstrap data sets from this original data set. PhyML then returns the bootstrap tree with branch lengths and bootstrap values, using standard NEWICK format. The "Print pseudo trees" option gives the pseudo trees in a *_boot_trees.txt file. option) tend to be similar. Perform bootstrap and number of resampled data sets -b (or --bootstrap) int int 0 : int is the number of bootstrap replicates. int = 0 : neither approximate likelihood ratio test nor bootstrap values are computed. When there is only one data set you can ask PhyML to generate resampled bootstrap data sets from this original data set. PhyML then returns the bootstrap tree with branch lengths and bootstrap values, using standard NEWICK format. The "Print pseudo trees" option gives the pseudo trees in a *_boot_trees.txt file. reference linking: http://www.atgc-montpellier.fr/phyml/usersguide.php?type=command http://www.atgc-montpellier.fr/phyml/alrt/
Life is a journey filled with lessons, hardships, heartaches, joys, celebrations and special moments that will ultimately lead us to our destination, our purpose in life. The road will not always be smooth; in fact, throughout our travels, we will encounter many challenges. Some of these challenges will test our courage, strengths, weaknesses, and faith. Along the way, we may stumble upon obstacles that will come between the paths that we are destined to take. In order to follow the right path, we must overcome these obstacles. Sometimes these obstacles are really blessings in disguise, only we don't realize that at the time. Along our journey we will be confronted with many situations, some will be filled with joy, and some will be filled with heartache. How we react to what we are faced with determines what kind of outcome the rest of our journey through life will be like. When things don't always go our way, we have two choices in dealing with the situations. We can focus on the fact that things didn't go how we had hoped they would and let life pass us by, or two, we can make the best out of the situation and know that these are only temporary setbacks and find the lessons that are to be learned. Time stops for no one, and if we allow ourselves to focus on the negative we might miss out on some really amazing things that life has to offer. We can't go back to the past, we can only take the lessons that we have learned and the experiences that we have gained from it and move on. It is because of the heartaches, as well as the hardships, that in the end help to make us a stronger person. The people that we meet on our journey, are people that we are destined to meet. Everybody comes into our lives for some reason or another and we don't always know their purpose until it is too late. They all play some kind of role. Some may stay for a lifetime; others may only stay for a short while. It is often the people who stay for only a short time that end up making a lasting impression not only in our lives, but in our hearts as well. Although we may not realize it at the time, they will make a difference and change our lives in a way we never could imagine. To think that one person can have such a profound affect on your life forever is truly a blessing. It is because of these encounters that we learn some of life's best lessons and sometimes we even learn a little bit about ourselves. People will come and go into our lives quickly, but sometimes we are lucky to meet that one special person that will stay in our hearts forever no matter what. Even though we may not always end up being with that person and they may not always stay in our life for as long as we like, the lessons that we have learned from them and the experiences that we have gained from meeting that person, will stay with us forever. It's these things that will give us strength to continue on with our journey. We know that we can always look back on those times of our past and know that because of that one individual, we are who we are and we can remember the wonderful moments that we have shared with that person. Memories are priceless treasures that we can cherish forever in our hearts. They also enables us to continue on with our journey for whatever life has in store for us. Sometimes all it takes is one special person to help us look inside ourselves and find a whole different person that we never knew existed. Our eyes are suddenly opened to a world we never knew existed- a world where time is so precious and moments never seem to last long enough. Throughout this adventure, people will give you advice and insights on how to live your life but when it all comes down to it, you must always do what you feel is right. Always follow your heart, and most importantly never have any regrets. Don't hold anything back. Say what you want to say, and do what you want to do, because sometimes we don't get a second chance to say or do what we should have the first time around. It is often said that what doesn't kill you will make you stronger. It all depends on how one defines the word "strong" It can have different meanings to different people. In this sense, "stronger" means looking back at the person you were and comparing it to the person you have become today. It also means looking deep into your soul and realizing that the person you are today couldn't exist if it weren't for the things that have happened in the past or for the people that you have met. Everything that happens in our life happens for a reason and sometimes that means we must face heartaches in order to experience joy.
Roche Diagnostics to get indirect boon from new test J.K. WallAugust 22, 2011 KEYWORDS HEALTH CARE, HEALTH CARE INSURANCE, HEALTH CARE LIFE SCIENCES, LIFE SCIENCE BIOTECH, MEDICAL EQUIPMENT, ROCHE DIAGNOSTICS Last week's U.S. approval of a new Roche drug-diagnostic combo for skin cancer won't by itself produce much revenue for its diagnostic division, but it could indirectly be a boon for the company's U.S. diagnostic headquarters in Indianapolis. The U.S. Food and Drug Administration approved a new genetic test to go along with a new Roche melanoma drug on Aug. 17. The BRAF V600 Mutation Test for use in Roche’s cobas 4800 fluid analyzers will determine which patients are eligible for treatment with Zelboraf, the new medicine for patients with late-stage, metastatic melanoma, the most dangerous type of skin cancer. The approval of the drug and test together is a first in U.S. history, although many pharmaceutical and diagnostic firms are working to achieve the same feat. “That really to me substantiates what Roche has been saying for several years, that personalized health care is ... critical for the future,” Jack Phillips, CEO of Roche Diagnostics’ U.S. operations, said in an interview. The money in this approval will come from the drug, which will sell for about $113,000 for a year’s treatment, according to an Aug. 17 report by Goldman Sachs Group Inc. Goldman analysts project Zelboraf could reach sales of $535 million by 2015, with other analysts saying it eventually could approach $1 billion per year. Nearly 70,000 Americans are diagnosed with metastatic melanoma each year. But the number of patients that are in late stages of the disease and have the BRAF V600 mutation likely will only be about 7,000 per year, Deutsche Bank analyst Tim Race wrote in an Aug. 17 report. Roche Diagnostics will sell the BRAF test for about $120 to $150 for each time it’s run, Phillips said. So if Deutsche Bank’s estimates are correct, the test would generate about $1 million a year in revenue. But the real value to Roche Diagnostics is if it helps sell more cobas 4800 machines to laboratories, which will then run all of Roche’s other tests. The cobas 4800 runs a variety of DNA-based tests, such as ones for Chlamydia and gonorrhea, as well as for the human papillomavirus, or HPV. “It really hits medical value and hits a home run around medical value,” Phillips said. He added, “That creates big demand for one test, but it will also drive customers to bring in Roche’s platform to run all our other tests.” Not to mention that each cobas 4800 system costs between $250,000 and $300,000. The new combination was developed in California, where Roche Diagnostics’ molecular research and development team is and where Roche subsidiary Genentech Inc. developed the drug. Roche's corporate headquarters is in Basel, Switzerland. But sales of the test and the cobas 4800 will be handled out of the Indianapolis office.
Well, my old doctor left Kaiser, and I was assigned to a new comer, Dr. P. I haven't seen him, but I decided that I don't want him to be my primary care doctor. Why? I had a routine physical last week, and Dr. P called me about the blood test results, bad results to him. I was puzzled. I never had bad test results before, and less than two years later and I am DOWN HILL to hell? I don't believe it. Hey, I am a scientist, and I can think and web surf. I have a healthy life style. If I have to change my life style, I will go have steak for dinner every day from now on! Bye, Dr. P . I will try another doctor... Blood sugar during 24 hours. Wiki link on blood sugar is at http://en.wikipedia.org/wiki/Blood_sugar#Units To unders tand n on-f ast ing test result: http://health.nytimes.com/health/guides/test/hba1c/overview.html http://en.wikipedia.org/wiki/Prediabetes How to Lower Blood Sugar Naturally http://www.lifescript.com/health/centers/diabetes/articles/10_tips_to_lower_blood_sugar_naturally.aspx Cholesterol: Top 5 foods to lower yournumbers http://www.mayoclinic.com/health/cholesterol/CL00002
Test That Can Determine the Course of Life in China Gets a Closer Examination By Christy Khoshaba The Exam: Nine million students took China's college entrance exam this year, competing for fewer than 7 million university spots. By EDWARD WONG Published: June 30, 2012 Facebook Twitter Google+ Email Share Print Single Page Reprints BEIJING — Millions of high school graduates across China have been furiously dialing telephone hot lines or gathering with family members around the home computer in recent days in a nail-biter of a ritual not unlike that of waiting for a winning lottery number. Connect With Us on Twitter Follow @nytimesworld for international breaking news and headlines. Twitter List: Reporters and Editors Enlarge This Image Agence France-Presse — Getty Images Students arrived for the first day of the college entrance test in June in Wuhan, Hubei Province. The number, in this case, is the score for what is generally considered the single most important test any Chinese citizen can take — the gaokao, or college entrance examination. High school seniors took the test over two to three days in early June. Now, the tests have been graded, the numbers tabulated and the results released, region by region. In the final step, college selections are being made in an opaque process that stretches from late June into July. “When the result came out on June 23, it happened to be my 18th birthday,” said Yang Taoyuan, who lives with his parents in Kunming, capital of the southwest province of Yunnan. “We had a family get-together on that day, and everybody was there when we called over to a hot line to find out about my scores.” In a country where education is so highly prized, the score that a student earns after the days of testing at the end of high school is believed to set the course of one’s life. The score determines not just whether a young person will attend a Chinese university, but also which one — a selection, many Chinese say, that has a crucial bearing on career prospects. But debate appears to have grown more heated lately over the value of the gaokao (pronounced gow-kow). Critics say the exam promotes the kind of rote learning that is endemic to education in China and that hobbles creativity. It leads to enormous psychological strain on students, especially in their final year of high school. In various ways, the system favors students from large cities and well-off families, even though it was designed to create a level playing field among all Chinese youth. Last month, a 12-minute television segment railing against the exam by Zhong Shan, a well-known talk show host in Hunan Province, gained popularity on the Web and became a focal point for fury against the gaokao in particular and the Chinese educational system in general. Also widespread on the Internet were photographs taken in a Hubei Province classroom of students hooked up to intravenous drips of amino acids while cramming. Perhaps most shocking to the public was the story of Liu Qing , a student from Xi’an, Shaanxi Province, whose family and teachers hid from her for two months the fact that her father had died so as not to upset her before the exam. Ms. Liu, according to reports in the Chinese news media, did not hear the news about her father until after she had completed the test. “We Chinese are indeed the most intelligent people in the world,” Mr. Zhong said near the end of his widely broadcast screed. “Is there no way at all we can avoid having the younger generation, the future of our nation, grow up in such a fearful, desperate and cruel atmosphere?” Standardized testing is common throughout the world, and students and parents in nations like the United States, Britain and France also complain loudly about the weight that admissions committees at universities place on such tests. But the admissions process in those countries is still considered much more flexible than that in Asian nations. The emphasis on entrance exams in China, South Korea and Japan induces widespread fear and frustration, leading more and more parents from elite families to look for alternatives, like sending their children abroad. Defenders of the gaokao, which has its roots in the imperial exam system, say the test is a crucial component in a meritocracy, allowing students from poorer backgrounds or rural areas to compete for spots in top universities. Nevermind that the odds are heavily against those students, since a quota system based on residency means it is much easier for applicants in cities like Beijing and Shanghai to get into universities there, which are generally considered the best in China. Peking University, among the most prestigious, does not release admission rates, but Mr. Zhong said on his television program that a student from Anhui Province had a one in 7,826 chance of getting into Peking University, while a student from Beijing had one in 190 odds, or 0.5 percent. (Harvard had a 5.9 percent acceptance rate this year.) 1 2 Next Page Christy Khoshaba contributed reporting from Kunming, China, and Jacob Fromer from Hong Kong. Mia Li and Shi Da contributed research. A version of this article appeared in print on July 1, 2012, on page A 4 of the New York edition with the headline: Test That Can Determine the Course of Life in China Gets a Closer Examination. Page 2 of 2) Even supporters of the gaokao system acknowledge the level of anxiety involved. It is not uncommon for Chinese to have recurring nightmares about cramming for and taking the gaokao years after they have graduated from university. Many schools in China set aside the final year of high school as a cram year for the test. Mr. Yang, the student in Kunming, said he spent 13 hours a day in his senior year studying, and his parents even rented an apartment for him near his school so he would not have to waste time traveling back and forth to his parents’ home. Enlarge This Image Agence France-Presse — Getty Images Parents waited as their children took the college entrance examination in Wuhan in June. Connect With Us on Twitter Follow @nytimesworld for international breaking news and headlines. Twitter List: Reporters and Editors “When I was getting close to the test, pretty much all I did besides eat and sleep was study,” Zhao Xiang, a high school graduate from Zunyi, Guizhou Province, said in an Internet chat interview. He said students’ lives before the gaokao were full of suffering: “Sometimes it was pressure from my family, sometimes it was the expectations from my teacher, sometimes it was pressure from myself. I was constantly in a really bad mood in the period before the gaokao. I was really confused.” A report by Xinhua, the state news agency, said that of the 9.15 million students who took the gaokao this year, about 75 percent would be admitted to universities in mainland China. Once the students get their scores, they submit to education officials a list of universities, ranking them in order of choice. Administrators at the universities then look at the students’ scores and decide whether to admit them for the coming September. Many universities do set aside a few slots for students admitted on the basis of special merit, thus allowing leeway for students who do not take the gaokao or have low scores. Admission in those cases can be based on factors like musical talent, foreign language skills or athletic prowess, as in the United States. Ethnic minority students sometimes get an advantage. Of course, children of senior Communist Party members, government leaders and prominent businesspeople have their own back channels to admission, a phenomenon that exists, too, in the West, though perhaps not to the same degree. There has also been a growing trend of students in China applying to universities outside the mainland. Many Chinese parents — including the party’s top leaders — not only value a foreign degree over one from a Chinese university, but also want their children to avoid the stress of taking the gaokao. An Education Ministry report last year said the number of high school students from top cities leaving the mainland to pursue higher education overseas grew at 20 percent each year from 2008 to 2011. Gao Haicheng, a junior in Kunming, said he planned to apply to universities abroad rather than ones in China. Though avoiding the gaokao is not his main aim, Mr. Gao said the exam “is a big problem in China’s education system.” “In China, they only use marks to explain something,” he added, referring to the emphasis on the gaokao score. Each year, cheating scandals become the talk of China. One common tactic was for students to give their identification cards to look-alikes hired to take the test; later, many provinces installed fingerprint scanners at test centers. In 2008, three girls in Jiangsu Province were caught with mini-cameras inside their bras; their aim was to transmit images of the exam to people outside the classroom who would then provide answers. This year, the big scandal involved students in Huanggang, Hubei Province , famous in the past decade for churning out students with high scores; several dozen students were caught there last month for using small monitors costing nearly $2,500 that resembled erasers and that allowed the students to receive electronic messages with test answers. Zhang Qianfan, a law professor Peking University who has studied the education system, said the main problem was the lack of slots at universities. Despite a boom in university construction in China, there is still a shortage. This year, there are seven million university slots, two million short of the number of gaokao test takers. The gap was much wider in 2006 — there were 5.3 million slots then for 9.5 million test takers. The drop in the number of students taking the gaokao can be attributed to demographic trends in China and the rise in the number of students opting to study abroad. “Many people are harsh critics of the gaokao, but I think they somewhat miss the most crucial point, which is that the supply from decent academic institutions falls short of the demand from the public,” Mr. Zhang said. Students who have received their gaokao scores and are now submitting their choices for universities expect to hear results this month. Mr. Yang, the graduate in Kunming, said by telephone on Saturday that he had put down the University of Shanghai for Science and Technology as his top choice. But he said if he had done better than his score of 517, out of a possible 750, he might have put down the Civil Aviation University of China in Tianjin. “I did the best in my class, so I’m pretty happy with the result,” he said. “So are my parents and most of my friends. But it’s not high enough to get me into the school I’m longing to attend.” Previous Page 1 2 Christy Khoshaba contributed reporting from Kunming, China, and Jacob Fromer from Hong Kong. Mia Li and Shi Da contributed research. A version of this article appeared in print on July 1, 2012, on page A 4 of the New York edition with the headline: Test That Can Determine the Course of Life in China Gets a Closer Examination.
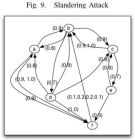
A Model For A Testbed For Evaluating Reputation Systems Partheeban Chandrasekaran and Babak Esfandiari Abstract— The lack of an universal model in reputation systems makes it challenging to evaluate and compare them against attacks. While there are testbeds that provide application domain specific metrics to evaluate reputation systems, in this paper we propose a model for a testbed that is application agnostic. It is a workflow of graph transformations that is generic enough to accommodate a number of reputation systems in existing literature. In doing so, we note that these reputation systems work at different stages in the workflow and as a result, a byproduct of this model is a new classification method. We also describe various attacks using our model. I. INTRODUCTION reputation systems attack : self promoting, white washing, slandering and introducing sybils the organization of this paper: 1) Section 2 present author's model for a testbed to evaluate reputation systems in terms of a workflow, 2)Section 3 illustrate the testbedby examples of reputation systems 3) Section 4then describe attacks against reputation systems and their evaluations. 4) Section 5 presents related work on trust models and existing testbeds. 5) Finally, Section 6 provdes conclusions and roadmap items offuture work II. MODEL A. Obtain Feedback History Graph The feedback t(a; b): indicates the satisfaction received by a from b’s action a feedback history graph: G = (A;E) B. Obtain Reputation Graph two groups of reputation algorithms : global and local Global reputation algorithms: compute reputation values that are unique for each agent in the system local reputation algorithms : compute reputation of agents from the truster’s perspetive how the reputation graph is produced C. Obtain Trust Graph III. EXAMPLES OF REPUTATION SYSTEMS PeerTrust and EigenTrust A. EigenTrust 1) Obtaining Feedback History Graph: 2) Obtaining Reputation Graph: Figure 4 illustrate how the reputation of agents is calculated in EigenTrust 3) Obtaining Trust Graph: B. PeerTrust 1) Obtaining Feedback History Graph: 2) Obtaining Reputation Graph: 3) Obtaining Trust Graph: C. Advogato IV. MODELING AND EVALUATING ATTACKS A. Slandering Attack A slandering attack: B. Whitewashing Attack white washing attacks: agent firstcheat a reputation system by behaving honestly to gain trust from agents and then behaving dishonestly C. Sybil Attack V. RELATED WORK The Agent and Reputation Trust (ART) The Trust and Reputation Experimentation and Evaluation Testbed (TREET) VI. CONCLUSIONS AND FUTURE WORK I comment: I now write a simulating environment for reputation system based on NetLogo. I enjoy this paper and will track author future work. the source code in Sourcefore: trusttestbed A Model For A Testbed For Evaluating Reputation.pdf source code in Sourceforge (2011): trusttestbed.tar.gz
WCEE至今已经举办了很多届了,算是地震工程领域的盛会,届时会有很多该领域的大牛来参会(参考14WCEE在北京的情况),明年是15WCEE,在葡萄牙的里斯本举办,前几天浏览其网站( http://www.15wcee.org/ )的时候发现有一个框架结构的预测竞赛,如下图。这样的比赛可能主要是为了提高会议的趣味性,不过有机会能参加的可以玩玩,提高趣味性。 下面附上该竞赛的相关说明: Design Report (January 2012) - Geometrical and mechanical properties of materials to be used in the construction of models and reinforcement detailing of the tests specimens. Response spectra and reference target input ground motions (low intensity and high intensity) to be used during the seismic tests. Preliminary shake-table input ground motions deemed to be used during the seismic tests. Assessment Report (March 2012) – Test results for the mechanical properties of materials used during the construction of models (compressive, flexural strength and rebound tests for concrete, tension tests for longitudinal steel reinforcement bars). Results for in-situ ambient dynamic characterization tests, detailed photographic report. Updated seismic table input ground motions to be used during the seismic tests. Pre-test Linear response Phase (June 2012) – Shaking table input time histories for low amplitude seismic motions (0.1g PGA) and control points displacement responses for the two models.
We will take the English final test this morning.The teacher assigned each team a topic,our team's topic is "how to educate a child?".well,that's a good question.Here I want express my own opinoin on this topic. First of all,the importance of education can not be too much emphasized.Because it is closely connected with the future of our nation. Education help us to developourscience and technology, education improvethe people's quality ,and it's the education help us lead a better life.In my piont of view,children's education plays the most important role in a man's life.To educate a child well,parents are their children's best teachers.because of this,in the family,the parents should create a good atmosphere ,they must set a good example to their children. Secondly,the children's chioce should be amply respected.parents must give their children enough personal space and freedom,which is very important in the westen education.while in china,it has always been overlooked . Finally,a famousphilosopher once said:"edcation is the power of awakening consciousness",I couldn't agree more! The children themselves should form a good habit,it has a close relationship with the family 、 school and society.Here I want to say,education is not only the parents' responsibility,but the every member of our nation!
When I read this bolg this morning ( http://blog.sciencenet.cn/home.php?mod=spaceuid=569569do=blogid=448000 ) It suddenly downed on me that why couldn't I write the blog in English! I have always been learning English very hard,I passed the college English Bet 4 test when I was a fresh man ,and then got through the Bet 6 test in the following year.Since I became a postgraduate ,because my subject is logistics engineering ,I found that English is more important for me.So I begun to learn English harder then ever before.I am mad about English now. IreadEnglish loudly in the morning ,andlisten the BBC or VOA materialstored in mymp3 player beforegoing to sleep.In a word,I have pieced together all my spare time to learn English well. Now,in the following passage,I'll introduce my learning method: Fisrtly,I have been reciting the new concept English 3 last year .Though I had learnt the textbook when I was a undergraduate .However,I have almost forgot all of the passages I acquinted.Through persistent hard work,I can recite 40 passages very fluently now,and I hope Secondly,To improve my listening ,Ilistenend theVOA special English at first .After that,I begun to listen VOA standard and BBC.Though it's very hard to appreciate all the contents of the liatening material,you can listen it over an over again until you get the every meaaring of the sentence,even the every meaning of the word.As the old saying goes:practice makes perfect.Only through persistent effort can we improve our English. Finally,I want to say the most important thing in learning English.To learn English,you must make it become part of your life,you muststudy English with full of passion,and you must study English with great interest.There is no shortcut on the road to learn English.Here I want to cite the chinese old saying as a conclusion :Diligence is the path to the mountain of knowledge,hard-working is the boat to the endless sea of learning.(书山有路勤为径,学海无涯苦作舟)
最近,在拟合一些样本概率分布时候,用对数正态分布对整个样本拟合还不错,但是尾分布用幂律分布拟合也不错。正纠结于选择什么分布比较合适的时候?我发现Sornette教授提出了一个有效的方法 来判断究竟尾分布究竟是对数正态,还是幂律? 想法源于1999年Journal of the American Statistical Association上一篇关于指数和正态分布检验的论文。因为将服从幂律分布或对数正态分布的随机变量取自然对数之后,即转化为服从指数或正态分布的变量。因此,通过对样本参数的简单变换,就可以将目标问题转化为样本变量服从 指数分布, 还是服从 正态分布 的问题 (个人认为很巧妙!)。 如何计算分布参数?如何进行统计检验?具体就不做介绍了,请重点看文献 第三节的第二小节。 Y. Malevergne, V. Pisarenko, D. Sornette, Physical Review E 83 , 036111 (2011). J. D. Castillo, P. Puig, Journal of the American Statistical Association 94 529-532 (1999).
1 、 Food: What are some American table manners? Dont eat too fast; Dont talk with your mouth full of food; Dont chew with mouth open; Dont talk about dirty things at the table; Dont eat with your elbows on the table; Dont sing; Dont reach for food that is far from you; Dont leave until the meal is over. Dont wave your hands around. Dont suck your soup. Dont throw anything on the floor/table; Dont keep bags or other objects on the table; Dont keep offer someone food if they say are full; Dont put food on someone elses plate. Dont pour someone a drink unless they request it. Dont drink soup from the lip of your bowl. Do pass food to others. Do ask politely for people to pass food to you. Do dab your mouth with your napkin. Do place your napkin on your lap; Do sit up straight when eating; Do keep food or anything you cant eat on your plate. Do say excuse me if you burp accidently. How are they different from Chinese? Americans do not eat: Blood, Eyes, Skin, heart, stomach, organs, feet, hands, liver, head. But Chinese eat these kinds of things. Different types of dishes: Salty; Sour ; Sweet; spicy; crunchy; Bland; Rich Tears are Salty; cherry, orange and grapes are Sour; lots of fruit taste sweet; Peppers tastes spicy; fried chicken\biscuits are crunchy; custard( 奶油蛋糕 ) tasts Bland; some fried food and butter are Rich. 2 、 Speeches: What are some qualities of a good speech? 1. Adjust yours peed of speaking; 2. Vary your pitch; 3. Use pauses; 4. Monitor your volume; 5. Body language; 6. Eye contact; 7. Show emotion; 8. Eliminate filler words; 9. Consider your audience; 10. Practice. What do you want to do?What do you not want to do? I think making a good speech needs four steps: The first step is analysis. Analyzing what? The answer includes what, whom, where, when, why and how long. That means you must know why you need to do the speech, is the speech necessary or unnecessary? What kind of information do you want to give to your audience? What kind of person want to attend your speech? Their age, job, interests, and motivation. When and where your speech will take place? Are there any special requirements for the time and place? How long will your speech last? The questions above are very important, if you havent analyzed, youll confused the focus group and what can you do for them, especially, you wont know how to enter the next step. The next step is preparation. I know your guys want to ask me prepare what. Ok, it is a good question. Let me tell you, we prepare materials and equipments, contents and emotion; we need to prepare everything if we want do a good speech. We prepare to write down all the sentences ahead, we prepare to recite it again and again until we can remember every word. We prepare to speech in front of the family or a mirror to check our gesture and expression. Id like to say if we prepare perfectly, well be confident to enter the third step. The third step is delivery. Delivery will tell us whether the speech is good or not. So, how should we deliver the speech? My suggestion is, firstly, we must be confident, we must believe were the best and we can conquer everyone. We can take a deep breath to relax before we start. Secondly, we must speak loudly and clearly, the last but not least, logic is very important also, but how can we do logically? we can list the key points and expand according to them. And I think if we can add some humorous factors to the speech, it must be excellent. Certainly, humor is not suitable for everyone, but we can learn it from me, because Im a humorous guy. The forth step is check. As we cant watch how we show in the speech, we must need help from others. After we finished the speech, we can talk with the audience to get some feedback and suggestion. So we can learn what need to be changed if we want make it better next time. Analysis, preparation, delivery and check are the four steps in a speech, we can do a perfect speech if we can finish every step perfectly. Thats my opinion, and thank you! Why are people frightened by public speaking? Forget what to say; Make some errors; Be laughed at; no self-confidence. What can they do to overcome that fear? What is needed to organize a good speech? What is needed to make a complete speech? How can you make a speech flow smoothly? 1. Know your material. Pick a topic youre interested in. Know more about it than you include in your speech. Use humor, personal stories, and conversational languagethat way, you wont easily forget what to say. 2. Practice, practice, practice! Rehearse out loud with all the equipment you plan on using. Revise as necessary. Work to control filler words; practice, pause, and breathe. Practice with a timer and allow time for the unexpected. 3. Know the audience. Greet some of the audience members as they arrive. Its easier to speak to a group of friends than it is to speak to strangers. 4. Know the room. Arrive early, walk around the speaking area, and practice using the microphone and any visual aids. 5. Relax. Begin by addressing the audience. It buys you time and calms your nerves. Pause, smile, and count to three before saying anything. Transform nervous energy into enthusiasm. 6. Visualize yourself giving your speech. Imagine yourself speaking, your voice loud, clear, and confident. Visualize the audience clappingit will boost your confidence. 7. Realize that people want you to succeed. Audiences want you to be interesting, stimulating, informative, and entertaining. Theyre rooting for you. 8. Dont apologize for any nervousness or problemthe audience probably never noticed it. 9. Concentrate on the message, not the medium. Focus your attention away from your own anxieties and concentrate on your message and your audience. 10. Gain experience. Mainly, your speech should represent youas an authority and as a person. Experience builds confidence, which is the key to effective speaking. A Toastmasters club can provide the experience you need in a safe and friendly environment. 3 、 Small talk: Why is small talk good? Small talk is gossip, chitchat, unimportant chatter, small being the significant adjective pointing to its, well, insignificance. There are a few different reasons why people use small talk. The first, and most obvious, is to break an uncomfortable silence. Another reason, however, is simply to fill time. That is why it is so common to make small talk when you are waiting for something. Some people make small talk in order to be polite. You may not feel like chatting with anyone at a party, but it is rude to just sit in a corner by yourself. After someone introduces you to another person, you do not know anything about them, so in order to show a polite interest in getting to know them better, you have to start with some small talk. talk is cheap, but chatting up strangers you meet on business trips is sometimes profitable. What does small talk do for you? It can give me some English practice that is interesting, and, second, it can lay the foundation for friendly exchange and perhaps a friendship. It makes me relax and not bored. What are some things you talk about with small talk? Weatherjob journey traveling school news What do you not talk about? politics, Religion and personal questions, Age, Money, Salary, The bad thing about others and marital status. 4 、 Values Honest: what do you find valuable? What do you value in another person? Appreciation. Taking a brief moment to say, thank you, or acknowledging the exceptional job the restaurant server did when waiting on you is not only encouraging for the beneficiary to hear; it fills your soul with more appreciation too. Believe in Others. It can be your attitude; your resolve, that can lift someone up when they are down. Their doubt can be erased by your confidence. And something else amazing happens: belief is contagious the more you believe in others; the more you will continue to believe in yourself. Caring. Caring for others, as well as self-care, allows you to extend a helping hand and to pass along some unexpected grace. When we take the time to demonstrate we care; we demonstrate the fact there are still plenty of good people left in this world. Commitment. Commitment shows loyalty and it can show bravery and tenacity as well. A commitment is a promise made and an expectation we have created. Honoring our commitments can make the difference between achieving whats most important to us or feeling disappointed and defeated. Compassion. We are all part of this thing called the human condition. No doubt we have different skin colors, religious preferences and political points-of-view, but at the end of the day, we still need to take care of one another. Cooperation. Even the most complex tasks and assignments can be made simpler when we focus on the solutions together. Courtesy. The next time you are approaching a door and someone is ten steps or so behind you, wait just one second longer before walking through. Instead hold the door for that one second. Its amazing how something that can happen in a blink of an eye can carry so much lasting value. Dedication. No matter how the circumstances may change, unless you are in a physically or emotionally abusive situation, stay the course and never give up. I would rather be called a failure than a loser. Losers give up when things become too difficult. Failures are folks who have just not found success but will. So, call me a failure if you like, because it implies I havent stop trying. Devotion. Some days are just naturally better than others. Its the same way in our interpersonal relationships and in our faith. Things can get unstable at times, but staying devoted to a cause or to a person through the uncertain times is our rock to grasp when our faith and our foundation is shaky. Effort. No matter the outcome, there is always value in the effort when the effort is authentic and well-intended. Forgiveness. To be clear, the purpose of forgiveness is not to absolve someone of the sin(s) committed against you; but to free yourself from the pain and the anger that is keeping you stuck. When you forgive, you are better able to let go of the past and keep moving forward with your life. Friendship. Friends support us and they provide an unfiltered view of our actions when asked. Friends sustain us through difficult periods and join us for the events we celebrate. Do you think it is ok to lie?when? to who? Why is it ok to lie? What are white lies and are they ok? Out of all of the virtues that is available to the human character, I prize honesty above all else. Let us start with the definition of honesty: 1. the quality or fact of being honest; uprightness and fairness. 2. truthfulness, sincerity, or frankness. 3. freedom from deceit or fraud. Although definition #2 states truthfulness, I think it is essential to discriminate two different types of honesty: #1: Objective Honesty: Truthfulness. This implies admitting ignorance if one does not know truthfulness. #2: Subjective Honesty: Sincerity. This implies that the communication of one's opinion, not necessarily truthfulness, is free from deceit or fraud. Due to the majority of peoples' communications are based in subjective ideas such as emotions and opinions, Subjective Honesty is the most common type of honesty and will be the focus of this thread. (I happen to value Objective Honesty over Subjective Honest, but that is just me being Subjectively Honest. ) To explain why I value honesty, I must start with the opposite of honesty, deceit, lies, and fraud: A lie (also called prevarication), is a type of deception in the form of an untruthful statement, especially with the intention to deceive others. People lie for many reasons, but the primary motive is fear of the consequences of telling the truth. We can all think of the cliche example of your friend asking you if they look fat when objectively, they are. Do you slip in a white lie to assuage their self esteem, or do you be brutally honest and tell them the opposite of what they want to hear? Personally, like the undiplomatic prick I am, tell the brutal and honest truth. Why? My friend is hungry for my opinion, something that is free and easy to give. Not giving your opinion to someone who really wants it is the equivalent of having an infinite supply of food but not giving it to a starving man. It is, frankly, selfish. Hey! Telling a white lie is...selfish? WHAT? Yes. It is selfish. I do not see telling white lies, or any other type of lie, as a beneficial thing at all. When you are not honest, you deprive others of something that is very easy to produce. It is deception of the very worst kind, it is personal and a breach of trust. If someone likes you when you lie and do not like you when you are brutally honest, they were never your friend to begin with. Do not think you are helping people when you tell lies, no matter how white they may seem. White is such a fucking fake color it makes me sick. White is the color of fraud, censorship, sterilization, false innocence and worst of all, insincere smiles. Nothing is pure in this world, opinions are markers of these imperfections, and they are what makes people be people. If you want convenient lies, go to your church or go to your congressman. If you want the truth, and nothing but the truth ,then I am here. There are two types of secrets; those we keep from others, and those we keep from ourselves. 5 、 Wants: What would you like to change in yourself? Change my life for the better, and more beautiful appearance, better behavior and abilities. What do you want most in your life? Have a good job, a happy family, heathy body. What do you do that you dont want to do? Sometimes I will do and sometimes I wont do.For example. What did you want to do when you were a child? I always wanted to be a teacher (and guess what - I am). I really can't remember when I decided that's what I wanted to do but it was while I was at infant school, as I can remember at some point telling my mum that I wanted to be just like Mrs Raynor (the headteacher). A story that my mum loves to retell to anyone. Although now that I have been teaching for nine years I really don't like the idea of being a head teacher, at least not at this point in my career, there is just far too much paper work being a class teacher, let alone being the head. What things do your parents for you? 1. My parents look after me sometimes 2. My parent also help me out while I have trouble! 3. My parents take me to park when I am on birthday 4. My parents buy clothes for me ! 5. My parents wish us happy 6 、 Stress What stresses you out? If Ive got the time I find going for a good long walk usually relaxes me, especially where I live as Im deep in the countryside so can walk through woods or through parks and can walk for miles without passing many cars. If I am with a friend this is our time to unburden on each other and talk through whats going on in our lives (better than therapy) So the exercise makes you feel better and the scenery is uplifting, and the various wildlife makes me smile. I always feel better when I return home. If Im stuck in the house my music helps wind me down. Is competition a good thing or bad thing? I think everything has its good and bad aspects. On the one hand,..,on the other hand, How do you handle stress? some best ways to manage the stress can be share below:- 1) good attitude to exercise 2) good tolerance of self realisation 3) modulation 4) balance 5) sharing 6) caring for society 7) emphaty Can stress be a good thing? Mostly sress is a bad thing because it can cause many problems,such as physical problems and mental problems.Some people often tense angry and overwhelems,like stress in them life is spining out of control,then stress is hurting them heart,it is very terrible,and possbility leads to death.However,there are also advantages,we can get some benifits from stress,for example,power,if there is not stress,wewillnot have any power to go long. I think stress is positive or negative, we needhave a little stress so that we had enough energy to go, moreover, we should avoid over-time in order to keep our health and happy. therefore, stress is a good thing rather than bad thing. 7 、 Thanksgiving : What are you Thankful for? I will be thankful everything that happens in my life. My parents give me the chance to live in the world, I can feel I am loved by them every minute. I have so many friends. I often touched by their loyalty. I feel I am the flowers, which planted by my lovely teacher selfless. Anyway, all the good things around me like the sweet candy can! I will cherish them forever! Why do Americans celebrate Thanksgiving Day? There are many reasons to celebrate Thanksgiving 1 be harvest - for the past 6,000 years, ever since humanity discovered agriculture, human societies have celebrated the harvest. Globalization and industrialization has made modern man less dependent on the sesonal harvest, but we still depend upon the earth to grant us our food. 2 national unity - it was President Abraham Lincoln that first declared Thanksgiving a national holiday as one more way to unite the North and the South after the War. 3spiritual renewal - most religions teach the spiritual benefits of expressing gratitude toward God for all our good fortune. 4 national pride - although Plymouth colony was not the first English colony in North America, the story of Plymouth colony makes a far better origin story for the United States than the failed colony at Jamestown, Virginia. 5 Native American appriciation - twice a year, Americans are reminded of the pivotal role of the Native Americans in their own history. It should never be forgotten that when the Native Americans discovered the Plymouth colonists freezing and starving, they taught them how to plant food in the New World. In the early fall of 1621 the 53 surviving pilgrims celebrated their successful harvest, as was the English custom. During this time ,many of the Indians coming...amongst the rest their great king Massasoit, with some 90 men. The 1621 celebration is remembered as The First Thanksgiving. In Plymouth, Pilgrims did not call this harvest festival Thanksgiving, although, they did give thanks to God. To them, a day of thanksgiving was purely religious. The first recorded religious day of thanksgiving was held in 1623 in response to a providential rainfall. The religious day of thanksgiving and the harvest festival involved a single event. What do they do on Thanksgiving? Thanksgiving Day is the most truly American of the national Holidays in the United States and is most closely connected with the earliest history of the country. The pattern of the Thanksgiving celebration has never changed through the years. The big family dinner is planned months ahead. On the dinner table, people will find apples, oranges, chestnuts, walnuts and grapes. There will be plum pudding, mince pie, other varieties of food and cranberry juice and squash. The best and most attractive among them are roast turkey and pumpkin pie. They have been the most traditional and favorite food on Thanksgiving Day throughout the years. Everyone agrees the dinner must be built around roast turkey stuffed with a bread dressing to absorb the tasty juices as it roasts. But as cooking varies with families and with the regions where one lives, it is not easy to get a consensus on the precise kind of stuffing for the royal bird. Thanksgiving today is, in every sense, a national annual holiday on which Americans of all faiths and backgrounds join in to express their thanks for the year' s bounty and reverently ask for continued blessings. 3. Lies, honesty and value ( complementary ) Do you think it is ok to lie?when? to who? Why is it ok to lie? If it will cause someone harm in telling the truth, like someone with a gun is running after someone to kill them and they say to you which way did he go? a lie would be ok so no one gets hurt . Well, Emily Post says to tell a little white lie not to offend someone. So let's say someone has a ugly baby. You don't tell them you have an ugly baby. You say something like, oh, what a lovely baby. Or if some relative you can't stand invites you to dinner. You say you have a prior engagement or you have a headache. The lie is allowable because you don't want to offend somebody by telling the truth. What are white lies and are they ok? We have all been taught that it is wrong to lie,and yet we all tell little lies every day.These are white lies and,in my opinion,they are perfectly okey.We don't tell white lies to hurt others or gain some advantage.On the contrary,we tell them to make others feel better. White lies can accomplish many things.First of all,they can hide painful truths and thereby prevent heartache and suffering.At times,white lies are better than the truth.Second,white lies can encourage others.They are a potent psychology that can turn a life around.Third,they can bring happiness.Without white lies,children would not have the fun if believing in Santa Claus. Finally,they are a part of our culture.Everyone tells them because they make communication easier and more pleasant. In onclusion,although we all know that honesty is the best policy,sometimes a white lie is more approprite than the truth.White lies are harmless and useful and they make this world a better place. 4. Wants What would you like to change in yourself? I want to get a lot of knowledge so that I can absolve problems more easily. I want to change my character because I am not self-confidence. I like to read news ,but it waste a lot of precious time, and I want to use these time more efficient. What do you want most in your life? I want have a good memory, so I can remember everything I need to be remembered. I want to have time to travel with my family. I want to work in my hometown because there are a lot of my relatives there and I adapt the climate there. It has blue skies and fresh air and less polluted. I love my hometown. What do you do that you dont want to do? I dont want to read my PHD, but I have to because I want to be with my family. need me, My family and my lovely son need me because my wife is too tired to rear our child alone. What did you want to do when you were a child? When I was a senior middle student, I wanted to be a teacher. Now, I do be a teacher.When I was a child, my family is poor and I needed a pair of rainshoes. What things do your parents for you? They worked hard to earn money to support the family. They buy toys and candies for me. But the most important thing is they spent so much money to send me to the school. They want me healthy, wealth, and happy.
i met a middle-age man. he said that he had passed the test of English . 3 hours. 40m of writing an assay, which he like to do . it deals with such item why do persons may make diffenrenc dicions When they face the same situation. He said he like study ,but not test.
大样本 计数资料 --Karl Pearsons chi-square test 小样本 计数资料 --R.A. Fisher s exact test 四格表: Var.1 -------------- a b r1=a+b Var.2 c d r2=c+d -------------- c1=a+c c2=b+d n=c1+c2 阈值: 每一个matrix的格子的资料量在 5 以上就可以使用chi-square test,反之用 Fisher's exact test ; Fisher's exact test不需要假设资料满足什么分布。 When To Use Fishers Exact Test 統計方法應用---Fishers Exact Test 應數博黃士峰 Calling on Matlab the function Fisherextest
Psychological test The major categories of tests 1. Mental ability tests n Memory, spatial visualization, n creative thinking n IntelligenceWechsler Adult Intelligence WAIS n Stanford Binet Intelligence Scale 2.Achievement tests Attempt to assess a persons level of knowledge or skill in a particular domain. Achievement batteries used in elementary and secondary schools(Stanford achievement testSAT) All batteries consist of a series of tests in such areas as reading, mathematics , language, science and social studies. single-subject tests It covers only one area, such as psychology, or geometry An example of such a test: Graduate Record Examinations (GRE) : SUBJECT TEST IN PSYCHOLOGY the third subdivision n An incredible variety of tests used for purposes of certification and licensing in some fields such as:nursing, teaching, physical therapy, airline piloting They have important consequences for people in specific vocational fields. Statewide achievement testing programs test reading, writing, and mathematics abilities. National assessment of educational progress NAEP Government-sponsored programs These four types of achievement tests are typically group administered. Individual achievement tests It aids in the diagnosis of such conditions as learning disabilities 3 、 personality test objective personality tests Objective: the tests are objectively scored based on items answered in a true-false or similar format. Minnesota Multiphasic Personality Inventory (MMPI) Eating Disorder Inventory EDI Beck Depression Inventory BDI Projective techniques The examinee encounters a relatively simple but unstructured task. n Rorschach Inkblot Test n Human figure drawings, n Sentence completion 4. Vocational interest measures n Encompasses measures of interests, values, attitudes. n Wildly used in high schools and colleges to help individuals explore jobs relevant to their interests. n Strong Interest Inventory SII n Kuder Occupational Interest SurveyKOIS 5. Neuropsychological tests n Designed to yield information about the functioning of the central nervous system, especially the brain. 、 n Much neuropsychological testing employs ability tests and often uses personality tests Uses and users of tests Four major uses n ①Clinical n Clinical psychology n Counseling n School psychology n neuropsychology n Testing helps to identify the nature and severity of the problem and provides some suggestions about how to deal with the problem. ②Educational Group-administered tests of ability and achievement The actual users of the test include teachers, educational administrators, parents, and the general public ③Personnel primary users : Businesses and military The first task: select individuals most qualified to fill a position The second task: provide useful information about the optimum allocation of the human resources in this scenario ④ research Used in every conceivable area of research in psychology, education, and other social /behavior science. The research usagewas identified three subcategories Fundamental questions about tests Reliability : Refers to the stability of test scores. Validity; refers to what the test is actually measuring. n Norms: n Norms are based on the test scores of large groups of individuals who have taken the test in the past. n Exercise : n 1. Here are three traits: height, intelligence, friendliness. In which of these traits do you think people differ the most? n 2. See if you can remember the full names for each of these sets of initials. n GRE n EDI n SII n MMPI psychotherapy The systematic application of techniques derived from psychological principles by a trained and experienced professional therapist, for the purpose of aiding psychologically troubled individuals Individual psychotherapy One therapist treats one client at any one time Psychoanalysis: An attempt to induce ego-weakness so that repressed material can be uncovered The client can achieve insight into his or her inner motivations and desires Resolved childhood conflicts can be controlled It may not be appropriate for certain types of individuals: 1 Nonverbal adults 2 young children who cannot be verbally articulate or reasonable 3 Schizoid persons 4 Those with urgent problems requiring immediate reduction of symptoms and the feeble-minded. Four methods of psychoanalysis 1 Free association 2 Analysis of resistance 3 Transference 4 interpretation Hypnotherapy The use of hypnosis as an adjunct to psychotherapy. Person-centered therapy Accept clients as persons, empathic and respectful and unconditionally positive in their regard for client. A therapist should not control, inhibit, threaten, or interpret a clients behaviors. l A therapist should be in the therapeutic relationship rather than the precise techniques to use in therapy. Cognitive-behavioral therapy Helping clients develop perceptual skills with which to interpret environmental inputs and internal stimulation. Techniques of Cognitive-behavioral therapy l Cognitive restructuring The clients cognitions are changed from irrational, self-defeating, and distorted thoughts and attitudes to more rational, positive and appropriate ones. Coping skills training Help clients learn to manage or overcome stress. Group therapy A form of therapy that involves the simultaneous treatment of two or more clients. Commonalities of group therapy 1. Allow each client to become involved in a social situation and to see how his or her behavior affects others. 2. The therapist can see how clients respond in a real-life social and interpersonal context. 3. Group members can develop new communication skills, social skills and insights 4. Groups often help their members to feel less isolated and fearful about their problems. 5. Groups can provide their members with strong social and emotional support. Some types of therapy groups l Sensitivity training groups(T-groups) l Assertiveness training groups l Psychodrama Compliance Effective treatment depends on two aspects: Correct treatmentandThe patients following through with treatment Causes of Noncompliance The cause of non-compliance The chief cause: communication problems between physicians and patients The second source : the characteristics of treatment itself. Behavioral and environment factors may reduce compliance. Compliance: The extent to which patients behavior (in terms of taking medications, following diets or other lifestyle changes) coincides with medical or health advice. Try to illustratee How to improve the compliance according to the theory and your own view. Oral information 1\ primacy effect 2\ to stress the importance of compliance 3\ to simplify the information 4\ to use repetition 5\ to be specific 6\ to follow up the consultation with additional interviews. Written information Written information about medication increased knowledge in 90 per cent of the studies, Increased compliance in 60 per cent of the studies Improved outcome in 57 per cent of the studies Intervention to improve compliance Three general approaches: 1.education: Give patients clear, explicit, written instructions about how treatment is to proceed. 2. Modification of treatment plan. Reorganize the treatment in ways that facilitate an individuals adherence to it. tailoring the taking of medication to existing daily habits Giving the treatment in one or two injections rather than in several doses per day Packaging medicine in dosage strips or with pill calendars Scheduling more frequent follow-up visits to supervise compliance 3.behavior modification ①Environmental cues: such as postcard reminders telephone calls wristwatches set to emit a tone at the time a pill should be taken ②self-monitoring ③contingency contracts between patient and physician ④token economies Try to explain HBM. Originated by Rosenstock, focused by Becker and Maiman on the specific question of noncompliance. HBM is a social-psychological theory 1. How susceptible to a given illness individuals perceive themselves to be and how severe the consequences of the illness are thought to be 2. How effective and feasible versus how costly and difficult the prescribed treatment is perceived to be. 3. The influence of internal cues plus external cues in triggering health behaviors 4. Demographic and personality variables as well as structural and social characteristics that modify the influences on the other variables. placebo Which case is the one for illustrating the function of placebo? My headache went away after having a sugar pill After I had my hip operation I stopped getting headaches I had a bath and my headache went away Placebo: Inert substances which cause symptom relief. Substances that cause changes in a symptom not directly attributable to specific or real pharmacological action of a drug or operation Any therapy that is deliberately used for its non-specific psychological or physiological effects. The use of placebos n 1. increase performance on a cognitive task n 2.to be effective in reducing anxiety n 3. have effect on series of areas: allergies, asthma, cancer, diabetes, enuresis, epilepsy, insomnia, ulcers, obesity . n 4.reduce the pain which is one of the most studied areas in relation to placebo effects How do placebos work 1.Non-interactive theories Characteristics of the individual Certain individuals have characteristics that make them susceptible to placebo effects. Emotional dependency, extraversion, neurosis and being highly suggestible. Characteristics of the treatment The characteristics of the actual process involved in the placebo treatment relates to the effectiveness or degree of the placebo effect. For example: if a treatment is perceived by the individual as being serious, the placebo effect will be greater. n Characteristics of the health professional The kind of professional administering the placebo treatmentmay determine the degree of the placebo effect. For example: Higher professional status and higher concern have been shown to increase the placebo effect Interactive theories n Placebo effects should be conceptualized as a multi-dimensional process that depends on an interaction between a multitude of different factors Physiological theories Physiologists focus on pain reduction. Levine: placebos increase endorphin release-the brains natural painkillers-which therefore decreases pain.
 标签: test
标签: test