前几天在关于中国缺水城市个数的讨论中,几位朋友论及国际水资源安全标准,陈昌春教授也发过一篇相关博文,资料很丰富( “国际公认的人均1700立方米的水资源紧张警戒线”是如何公认的? ) 。我2002年曾在《地利科学进展》上发表一篇文章“ 区域水资源压力指数与水资源安全评价指标体系 ”,初步做了介绍,现整理如下,供参考和讨论。 反映人类对水资源压力 ( water resources stress )大小的 指标,或衡量一个国家或地区水资源稀缺程度的指标,可以较粗略地反映一个国家或地区的水资源安全程度。目前 国际上通用的宏观衡量 水资源压力 的指标有 2 个:一是区域人均水资源量,二是水资源开发利用程度。但这些指标的使用有两个方面需要注意:一是这些指标的建立都有假设条件,二是这些指标存在一些弱点。 1 人均水资源量 1989年,瑞典著名水资源学者 Falkenmark 等人根据100万方水资源供养的人口数量,把水资源压力分成5个等级:0-100、100-600、600-1000、1000-2000、2000+(人/百万方水资源)。1992年他们正式提出了用 人均水资源量作为水资源压力指数( Water Stress Index )以度量区域水资源稀缺程度 。他们根据干旱区中等发达国家的人均需水量确定了水资源压力的临界值:当人均水资源量低于 1700方/ 人年 时出现水资源压力( Water Resources Stress ) , 当人均水资源量低于 1000方/人年 时出现慢性水资源短缺( ChronicWater Scarcity )。 这一指标简明易用,只要是进行过水资源评价和有人口统计资料的地区,都可以获得人均水资源量数据。而且按用水主体人口来平均水资源符合公平合理的原则。但应用这一指标时应当注意一些限制条件,否则容易产生歧异。这一指标实际上是针对干旱区以工业为主的经济结构提出来的,对以灌溉农业为主的地区根本不使用。例如新疆尤其是南疆是水资源很紧张的地区,但一些人却根据该地区人均水资源量超过 2000 m 3 / 人而得出新疆不缺水的结论 。 人均水资源量作为衡量水资源稀缺程度的指标,还有以下几个弱点: 第一 ,没有考虑生态用水的差异。在可持续发展的原则下,尤其要强调:在人均可更新淡水资源中,还包括一部分为维持生态平衡所需要的生态用水,这部分水量人类不能耗用。由于不同的地区生态用水占水资源总量的比例很不相同,人均水资源量并不反映人均实际可用的水资源。对于干旱内陆区,人类生活和生产用水必然挤占原来的湖泊、湿地等生态用水,应该受到严格控制,即在总水资源量中,必须保留相当一部分作为天然生态用水,否则就会出现河湖干涸、植被衰退、沙漠扩张等恶果。所以为了更合理,人均水资源量的计算应该扣除生态用水,而只计算人类生活、生产可耗用的那部分水资源量。 第二 ,只考虑水资源的供给方面,而没有考虑水资源的需求方面。实际上水资源的稀缺程度必须从供给和需求两个方面综合来考虑,具体来说应考虑产业结构对需水的影响。如果经济结构以灌溉农业为主,则人均所需的水资源量必然较大;如果以耗水少的服务业为主,则人均所需的水资源量较少。所以由于产业结构的差异,人均水资源量供给相同的地区,可能缺水程度很不相同。 第三 ,只考虑水资源数量而没有考虑水资源的质量。人均水资源量较高的地区也可能因为水质问题例如水被污染而缺水,例如前几年安徽省蚌埠市水厂因为水源淮河被污染而停产,全城失去供水来源。 第四 ,只考虑数量的多少而没有考虑水资源开发利用的难易程度。实际上一些人均水资源量很高但开发很难的地区也存在缺水现象,例如我国西南的高山地区和喀斯特地区。 第五 ,只考虑总量而没有考虑水资源的时空分布。虽然多年平均人均水资源量很高但年内年际分配不均的地区,在枯水季节、枯水年份也存在缺水现象。水资源的空间分配也是一个问题。如果以中国为评价单元,则按人均水资源量指标中国是不缺水的(中国人均水资源量 2300 m 3 ,大于缺水临界值 1700方/人年 ),但如果以中国北方地区或华北为评价单元(华北海河流域人均水资源量低于 400 m 3 ),则中国是缺水的。所以评价区域的大小对评价结果有很大影响。最好是按水资源可以调配的流域作为空间单元来评价。 2 水资源开发利用程度 水资源开发利用程度 定义为年取用的淡水资源量占可获得的(可更新)淡水资源总量的百分率 ( water use intensity,withdrawal to availability ratio ) 。Raskin 等人1997年提出用这一指标作为水稀缺指数或水脆弱指数。世界粮农组织 、联合国教科文卫组织 、联合国可持续发展委员会 等很多机构都 选用这一指标作为反映水资源稀缺程度的指标:当水资源开发利用程度小于 10% 时为 低水资源压力 ( low water stress );当水资源开发利用程度大于 10% 、小于 20% 时为 中低水资源压力 ( moderate water stress );当水资源开发利用程度大于 20% 、小于 40% 时为 中高水资源压力 ( medium-high water stress );当水资源开发利用程度大于 40% 时为 高水资源压力 ( high water stress )。 这一 指标的阈值或标准,系根据水资源开发利用率与水生态环境问题的对应关系的经验确定。 Falkenmark and Lmdh (1976), Szesztay (1970), Kulshrestha (1993) and Strzepeket al. (1996)等人曾经研究总结出水资源开发利用率20%是一个重要的临界值。其他临界值是 Raskin 等人根据有关文献确定的。 水资源开发利用程度作为衡量水资源稀缺程度的指标,比人均水资源量指标优越的地方是隐含考虑了生态用水,认为人类对水资源开发利用程度越高,水系统及相关自然生态受到的压力就越大。但它也有限制或弱点: 第一 ,水资源开发利用程度与水资源紧缺程度并不完全对应。水资源开发利用程度低并不一定意味着水资源不紧缺或水资源利用效率高。在经济发展水平落后或水资源开发利用条件差的地区,尽管水资源很紧缺但水资源开发利用程度也可能很低。 第二 ,对大的区域进行评价时,这一指标不能反映水资源开发利用强度的时空差异。 第三 ,所需资料要求较高而不易获取。计算水资源开发利用程度除了需要水资源量和人口统计数据之外,还需要水资源开发利用评价资料。 事务总是复杂的,但听众总希望听所谓简单清晰的表述,总避免不了在一些场合要用简单的指标表述复杂的事务。因此,归纳的指标或标准虽然简单了点,但也是有用的,关注是要应用在适用的地方。不该用的地方用了就是用的人的问题了。 http://www.unesco.org/water/wwap/wwdr/index.shtml#indicators Falkenmark, M., J. Lundquist and C. Widstrand (1989), “Macro-scale Water Scarcity Requires Micro-scale Approaches: Aspects of Vulnerability in Semi-arid Development”, Natural Resources Forum, Vol. 13, No. 4, pp. 258–267 Malin Falkenmark and Carl Widstrand,Population and Water Resources: A Delicate Balance, in Population Bulletin (PopulationReference Bureau, Washington, D.C., 1992), p. 19. Raskin, P, P Gleick, P Kirshen, G Pontius, and K Strzepek. Waer Futures: Assessment of Long-rangePatterns and Prospects. Stockholm, Sweden: Stockholm Environment Institute, 1997. Robert Engelman, Pamela LeRoy. Sustaining Water: Population and the Futureof Renewable Water Supplies. Population Action International, Washington,D.C., 1993: pp. 18-22.
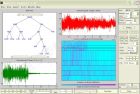
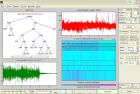
原载 http://blog.sina.com.cn/s/blog_729a92140102uwlk.html 进入小波工具箱后,“SURE”,是令人不舒服的东西之一。某种阈值处理,而已,若属居士写的东西,不被喜欢就拉倒。但它与“名校名家”、“无偏”、“自适应”、“最佳”相关联,却易使人面临混乱。 《 小波工具箱中 sure不比shannon更危险吗 》 (2013-09-16)称: 可以肯定,现在 Matlab的主要问题不在于“Shannon”本身。后来《改善Matlab的小波包处理的一个简单例子》(2013-12-14)已表明:Shannon熵本身,是可以使用的,人们常用它是不奇怪的,虽然Wavelab的作者Dr.Donoho等质疑了其合理性、认为它最差,也许它确实有不足。 那两个熵准则的Matlab的定义式中,都有对“未取模值”的数据的直接取平方的运算,表明未准备复信号的处理。当然,把复信号的实部和虚部分开处理,是一种方法,但是,小波理论,实际上一般使用复数域、复信号空间。早在Matlab小波工具箱诞生之前,小波包基系数的Shannon熵的计算表达式,就常有数据取模和能量归一化运算。然而,工具箱的文档资料中,一直没有采用这些。 小波包变换用的那个SURE阈值的计算形式,不如普通离散小波变换降噪中的rigrsure似的繁琐,而类似sqtwolog的计算。虽然,普通的小波变换,只是小波包变换树中的一个局部,但是两个阈值计算相似而不相同。这里,反映了Dr.Donoho的小波包降噪的一个基本特点,它与Tpwp循着不同的思路(不论是非)。 按Matlab-R2011a的帮助文档所述,把它用于一个可与“Shannon”并列的最佳小波包基的选择准则,这很抬举了,所以也使其不得不面临信号定标和作为代价函数的那种一般问题的拷问。 现在宽容退步。依据用户手册,可认为它是只为降噪而设计的。即使如此,有同样问题:实际噪声标准差,和要求输入的阈值参数,都乘以同一个适当的常数后,类似《用Matlab的小波包变换试验能量阈值降噪方法》(2014-06-26)中那样,结果会怎样? 可能试一试,但是注意到,最早和最新的手册都称:在白噪声的方差为“1”时,其工具箱的小波包降噪的性能良好(For now, suffice it to say that this method works well if your signal is normalized in such a way that the data fit the model x ( t ) = f ( t ) + e ( t ), where e ( t ) is a Gaussian white noise with zero mean and unit variance.)。 所以,直接再厚道些,就使试验中的实际噪声标准差只为1!要求用户对被处理数据用噪声定标,也不一定过分。当然,这已略使人不自在,因为,既如此,如果有了被处理信号时,阈值实际也就定了,那么,真正的SURE准则,实际无需其它“输入参数”。 干脆,由工具箱的函数ddencmp,自动确定降噪参数。 依据手册和帮助文档的长期的内容重复,可以假定:SURE、不寻常的代价准则、Donoho、自动设置参数的函数ddencmp、小波包降噪和压缩的函数wpdencmp、试验信号生成函数wnoise、常见数据长度、滤波器选择,在小波工具箱中应该已经磨合为一体了,可以构成小波包降噪的“金标准”。 从可选基的数目、对DFT的频率分辨率的逼近方面看,在累积误差、存储空间、时间开销都允许时,分解越深的小波包处理,对不同信号的自适应性就越强。但是,在与Dr.Donoho有关的小波变换和小波包变换降噪方法中,常见:选择(人为)适当的分解深度参数。 为保险起见,把好人做到底:做“金标准”时,用循环语句试验不同深度分解的处理结果,可看其中最好的。 设置一个“无所谓最不最佳的伪SURE”,当作灯泡:依据《 小波工具箱举例不当与 Donoho阈值》(2013-09-26),用“3倍标准差”作为硬阈值,强行替换自动的SURE的默认参数。 试验程序,如图片1.所示。其主体有4层嵌套for循环,从外到内,依次对应:由wnoise给出的6种基本测试信号,无噪信号的6种强度,10次(变量Te0)随机试验,不同的分解深度。 误差数据阵列Ea的三维寻址指标,依次为:无噪信号的编号,信噪比条件的编号,分解深度和准则参数的编号。 显示时,以整数1或0开始的行中,这第一个数字,“1”表示直接用ddencmp给的参数;“0”表示以“3倍标准差”做“硬阈值”的“伪SURE”。同一行中,第二个整数,表示分解深度;第三、四、五、六个数,分别表示,紧随其后的6个行显示的误差(范数比)矩阵中的元素的均值、标准差、最小值、最大值。 保存这一行数据。在程序结束时,以“IsDefault_Depth_Mean_Std_Min_Max”为名,再集中显示它们,如图片2所示。 此前的一行,显示一下默认参数,确认“SURE”。 从均值 、标准差、最大值看来,默认处理的结果,明显最差;“伪 SURE”的结果,最好;《用Matlab的小波包变换试验能量阈值降噪方法》的结果,处于二者之间。从可以实现的很低信噪比时的最小的误差值看,那个rigrsure最差,这里的默认处理中,存在比其它方法都更好的少数例子。 新浪赛特居士SciteJushi-2014-06-30。 图片 1. 设置Matlab小波包降噪的“金标准”的程序段 图片 2. 图片1.中的程序运行的结果(末尾部分)
CiteSpace 在单个时间分区按阈值控制网络节点数量,满足阈值条件的引文才被可视化,有 Top N 、 TopN% 、 ThresholdInterpolation 、 SelectCiters 共 4 种设定方式。 Top N 选取被引次数最高的 N 个引文, TopN% 先按被引次数排序再按百分比( N% )选取引文,这两种方式各时间分区的阈值完全相同。阈值插值( Threshold Interpolation )从被引频次 c ( citation )、两篇文献的共被引频次 cc ( cocitation )和共被引系数 ccv ( cosinecoefficient )三个层次设置阈值,其中 ccv 计算公式为 ,其中 cc(i,j) 是文献 i 和文献 j 的共被引次数, c(i) 和 c(j) 是各自的被引次数,例如在某个时间分区里,文献 i 和文献 j 共被引 2 次,文献 i 被引 4 次,文献 j 被引 3 次,则 ccv=2/sqrt(4 × 3) ≈ 0.577 。它在整个时间跨度的第一个、中间一个、最后一个时间分区分别设定阈值锚点,其余时间分区的阈值利用线性插值算法来计算,实现了不同时间分区阈值的个性化。选择施引文献( Select Citers )先根据引文记录中的 TC 字段值筛选施引文献,然后需再用 Top N 、 TopN% 、 ThresholdInterpolation 中其中一种方法作为阈值筛选施引文献中的参考文献。阈值调谐可依据 Citespace 软件界面左下角( Space Status 和 Process Reports )数据处理报告的选中的引文数量、节点数和连接数量进行调整,确定合理的阈值需要进行反复的试算和比较。软件界面左侧 Space Status 文本框中 space 栏对应数值为该时间分区内引文的有效参考文献数目,题录字段缺失及重复的参考文献不计入, nodes 指满足阈值条件的参考文献数目。 Process Reports 中 Records within the chosen range 的值指有效的引文数量,缺少参考文献的引文不记数。
玩科学,还是被科学玩,这是一个问题! 玩科学,还是被科学玩,这是一个问题!( To play science, or to be played by science, this is a question! ) 根据文双春老师的 博文 ,大概年轻人是被科学玩,而在达到一定阈值后,你就可以玩科学了!不过我想说明一点的是,其实很多院士、千人照样只有被科学玩的份,而不是玩科学! 其实不光做科学是如此,任何两者之间互动的关系莫不如此,不是你强,就是它弱!当势均力敌时,我们看到的是张力美;但一方变得游刃有余时,和谐美就出现了! 相对于“ 玩科学是一种境界 ”,我更喜欢“ 做科学是一种生活方式 ”,其实社会上三百六十行,每行都有自己的生活方式,做科学的也不能例外!人的分化其实跟细胞的分化很像,最早大家都是干细胞,具有无限的可能性,但是迟早是要分化定型的,有的人变成了政治家、有的人变成了科学家,其实他们早年不过就是要奶喝的小 baby 而已。当然有的可塑性很强,有点像诱导多功能性干细胞 (induced pluripotent stem cells, iPS ),学而优则仕嘛,或者仕而优则学嘛!
 标签: 阈值
标签: 阈值