董: 让我们记住 Benjio 的这段话:“【 Yoshua 】深度学习指向与乔姆斯基完全相反。深度学习几乎完全依赖通过数据进行的学习。当然,我们设计了神经网络的构架,但在大部分时候,它都依赖于数据、大量的数据。至于乔姆斯基,则是聚焦于固有语法和对逻辑的使用,而深度学习则关注意义。我们发现,语法只是像蛋糕上的糖霜一样的表层的东西。相反,真正重要的东西是我们的意图:我们对词的选择决定了我们要表达什么意义,而与词相联系的意义是可以被学习的。这些思想都与乔姆斯基学派的观点针锋相对。“ 看看 5 年以后还有什么话? 我查了查,上面Benjio的那段话的出处: Machines that dream Understanding intelligence: An interview with Yoshua Bengio. By David BeyerApril 19, 2016 引文原文如下:YB: It suggests the complete opposite. Deep learning relies almost completely on learning through data. We, of course, design the neural net’s architecture, but for the most part, it relies on data and a lot of it. And whereas Chomsky focused on an innate grammar and the use of logic, deep learning looks to meaning. Grammar, it turns out, is the icing on the cake. Instead, what really matters is our intention: it’s mostly the choice of words that determines what we mean, and the associated meaning can be learned. These ideas run counter to the Chomskyan school. 把原文的最后一句送进流行机译系统,看看什么结果:These ideas run counter to the Chomskyan school. Google的:这些想法背道而驰乔姆斯基学校。 Baidu的:这些想法背道而驰的乔姆斯基学派。 看起来,就是缺了那些“糖霜”! 白 : 他们对数据和学习的偏爱,掩盖了一个重要的因素:想要学到的东西长什么样。这个“长什么样”决定了学习的上限,再多数据也突不破这个上限。 多层,循环,记忆,都是“长什么样”的创新。 从某种意义上,都是在向 Chomsky 靠拢 董 : 还记得 SMT 刚兴起时,有两条宣称: 1. 不需要语言学家的知识; 2. 依靠标注的数据,主要是对齐的数据。随着数据的增加,翻译的能力将提高。那时是有监督的数据,这把该是无监督的数据了。这就连语言的句法也知识 糖霜”了。这回大概是真正的智能了。难怪李彦宏宣称人工翻译很快将被机器取代了。太狂了,就不是科学了。 白 : 他们把数据的作用夸大了,把模型长什么样的作用低估了。 马 : 公司的喜欢说大话炒作,媒体人又喜欢跟着他们吵 我 : 那段话不仅仅是大话, 而是让人怀疑他知道不知道自己在说啥。 智人说梦罢, 不值得认真对待, 我不管他 or 她是谁。 另一方面,在一个非常狭窄的领域,一个非常粗线条的“语义落地”的应用,也许“ 毛毛虫”长成啥样 的制约可以让位。 这时候,大量的数据,从数据中学习一个黑箱子出来,是可能达到可用甚至超过人工水平的“落地”应用的。 只有细线条的语义落地,对语言的机制和结构有较强的依赖,这时候白老师说的再多的数据也突不破这个上限才真正是盲目迷信学习者的紧箍咒。 就举这个我最近五年一直在做的 sentiment analysis 为例。 如果领域是 movie reviews ,语义落地的目标定为褒贬分类, 可以利用 movie review 中读者打星作为客观度量, 学出一个系统来与人工标注的打星看其吻合度。 褒分类定义为四星五星,贬分类定义为一星或二星。实践证明这是一个适合机器学习的任务,如果打了星的训练数据足够多的话,其结果不亚于人工。可以做双盲试验。可是要是语义落地都是如此粗线条的“语义”目标的话,我们语言学家就不要吃饭了。 一旦语义落地的实际需要是细线条的,语言长成啥样的乔姆斯基或 quasi-Chomsky 的毛毛虫的机制开始发力:顺之者昌,逆之者 stuck。 对于 sentiment 细线条,社会媒体舆情挖掘类应用大体是 这样的语义落地需求 : ( 1 ) 分类不够,还必须把类与 topic 相关联。 movie review 讨巧的地方是, topic 是外定的,在标题或 meta data 里;而社会媒体的大多数 topic 是在文本里的; ( 2 ) 不能是 movie review 这样的狭窄领域,而是领域独立 ; ( 3 )不能是 movie review 这样的成段落的文本,而是以绝大多数短消息为主的社会媒体; ( 4 ) 不能是简单的褒贬情绪分类,必须找到情绪背后的种种理由。 多方面的来源(种种独立的benchmarking,加上我们自己的实验探索)表明,面对这样一个任务,即便单就(1)(2)(3)而言,目前的机器学习 sentiment 死定了,突破不了大约 60% 的“与 topic 关联的褒贬”精准度瓶颈(且不说(4)细线条的情绪背后的原因等的抽取挖掘)。而语言学的路子可以轻易达到 80%+ ,这就是语义落地时的差别度量,至少 20% 精准度差距。 现在的问题变成,在实际应用中,到底多大比例的语义落地需求是粗线条就可以满足,多大比例的应用必须对“语义”有比较深入的分析? 当年 Autonomy 那家公司做得蛮成功,其中主打的 text analytics 应该就是依赖粗线条的语义,分类聚类(classfication or clustering)之类,被倒霉的 HP 并购后,现在也不大听说了。否则还可以关注一下他们在粗线条落地的语用上到底能走多远,感觉上他们已经几乎做到极限了,充分采集了“ 低枝果实 ”。 MT 当然不属于粗线条的语义落地,好在有几乎无限的人工翻译积累作为带标大数据(labeled big data),所以一路高歌猛进到今天的百度 MT 、谷歌 MT 之类的普及程度。但是现在已经很清楚, it is stuck, 如果不在语言结构上下功夫的话。我是相信白老师和董老师的铁口的,本质上看,再多的数据也救不了它 除非做某种改弦易辙。 戴 : 如果结构化的方法也无法抽象出语义是如何结构化的话,最好的语法结构分析也是徒劳的。纯粹的机器学习方式至少可以绕过去这一步直接面向目标来处理。对于意图来说,并不是一定要理解意图是怎么构成的或者如何构成,直接针对意图使用的目的,比如返回合适的结果也是可以的 我 : “如果结构化的方法也无法抽象出语义是如何结构化的话”?? 太绕。说的是什么状况? 说到底不就是:通过结构还是绕过结构达到目标么? 戴 : 简单地说就是你语法结构如何走向语义这一步,现在不都卡在这里吗。而且也没有充分的理由说明必须由语法结构走向语义,这只是语言学上的思维而已 我 : 不能抽象谈语义:至少要分粗线条或细线条。现在的 argument 就是,绕过结构到达细线条的语义,基本走不通。 这个语义就是落地的语义,语用阶段的语义。 戴 : 问题是细线条的语义是什么?如果都不知道是什么,怎么说不能达到呢 我:我不是举例说明了粗细的区别了吗,还可以举更多的例。 戴 : 以什么样的形式呈现?需要结构化吗 我 : 估计是背景相差大,好像我们不在一个频道,因此对话很困难。 白 : 老乔所说的 logic form 也不是狭义的逻辑,只是填坑的结构而已。连填坑的结构都不要,还好意思说是扔下逻辑直奔语义。 董 : 如果有人写一篇论文,批评“语法 = 糖霜论“的,我不知道如果投稿给 ACL 或 COLING ,会通得过审阅吗?记得在我国的计算语言学研究中,也曾有过为多数人不太赞同的”学派“,但几乎没有一届国内的学术大会会完全枪毙那些论文的。学术研究要允许真正的百花齐放,不可以” squeeze out “( Church 语)。这就是为什么我不赞成现在 NLP 界的风气。 白 : 江湖归江湖,落地归落地 【相关】 《立委随笔:语言自动分析的两个路子》 泥沙龙笔记:parsing 是引擎的核武器,再论NLP与搜索 泥沙龙笔记:从 sparse data 再论parsing乃是NLP应用的核武器 【白硕 - 穿越乔家大院寻找“毛毛虫”】 【科研笔记:NLP “毛毛虫” 笔记,从一维到二维】 一切声称用机器学习做社会媒体舆情挖掘的系统,都值得怀疑 【立委科普:基于关键词的舆情分类系统面临挑战】 一袋子词的主流方法面对社交媒体捉襟见肘,结构分析是必由之路 【立委科普:自动民调】 【立委科普:舆情挖掘的背后】 Coarse-grained vs. fine-grained sentiment extraction 【立委科普:自然语言parsers是揭示语言奥秘的LIGO式探测仪】 【新智元笔记:李白对话录 - RNN 与语言学算法】 【立委科普:语言学算法是 deep NLP 绕不过去的坎儿】 【泥沙龙笔记:NLP hard 的歧义突破】 【立委科普:结构歧义的休眠唤醒演义】 【NLP主流的反思:Church - 钟摆摆得太远(1):历史回顾】 【Church - 钟摆摆得太远(5):现状与结论】 没有语言学的 CL 走不远 【置顶:立委科学网博客NLP博文一览(定期更新版)】 《朝华午拾》总目录
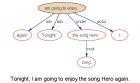
我们知道,语句呈现的是线性的字符串,而语句 结构却是二维的。我们之所以能够理解语句的意思,是因为我们的大脑语言处理中枢能够把线性语句解构(decode)成二维的结构:语法学家常常用类似下列的上下颠倒的树形图来表达解构的结果(所谓 parsing)。 上面这个树形图叫作依从关系树形图(dependency tree,常常用来表达词或词组之间的逻辑语义关系,与此对应的还有一种句法树,叫短语结构树 phrase structure tree,更适合表达语句单位之间的边界与层次关系)。直观地说,所谓理解了一句话,其实就是明白了两种意义:(1)节点的意义(词汇意义);(2)节点之间的关系意义(逻辑语义)。譬如上面这个例子,在我们的自动语句分析中有大小六个节点:【Tonight】 【I】 【am going to enjoy】 【the 【song】 Hero】 【again】,分解为爷爷到孙儿三个层次,其中的逻辑语义是:有一个将来时态的行为【am going to enjoy】,结构上是老爷爷,他有两个亲生儿子,两个远房侄子。长子是其逻辑主语(Actor) 【I】,此子是其逻辑宾语(Undergoer)【the song Hero】,父子三人是语句的主干(主谓宾,叫做 argument structure),构成语句意义的核心。 两个远房侄子,一个是表达时间的状语(adverbial)【Tonight】,另一个表达频次的状语(adverbial)【again】。最后,还有一个孙子辈的节点【song】,他是次子的修饰语(modifier,是同位语修饰语),说明【Hero】的类别。 从句法关系角度来看,依从关系遵从一个原则:老子可以有n(n=0)个儿子(图上用下箭头表示),而儿子只能有一个老子:如果有一个以上的老子,证明有结构歧义,说明语义没有最终确定,语言解构(decoding)没有最终完成。虽然一个老子可以有任意多的下辈传人,其亲生儿子是有数量限制的,一般最多不超过三个,大儿子是主语,次子是宾语,小儿子是补足语。比如在句子 “I gave a book to her” 中,动词 gave 就有三个亲儿子:主语 【I】, 宾语【a book】,补足语 【to her】. 很多动词爷爷只有两个儿子(主语和宾语,譬如 John loves Mary),有的只有一个儿子(主语,譬如 John left)。至于远房侄子,从结构上是可有可无的,在数量上也是没有限量的。他们的存在随机性很强,表达的是伴随一个行为的边缘意义,譬如时间、地点、原因、结果、条件等等。 自然语言理解(Natural Language Understanding)的关键就是要模拟人的理解机制,研制一套解构系统(parser),输入的是语句,输出的是语法结构树。在这样的结构树的基础上,很多语言应用的奇迹可以出现,譬如机器翻译,信息抽取,自动文摘,智能搜索,等等。 在结束本文前,再提供一些比较复杂一些的语句实例。我把今天上网看到的一段英文输入给我们研制的parser,其输出的语法结构树如下(未经任何人工编辑,分析难免有小错)。 说明:细心的读者会发现下列结构树中,有的儿子有两个老子,有的短语之间互为父子,这些都违反了依存关系的原则。其实不然。依存关系的原则针对的是句法关系,而句法后面的逻辑关系有时候与句法关系一致,有时候不一致。不一致的时候就会出现两个老子,一个是与句法关系一致的老子,一个是没有相应的显性句法关系的老子。最典型的情形是所谓的隐性(逻辑)主语或宾语。 譬如第一个图示中的右边那棵结构树中,代词「I」就有两个老子:其句法老子是谓语动词「have learned」,它还有一个非谓语动词(ING形式)的隐性的逻辑老子「(From) reading」,也做它的逻辑主语 (who was reading? I)。再如第二个图示中的语法结构树中,定语从句的代表动词「were demonstrating」的句法老子是其所修饰的名词短语「students」,但逻辑上该名词短语却是定语从句动词「were demonstrating」的主语(actor)。有些纯粹的句法分析器(parser)只输出句法关系树,而我们研制的parser更进一步,深入到真正的逻辑语义层次。这样的深层分析为自然语言理解提供了更为坚实的基础,因为显性和隐性的关系全部解构,语义更为完整。 我们每天面对的就是这些树木构成的语言丛林。在我的眼中,它们形态各异,婀娜多姿,变化多端而不离其宗(“语法”)。如果爱因斯坦在时空万物中看到了造物主的美,如果门捷列夫在千姿百态的物质后面看到了元素表的简洁,语言学家则是在千变万化的语言现象中看到了逻辑结构之美。这种美的体验伴随着我们的汗水,鼓励我们为铲平语言壁垒而愚公移山,造福人类。 后记:When I showed the above trees to my daughter today, she was amazed, pretty! She asked, is this what you made the machine to do in diagramming sentences? Yes. Wow, incredible. I don't think I can diagram the sentences as nice as these. Can some day the machine be smarter than you the creator? Is the machine learning by itself? I said, it is not self-learning at this point and the self-learning system is too research oriented to put into a real life system now. But I do observe from time to time that the machine we made for parsing sometimes generate results of very complicated sentences way beyond our expectation, better than most human learners at times. This is because I encode the linguistics knowledge piece by piece, and machine is super good at memory. Once taught, it remembers every piece of knowledge we programmed into the system. Over the years of the development cycle, the accumulation of the knowledge is incredibly powerful. We humans are easy to forget things and knowledge, but machine has no such problems. In this sense, it is not impossible that a machine can beat his creator in practical performance of a given task. 回答: I don't think tree is the way my mind thinks 1窃以为,句法树迄今仍是大脑黑箱作业的最好的模拟和理论 2 does not really matter 作者: 立委 (*) 日期: 06/03/2011 04:30:20 As long as subtree matching is a handy and generalized way of info extraction. Tree is not the goal but a means to an end. The practical end is to extract knowledge or facts or sentiments from language. In practice, our goal is not to simulate the human comprehension per se , the practical goal is: Quote 在这样的结构树的基础上,很多语言应用的奇迹可以出现,譬如机器翻译,信息抽取,自动文摘,智能搜索,等等。 【相关博文】 《泥沙龙笔记:漫谈自动句法分析和树形图表达》 【 科普小品:文法里的父子原则 】 【立委科普:语法结构树之美(之二)】 《新智元:有了deep parsing,信息抽取就是个玩儿》 泥沙龙笔记:parsing 是引擎的核武器,再论NLP与搜索 乔氏 X 杠杠理论 以及各式树形图表达法 【 立委随笔:创造着是美丽的 】 【 科研笔记:开天辟地的感觉真好 】 【立委科普:美梦成真的通俗版解说】 【征文参赛:美梦成真】 【立委科普:自然语言parsers是揭示语言奥秘的LIGO式探测仪】 【置顶:立委科学网博客NLP博文一览(定期更新版)】
 标签: 句法
标签: 句法