白: “是他杀的张三”是一个完整句子吗? 主谓宾都在哪儿? 我: shi S Vt de O ==》SVO 很常见的句式,主谓宾齐全, 是 S V 的 O == S V 的 O == SVO 不过其中 “SV的O” 有歧义,因为与带定语从句的NP同形。 不过加了强调小词 “是” 在句首以后,似乎歧义就消失了。 白: “是”当什么?自己没有主谓宾? 我: 是数学我不喜欢。 是在北京他们开的董事会。 是1990年我毕业的。 句首的“是”,是强调小词。 类似于英语的强调表达法: it is X 。。。。 it was in 1990 when I graduated It was in Beijing where we got the deal 白: 可否认为“张三是他杀的”,然后“张三”后移到句尾。 我: 张三是他杀的 ==》 是他杀的张三 ? 张三他杀的 ==》 他杀的张三 白: “是他杀了张三”可以这么做。“是他杀的张三”不能。 “是他杀了张三”跟“有人敲门”是一个性质,在坑论里是两个谓词合并,共享一个萝卜。 但“是他杀的张三”不好套用这个结构。没办法把二元关系进行到底。不仅“的”捞不出来,连“是”还得搭进去。 我: “的” 字的两个用法:1 定语标志(或所有格);2. 肯定语气 表示肯定语气的 ”的“,通常位于句末,也常与表示肯定或强调的 ”是“ 搭配使用: 是 XP 的 貌似由此衍生出表示肯定的 ”的“ 用于谓宾之间。 “是他杀的张三” 说的是对过去或完成的肯定,但是却不允许用助词 ”了“ 或 ”过“,原因可能是这个位置被 “的” 占据了。另一个原因是 这种肯定语气蕴含了完成。肯定的行为动作不可能是没有发生的事件。 在 pattern 中,只要能列举出这种即可,很容易捕捉,除非是歧义。 白: 表达什么先不管,谁跟谁有关系是首先要解决的。 我: 没有句首“是”的pattern “SV的O” 的确有歧义,但是这种歧义是 consistent 的。对于consistent 的歧义,其实不难处理,可以将错就错。直到错到某个点,系统觉得应该校正了,就校正。现在的处置是,开始 parsing 的时候,一律做定语从句看。 白: 有套路,就把构成套路的词摘到二元关系之外,语言学上不够简约。 前面说到的踢出机制试了几个例子,很好玩,基本通了。 我: 有套路,就把构成套路的词摘到二元关系之外,没有问题啊。因为小词已经在套路(patterns)起到了该起的条件作用,譬如 “是+S+V+的+O”,在这个 pattern 中,没有歧义, SVO 被确定,逻辑语义被解构,一抓一个准,完事了,把 “是” 和 “的” 这种句法辅助小词挂起来。这是pattern的天经地义。pattern 比起二元关系环环相扣的 parsing 有不同的优缺点:pattern 可能比较长,上述 pattern 是个五元组,实词的元是XP,所以实际的跨越可能是很长的 string,用的是长度来换取确定性,牺牲了某种抽象性,或换句话说,带来了一些规则的冗余度。二元关系环环相扣的做法,可能更加简约和概括。 白: 做系统咋都行。做句法。感觉非常实用主义,理论上不连贯。 我: 句法标配说的是 sv 语序,多数系统都用的。你的系统先不用,是例外。 白: 我这不用。至少matcher不用。以后语义模块用另说。 我: 虽然汉语语序很操蛋,孤立语中它自由得简直不讲道理,但是 sv 是默认,有统计性依据,也有心理认知的依据。这一汉语句法标配的形式痕迹,不用白不用。 白: 用了也有误导的时候。 我在尝试踢出边的功能:一个强搭配萝卜进来,在坑饱和的情况下,踢走一个已经进坑的萝卜,自己跳坑。如果没有不占指标的额度的话。一进一出,不破坏结构,不重构结构,也不改变结构对外部的联系。与所谓“回溯”大不一样。拔出来的萝卜再进什么坑,全看后续发展。 我: 所以句法结构的时候 可以不利用语序,因为这个结构的标签暂时不不用给出。其实这是跳过句法标签,直接在下一步进入逻辑语义标签。但传统做法是区分 arg1 arg2 arg3,现在是不区分 只说这是arg,有别于 mod 就可以了。 白: 但是各个arg如果subcat不同的话,需要锁定,免得互相串了。 我: 所以是标签隐藏在后面,暂时不露而已。 对,免得互相串了 是必须的。 白: 如果连另一个可能性都没有指出来,焉知落地想要的不是另一个? 我: 这个问题哪里会有?是落地的需求 drive 开发呀。世界上哪里有飘在天上搞开发的呢。何况开发这事儿也不是一锤子买卖。今天没有的可能性,明天加上可能性也是可以的。系统不可能是一成不变的。pattern 不变的话,在结论上增加点什么,连重新测试都不需要就可以搞定,有何难哉?更何况 我们 patterns 用完小词以后,还发扬了革命人道主义,并没有扔掉敲门砖,还用 X 把小词给挂上呢。所有的痕迹都在,过河没拆桥。不过是不让过了河的桥和敲了门的砖占据我们的语义核心地位而已。 小词负载结构,我的理解,本质上也就是一个过渡,一个粘结剂,一个特定的 parsing 算法所依赖的一种手段,并不是一种必需。小词成为条件,则是一种通用的必需,因为没有小词,结构关系就很难搞定,这是小词存在的理由。 白: “杀人犯把卖盐的杀了化妆成卖盐的在那卖盐。”杀人犯是卖盐的? 我: 那句话一时看不懂,但 point 明白了。你是在诘问 把“S是V的”处理成 SV 的做法。它们不等同,不仅仅是 affirmative 的差别,还有另一个差别在。这个差别是,“S是V” 的 可以回答 “S是谁” 的问题,而 “SV” 不能回答 “S是谁” 的问题。好,这是一个典型的语义落地决定如何表达的例子。现在的问答系统的语义落地有对这两种结构做区分的需求,那就让第二个pattern在输出表达中,把这种需求满足即可。譬如,可以让第二个pattern (S 是 V 的)输出这样的结果: arg structure: S V feature: affirmative answer: who is S 白: 杀人犯不是卖盐的VS杀人犯不卖盐 这些零碎副词加在affirmative上还是加在普通谓语上怎么区分? 我: bottom line is pattern1 和 pattern2 是两个独立的捕捉,二者该怎样处理都可以,加在哪里都可以。加在哪里落地好用,落地觉得有用,就加在哪里。这都不是事儿。媳妇都娶回家了,怎么打扮还不是男家一句话吗? 白: 那就是说实际上做了两个谓词,简化成一个谓词是伪命题。而小词负载结构,只不过把两个谓词显性化而已。 我: 早早年的parsing,其原始定义记得是没有parse tree的表达的。什么都没有。就是一个合法非法的结论。所谓合法的结论,就是 parser 把那个句子从头到尾都吃进去了。 白: 判定问题 我: 后来的 tree representation 或其他的表达,全部是 parsing 过程留下的痕迹,或副作用。这样看parsing就明白了娶媳妇是核心,打扮媳妇是具有任意性和功利性的副产品。小词负载结构如果能在语义上表现出贡献,那么这种贡献可以等价地由 pattern 给出。换句话说,如果某种用小词作为枢纽来区别谓词的表达法,对于语义落地有益,那么没有人可以阻挡pattern的编写者,输出同样的表达。但实践中,我们知道,其实绝大多数时候,这些小词丢掉了,核心语义没啥损失。譬如 小词 “把”点名了宾语的所在,借助它表达出宾语的核心语义以后,“把”的使命也就完结了。 白: “把”和述补结构连接,绝不是只有“宾语”这一个含义。参照“他把眼睛哭肿了。” 我: 小词负载结构的语义贡献注定是有限的小词的本质就是句法的显性形式,在句法走向逻辑语义的过程中,形式走向内容。表层走向深层。言语走向逻辑。这种趋向决定了小词负载结构基本是边缘的语义。换一个角度看这个问题,小词是 language specific 的,而语义的本质是人类共通,language-independent 的。language specific 的东西不会在语义里面唱主角。 30 年前,董老师提出,以人类共同的逻辑语义作为机器翻译的基础,而不是在句子表层实施转换。这样一来,不仅用了不同小词和词序的主动语态和被动语态被认为是相同的,而且动词与deverbal的名词也被认为是相同的。因为其 arg structure 的核心逻辑语义都是相同的。用它指导 MT 就是: I translated A from B into C == A is translated from B to C (by me) == my translation of A from B to C == 我把A从B翻译成C 当时觉得董老师的做法的确抓到了要害,但也觉得表层的小词和细微差别(譬如语态)也不能就这么扔了。最后的体会和结论是: 在语义落地的时候(譬如MT),逻辑语义是主要的,表层结构是辅助的。做到了逻辑语义的转换,基本任务可以算是完成了。但是要想做得更好一点,还可以参照表层结构或features,再做一些细节上的调整。譬如 英语是被动态的,也许也翻译成被动态更合适(其实,由于两个语言的显性被动表达形式具有不同的使用频度,只能说,部分的被动态用汉语的显性被动为宜,其他的被动态可以用隐性的被动形式,最后还有一部分被动其实更合适用汉语的主动态来翻译,这个要细细研究的话,可以针对不同情形结合表层和深层结构写一大篇来)。 总而言之,小词和表层,顾不上来的话,扔掉了也没啥大不了的。这些边缘的语义色彩,对于语义落地的不同场景或许可以有参照作用,但不是核心。 白: 实际情况是,逻辑语义也是人参照表层写出来的。本族语表层研究不到位,就只好迁就着走。就好像grandma不知道是姥姥还是奶奶。并不是他们说英语的人逻辑上不能定义和区分爸爸的妈妈还是妈妈的妈妈。我们要高频率地使用,就不能绕着走。 我: 这样看也是一个角度,有其道理。 理论上,逻辑语义应该是参照多数的人类语言提出来。基本立足点就是,人类的概念和思维是共同的,理解也应该是共同的,只是表达的时候穿了不同的外衣。当然,语言对思维也有反作用,因此人类思维和理解的共同性,只可能是大同小异,而不可能是完全一致。 白: 共同性体现为外衣的并集 如果主要外衣缺失,就谈不上共同性了 【相关】 【李白对话录系列】 中文处理 Parsing 【置顶:立委NLP博文一览】 《朝华午拾》总目录
上次说过,绝大多数的parsers对于谓词的 subcat 的表达都很简陋,伸展不开,多数不过把 subcat 当成一个代码,然后在相关的 subcat 规则中去确定 pattern。但是词驱动的文法 HPSG 却可以丝丝入扣,合情合理,可以直接在词典里面把 subcat 的 pattern 细致地描述,并对其句法语义的输入(pattern的条件)和输出(逻辑语义)之间的映射和解构,做出一个符合语言学原则的表达(representation)。 简陋有简陋的工程考量和理由,叠床架屋有叠床架屋的逻辑优美。鱼与熊掌不可兼得,我们最终还是更加倾向于简陋之法。尽管如此,走简陋快捷的路线的人,如果对结构表达的优美有所体验,还是有莫大的好处,至少不会被简陋的表象所迷惑,对于复杂的语言现象,逐渐摆脱简陋的捉襟见肘。 最近回看当年博士阶段的 涂鸦文章 ,虽然其中反映出的对汉语句法的见识并不出彩,但是得力于 HPSG 的结构丰富性,还是把 subcat 在汉语文法中应用,表现得有条不紊,经得起时间的检验。当年钻研 HPSG 还是很专心的,吃得蛮透。正因为吃得透了,后来扬弃的时候就没有拖泥带水的牵挂。 譬如,在论及汉语NP带坑的现象的时候,是这样模型的: 11a) 桌子坏了。 11b) 腿坏了。 11c) 桌子的腿坏了。 12a) 他好。 12b) 身体好。 12c) 他的身体好。 When people say 11b) tui huai le (leg went wrong), we know something (the possessor) is omitted. For 11a), however, we have no such feel of incompleteness. Although we may also ask whose table, this possessive relation between who and table is by no means innate. Similarly, ta (he) in 12a) is a complete notion denoting someone while shenti (body) in 12b) is not. In 11c) and 12c), the possessor appears in the possessive structure DE-construction, the expectation of tui (leg) and shenti (body) is realized. These examples show that some words (concepts) have conceptual expectation for some other words (concepts) although the expected words do not necessarily show up in a sentence and the expectation might not be satisfied. In fact, this type of expectation forms part of our knowledge (common sense). One way to represent the knowledge is to encode it with the related word in the lexicon. Therefore we propose an underlying SYNSEM feature KNOWLEDGE to store some of our common sense knowledge by capturing the internal relation between concepts. KNOWLEDGE parallels to syntactic SUBCAT and semantic RELATION. KNOWLEDGE imposes semantic constraints on their expected arguments no matter what syntactic forms the arguments will take (they may take null form, i.e. the underlying arguments are not realized). In contrast, SUBCAT only defines syntactic requirement for the complements and gets interpreted in RELATION. Following this design, syntactic form and semantic constraints are kept apart. When necessary, the interaction between them can be implemented by lexical rules, or directly coindexed in the lexicon. For example, the following KNOWLEDGE information will be enforced as the necessary semantic constraints when we handle Chinese NP predicates by a lexical rule (see 3.3). 把常识暗度陈仓从后门带入文法,就是从那时候开始的。这个做法在欧洲语言的形式文法中不多见,因为句法形式大体够用了,通常不需要常识的帮忙。但是对于汉语,没有某种常识的引入,想做一个成熟的深度分析系统,则很难。当年带常识的的句法结构模型是这样定义的: PHON shenti SYNSEM | KNOWLEDGE | PRED possess SYNSEM | KNOWLEDGE | POSSESSOR human SYNSEM | KNOWLEDGE | POSSESSED SYNSEM | LOCAL | CONTENT | INDEX SYNSEM | LOCAL | CONTENT | RESTRICTION { RELATION body } SYNSEM | LOCAL | CONTENT | RESTRICTION { INSTANCE } 最后,汉语文法中常识的引入被认为是对欧洲语言利用性数格的 agreement 的一个自然延伸。句法手段到语义限制的延伸。 Agreement revisited This section relates semantic constraints which embody common sense to the conventional linguistic notion of agreement. We will show that they are essentially the same thing from different perspectives. We only need slight expansion for the definition of agreement to accommodate some of our basic knowledge. This is important as it accounts for the feasibility of coding knowledge in linguistic ways. Linguistic lexicon seems to be good enough to house some general knowledge in addition to linguistic knowledge. 为 parse“我鸡吃“ 和“鸡我吃”, 常识进入了文法(现在也可以利用大数据把常识代入): A typical example of how concepts are linked in a network (a sophisticated concept lexicon) is seen in the representation of drink ((*ANI SUBJ) (((FLOW STUFF) OBJE) ((SELF IN) (((*ANI (THRU PART)) TO) (BE CAUSE))))) in Wilks 1975b. While for various reasons we will not go as far as Wilks, we can gain enlightenment from this type of AI approach to knowledge. Lexicon-driven systems like the one in HPSG can, of course, make use of this possibility. Take the Chinese role-assignment problem, for example, the common sense that ANIMATE being eats FOOD can be seamlessly incorporated in the lexical entry chi (eat) as a semantic agreement requirement. PHON chi SYNSEM | KNOWLEDGE | PRED eat SYNSEM | KNOWLEDGE | AGENT animate SYNSEM | KNOWLEDGE | PATIENT food SYNSEM | LOCAL | CATEGORY | SUBCAT | EXTERNAL_ARGUMENT ] SYNSEM | LOCAL | CATEGORY | SUBCAT | INTERNAL_ARGUMENTS ] SYNSEM | LOCAL | CONTENT | RELATION SYNSEM | LOCAL | CONTENT | EATER | INDEX | ROGET SYNSEM | LOCAL | CONTENT | EATEN | INDEX | ROGET 可见,看上去不过是 POS 细分后的一个 subcat 的代码,里面其实包含了多少结构及其蕴含其内的知识。在 unification grammars 几乎成为历史陈迹的今天,我还是认为 HPSG 这样的表达是最优美的语言学的逻辑表达之一,论逻辑的清晰和美,后来的文法很难超越。 Handling Chinese NP predicate in HPSG (old paper) Notes for An HPSG-style Chinese Reversible Grammar Outline of an HPSG-style Chinese reversible grammar PhD Thesis: Morpho-syntactic Interface in CPSG (cover page) Overview of Natural Language Processing Dr. Wei Li’s English Blog on NLP
5.0. Introduction This chapter investigates the phenomena usually referred to as separable verbs (离合动词 lihe dongci ) in the form V+X. Separable verbs constitute a significant portion of Chinese verb vocabulary. These idiomatic combinations seem to show dual status (Z. Lu 1957; L. Li 1990). When V+X is not separated, it is like an ordinary verb. When V is separated from X, it seems to be more like a phrasal combination. The co-existence of both the separated use and contiguous use for these constructions is recognized as a long-standing problem at the interface of Chinese morphology and syntax (L. Wang 1955; Z. Lu 1957; Chao 1968; Lü 1989; Lin 1983; Q. Li 1983; L. Li 1990; Shi 1992; Dai 1993; Zhao and Zhang 1996). Some linguists (e.g. L. Li 1990; Zhao and Zhang 1996) have made efforts to classify different types of separable verbs and demonstrated different linguistic facts about these types. There are two major types of separable verbs: V+N idioms with the verb-object relation and V+A/V idioms with the verb-modifier relation - when X is A or non-conjunctive V. The V+N idiom is a typical case which demonstrates the mismatch between a vocabulary word and grammar word. There have been three different views on whether V+N idioms are words or phrases in Chinese grammar. Given the fact that the V and the N can be separated in usage, the most popular view (e.g. Z. Lu 1957; L. Li 1990; Shi 1992) is that they are words when V+N are contiguous and they are phrases otherwise. This analysis fails to account for the link between the separated use and the contiguous use of the idioms. In terms of the type of V+N idioms like 洗澡 xi zao (wash-bath: take a bath), this analysis also fails to explain why a different structural analysis should be given to this type of contiguous V+N idioms listed in the lexicon than the analysis to the also contiguous but non-listable combination of V and N (e.g. 洗碗 xi wan 'wash dishes'). As will be shown in Section 5.1, the structural distribution for this type of V+N idioms and the distribution for the corresponding non-listable combinations are identical. Other grammarians argue that V+N idioms are not phrases (Lin 1983; Q. Li 1983; Zhao and Zhang 1996). They insist that they are words, or a special type of words. This argument cannot explain the demonstrated variety of separated uses. There are scholars (e.g. Lü 1989; Dai 1993) who indicate that idioms like 洗澡 xi zao are phrases. Their judgment is based on their observation of the linguistic variations demonstrated by such idioms. But they have not given detailed formal analyses which account for the difference between these V+N idioms and the non-listable V+NP constructions in the semantic compositionality. That seems to be the major reason why this insightful argument has not convinced people with different views. As for V+A/V idioms, Lü (1989) offers a theory that these idioms are words and the insertable signs between V and A/V are Chinese infixes. This is an insightful hypothesis. But as in the case of the analyses proposed for V+N idioms, no formal solutions have been proposed based on the analyses in the context of phrase structure grammars. As a general goal, a good solution should not only be implementable, but also offer an analysis which captures the linguistic link, both structural and semantic, between the separated use and the contiguous use of separable verbs. It is felt that there is still a distance between the proposed analyses reported in literature and achieving this goal of formally capturing the linguistic generality. Three types of V+X idioms can be classified based on their different degrees of 'separability' between V and X, to be explored in three major sections of this chapter. Section 5.1 studies the first type of V+N idioms like 洗澡 xi zao (wash-bath: take a bath). These idioms are freely separable. It is a relatively easy case. Section 5.2 investigates the second type of the V+N idioms represented by 伤心 shang xin (hurt-heart: sad or heartbroken). These idioms are less separable. This category constitutes the largest part of the V+N phenomena. It is a more difficult borderline case. Section 5.3 studies the V+A/V idioms. These idioms are least separable: only the two modal signs 得 de3 (can) and 不 bu (cannot) can be inserted inside them, and nothing else. For all these problems, arguments for the wordhood judgment will be presented first. A corresponding morphological or syntactic analysis will be proposed, together with the formulation of the solution in CPSG95 based on the given analysis. 5.1. Verb-object Idioms: V+N I The purpose of this section is to analyze the first type of V+N idioms, represented by 洗澡 xi zao (wash‑bath: take a bath). The basic arguments to be presented are that they are verb phrases in Chinese syntax and the relationship between the V and the N is syntactic. Based on these arguments, formal solutions to the problems involved in this construction will be presented. The idioms like 洗澡 xi zao are classified as V+N I, to be distinguished from another type of idioms V+N II (see 5.2). The following is a sample list of this type of idioms. (5-1.) V+N I: xi zao type 洗澡 xi (wash) zao (bath #) take a bath 擦澡 ca (scrub) zao (bath #) clean one's body by scrubbing 吃亏 chi (eat) kui (loss #) get the worst 走路 zou (go) lu (way $) walk 吃饭 chi (eat) fan (rice $) have a meal 睡觉 shui (V:sleep) jiao (N:sleep #) sleep 做梦 zuo (make) meng (N:dream) dream (a dream) 吵架 chao (quarrel) jia (N:fight #) quarrel (or have a row) 打仗 da (beat) zhang (battle) fight a battle 上当 shang (get) dang (cheating #) be taken in 拆台 chai (pull down) tai (platform #) pull away a prop 见面 jian (see) mian (face #) meet (face to face) 磕头 ke (knock) tou (head) kowtow 带头 dai (lead) tou (head $) take the lead 帮忙 bang (help) mang (business #) give a hand 告状 gao (sue) zhuang (complaint #) lodge a complaint Note: Many nouns (marked with # or $) in this type of constructions cannot be used independently of the corresponding V. But those with the mark $ have no such restriction in their literal sense. For example, when the sign fan means 'meal', as it does in the idiom, it cannot be used in a context other than the idiom chi-fan (have a meal). Only when it stands for the literal meaning ‘rice’, it does not have to co-occur with chi . There is ample evidence for the phrasal status of the combinations like 洗澡 xi zao . The evidence is of three types. The first comes from the free insertion of some syntactic constituent X between the idioms in the form V+X+N: this involves keyword-based judgment patterns and other X‑insertion tests proposed in Chapter IV. The second type of evidence resorts to some syntactic processes for the transitive VP, namely passivization and long-distance topicalization. The V+N I idioms can be topicalized and passivized in the same way as ordinary transitive VP structures do. The last piece of evidence comes from the reduplication process associated with this type of idiom. All the evidence leads to the conclusion that V+N I idioms are syntactic in nature. The first evidence comes from using the wordhood judgment pattern: V(X)+zhe/guo à word(X). It is a well observed syntactic fact that Chinese aspectual markers appear right after a lexical verb (and before the direct object). If 洗澡 xi zao were a lexical verb, the aspectual markers would appear after the combinations, not inside them. But that is not the case, shown by the ungrammaticality of the example in (5-2b). A productive transitive VP example is given in (5-3) to show its syntactic similarity (parallelness) with V+N I idioms. (5-2.) (a) 他正在洗着澡 ta zheng-zai xi zhe zao . he right-now wash ZHE bath He is taking a bath right now. (b) * 他正在洗澡着。 ta zheng-zai xi - zao zhe. he right-now wash-bath ZHE (5-3.) (a) 他正在洗着衣服。 ta zheng-zai xi zhe yi-fu . he right-now wash ZHE clothes He is washing the clothes right now. (b) * 他正在洗衣服着。 ta zheng-zai xi yi-fu zhe. he right-now wash clothes ZHE The above examples show that the aspectual marker 着 zhe (ZHE) should be inserted in the V+N idiom, just as it does in an ordinary transitive VP structure. Further evidence for X-insertion is given below. This comes from the post-verbal modifier of ‘action-times’ (动量补语 dongliang buyu ) like 'once', 'twice', etc. In Chinese, action-times modifiers appear after the lexical verb and aspectual marker (but before the object), as shown in (5-4a) and (5-5a). (5-4.) (a) 他洗了两次澡。 ta xi le liang ci zao . he wash LE two time bath He has taken a bath twice. (b) * 他洗澡了两次。 ta xi - zao le liang ci. he wash-bath LE two time (5-5.) (a) 他洗了两次衣服。 ta xi le liang ci yi-fu . he wash LE two time clothes He has washed the clothes twice. (b) * 他洗衣服了两次。 ta xi yi-fu le liang ci. he wash clothes LE two time So far, evidence has been provided of syntactic constituents which are attached to the verb in the V+N I idioms. To further argue for the VP status of the whole idiom, it will be demonstrated that the N in the V+N I idioms in fact fills the syntactic NP position in the same way as all other objects do in Chinese transitive VP structures. In fact, N in the V+N I does not have to be a bare N: it can be legitimately expanded to a full-fledged NP (although it does not normally do so). A full-fledged NP in Chinese typically consists of a classifier phrase (and modifiers like de- construction) before the noun. Compare the following pair of examples. Just like an ordinary NP 一件崭新的衣服 yi jian zan-xin de yi-fu (one piece of brand-new clothes), 一个痛快的澡 yi ge tong-kuai de zao (a comfortable bath) is a full-fledged NP. (5-6.) 他洗了一个痛快的澡。 ta xi le yi ge tong-kuai de zao . he wash LE one CLA comfortable DE bath He has taken a comfortable bath. (5-7.) 他洗了一件崭新的衣服。 ta xi le yi jian zan-xin de yi-fu . he wash LE one CLA brand-new DE clothes He has washed one piece of brand-new clothes. It requires attention that the above evidence is directly against the following widespread view, i.e. signs like 澡 zao , marked with # in (5-1), are 'bound morphemes' or ‘bound stems’ (e.g. L. Li 1990; Zhao and Zhang 1996). As shown, like every other free morpheme noun (e.g. yi-fu ), zao holds a lexical position in the typical Chinese NP sequence 'determiner + classifier + ( de -construction) + N', e.g. 一个澡 yi ge zao (a bath), 一个痛快的澡 yi ge tong-kuai de zao (a comfortable bath). In fact, as long as the ‘V+N I phrase’ arguments are accepted (further evidence to come), by definition ‘bound morpheme’ is a misnomer for 澡 zao . As a part of morphology, a bound morpheme cannot play a syntactic role: it is inside a word and cannot be seen in syntax. The analysis of 洗 xi (...) 澡 zao as a phrase entails the syntactic roles played by 澡 zao : (i) 澡 zao is a free morpheme noun which fills the lexical position as the final N inside the possibly full-fledged NP; (ii) 澡 zao plays the object role in the syntactic transitive structure 洗澡 xi zao . This bound morpheme view is an argument used for demonstrating the relevant V+N idioms to be words rather than phrases (e.g. L. Li 1990). Further examination of this widely accepted view will help to strengthen the counter-arguments that all V+N I idioms are phrases. Labeling signs like 澡 zao (bath) as bound morphemes seem to come from an inappropriate interpretation of the statement that bound morphemes cannot be ‘freely’, or ‘independently’, used in syntax. This interpretation places an equal sign between the idiomatic co-occurrence constraint and ‘not being freely used’. It is true that 澡 zao is not an ordinary noun to be used in isolation. There is a co-occurrence constraint in effect: 澡 zao cannot be used without the appearance of 洗 xi (or 擦 ca ). However, the syntactic role played by 澡 zao, the object in the syntactic VP structure, has full potential of being ‘freely’ used as any other Chinese NP object: it can even be placed before the verb in long-distance constructions as shall be shown shortly. A more proper interpretation of ‘not being freely used’ in terms of defining bound morphemes should be that a genuine bound morpheme, e.g. the suffix 性 -xing ‘-ness’, has to attach to another sign contiguously to form a word. A comparison with similar phenomena in English may be helpful. English also has similar idiomatic VPs, such as kick the bucket . For the same reason, it cannot be concluded that bucket (or the bucket ) is a bound morpheme only because it demonstrates necessary co-occurrence with the verb literal kick . Signs like bucket, 澡 zao (bath) are not of the same nature as bound morphemes like –less, -ly, un-, ‑xing (-ness), etc The second type of evidence shows some pattern variations for the V+N I idioms. These variations are typical syntactic patterns for the transitive V+NP structure in Chinese. One of most frequently used patterns for transitive structures is the topical pattern of long distance dependency. This provides strong evidence for judging the V+N I idioms as syntactic rather than morphological. For, with the exception of clitics, morphological theories in general conceive of the parts of a word as being contiguous. Both the V+N I idiom and the normal V+NP structure can be topicalized, as shown in (5-8b) and (5-9b) below. (5-8.) (a) 我认为他应该洗澡。 wo ren-wei ta ying-gai xi zao . I think he should wash-bath I think that he should take a bath. (b) 澡我认为他应该洗 zao wo ren-wei ta ying-gai xi . bath I think he should wash The bath I think that he should take. (5-9.) (a) 我认为他应该洗衣服。 wo ren-wei ta ying-gai xi yi-fu . I think he should wash clothes I think that he should wash the clothes. (b) 衣服我认为他应该洗。 yi-fu wo ren-wei ta ying-gai xi . clothes I think he should wash The clothes I think that he should wash. The minimal pair of passive sentences in (5-10) and (5‑11) further demonstrates the syntactic nature of the V+N I structure. (5-10.) 澡洗得很干净。 zao xi de3 hen gan-jing. bath wash DE3 very clean A good bath was taken so that one was very clean. (5-11.) 衣服洗得很干净。 yi-fu xi de3 hen gan-jing. clothes wash DE3 very clean The clothes were washed clean. The third type of evidence involves the nature of reduplication associated with such idioms. For idioms like 洗澡 xi zao (take a bath), the first sign can be reduplicated to denote the shortness of the action: 洗澡 xi zao (take a bath) -- 洗洗澡 xi xi zao (take a short bath). If 洗澡 xi zao is a word, by definition, 洗 xi is a morpheme inside the word and 洗洗澡 xi-xi-zao belongs to morphological reduplication (AB--AAB type). However, this analysis fails to account for the generality of such reduplication: it is a general rule in Chinese grammar that a verb reduplicates itself contiguously to denote the shortness of the action. For example, 听音乐 ting (listen to) yin-yue (music) -- 听听音乐 ting ting yin-yue (listen to music for a while); 休息 xiu-xi (rest) -- 休息休息 xiu-xi xiu-xi (have a short rest), etc. On the other hand, when we accept that 洗澡 xi zao is a verb-object phrase in syntax and the nature of this reduplication is accordingly judged as syntactic, we come to a satisfactory and unified account for all the related data. As a result, only one reduplication rule is required in CPSG95 to capture the general phenomena; there is no need to do anything special for V+N idioms. This AB ‑‑ AAB type reduplication problem for the V+N idioms poses a big challenge to traditional word segmenters (Sun and Huang 1996). Moreover, even when a word segmenter successfully incorporates some procedure to cope with this problem, the essentially same rule has to be repeated in the grammar for the general VV reduplication. This is not desirable in terms of capturing the linguistic generality. All the evidence presented above indicates that idioms like 洗澡 xi zao , no matter whether V and N are used contiguously or not, are not words, but phrases. The idiomatic nature of such combinations seems to be the reason why most native speakers, including some linguists, regard them as words. Lü (1989: 113-114) suggests that vocabulary words like 洗澡 xi zao should be distinguished from grammar words. He was one of the first Chinese grammarians who found that the V+N relation in the idioms like 洗澡 xi zao is a syntactic verb object relation. But he did not provide full arguments for his view, neither did he offer a precise formalized analysis of this problem. As shown in the previous examples, the V+N I idioms do not differ from other transitive verb phrases in all major syntactic behaviors. However, due to their idiomatic nature, the V+N I idioms are different from ordinary transitive VPs in the following two major aspects. These differences need to be kept in mind when formulating the grammar to capture the phenomena. Semantics: the semantics of the idiom should be given directly in the lexicon, not as a result of the computation of the semantics of the parts based on some general principle of compositionality. Co-occurrence requirement: 洗 xi (or 擦 ca ) and 澡 zao must co-occur with each other; 走 zou (go) and 路 lu (way) must co-occur; etc. This is a requirement specific to the idioms at issue. For example, 洗 xi and 澡 zao must co-occur in order to stand as an idiom to mean ‘take a bath’. Based on the study above, the CPSG95 solution to this problem is described below. In order to enforce the co-occurrence of the V+N I idioms, it is specified in the CPSG95 lexicon that the head V obligatorily expects as its object an NP headed by a specific literal. This treatment originates from the practice of handling collocations in HPSG. In HPSG, there are features designed to enable the subcategorization for particular words, or phrases headed by particular words. For example, the feature and refer to the expletive there and it respectively for the special treatment of existential constructions, cleft constructions, etc. (Pollard and Sag 1987:62). The values of the feature PFORM distinguish individual prepositions like for, on , etc. They are used in phrasal verbs like rely on NP , look for NP , etc. In CPSG95, this approach is being generalized, as described below. As presented before, the feature for orthography records the Chinese character string for each lexical sign. When a specific lexical literal is required in an idiomatic expectation, the constraint is directly placed on the value of the feature of the expected sign, in addition to possible other constraints. It is standard practice in a lexicalized grammar that the expected complement (object) for the transitive structure be coded directly in the entry of the head V in the lexicon. Usually, the expected sign is just an ordinary NP. In the idiomatic VP like 洗 xi (...) 澡 zao , one further constraint is placed: the expected NP must be headed by the literal character 澡 zao . This treatment ensures that all pattern variations for transitive VP such as passive constructions, topicalized constructions, etc. in Chinese syntax will equally apply to the V+N I idioms. The difference in semantics is accommodated in the feature of the head V with proper co-indexing. In ordinary cases like 洗衣服 xi yi-fu (wash clothes), the argument structure is which requires two arguments, with the role filled by the semantics of the object NP. In the idiomatic case 洗澡 xi zao (take a bath), the V and N form a semantic whole, coded as . The V+N I idioms are formulated like intransitive verbs in terms of composing the semantics - hence coded as , with only one argument to be co-indexed with the subject NP. Note that there are two lexical entries in the lexicon for the verb 洗 xi (wash), one for the ordinary use and the other for the idiom, shown in (5-12) and (5-13). The above solution takes care of the syntactic similarity of the V+N I idioms and ordinary V+NP structures. It is also detailed enough to address their major differences. In addition, the associated reduplication process (i.e. V+N -- V+V+N) is no longer a problem once this solution is adopted. As the V in the V+N idioms is judged and coded as a lexical V (word) in this proposal, the reduplication rule which handles V -- VV will equally apply here. 5.2. Verb-object Idioms: V+N II The purpose of this section is to provide an analysis of another type of V+N idiom and present the solution implemented in CPSG95 based on the analysis. Examples like 洗澡 xi zao (take a bath) are in fact easy cases to judge. There are more marginal cases. When discussing Chinese verb-object idioms, L. Li (1990) and Shi (1992) indicate that the boundary between a word and a phrase in Chinese is far from clear-cut. There is a remarkable “gray area” in between. Examples in (5-14) are V+N II idioms, in contrast to the V+N I type, classified by L. Li (1990). (5-14.) V+N II: 伤心 shang xin type 伤心 shang (hurt) xin (heart) sad or break one's heart 担心 dan (carry) xin (heart) worry 留神 liu (pay) shen (attention) pay attention to 冒险 mao (take) xian (risk) take the risk 借光 jie (borrow) guang (light) benefit from 劳驾 lao (bother) jia (vehicle) beg the pardon 革命 ge (change) ming (life) make revolution 落后 luo (lag) hou (back) lag behind 放手 fang (release) shou (hand) release one's hold Compared with V+N I (洗澡 xi zao type), V+N II has more characteristics of a word. The lists below given by L. Li (1990) contrast their respective characteristics. (5-15.) V+N I (based on L. Li 1990:115-116) as a word V-N (a1) corresponds to one generalized sense (concept) (a2) usually contains ‘bound morpheme(s)’ as a phrase V X N (b1) may insert an aspectual particle (X= le/zhe / guo ) (b2) may insert all types of post-verbal modifiers (X=BUYU) (b3) may insert a pre-nominal modifier de -construction (X=DEP) (5-16.) V+N II (based on L. Li 1990:115) as a word V-N X (a1) corresponds to one generalized sense (concept) (a2) usually contains ‘bound morpheme(s)’ (a3) (some) may be followed by an aspectual particle (X= le/zhe/guo ) (a4) (some) may be followed by a post-verbal modifier of duration or number of times (X=BUYU) (a5) (some) may take an object (X=BINYU) as a phrase V X N (b1) may insert an aspectual particle (X= le/zhe / guo ) (b2) may insert all types of post-verbal modifiers (X=BUYU) (b3) may insert a pre-nominal modifier de -construction (X=DEP) For V+N I, the previous text has already given detailed analysis and evidence and decided that such idioms are phrases, not words. This position is not affected by the demonstrated features (a1) and (a2) in (5‑15); as argued before, (a1) and (a2) do not contribute to the definition of a grammar word. However, (a3), (a4) and (a5) are all syntactic evidence showing that V+N II idioms can be inserted in lexical positions. On the other hand, these idioms also show the similarity with V+N I idioms in the features (b1), (b2) and (b3) as a phrase. In particular, (a3) versus (b1) and (a4) versus (b2) demonstrate a 'minimal pair' of phrase features and word features. The following is such a minimal pair example (with the same meaning as well) based on the feature pairs (a3) versus (b1), with a post-verbal modifier 透 tou (thorough) and aspectual particle 了 le (LE). It demonstrates the borderline status of such idioms. As before, a similar example of an ordinary transitive VP is also given below for comparison. (5-17.) V+N II: word or phrase? 伤心:sad; heart-broken shang xin hurt heart (a) 我伤心透了 wo shang-xin tou le. I sad thorough LE I was extremely sad. (b) 我伤透了心 wo shang tou le xin . I break thorough LE heart I was extremely sad. (5-18.) Ordinary V+NP phrase: 恨 hen (hate) 他 ta (he) (a) * 我恨他透了 wo hen ta tou le. I hate he thorough LE (b) 我恨透了他 wo hen tou le ta . I hate thorough LE he I thoroughly hate him. As shown in (5-18), in the common V+NP structure, the post-verbal modifier 透 tou (thorough) and the aspectual particle 了 le (perfect aspect) can only occur between the lexical V and NP. But in many V+N II idioms, they may occur either after the V+N combination or in between. In (5‑17a), 伤心 shang xin is in the lexical position because Chinese syntax requires that the post-verbal modifier attach to the lexical V, not to a VP as indicated in (5-18a). Following the same argument, 伤 shang (hurt) alone in (5-17b) must be a lexical V as well. The sign 心 xin (heart) in (5‑17b) establishes itself in syntax as object of the V, playing the same role as 他 ta (he) in (5-18b). These facts show clearly that V+N II idioms can be used both as lexical verbs and as transitive verb phrases. In other words, before entering a context, while still in the lexicon, one can not rule out either possibility. However, there is a clear cut condition for distinguishing its use as a word and its use as a phrase once a V+N II idiom is placed in a context. It is observed that the only time a V+N II idiom assumes the lexical status is when V and N are contiguous . In all other cases, i.e. when V and N are not contiguous, they behave essentially similar to the V+N I type. In addition to the examples in (5-17) above, two more examples are given below to demonstrate the separated phrasal use of V+N II. The first is the case V+X+N where X is a possessive modifier attached to the head N. Note also the post-verbal position of 透 tou (thorough) and 了 le (LE). The second is an example of passivization when N occurs before V. These examples provide strong evidence for the syntactic nature of V+N II idioms when V and N are not used contiguously. (5-19.) (a) * 你伤他的心透了 ni shang ta de xin tou le. you hurt she DE heart thorough LE (b) 你伤透了他的心 ni shang tou le ta de xin . you hurt thorough LE she DE heart You broke her heart. (5-20.) V+N II: instance of passive with or without 被 bei (BEI) 心(被)伤透了 xin (bei) shang tou le. heart BEI break thorough LE The heart was completely broken. or: (Someone) was extremely sad. Based on the above investigation, it is proposed in CPSG95 that two distinct entries be constructed for each such idiom, one as an inseparable lexical V, and the other as a transitive VP just like that of V+N I. Each entry covers its own part of the phenomena. In order to capture the semantic link between the two entries, a lexical rule called V_N_II Rule is formulated in CPSG95, shown in (5-21). The input to the V_N_II Lexical Rule is an entry with where is a given sub-category in the lexicon for V+N II type verbs. The output is another entry with the same information except for three features , and . The new value for is a list concatenating the old and the for the expected . The new value is simply . The value for becomes . The outline of the two entries captured by this lexical rule are shown in (5-22) and (5-23). It needs to be pointed out that the definition of in CPSG95 is narrower than L. Li’s definition of V+N II type idioms. As indicated by L. Li (1990), not all V+N II idioms share the same set of lexical features (a3), (a4) and (a5) as a word. The definition in CPSG95 does not include the idioms which share the lexical feature (a5), i.e. taking a syntactic object. These are idioms like 担心 dan - xin (carry-heart: worry about). For such idioms, when they are used as inseparable compound words, they can take a syntactic object. This is not possible for all other V+N idioms, as shown below. (5-24.) (a) 她很担心你 ta hen dan-xin ni. he very worry (about) you He is very concerned about you. (b) * 他很伤心你 ta hen shang-xin ni. he very sad you In addition, these idioms do not demonstrate the full distributional potential of transitive VP constructions. The separated uses of these idioms are far more limited than other V+N idioms. For example, they can hardly be passivized or topicalized as other V+N idioms can, as shown by the following minimal pair of passive constructions. (5-25.)(a) * 心(被)担透了 xin (bei) dan tou le. heart BEI carry thorough LE (b) 心(被)伤透了 xin (bei) shang tou le. heart BEI break thorough LE The heart was completely broken. or: (Someone) was extremely sad. In fact, the separated use ('phrasal use') for such V+N idioms seems only limited to some type of X-insertion, typically the appearance of aspect signs between V and N. Such separated use is the only thing shared by all V+N idioms, as shown below. (5-26.)(a) 他担过心 ta dan guo xin he carry GUO heart He (once) was worried. (b) 他伤过心 ta shang guo xin he break GUO heart He (once) was heart-broken. To summarize, the V+N idioms like 担心 dan-xin which can take a syntactic object do not share sufficient generality with other V+N II idioms for a lexical rule to capture. Therefore, such idioms are excluded from the type. This makes these idioms not subject to the lexical rule proposed above. It is left for future research to answer the question whether there is enough generality among this set of idioms to justify some general approach to this problem, say, another lexical rule or some other ways of generalization of the phenomena. For time being, CPSG95 simply lists both the contiguous and separated uses of these idioms in the lexicon. It is worth noticing that leaving such idioms aside, this lexical rule still covers large parts of V+N II phenomena. The idioms like 担心 dan-xin only form a very small set which are in the state of transition to words per se (from the angle of language development) but which still retain some (but not complete) characteristics of a phrase. 5.3. Verb-modifier Idioms: V+A/V This section investigates the V+X idioms in the form of V+A/V. The data for the interaction of V+A/V idioms and the modal insertion are presented first. The subsequent text will argue for Lü's infix hypothesis for the modal insertion and accordingly propose a lexical rule to capture the idioms with or without modal insertion. The following is a sample list of V+A/V idioms, represented by kan jian (look-see: have seen). (5-27.) V+A/V: kan jian type 看见 kan (look) jian (see) have seen 看穿 kan (look) chuan (through) see through 离开 li (leave) kai (off) leave 打倒 da (beat) dao (fall) down with 打败 da (beat) bai (fail) defeat 打赢 da (beat) ying (win) fight and win 睡着 shui (sleep) zhao (asleep) fall asleep 进来 jin (enter) lai (come) enter 走开 zou (go) kai (off) go away 关上 guan (close) shang (up) close In the V+A/V idiom kan jian (have-seen), the first sign kan (look) is the head of the combination while the second jian (see) denotes the result. So when we say, wo (I) kan-jian (see) ta (he), even without the aspectual marker le (LE) or guo (GUO), we know that it is a completed action: 'I have seen him' or 'I saw him'. Idioms like kan-jian (have-seen) function just as a lexical whole (transitive verb). When there is an aspect marker, it is attached immediately after the idioms as shown in (5‑28). This is strong evidence for judging V+A/V idioms as words, not as syntactic constructions. (5-28.) 我看见了他 wo kan jian le ta. I look-see LE he I have seen him. The only observed separated use is that such idioms allow for two modal signs 得 de3 (can) and 不 bu (cannot) in between, shown by (5-29a) and (5-29b). But no other signs, operations or processes can enter the internal structure of these idioms. (5-29.) (a) 我看不见他 wo kan bu jian ta. I look cannot see he I cannot see him. (c) 你看得见他吗? ni kan de3 jian ta me? you look can see he ME Can you see him? Note that English modal verbs ‘can’ and ‘cannot’ are used to translate these two modal signs. In fact, Contemporary Mandarin also has corresponding modal verbs (能愿动词 neng-yuan dong-ci ): 能 neng (can) and 不能 bu neng (cannot). The major difference between Chinese modal verbs 能 neng / 不能 bu neng and the modal signs 得 de3 / 不 bu lies in their different distribution in syntax. The use of modal signs 得 de3 (can) and 不 bu (cannot) is extremely restrictive: they have to be inserted into V+BUYU combinations. But Chinese modal verbs can be used before any VP structures. It is interesting to see the cases when they are used together in one sentence, as shown in (5-30 a+b) below. Note that the meaning difference between the two types of modal signs is subtle, as shown in the examples. (5-30.)(a) 你看得见他吗? ni kan de3 jian ta me? you look can see he ME Can you see him? (Is your eye-sight good enough?) (b) 你能看见他吗? ni neng kan jian ta me? you can see he ME Can you see him? (Note: This is used in more general sense. It covers (a) and more.) (a+b) 你能看得见他吗? ni neng kan de3 jian ta me? you can look can see he ME Can you see him? (Is your eye-sight good enough?) (5-31.)(a) 我看不见他 wo kan bu jian ta I look cannot see he I cannot see him. (My eye-sight is too poor.) (b) 我不能看见他 wo bu neng kan jian ta I not can see he I cannot see him. (Otherwise, I will go crazy.) (a+b) 我不能看不见他 wo bu neng kan bu jian ta. I not can look cannot see he I cannot stand not being able to see him. (I have to keep him always within the reach of my sight.) Lü (1989:127) indicates that the modal signs are in fact the only two infixes in Contemporary Chinese. Following this infix hypothesis, there is a good account for all the data above. In other words, the V+A/V idioms are V+BUYU compound words subject to the modal infixation. The phenomena of 看得见 kan-de3-jian (can see) and 看不见 kan-bu-jian (cannot see) are therefore morphological by nature. But Lü did not offer formal analysis for these idioms. Thompson (1973) first proposed a lexical rule to derive the potential forms V+ de3/bu +A/V from the V+A/V idioms. The lexical rule approach seems to be most suitable for capturing the regularity of the V+A/V idioms and their infixation variants V+ de3/bu +A/V. The approach taken in CPSG95 is similar to Thompson’s proposal. More precisely, two lexical rules are formulated in CPSG95 to handle the infixation in V+A/V idioms. This way, CPSG95 simply lists all V+A/V idioms in the lexicon as V+A/V type compound words, coded as . Such entries cover all the contiguous uses of the idioms. It is up to the two lexical rules to produce two infixed entries to cover the separated uses of the idioms. The change of the infixed entries from the original entry lies in the semantic contribution of the modal signs. This is captured in the lexical rules in (5-32) and (5-33). In case of V+ de3 +A/V, the Modal Infixation Lexical Rule I in (5-32) assigns the value to the feature in the semantics. As for V+ bu +A/V, there is a setting used to represent the negation in the semantics, shown in (5-33). The following lexical entry shows the idiomatic compound 看见 kan-jian as coded in the CPSG95 lexicon (leaving some irrelevant details aside). This entry satisfies the necessary condition for the proposed infixation lexical rules. The modal infixation lexical rules will take this type compound as input and produce two V+MODAL+BUYU entries. As a result, new entries 看得见 kan-de3-jian (can see) and 看不见 kan-bu-jian (cannot see) as shown below are added to the lexicon. The above proposal offers a simple, effective way of capturing the linguistic data of the interaction of V+A/V idioms and the modal insertion, since it eliminates the need for any change of the general grammar in order to accommodate this type of separable verbs interacting with 得 de3 / 不 bu , the only two infixes in Chinese. 5.4. Summary This chapter has conducted an inquiry into the linguistic phenomena of Chinese separable verbs, a long-standing difficult problem at the interface of Chinese compounding and syntax. For each type of separable verb, arguments for the wordhood judgment have been presented. Based on this judgment, CPSG95 provides analyses which capture both structural and semantic aspects of the constructions at issue. The proposed solutions are formal and implementable. All the solutions provide a way of capturing the link between the separated use and contiguous use of the V+X idioms. The proposals presented in this chapter cover the vast majority of separable verbs. Some unsolved rare cases or potential problems are also identified for further research. ---------------------------------------------------------------------- They are also called phrasal verbs ( duanyu dongci ) or compound verbs ( fuhe dongci ) among Chinese grammarians. For linguists who believe that they are compounds, the V+N separable verbs are often called verb object compounds and the V+A/V separable verbs resultative compounds . The want of a uniform term for such phenomena reflects the borderline nature of these cases. According to Zhao and Zhang (1996), out of the 3590 entries in the frequently used verb vocabulary, there are 355 separable V+N idioms. As the term 'separable verbs' gives people an impression that these verbs are words (which is not necessarily true), they are better called V+X (or V+N or V+A/V) idioms. There is no disagreement among Chinese grammarians for the verb-object combinations like xi wan : they are analyzed as transitive verb phrases in all analyses, no matter whether the head V and the N is contiguous (e.g. xi wan 'wash dishes') or not (e.g. xi san ge wan 'wash three dishes'). Such signs as zao (bath), which are marked with # in (5-1), are often labeled as 'bound morphemes' among Chinese grammarians, appearing only in idiomatic combinations like xi zao (take a bath), ca zao (clean one's body by scrubbing). As will be shown shortly, bound morpheme is an inappropriate classification for these signs. It is widely acknowledged that the sequence num+classifier+noun is one typical form of Chinese NP in syntax. The argument that zao is not a bound morpheme does not rely on any particular analysis of such Chinese NPs. The fact that such a combination is generally regarded as syntactic ensures the validity of this argument. The notion ‘free’ or ‘freely’ is linked to the generally accepted view of regarding word as a minimal ‘free’ form, which can be traced back to classical linguistics works such as Bloomfield (1933). It is generally agreed that idioms like kick the bucket are not compounds but phrases (Zwicky 1989). That is the rationale behind the proposal of inseparability as important criterion for wordhood judgment in Lü (1989). In Chinese, reduplication is a general mechanism used both in morphology and syntax. This thesis only addresses certain reduplication issues when they are linked to the morpho-syntactic problems under examination, but cannot elaborate on the Chinese reduplication phenomena in general. The topic of Chinese reduplication deserves the study of a full-length dissertation. In the ALE implementation of CPSG95, there is a VV Diminutive Reduplication Lexical Rule in place for phenomena like xi zao (take a bath) à xi xi zao (take a short bath) ; ting yin-yue (listen to music) à ting ting yin-yue (listen to music for a while) ; xiu-xi (rest) à xiu-xi xiu-xi (have a short rest). He observes that there are two distinct principles on wordhood. The vocabulary principle requires that a word represent an integrated concept, not the simple composition of its parts. Associated with the above is a tendency to regard as a word a relatively short string. The grammatical principle, however, emphasizes the inseparability of the internal parts of a combination. Based on the grammatical principle, xi zao is not a word, but a phrase. This view is very insightful. The pattern variations are captured in CPSG95 by lexical rules following the HPSG tradition. It is out of the scope of this thesis to present these rules in the CPSG95 syntax. See W. Li (1996) for details. In the rare cases when the noun zao is realized in a full-fledged phrase like yi ge tong-kuai de zao (a comfortable bath), we may need some complicated special treatment in the building of the semantics. Semantically, xi (wash) yi (one) ge (CLA) tong‑kuai (comfortable) de (DE) zao (bath): ‘take a comfortable bath’ actually means tong‑kuai (comfortable) de2 (DE2) xi (wash) yi (one) ci (time) zao (bath): ‘comfortably take a bath once’. The syntactic modifier of the N zao is semantically a modifier attached to the whole idiom. The classifier phrase of the N becomes the semantic 'action-times' modifier of the idiom. The elaboration of semantics in such cases is left for future research. The two groups classified by L. Li (1990) are not restricted to the V+N combinations. In order not to complicate the case, only the comparison of the two groups of V+N idioms are discussed here. Note also that in the tables, he used the term ‘bound morpheme’ (inappropriately) to refer to the co-occurrence constraint of the idioms. Another type of X-insertion is that N can occasionally be expanded by adding a de ‑phrase modifier. However, this use is really rare. Since they are only a small, easily listable set of verbs, and they only demonstrate limited separated uses (instead of full pattern variations of a transitive VP construction), to list these words and all their separated uses in the lexicon seems to be a better way than, say, trying to come up with another lexical rule just for this small set. Listing such idiosyncratic use of language in the lexicon is common practice in NLP. In fact, this set has been becoming smaller because some idioms, say zhu-yi 'focus-attention: pay attention to', which used to be in this set, have already lost all separated phrasal uses and have become words per se. Other idioms including dan-xin (worry about) are in the process of transition (called ionization by Chao 1968) with their increasing frequency of being used as words. There is a fairly obvious tendency that they combine more and more closely as words, and become transparent to syntax. It is expected that some, or all, of them will ultimately become words proper in future, just as zhu-yi did. In general, one cannot use kan-jian to translate English future tense 'will see', instead one should use the single-morpheme word kan : I will see him -- wo (I) jiang (will) kan (see) ta (he). Of course, is a sub-type of verb . The use of this feature for representing negation was suggested in Footnote 18 in Pollard and Sag (1994:25) This is the procedural perspective of viewing the lexical rules. As pointed out by Pollard and Sag (1987:209), “Lexical rules can be viewed from either a declarative or a procedural perspective: on the former view, they capture generalizations about static relationships between members of two or more word classes; on the latter view, they describe processes which produce the output from the input form.” PhD Thesis: Morpho-syntactic Interface in CPSG (cover page) PhD Thesis: Chapter I Introduction PhD Thesis: Chapter II Role of Grammar PhD Thesis: Chapter III Design of CPSG95 PhD Thesis: Chapter IV Defining the Chinese Word Overview of Natural Language Processing Dr. Wei Li’s English Blog on NLP
董: 让我们记住 Benjio 的这段话:“【 Yoshua 】深度学习指向与乔姆斯基完全相反。深度学习几乎完全依赖通过数据进行的学习。当然,我们设计了神经网络的构架,但在大部分时候,它都依赖于数据、大量的数据。至于乔姆斯基,则是聚焦于固有语法和对逻辑的使用,而深度学习则关注意义。我们发现,语法只是像蛋糕上的糖霜一样的表层的东西。相反,真正重要的东西是我们的意图:我们对词的选择决定了我们要表达什么意义,而与词相联系的意义是可以被学习的。这些思想都与乔姆斯基学派的观点针锋相对。“ 看看 5 年以后还有什么话? 我查了查,上面Benjio的那段话的出处: Machines that dream Understanding intelligence: An interview with Yoshua Bengio. By David BeyerApril 19, 2016 引文原文如下:YB: It suggests the complete opposite. Deep learning relies almost completely on learning through data. We, of course, design the neural net’s architecture, but for the most part, it relies on data and a lot of it. And whereas Chomsky focused on an innate grammar and the use of logic, deep learning looks to meaning. Grammar, it turns out, is the icing on the cake. Instead, what really matters is our intention: it’s mostly the choice of words that determines what we mean, and the associated meaning can be learned. These ideas run counter to the Chomskyan school. 把原文的最后一句送进流行机译系统,看看什么结果:These ideas run counter to the Chomskyan school. Google的:这些想法背道而驰乔姆斯基学校。 Baidu的:这些想法背道而驰的乔姆斯基学派。 看起来,就是缺了那些“糖霜”! 白 : 他们对数据和学习的偏爱,掩盖了一个重要的因素:想要学到的东西长什么样。这个“长什么样”决定了学习的上限,再多数据也突不破这个上限。 多层,循环,记忆,都是“长什么样”的创新。 从某种意义上,都是在向 Chomsky 靠拢 董 : 还记得 SMT 刚兴起时,有两条宣称: 1. 不需要语言学家的知识; 2. 依靠标注的数据,主要是对齐的数据。随着数据的增加,翻译的能力将提高。那时是有监督的数据,这把该是无监督的数据了。这就连语言的句法也知识 糖霜”了。这回大概是真正的智能了。难怪李彦宏宣称人工翻译很快将被机器取代了。太狂了,就不是科学了。 白 : 他们把数据的作用夸大了,把模型长什么样的作用低估了。 马 : 公司的喜欢说大话炒作,媒体人又喜欢跟着他们吵 我 : 那段话不仅仅是大话, 而是让人怀疑他知道不知道自己在说啥。 智人说梦罢, 不值得认真对待, 我不管他 or 她是谁。 另一方面,在一个非常狭窄的领域,一个非常粗线条的“语义落地”的应用,也许“ 毛毛虫”长成啥样 的制约可以让位。 这时候,大量的数据,从数据中学习一个黑箱子出来,是可能达到可用甚至超过人工水平的“落地”应用的。 只有细线条的语义落地,对语言的机制和结构有较强的依赖,这时候白老师说的再多的数据也突不破这个上限才真正是盲目迷信学习者的紧箍咒。 就举这个我最近五年一直在做的 sentiment analysis 为例。 如果领域是 movie reviews ,语义落地的目标定为褒贬分类, 可以利用 movie review 中读者打星作为客观度量, 学出一个系统来与人工标注的打星看其吻合度。 褒分类定义为四星五星,贬分类定义为一星或二星。实践证明这是一个适合机器学习的任务,如果打了星的训练数据足够多的话,其结果不亚于人工。可以做双盲试验。可是要是语义落地都是如此粗线条的“语义”目标的话,我们语言学家就不要吃饭了。 一旦语义落地的实际需要是细线条的,语言长成啥样的乔姆斯基或 quasi-Chomsky 的毛毛虫的机制开始发力:顺之者昌,逆之者 stuck。 对于 sentiment 细线条,社会媒体舆情挖掘类应用大体是 这样的语义落地需求 : ( 1 ) 分类不够,还必须把类与 topic 相关联。 movie review 讨巧的地方是, topic 是外定的,在标题或 meta data 里;而社会媒体的大多数 topic 是在文本里的; ( 2 ) 不能是 movie review 这样的狭窄领域,而是领域独立 ; ( 3 )不能是 movie review 这样的成段落的文本,而是以绝大多数短消息为主的社会媒体; ( 4 ) 不能是简单的褒贬情绪分类,必须找到情绪背后的种种理由。 多方面的来源(种种独立的benchmarking,加上我们自己的实验探索)表明,面对这样一个任务,即便单就(1)(2)(3)而言,目前的机器学习 sentiment 死定了,突破不了大约 60% 的“与 topic 关联的褒贬”精准度瓶颈(且不说(4)细线条的情绪背后的原因等的抽取挖掘)。而语言学的路子可以轻易达到 80%+ ,这就是语义落地时的差别度量,至少 20% 精准度差距。 现在的问题变成,在实际应用中,到底多大比例的语义落地需求是粗线条就可以满足,多大比例的应用必须对“语义”有比较深入的分析? 当年 Autonomy 那家公司做得蛮成功,其中主打的 text analytics 应该就是依赖粗线条的语义,分类聚类(classfication or clustering)之类,被倒霉的 HP 并购后,现在也不大听说了。否则还可以关注一下他们在粗线条落地的语用上到底能走多远,感觉上他们已经几乎做到极限了,充分采集了“ 低枝果实 ”。 MT 当然不属于粗线条的语义落地,好在有几乎无限的人工翻译积累作为带标大数据(labeled big data),所以一路高歌猛进到今天的百度 MT 、谷歌 MT 之类的普及程度。但是现在已经很清楚, it is stuck, 如果不在语言结构上下功夫的话。我是相信白老师和董老师的铁口的,本质上看,再多的数据也救不了它 除非做某种改弦易辙。 戴 : 如果结构化的方法也无法抽象出语义是如何结构化的话,最好的语法结构分析也是徒劳的。纯粹的机器学习方式至少可以绕过去这一步直接面向目标来处理。对于意图来说,并不是一定要理解意图是怎么构成的或者如何构成,直接针对意图使用的目的,比如返回合适的结果也是可以的 我 : “如果结构化的方法也无法抽象出语义是如何结构化的话”?? 太绕。说的是什么状况? 说到底不就是:通过结构还是绕过结构达到目标么? 戴 : 简单地说就是你语法结构如何走向语义这一步,现在不都卡在这里吗。而且也没有充分的理由说明必须由语法结构走向语义,这只是语言学上的思维而已 我 : 不能抽象谈语义:至少要分粗线条或细线条。现在的 argument 就是,绕过结构到达细线条的语义,基本走不通。 这个语义就是落地的语义,语用阶段的语义。 戴 : 问题是细线条的语义是什么?如果都不知道是什么,怎么说不能达到呢 我:我不是举例说明了粗细的区别了吗,还可以举更多的例。 戴 : 以什么样的形式呈现?需要结构化吗 我 : 估计是背景相差大,好像我们不在一个频道,因此对话很困难。 白 : 老乔所说的 logic form 也不是狭义的逻辑,只是填坑的结构而已。连填坑的结构都不要,还好意思说是扔下逻辑直奔语义。 董 : 如果有人写一篇论文,批评“语法 = 糖霜论“的,我不知道如果投稿给 ACL 或 COLING ,会通得过审阅吗?记得在我国的计算语言学研究中,也曾有过为多数人不太赞同的”学派“,但几乎没有一届国内的学术大会会完全枪毙那些论文的。学术研究要允许真正的百花齐放,不可以” squeeze out “( Church 语)。这就是为什么我不赞成现在 NLP 界的风气。 白 : 江湖归江湖,落地归落地 【相关】 《立委随笔:语言自动分析的两个路子》 泥沙龙笔记:parsing 是引擎的核武器,再论NLP与搜索 泥沙龙笔记:从 sparse data 再论parsing乃是NLP应用的核武器 【白硕 - 穿越乔家大院寻找“毛毛虫”】 【科研笔记:NLP “毛毛虫” 笔记,从一维到二维】 一切声称用机器学习做社会媒体舆情挖掘的系统,都值得怀疑 【立委科普:基于关键词的舆情分类系统面临挑战】 一袋子词的主流方法面对社交媒体捉襟见肘,结构分析是必由之路 【立委科普:自动民调】 【立委科普:舆情挖掘的背后】 Coarse-grained vs. fine-grained sentiment extraction 【立委科普:自然语言parsers是揭示语言奥秘的LIGO式探测仪】 【新智元笔记:李白对话录 - RNN 与语言学算法】 【立委科普:语言学算法是 deep NLP 绕不过去的坎儿】 【泥沙龙笔记:NLP hard 的歧义突破】 【立委科普:结构歧义的休眠唤醒演义】 【NLP主流的反思:Church - 钟摆摆得太远(1):历史回顾】 【Church - 钟摆摆得太远(5):现状与结论】 没有语言学的 CL 走不远 【置顶:立委科学网博客NLP博文一览(定期更新版)】 《朝华午拾》总目录
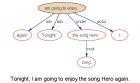
我们知道,语句呈现的是线性的字符串,而语句 结构却是二维的。我们之所以能够理解语句的意思,是因为我们的大脑语言处理中枢能够把线性语句解构(decode)成二维的结构:语法学家常常用类似下列的上下颠倒的树形图来表达解构的结果(所谓 parsing)。 上面这个树形图叫作依从关系树形图(dependency tree,常常用来表达词或词组之间的逻辑语义关系,与此对应的还有一种句法树,叫短语结构树 phrase structure tree,更适合表达语句单位之间的边界与层次关系)。直观地说,所谓理解了一句话,其实就是明白了两种意义:(1)节点的意义(词汇意义);(2)节点之间的关系意义(逻辑语义)。譬如上面这个例子,在我们的自动语句分析中有大小六个节点:【Tonight】 【I】 【am going to enjoy】 【the 【song】 Hero】 【again】,分解为爷爷到孙儿三个层次,其中的逻辑语义是:有一个将来时态的行为【am going to enjoy】,结构上是老爷爷,他有两个亲生儿子,两个远房侄子。长子是其逻辑主语(Actor) 【I】,此子是其逻辑宾语(Undergoer)【the song Hero】,父子三人是语句的主干(主谓宾,叫做 argument structure),构成语句意义的核心。 两个远房侄子,一个是表达时间的状语(adverbial)【Tonight】,另一个表达频次的状语(adverbial)【again】。最后,还有一个孙子辈的节点【song】,他是次子的修饰语(modifier,是同位语修饰语),说明【Hero】的类别。 从句法关系角度来看,依从关系遵从一个原则:老子可以有n(n=0)个儿子(图上用下箭头表示),而儿子只能有一个老子:如果有一个以上的老子,证明有结构歧义,说明语义没有最终确定,语言解构(decoding)没有最终完成。虽然一个老子可以有任意多的下辈传人,其亲生儿子是有数量限制的,一般最多不超过三个,大儿子是主语,次子是宾语,小儿子是补足语。比如在句子 “I gave a book to her” 中,动词 gave 就有三个亲儿子:主语 【I】, 宾语【a book】,补足语 【to her】. 很多动词爷爷只有两个儿子(主语和宾语,譬如 John loves Mary),有的只有一个儿子(主语,譬如 John left)。至于远房侄子,从结构上是可有可无的,在数量上也是没有限量的。他们的存在随机性很强,表达的是伴随一个行为的边缘意义,譬如时间、地点、原因、结果、条件等等。 自然语言理解(Natural Language Understanding)的关键就是要模拟人的理解机制,研制一套解构系统(parser),输入的是语句,输出的是语法结构树。在这样的结构树的基础上,很多语言应用的奇迹可以出现,譬如机器翻译,信息抽取,自动文摘,智能搜索,等等。 在结束本文前,再提供一些比较复杂一些的语句实例。我把今天上网看到的一段英文输入给我们研制的parser,其输出的语法结构树如下(未经任何人工编辑,分析难免有小错)。 说明:细心的读者会发现下列结构树中,有的儿子有两个老子,有的短语之间互为父子,这些都违反了依存关系的原则。其实不然。依存关系的原则针对的是句法关系,而句法后面的逻辑关系有时候与句法关系一致,有时候不一致。不一致的时候就会出现两个老子,一个是与句法关系一致的老子,一个是没有相应的显性句法关系的老子。最典型的情形是所谓的隐性(逻辑)主语或宾语。 譬如第一个图示中的右边那棵结构树中,代词「I」就有两个老子:其句法老子是谓语动词「have learned」,它还有一个非谓语动词(ING形式)的隐性的逻辑老子「(From) reading」,也做它的逻辑主语 (who was reading? I)。再如第二个图示中的语法结构树中,定语从句的代表动词「were demonstrating」的句法老子是其所修饰的名词短语「students」,但逻辑上该名词短语却是定语从句动词「were demonstrating」的主语(actor)。有些纯粹的句法分析器(parser)只输出句法关系树,而我们研制的parser更进一步,深入到真正的逻辑语义层次。这样的深层分析为自然语言理解提供了更为坚实的基础,因为显性和隐性的关系全部解构,语义更为完整。 我们每天面对的就是这些树木构成的语言丛林。在我的眼中,它们形态各异,婀娜多姿,变化多端而不离其宗(“语法”)。如果爱因斯坦在时空万物中看到了造物主的美,如果门捷列夫在千姿百态的物质后面看到了元素表的简洁,语言学家则是在千变万化的语言现象中看到了逻辑结构之美。这种美的体验伴随着我们的汗水,鼓励我们为铲平语言壁垒而愚公移山,造福人类。 后记:When I showed the above trees to my daughter today, she was amazed, pretty! She asked, is this what you made the machine to do in diagramming sentences? Yes. Wow, incredible. I don't think I can diagram the sentences as nice as these. Can some day the machine be smarter than you the creator? Is the machine learning by itself? I said, it is not self-learning at this point and the self-learning system is too research oriented to put into a real life system now. But I do observe from time to time that the machine we made for parsing sometimes generate results of very complicated sentences way beyond our expectation, better than most human learners at times. This is because I encode the linguistics knowledge piece by piece, and machine is super good at memory. Once taught, it remembers every piece of knowledge we programmed into the system. Over the years of the development cycle, the accumulation of the knowledge is incredibly powerful. We humans are easy to forget things and knowledge, but machine has no such problems. In this sense, it is not impossible that a machine can beat his creator in practical performance of a given task. 回答: I don't think tree is the way my mind thinks 1窃以为,句法树迄今仍是大脑黑箱作业的最好的模拟和理论 2 does not really matter 作者: 立委 (*) 日期: 06/03/2011 04:30:20 As long as subtree matching is a handy and generalized way of info extraction. Tree is not the goal but a means to an end. The practical end is to extract knowledge or facts or sentiments from language. In practice, our goal is not to simulate the human comprehension per se , the practical goal is: Quote 在这样的结构树的基础上,很多语言应用的奇迹可以出现,譬如机器翻译,信息抽取,自动文摘,智能搜索,等等。 【相关博文】 《泥沙龙笔记:漫谈自动句法分析和树形图表达》 【 科普小品:文法里的父子原则 】 【立委科普:语法结构树之美(之二)】 《新智元:有了deep parsing,信息抽取就是个玩儿》 泥沙龙笔记:parsing 是引擎的核武器,再论NLP与搜索 乔氏 X 杠杠理论 以及各式树形图表达法 【 立委随笔:创造着是美丽的 】 【 科研笔记:开天辟地的感觉真好 】 【立委科普:美梦成真的通俗版解说】 【征文参赛:美梦成真】 【立委科普:自然语言parsers是揭示语言奥秘的LIGO式探测仪】 【置顶:立委科学网博客NLP博文一览(定期更新版)】
 标签: 句法
标签: 句法