LEGClust—A Clustering Algorithm Based on Layered Entropic Subgraphs A Redundancy-Based Measure of Dissimilarity among Probability Distributions for Hierarchical Clustering Criteria
read SemiBoost: Boosting forSemi-SupervisedLearning 半监督 Boost : SemiBoost 半监督提升 : SemiBoost 半监督提升 : SemiBoost read Semi-SupervisedLearning via Regularized Boosting Working on MultipleSemi-SupervisedAssumptions 正则提升 : Regularized Boosting 正则提升 : Regularized Boosting read SemisupervisedLearning for a Hybrid Generative/Discriminative Classifier based on the Maximum Entropy Principle 混合分类器的半监督学习 : Semisupervised Learningfor a Hybrid read Linear Neighborhood Propagation and Its Applications read Graph-BasedSemisupervisedLearning 先近邻再远亲: Sequential predictions Algorithm read Semi-SupervisedClassification via Local Spline Regression 局部样条回归 : Local Spline Regression 局部样条回归 : Local Spline Regression 像样条那样入党 : Local Spline Regression read The Sum-over-Paths Covariance Kernel: A Novel Covariance Measure between Nodes of a Directed Graph 统计物理应用于机器学习的完美典范 : Sum-over-PathsCovar 统计物理应用于机器学习的完美典范 : Sum-over-PathsCovariance Kernel read Semisupervised Multitask Learning 半监督多任务学习: Semisupervised Multitask Learning Semisupervised Learning of Hidden Markov Models via a Homotopy Method Semisupervisedlearning of classifiers: theory, algorithms, and their application to human-computer interaction On Classification with Incomplete Data Learning to Transform Time Series with a Few Examples The Effect of Model Misspecification onSemi-SupervisedClassification Nonsmooth Optimization Techniques for Semisupervised Classification
Maximum-Likelihood Registration of Range Images with Missing Data read Point SetRegistration: Coherent Point Drift read Rigid and Articulated PointRegistrationwith Expectation Conditional Maximization read Penalizing Closest Point Sharing for Automatic Free Form ShapeRegistration read Nonlinear ShapeRegistrationwithout Correspondences read 3D Face Recognition Using Simulated Annealing and the Surface Interpenetration Measure read Decoupled Linear Estimation of Affine Geometric Deformations and Nonlinear Intensity Transformations of Images A Similarity Measure for Image and Volumetric Data Based on Hermann Weyl's Discrepancy
医科院信息所国内期刊论文主题分析 李阳 许培扬 * (北京协和医学院医学信息研究所 北京 100020 ) 目的: 通过对 1978 年 ~2011 年医科院信息所研究人员发表并被中国知网 CNKI 学术文献总库中《中国学术期刊网络出版总库》收录的 期刊 论文进行计量分析,旨在揭示医科院信息所研究人员发表期刊论文涉及的研究主题随时间演进情况。 方法: 运用共词分析法和社会网络分析法,采用 MS Excel2003 自带的 VBA 程序及 社会网络分析软件 Ucinet 中的可视化工具 Netdraw ,从关键词角度开展论文主题分析。 结果: 1978 年 ~2011 年,《中国学术期刊网络出版总库》共收录医科院信息所研究人员发表的期刊论文 990 篇; 研究主题主要包括医学图书馆学研究、医学信息分析与评价及卫生政策研究三个方面。 结论: 未来一段时间内医科院信息所将重点开展医学信息资源建设与网络技术、医学信息分析与评价、卫生政策 研究 及卫生信息化四个方面的研究。 医科院信息所 / 中国医学科学院医学信息研究所 ; 期刊论文 ; 共词分析 ; 社会网络分析 ; 信息可视化 ; 文献计量学 A Bibliometrics Analysis of Chinese Journal Articles Published by researchers in Institute of Medical Information Li Yang 1 Xu Pei-yang * (Inistitute of Medical Information, Peking Union Medical College, Beijing 100020) Objective : This study aims at providing some references about the history, evolution of the development trends of research topics in Institute of Medical Information, Chinese Academy of Medical Sciences by analyzing all journal articles published by researchers in this institute since 1978, which is included by China Academic Journal Network Publishing Database(CAJD). Methods: keywords were analyzed by co~word analysis and social network analysis(SNA) with VBA program nested in MS Excel 2003 and Netdraw which is a information visualization tool. Results: A total of 990 journal articles were searched in CAJD; The major research themes are medical library research, medical information analysis or evaluation and health policy research. Conclusion: The research focus of the institute in the future will be Medical information resources construction and network technology, medical information analysis and evaluation, health policy analysis and evaluation, and health informatization. Institute of Medical Information, Chinese Academy of Medical Sciences; Journal Articles; Co-word Analysis; Social Network Analysis; Information Visualization; Bibliometrics 作者简介:李阳( 1986~ ),男(汉),河南省焦作市,北京协和医学院医学信息研究所在读硕士研究生,研究方向:医学信息分析与评价,已发表论文 2 篇。 E~mail:feng8100feng@163.com. 联系电话 : 15201507155. * 通讯作者:许培扬( 1953~ ),男(汉),浙江省诸暨市,大学本科,中国医学科学院医学信息研究所研究员,硕士生导师,研究方向:医学信息分析与情报研究方法。 E~mail: xupeiyang@vip.163.com . 全文见 医科院信息所期刊论文计量分析终稿 2011 12 08.doc
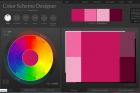
个人认为EXCEL中,配色问题绝不是一个小问题。这是一个EXCEL中的高技技巧。哈哈。 专利的商务图表很让人崇拜,也是打动用户的关键一弹。 那么如何实现配色呢?网上有诸多技巧,我这里不一一列举,我仅仅给大家介绍一个最简单、直观的方法。(独家秘籍) http://colorschemedesigner.com/ 这是一个叫色彩主题设计的网站,专门帮助我们来解决不同主题的配色问题。 简要介绍一下功能,我也不是太清楚。 1.可以设置主色调和2分法,4分法等多种配色方案 2.可以精准选择颜色,而且有冷暖色调选择。 3.选择的颜色首先是可以直接预览的。 4.可以查看你选择的方案和色调搭配的整体效果如何,这里有亮光版和暗光版的选择。 5.当你确定好配色方案后,可以将配色方案导出,包括HTML,XML,TXT格式等 做一个简单示例: 以下呈现我选择的色彩搭配。 相关的色彩具体参数如下,可以用XML文件导出 !-- Color Palette by Color Scheme Designer -- palette !-- Generated by Color Scheme Designer Petr Stanicek 2002-2010 -- url http://colorschemedesigner.com/#5y200o8o8CkAv / url colorspace RGB; / colorspace colorset title =" Primary Color " id =" primary " color id =" primary-1 " b =" 64 " g =" 45 " r =" 183 " rgb =" B72D40 " nr =" 1 "/ color id =" primary-2 " b =" 70 " g =" 61 " r =" 127 " rgb =" 7F3D46 " nr =" 2 "/ color id =" primary-3 " b =" 23 " g =" 10 " r =" 104 " rgb =" 680A17 " nr =" 3 "/ color id =" primary-4 " b =" 122 " g =" 105 " r =" 225 " rgb =" E1697A " nr =" 4 "/ color id =" primary-5 " b =" 156 " g =" 145 " r =" 225 " rgb =" E1919C " nr =" 5 "/ / colorset colorset title =" Complementary Color " id =" complement " color id =" complement-1 " b =" 40 " g =" 163 " r =" 70 " rgb =" 46A328 " nr =" 1 "/ color id =" complement-2 " b =" 54 " g =" 113 " r =" 68 " rgb =" 447136 " nr =" 2 "/ color id =" complement-3 " b =" 9 " g =" 93 " r =" 29 " rgb =" 1D5D09 " nr =" 3 "/ color id =" complement-4 " b =" 101 " g =" 217 " r =" 129 " rgb =" 81D965 " nr =" 4 "/ color id =" complement-5 " b =" 140 " g =" 217 " r =" 158 " rgb =" 9ED98C " nr =" 5 "/ / colorset / palette
时代杂志有一期的主题是《美国梦还能实现吗?》(Can you still move up in America?) 主要是说美国梦越来越难以实现了。 来美国二十多年,我自觉是已经实现美国梦了。我从心底里感谢美国,感谢美国给我的机会。我周围也有很多朋友或多或少都实现了美国梦。其中我写过一个 例子 。 后来有读者评论:实现美国梦当然好,很浪漫。但并不是每个人都有能力有运气爬上社会的阶梯。一个国家的责任之一是保证那些在社会底层的人也能过上有尊严的日子。(感觉这个评论真的说到点子上)
 标签: 主题
标签: 主题