互联网信息生,应该说都是界于结构化与非结构化之间。互联网信息的概念过泛,这里限定在 Web 网页信息及其链接网络所承载的信息,或者叫做 Web 信息更为合适一些。关于 Web 信息的挖掘研究,各个学科研究重点有些不同。大的来看, Web 挖掘( Web Mining ),主要有 Web 内容挖掘、 Web 结构挖掘和 Web 使用记录挖掘。计算机科学,强调如何利用计算机技术自动得到有用的信息;而情报学,则更为偏重这些信息是什么,怎么让它更为有用;相应地其他学科研究也有自己的特色。 从最近的技术发展和应用来看,我更倾向于将任何非结构化的信息,看作是结构化的信息。 NoSQL 之美,也逃不过结构的骨干;社交网站更像一个网络信息组织系统,只是组织方式发生了变革; Web 链接,也有结构化表示方法; Web 的 HTML 也能抽取出核心的结构要素。似乎结不结构在于如何看待与分析了,个人觉得目前对于非结构的信息转变为了结构信息才更有研究价值,研究也更为方便。最近有一些关于 Web 信息结构化处理的想法,先记在下面。 首先, Web 结构化信息的搜集。国内计量学喜欢对一些结构性较强的数据进行分析,其原因之一在于这些信息获取非常容易, ISI 、期刊网等等说到底也都是关系数据库中的数据,其结构性非常强,数据获取比较容易。在 Web 信息获取方面,链接信息结构性也比较强,似乎也可以利用现有的一些网络计量理论进行分析。但链接信息,似乎是网络中比较外在的数据,对于 Web 网页内容呢,是不是也有结构化的信息可以采集并进行分析?这一方面,深网、垂直搜索引擎等已有所研究,主要还是数据库信息的 Web 呈现方式。一般来说,其采集的信息在一个 Web 页之内。利用相关的一些数据采集软件即可实现,如火车头、 htmlclient 、 htmlparser 等,不算难但也并不是随便就能使用的。而对于一些涉及多个 Web 页、更为宏观一些的结构化数据呢?目前这方面的分析似乎不太多,比如说社交网站中的数据采集,需要涉及用户关系的采集、核心分析对象(如日志)的采集等,并不是在一个网页内就能实现的。这恐怕只有编程实现了。当然,如果有数据库数据,那么也不用去采集。可惜的是,这方面开放的数据集很少见,需要看研究的具体领域,现在关于标签数据集、评论数据集等还有一些。 其次, Web 结构化信息的分析方法 。说到分析方法似乎都逃不过计量和语义了,语义难度大,现实应用较少,计量分析(这里理解为利用数理原理进行分析的方法)内涵丰富,研究较多。个人觉得,词频分析、共现分析、基于图论的分析方法,都属于这个范畴。词频分析的难点,也是这一方面分析的基础性难题,就是“词”的确定。中文中需要分词处理,特定领域( domain )需要特征词提取,每一个问题都是大问题,由计算机全自动处理能够取得一定的效果,但似乎都逃脱不掉人工标注,尤其是在情报学领域的研究,似乎人参与的部分所占比例更大,计算机科学则在尽力解决如果让人参与得更少。现在的方法热点,也集中在寻找一种更好地数理理论模型,来解决具体领域的一些问题,揭示存在和发展规律(最近似乎都喜欢用“机制”、“演化”这样的词)。 最后, Web 结构化信息的分析目的,这个也是情报学领域里研究的目的吧。通过 Web 信息挖掘,能够为“人”带来什么?个人了解得并不是很多,胡乱谈一通。从服务角度讲,提供协同服务、集成服务、个性化服务是热点;从知识角度讲, Web 知识发现、知识组织方式、知识形成和演化规律;从人的角度,研究网络用户兴趣、认知行为、选择行为、检索行为、交流行为、分享行为等等;从宏观管理的角度,有舆情监测;更细粒度的一些有意见挖掘、情感倾向性分析、话题跟踪与监测、主题识别、分类、聚类等任务,而这些任务主要是计算机领域在解决。 对于 Web 结构信息的研究,有一些倾向于对某个或某些特定领域进行深入的分析,例如 Web2.0 环境下的科学研究的知识交流和知识共享、学术博客的知识组织和整合模式、网络学术社区的信息聚合与共享模式研究等。有些奇怪的是,情报学研究在选择研究领域 时,似乎总喜欢围绕“知识”本身的相关领域。另外,部分研究比较喜欢新的技术,比如 Grid Computing 、 Distributed Computing 、 Linked Data 、 Cloud Computing ,而往往题目是 XXX 在 XXX 中的应用,俨然一副应用科学的样子,还是深入一些好。
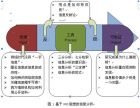
用 VBA 剖析文献计量分析研究中的 统计分析技术 化柏林 ( 中国科学技术信息研究所 北京 100038) (发表于《现代图书情报技术》2007年第4期) 【摘要】 对计量分析研究中的统计按照统计结果进行了详细分类,然后对这些统计进行归纳分析,发现各种统计的关键技术都一样,只是对基础统计的依赖程度和输出结果的表现形式有所不同。在不支持 SQL语句的excel里用VBA进行统计,其实质变成了查找。通过本项研究,有望推动文献计量分析论文的自动生成与深入正文字段的内容分析。 【关键词】 计量分析 统计分析 技术实现 VBA 【分类号】 TP311,G35 Anatomy of statistic analysis technology in bibliometric and analytic system via VBA Hua Bolin ( Institute of Scientific and Technical Information of China, Beijing 100038, china) 【 Abstract 】 Statistic process of bibliometric is classified by statistic result. After concluding and analyzing various statistics, It is showed that critical technology of these statistics is same, but there is some difference in dependence on basic statistic and form of output. Statistic is actualized by find and comparing in excel using VBA, which is not supported with SQL. It is expected that papers of bibliometric can be written automatically and paper text can be analyzed deeply. 【 Keywords 】 bibliometric, statistic analysis, technical implement, VBA 文献计量中的统计按照对象分为作者统计、关键词、机构统计、主题统计、分类号统计、期刊统计、地区统计、参考文献统计(不同于引文分析)、基金资助统计、篇名统计、摘要统计、正文统计。按照统计结果又分为Top N 统计、奇异值统计、数量分布统计、年度增长统计、其它关联统计。统计计算过程与类型如图 1 所示。 图1 统计计算过程与类型图 1 数量初步统计 初步统计从技术实现上分为顺排统计与倒排统计。顺排统计指每一步统计只针对一条记录,如一篇文章含有几个关键词 ( 篇含关键词数 ) 、一个标题含多少字 ( 标题长度 ) ;倒排统计指每一项的统计涉及很多条记录,如一个关键词出现在哪些文章里,即统计关键词在统计样本里的总频次。顺排统计一般只需要 一重循环就可以了,而倒排统计往往要麻烦得多。 在不能使用 SQL 语句的情况下,倒排统计变成了一个查找的过程。以作者统计为例的统计程序流程如图 2 所示。 图 2 作者统计数据流程图 以作者统计为例的处理过程如下:从源表里每取一个数据,就要到目标表里去找,如果已经出现,那么在相应值后加 1 ,如果没有找到,则把该作者追加到后面,并初始化值为 1 。该程序需要注意的地方是对目标表必须遍历一趟才能知道有没有,所以用个布尔变量 bFind 来控制,如果找到了,置为 True ;如果没有找到,一直为 False 。也就是说相等说明找到了,不相等不能说明没有找到,只有所有的都不相等才能说明没有找到。统计程序源代码如表 1 所示。 表 1 关键词统计程序源代码 1: For i = 1 To iSrceCount 2: For j = 1 To 20 3: bFind = False 4: sTemp = Trim(Worksheets(sSrce).Cells(i, j)) 5: If sTemp = Then 6: Exit For 7: End If 8: For k = 1 To iDestCount 9: If sTemp = Worksheets(sDest).Cells(k, 1) Then 10: Worksheets(sDest).Cells(k, 2) = Worksheets(sDest).Cells(k, 2) + 1 11: bFind = True 12: Exit For 13: End If 14: Next 15: If bFind = False Then 16: iDestCount = iDestCount + 1 17: Worksheets(sDest).Cells(iDestCount, 1) = sTemp 18: Worksheets(sDest).Cells(iDestCount, 2) = 1 19: End If 20: Next 21: Next 这个算法速度非常慢,当有近五万条数据时,执行时间为二十多个小时。其原因是查找过程( k 循环)读取的是硬盘,因此把目标内容装到内存里,等操作完毕后再写回硬盘。改造前读写硬盘的次数为 iSrceCount*iCount*iDestCount/2 。在本实验中统计关键词时, iSrceCount=42989 , iDestCount=43980 ,篇均关键词个数为 4.7 ,因此统计关键词时读写硬盘的次数为 42989*4.7*43980/2=8886084234 ,约合为 9G 次。 为了提高程序执行速度, 把要查找的内容装到内存里(也就是变量),执行查找,等完全操作完毕后再写回硬盘,并把查找的过程写成函数,程序代码改造如表 2 所示。 表 2 改造后的统计程序源代码 1: Dim sTable(iRecCount, 2) As String 2: For i = 1 To iRecCount 3: For j = 1 To 10 4: sTemp = Worksheets(sSrce).Cells(i, j) 5: If sTemp = Then 6: Exit For 7: End If 8: iFindCol = findinArray(sTemp, sTable, 1) 9: If iFindCol 0 Then 10: sTable(iFindCol, 2) = sTable(iFindCol, 2) + 1 11: Else 12: iDestCount = iDestCount + 1 13: sTable(iDestCount, 1) = sTemp 14: sTable(iDestCount, 2) = 1 15: End If 16: Next 17: Next 18: For i = 1 To iRecCount 19: Worksheets(sDest).Cells(i, 1) = sTable(i, 1) 20: Worksheets(sDest).Cells(i, 2) = sTable(i, 2) 21: Next findinArray() 函数类似于系统提供的 instr() 函数。 Instr() 查找某字符串在整个字符串中的首次出现的位置,而 findinArray() 查找某字符串在整个数组中的位置。 本程序的查找过程使用了顺序遍历,如果目标数据做成有序的,按字符顺序排列就可以使用二分查找;如果是按频率排序,还需顺序遍历,这样保证高频词快速找到。按字符顺序排序的情况下,插入新数据比较麻烦;按频率排序的情况下,直接在末尾插入就可以了。 2 加权统计 不同位置的数据有着不同的重要性,因此有的统计需要加权。加权统计分为同字段位序加权与多字段加权。同字段位序加权是同一字段内给不同位序的值分配不同的权重,如作者、机构、分类号等都是有位序的,关键词等一般来讲是无序的。多字段加权是为不同的字段分配不同的权重,例如主题分析时为标题、关键词、分类号等字段分配不同的权重,然后利用公式进行计算求得文献的主题,同一个词在标题、关键词、摘要与正文里出现的权重是不同的。 同字段位序加权是按不同的位序分配不同的权重,一般来讲,位置靠前的作者权重高。加权统计有多种算法,常用的加权统计方法有等级分配法 ,即按合著文献中每个作者的排名先后递减分配其权重,设合作者人数为n ,则排名第i 位的著者的权重 为: 。 如果是加权统计,按表 2 进行计算的话, 把对目标表第 2 列加 1 的地方换成 (iCount-j+1)/iSum 就可以了,当然 iCount 与 iSum 要提前求出来。 由于关键词没有顺序关系,因此直接按出现次数进行统计并从大到小排列就可以了。但是统计关键词平均长度时就需要考虑是否带上频率。统计 关键词平均字符个数有两种统计方法,一种是不考虑出现频率的平均长度统计,一种是考虑出现频率的平均长度统计。用每个关键词长度乘以出现频率累加后除以总关键词频数 ,得到带频率的关键词平均长度 。关键词长度统计算法如表 3 所示。 表 3 带频率的关键词长度取值 1: For i = 1 To recCount 2: Worksheets(sDest).Cells(i, 3) = Len(Worksheets(sDest).Cells(i, 1)) 3: Worksheets(sDest).Cells(i, 4) = CInt(Worksheets(sDest).Cells(i, 3)) * CInt(Worksheets(sDest).Cells(i, 2)) 4: Next 3 TopN 统计 Top N是最常用最基本的统计,如高产作者统计、高被引作者(或文章或机构)统计、高频关键词统计等,以分析核心作者、核心期刊、核心研究机构等,Top N的输出以表格式形式所列,一般不进行图形显示。 Top N统计分为两类,一类是绝对数N,不管总数据量有多少,取绝对数N,例如高产作者前50位。另一类是相对数N,这个N的值不是一个确定的数,往往根据总数据量的多少来确定,一般是数据量的百分比。例如核心期刊的确定就是按照总数据量的多少来取,或者按二八原则确定某一专题研究的核心作者 。前者几乎不需要什么算法,直接取就可以了。后者的处理方式很多,有的按数据个数的百分比,有的按数据累加量的百分比。按二八原则取前N项的程序如表4所示。 表 4 按二八原则取前 N 项的程序源代码 1: For i=1 to iRecCount 2: iTotal=iTotal+ Worksheets(sDest).Cells(i, 2) 3: next 4: For i=1 to iRecCount 5: iSum = iSum+ Worksheets(sDest).Cells(i, 2) 6: if iSum/iTotal0.8 then 7: iTopN=i 8: exit for 9: end if 10: next 4 奇异值统计 奇异值统计包括最长、最短、最多、最少等端点值的统计,它不同于Top N统计。Top N统计某一特征的前N项,奇异值统计的是某一特征的端点值,而且有些特征本身就比较特殊,返回的是一个值,这种特征有时是一些很特殊的需求,所反映的是个别现象或特殊情况,如字符数最多的关键词、不含英文字符与标点符号的最长的关键词是什么,有多长,篇含关键词最多的个数,最短标题的长度,用等值统计和加权统计差别最大的作者(前者是不管第几作者都按一篇计算,后者按位序乘以相应的权重,一篇文章所有的和为1,分析是否有挂名现象等)。这些统计不是没有意义,例如找出最长的关键词可以确定可以在使用关键词构成的词库对标题、摘要等字段进行向量分词时确定最大向量长度。奇异值统计不适合以任何图形形式展现。 奇异值统计主要是循环比较,这种奇异值是需要根据特定的需求进行计算。如想查找标题里出现助词的最多的个数,其算法如表5所示。 表 5 统计标题中助词的最多的次数程序源代码 1: For i = 1 To iRecCount 2: sSentence = LTrim(Worksheets(sSrce).Cells(i, iSrceCol)) 3: For j = 1 To Len(sSentence) 4: If InStr(j, sSentence, 的 /u) 0 Then 5: iDeCount = iDeCount + 1 6: Else 7: exit for 8: End If 9: Next 10: If iDeCountiMaxCount then 11: iMaxCount=iDeCount 12: End If 13: Next 本实验先对所有文章标题进行分词,然后进行词性标记,然后再进行查找出现的字最多的标题。经过分词与词性标记避免了的确、有的放矢等噪声的影响,最终求得的iMaxCount 就是标题里含有助词 的最多的个数。 5 数量分布统计 数量分布统计主要统计数量分布关系,如实验中对图书情报学核心期刊的42,989篇文章进行统计分析,发现篇含关键词数量为三到八个的占到95%,这也要与大多数编辑部要求提供三到八个关键词有关,反过来也可以对一些规定进行验证其合理性。再者统计出四字关键词占关键词总数的41%。数量分布统计常以曲线图、柱状图、饼状图等形式展现。数量分布的统计比较简单,求标题长度分布的程序源代码如表6所示。 表 6 统计标题长度分布的程序源代码 1: For i=1 to iRecCount 2: Worksheets(sDest).Cells(i, 2)=len(Worksheets(sDest).Cells(i, 1)) 3: iLength= CInt(Worksheets(sDest).Cells(i, 2)) 4: Worksheets(sDest).Cells(iLength, 7) =Worksheets(sDest).Cells(iLength, 7) + 1 5: Next 实验中把标题长度进行了数量分布的统计,发现14个字符的标题最多,达到3909篇。数量分布统计的关键是找到分布情况,而不是端点值。例如,标题长度介于8~24个字符的文章数量达到38644篇,占90%,介于5~36个字符的文章数量达到42560,占99%。论文标题长度数量分布统计如图3所示。 图 3 标题长度数量分布统计图 6 年度增长统计 年度增长统计主要进行和时间有关的统计,如作者发文量的增长、关键词年度增长情况等。按年度统计可以分析新的生力军、新的研究热点,按关键词统计年度分布可以分析某项研究的生命周期,作者与关键词及年度的关系可以反映作者的研究轨迹。比较是年度增长统计的主要分析手段,无论是增长量还是增长率,都是双目运算。在年度增长的统计图中,必然要有年度作为一个时间维,这种统计常以曲线图或双柱状图,不适合以饼图形式展现。 还有机构的年度分布,或者关键词按年统计并分析出关键词年增长情况,还可分析关键词与期刊或分类号与期刊之间的关系,得到期刊的偏好,以方便大家投稿。按年度统计关键词程序如表7所示。 表 7 按年度统计关键词程序源代码 1: For i = 1 To iRecCount 2: iYear = Format(Date, YYYY) - Sheet5.Cells(i, 2) 3: iYearCol = iYear * 2 - 1 4: For j = 1 To 20 5: bFind = False 6: sTemp = Trim(Worksheets(sSrce).Cells(i, j)) 7: If sTemp = Then 8: Exit For 9: End If 10: For k = 1 To iYearCount(iYear) + 1 11: If sTemp = Worksheets(sDest).Cells(k, iYearCol) Then 12: Worksheets(sDest).Cells(k, iYearCol + 1) = Worksheets(sDest).Cells(k, iYearCol + 1) + 1 13: bFind = True 14: Exit For 15: End If 16: Next 17: If bFind = False And sTemp Then 18: iYearCount(iYear) = iYearCount(iYear) + 1 19: Worksheets(sDest).Cells(iYearCount(iYear), iYearCol) = sTemp 20: Worksheets(sDest).Cells(iYearCount(iYear), iYearCol + 1) = 1 21: End If 22: Next 23: Next 从关键词增长可以看出当年的研究热点,其计算方法也很多。第一种是年增长量,其弊端是高频关键词会靠前,如图书馆、中国等高频关键词会轮流排在前面;第二种方法是倍数,这样上一年较小的关键词排在前面,尤其是上一年频次为1的关键词;第三种方法是增长率,用当年的频次减去上一年的频次后再除以上一年的频次,得到的是相对于上一年的增长率;第四种方法是相对增长率,用当年的频次除以当年的所有关键词总频次f1,上一年的频次除以上一年的所有关键词总频次f2,然后用f1除以f2,当然也可以除以当年的文献数,这种情况主要是考虑不同年的文献量不一样,这种方法反映关键词在当年比重的增长情况;第五种方法是当年的关键词频次减去上一年的关键词频次再除以该关键词所有年的总频次,这种方法能够反映该关键词增长的高峰期,避免了基数大的词在当年排在了前面;第六种方法是把所有上一年为低频的次年变成高频的关键词统计出来,这能反映出关键词的快速增长期,反映出新的研究热点,不同的计算方法有不同的优缺点,可以满足不同的需求。 除了与时间有关的关联统计外,还可以统计关键词与期刊的关系,以及年度关键词与期刊的关系等都能反映出期刊的侧重点或期刊倾向的转变,便于大家有针对性地查资料或者投稿。技术实现上与年度增长统计大同小异。 7 结论 Top N统计、奇异值统计、数量分布统计、年度增长统计、其它关联统计基本上是在初步统计的基础上进行的。这些统计之间既有共性,又存在着差异。统计不是最终目的,最终目的是通过统计,能够做出评价、分析与预测。 不论是哪种统计,关键技术都比较相似,用循环与条件判断两种程序结构加上数学运算函数与字符串处理函数,无论是主题计量分析研究还是引文分析等计量分析研究都可以自动实现。纵观统计技术,实现起来都比较简单,期望更多的非技术背景的人能够很好的使用这种统计分析技术,共同推动计量分析特别是主题型计量分析研究论文的自动化生成。 虽然各种统计的关键技术相似,但不同的统计计算 对基础统计的依赖程度不一样,输出结果的形式也有所不同。 数量初步统计是基础, 各种统计 与基础统计的关系主要有两类,一类是直接在初步统计的基础上,对统计结果进行某种处理,包括数量分布统计和 Top N 统计,它们都绝对依赖于基础统计,如文章所含关键词个数的数量分布依赖于每篇文章所含的关键词数量,高产作者前 N 位依赖于每位作者的发文量;第二类是在进行基础统计的时候加上某种限定条件,包括奇异值统计、年度增长统计、其它关联统计等,它们是部分依赖于基础统计的,如年度增长统计是按年度进行分类统计,在此基础上进行不同年度之间的比较。 本研究尽管实现了对小字段的全自动统计分析,但尚存在以下几个问题:第一,处理大数据量能力有限,因为excel的限制,几十万的数据量处理起来就稍麻烦一些,需要多个sheet连接处理。第二,更多的是统计,对分析做得很不够。如统计模型与信息分析方法的运用很欠缺,缺乏对一些统计结果的自动化分析,如对奇异值的自动分析。也缺乏对统计结果上升到理论层面的验证与分析。对评价、预测与挖掘等深度分析尚未涉及。预测需要数学模型和专门的方法,如趋势外推法、时间序列法等 。挖掘是要从大量的统计数据中总结出新颖的、潜在有用的知识 。第三,没能实现统计报告的自动生成,统计报告要自动生成,语言理解与生成必不可少。使用统计报告要比统计论文更确切一些。这些统计报告大都涉及对数据源的选取、处理过程、统计结果以及对结果的说明,作者会在后续的研究中进一步总结这些报告或论文的框架与写作规律、常用句型的统计计量等,以实现报告或论文的自动化生成。 参考文献 1 娄策群.社会科学评价的文献计量理论与方法.华中师范大学出版社, 1999 : 68 2 李长玲,化柏林.我国网络计量学研究的文献计量分析.图书情报工作, 2006 ( 9 ): 46-50 3 化柏林.图书情报学核心期刊论文标题计量分析研究.情报学报, 2007(x) 4 蔡筱英,金新政,陈氢.信息方法概论.科学出版社:北京. 2004 . 231 , 239 5 粟湘.数据挖掘在科技论文分析中的应用研究 .中国科学技术信息研究所. 2003
 标签: 计量分析
标签: 计量分析