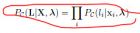@INPROCEEDINGS{XAZZ+13, author = {Xu, Shuo and An, Xin and Zhu, Lijun and Zhang, Yunliang and Zhang, Haodong}, title = {A {CRF}-Based System for Recognizing Chemical Entities in Biomedical Literature}, booktitle = {Proceedings of the 4th BioCreative Challenge Evaluation Workshop}, year = {2013}, volume = {2}, series = {152--157}, abstract = {One of tasks of the BioCreative IV competition, the CHEMDNER task, includes two subtasks: CEM and CDI. We participated in the later subtask, and developed a CEM recognition system on the basis of CRF approach and some open-source NLP toolkits. Our system processing pipeline consists of three major components: pre-processing (sentence detection, tokenization), recognition (CRF-based approach), and post-processing (rule-based approach and format conversion).}, keywords = {Chemical Compound and Drug Name Recognition \sep Conditional Random FField (CRFs) \sep Entity Mention \sep Rule-based Approach}, } 全文见: CEM.pdf
CRF and MRF are two popular graphical models, which is an intuitive model to model all kinds of networks. Recently deep belief network has aroused a huge surge in Machine Learning community, and it got state of the art results in numerous fields, like object recognition, acoustic understanding and topic modeling. DBN is also one kind of graphical models. As we know, CRF is a discriminative model, while MRF is a generative model. Naive Bayes is probably the simplest MRF, while logistic regression is one kind of simple CRFs. The key difference between these two kinds of models is that: MRF is trying to model a joint distribution p(X,Y), however, CRF aims to build a conditional distribution p(Y|X). To be more clear, there are no kinds of potential functions like g(x1,x2) in CRF. Nevertheless, the learning methods procedures are quite the same, and maximum likelihood works for both model. By the way, for parameter learning in DBN, Prof. Hinton developed a method called contrastive divergence, which is pseudo-likelihood. One important theorem in undirected graph is: Hammersley-Clifford theorem: a positive distribution p(y) 0 satisfies the conditional independence properties of an undirected graph G if and only if p can be represented as a product of factors, one per maximal clique.
discriminative model: An introduction to conditional random fields for relational learning (CRF) generative model: Learning deep architectures for AI (DBN)
wiki上的解释: http://en.wikipedia.org/wiki/Conditional_random_field Wallach, H.M.: Conditional random fields: An introduction . Technical report MS-CIS-04-21, University of Pennsylvania (2004) 这篇文章说明了CRF是一个判别式的概率模型,相比普通的判别式模型,里面用到了图论工具,因为CRF用在序列型数据中,样本构成了一条链式结构. Sutton, C., McCallum, A.: An Introduction to Conditional Random Fields for Relational Learning. In Introduction to Statistical Relational Learning. Edited by Lise Getoor and Ben Taskar. MIT Press. (2006) 中的图解说明了CRF与其他模型之间的联系. Lafferty开始给出的CRF的定义为:
 标签: CRF
标签: CRF