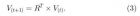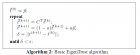Reputation Estimation and Query in Peer-to-Peer Networks Xing Jin, S.-H. Gary Chan IEEE Communications Magazine • April 2010 ABSTRACT Many peer-to-peer systems assume that peers are cooperative to share and relay data. But in the open environment of the Internet, there may be uncooperative malicious peers. To detect malicious peers or reward well behaved ones, a reputation system is often used. In this article we give an overview of P2P reputation systems and investigate two fundamental issues in the design: reputation estimation and query . We classify the state-of-the-art approaches into several categories and study representative examples in each category. We also qualitatively compare them and outline open issues for future research. 1 INTRODUCTION selfish behavior in P2P: malicious actions andmalicious peers KaZaa examples a reputation system:To detect malicious peers or reward well behaved ones, three functional components of a P2P reputation system: -- collecting information on peer behavior --scoring and ranking peers, -- responding based on peers’ scores. the following consideration of reputation system: • Scalability • Adaption to peer dynamics • Security the goal of this paper: to study two fundamental issues in P2P reputation systems -- Reputation estimation: how to generate peer reputation based on others’ feedback. -- three categories: social network, probabilistic estimation, and game-theoretic model. -- Reputation query: -- First, efficient data storage and retrieval is always a challenging issue in P2P networks. -- Second, reputation data are highly security-sensitive -- three categories the organization of this paper: 1) Section 2 explore the reputation estimation issue. 2) Section 3then discuss reputation query techniques. 2 REPUTATION ESTIMATION three reputation estimation methods in current P2P networks: -- The first one is the social network, where all feedback available in the network are aggregated to compute peer reputation. -- The second one is probabilistic estimation, which uses sampling of the globally available feedback to compute peer reputation. -- The third one is the game-theoretic model, which assumes that peers have rational behavior and uses game theory to build a reputation system. 2.1 SOCIAL NETWORK two categories of RS (reputation system) based on social network: -- separated reputation model --correlated reputation model a separated reputation model : -- only the direct transaction partners of a peer (e.g., resource provider/downloader or streaming neighbor) can express their opinion on the reputation of the peer. -- example: eBay,PeerTrust a correlated reputation model: --the reputation of a peer is computed based on the opinion of its direct transaction partners as well as third party peers. -- Example: EigenTrust, the network information and control exchange (NICE) reputation model { author remark: The correlated reputation model is more like our real social network, where third-party peers can express their opinion on a peer. But it takes more cost to collect and aggregate third-party opinion. For example, EigenTrust takes a long time to wait for reputation values to converge.} 2.2 PROBABILISTIC ESTIMATION assumption: methods: -- maximum likelihood estimation -- Bayesian estimation 2.3 GAME-THEORETIC MODEL 3 REPUTATION QUERY the purpose of this section: discuss techniques for reputation query in P2P networks. 3.1 CENTRALIZED AND PARTIALLY CENTRALIZED STRUCTURES The simplest solution: the centralized reputation system, eBay centralized approaches vs.partially centralized approaches 3.1 STRUCTURED OVERLAY distributed hash table (DHT) PeerTrust P-Grid 3.2 UNSTRUCTURED OVERLAY XREP:a polling algorithm four operations of XRep: -- resource searching --vote polling --- vote evaluation --- resource downloading 3.3 COMPARISONS 4 CONCLUSION I comment: the logic of paper is clear. Reputation estimation and query in peer-to-peer networks.pdf
Contents 1 2D Euclidean Distance Transform Algorithms: A Comparative Survey 1 2D Euclidean Distance Transform Algorithms: A Comparative Survey RICARDO FABBRI, LUCIANO DA F. COSTA,and JULIO C. TORELLI and ODEMIR M. BRUNO ACM Computing Surveys, Vol. 40, No. 1, Article 2, Publication date: February 2008. Abstract: The distance transform (DT) is a general operator forming the basis of many methods in computer vision and geometry, with great potential for practical applications. However, all the optimal algorithms for the computation of the exact Euclidean DT (EDT) were proposed only since the 1990s. In this work, state-of-theart sequential 2D EDT algorithms are reviewed and compared, in an effort to reach more solid conclusions regarding their differences in speed and their exactness. Six of the best algorithms were fully implemented and compared in practice. KeyWords and Phrases: Distance transform, exact Euclidean distance map, Dijkstra’s algorithm, shape analysis, computational geometry, performance evaluation 1. OVERVIEW 2. OBJECTIVES 3. ORGANIZATION This work is organized as follows. 1)Section 4 presents the formal definitions required for a precise understanding of the ideas. 2) Section 5 usesan account of DT applications to illustrate its importance and its relation to other entities. 3) Section 6 illustrates the importance of the Euclidean metric, motivating the need for efficient EDT schemes. 4) Section 7 explain the main recent EDT algorithms 5) Section 8 describes the methodology for speed and exactness tests. 6) Section 9 shows the results of the tests 7) Finally, Section 10 lists the main contributions of this work, and future activities. 4. DEFINITIONS 4.1. Main Concepts 2D Euclidean Distance Transform Algorithms.pdf
Contents 1 GRAP: Grey risk assessment based on projection in ad hoc networks 2 移动自组网中非完全信息节点风险评估 GRAP: Grey risk assessment based on projection in ad hoc networks Fu Cai Gao Xiang Liu Minga, Liu Xiaoyang , Han Lansheng , Chen Jing abstract: In this paper, we discuss the risk assessment of ad hoc networks, which have highly dynamic topology, open access of wireless channels, and vulnerable data communication. Conventional risk assessment methods are subjective and unreliable as some nodes reveal little information, and the quantity of samples is limited in ad hoc networks. To solve this problem, we propose a GRAP method , which includes grey relational projection (GRP), grey prediction, and grey decision making. Our scheme is designed to assess nodes’ risk under limited circumstances such as small number of samples, incomplete information and lack of experience. Compared with principal component analysis, GRAP has demonstrated better performance and more flexible characteristics. To further the practicability of this method, we utilize a dynamic grey prediction, which shows high accuracy for decision making. In our scheme, four major nodes’ attributes are selected, and the experiment results suggest that our model is more effective and efficient for risk assessment than principal component analysis in ad hoc networks. 1. Introduction the characteristic of ad hoc networks: self-organization, non-central authority, dynamic topology, and open access of wireless channels The security challenges current solution: trust or reputation evaluation the two category of assessment methods: probability and fuzzy theory 移动自组网中非完全信息节点风险评估 付才 洪亮 彭冰 韩兰胜 徐兰芳 计算机学报 2009-4 摘要: 移动自组网是一种无中心、自组织以及多跳的无线网络,能否有效可靠地对通信节点进行风险评估是保障节点高质量通信的重要因素.当前基于可信度或是信誉的评估方法对评估样本都有特殊的要求,对评估对象提出种种假设,无法辨别间接样本的恶意推荐问题,在实际移动自组网中各个节点尤其是恶意节点对外暴漏的信息往往偏少,样本数量有限,无法明确判断其状态,大部分是非完全信息,从而导致评估结果缺乏客观性与可靠性.文中提出采用 灰色系统理论 描述通信节点非完全信息状态,根据灰类白化以及灰色聚类思想进行节点风险评估.方案针对自组网络通信需求对节点行为进行多关键属性划分,采用味集群方法收集原始样本,避免恶意推荐;将难以用数值精确刻画的关键属性以白化权函数量化,引入灰聚类的概念和计算方法,将实体的通信风险水平定义为实体关键属性值序列针对各评估灰类的聚类评估值,从而得到该实体通信风险水平的相对参考值.分析与实际计算表明该方法是一种适合移动自组网中非完全信息节点风险评估的有效方法. 关键词: 移动自组网;风险评估;灰色理论;非完全信息 1 引言 风险评估 necessity current solution: 可信度或是信誉的角度 (1)基于权重的信任传递方法 (2)基于概率的信任模型 (3)基于证据理论的信任模型 (4)基于主观逻辑的信任模型 (5)模糊集合理论 ad-hoc network 自私节点问题 灰色理论 风险评估 in ad-hoc network 3个方面的核心问题: (1)需要解决样本获取的问题 (2)要解决恶意推荐即间接样本的问题 (3)样本的聚集与应用问题 the organization of this paper: 1) 第2节对灰色系统理论做一个基础描述,并证明灰数白化函数存在定理; 2) 第3节描述恶意节点评估方案,证明方案中各节点样本聚类权满足灰色关联度3个必要条件; 3) 第4节针对实验数据进行实例计算; 4) 第5节对本文的非完全信息节点风险评估机制特点进行总结. 2 基本概念 定义1 评估节点集、味集群 定义2 灰数、灰类集 3 移动自组网节点风险评估方案 the outline of this section: 1) 首先对被评估节点进行关键属性定义,得到关键属性集合 2) 各个评估节点对这些关键属性进行监测后,将样本数据发给t0,通过选择,得到味集群, 3) 对每个味集群样本进行量化单位统一化处理以及指标多极性处理后,进行灰聚类计算, 4) 最后通过味集群决策得出结论 3.1 非完全信息节点风险评估框架 3.2 非完全信息节点风险评估流程 4 实例计算 4.1 关键属性定义 security: 1) 一类是采用常规的“硬安全”措施,比如各种分布式数字签名、群签名、通信加密等; 2) 另外一类是“软安全”,如节点风险评估 节点的行为风险评估 要素 :需要定义关键属性,即确定评估指标 关键属性 + ad-hoc network 4.2 灰类集定义 4.3 白化函数定义 4.4 灰色聚类评估与味集群决策 4.5 灰色聚类算法复杂性分析 5 小结 I comment: in this paper (in chinese), what I am interesting is how to build risk model for ad-hoc network by means of grey model. for grey model, Ihave nointeresting. but I notice this process to build mathematical model. First, author select the key index for ad-hoc network, which includes avability and reliability index. Second, to set the threshold for selecting index Third, clustering and group decision by means of gray model I consider this process clear my some question. I will read it. 移动自组网中非完全信息节点风险评估.pdf
Contents 1 Kai Hwang PowerTrust: A Robust and Scalable Reputation System for Trusted Peer-to-Peer Computing Fuzzy Trust Integration for Security Enforcement in Grid Computing 2 1 Kai Hwang PowerTrust: A Robust and Scalable Reputation System for Trusted Peer-to-Peer Computing Runfang Zhou,and Kai Hwang IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS,2007 Abstract: Peer-to-Peer (P2P) reputation systems are essential to evaluate the trustworthiness of participating peers and to combat the selfish, dishonest, and malicious peer behaviors. The system collects locally -generated peer feedbacks and aggregates them to yield the global reputation scores. Surprisingly, most previous work ignored the distribution of peer feedbacks . We use a trust overlay network (TON) to model the trust relationships among peers. After examining the eBay transaction trace of over 10,000 users, we discover a power-law distribution in user feedbacks. Our mathematical analysis justifies that power-law distribution is applicable to any dynamically growing P2P systems, either structured or unstructured. We develop a robust and scalable P2P reputation system, PowerTrust, to leverage the power-law feedback characteristics. The PowerTrust system dynamically selects small number of power nodes that are most reputable using a distributed ranking mechanism. By using a look-ahead random walk strategy and leveraging the power nodes, PowerTrust significantly improves in global reputation accuracy and aggregation speed. PowerTrust is adaptable to dynamics in peer joining and leaving and robust to disturbance by malicious peers. Through P2P network simulation experiments, we find significant performance gains in using PowerTrust. This power-law guided reputation system design proves to achieve high query success rate in P2P file-sharing applications. The system also reduces the total job makespan and failure rate in large-scale, parameter-sweeping P2P Grid applications. Index Terms: Peer-to-Peer system, overlay network, distributed hash table, reputation system, eBay trace data set, distributed file sharing, P2P Grids, PSA benchmark, system scalability. 1 INTRODUCTION reputation management examples: eBay and its drawbacks trend: calculate the global reputation scores by aggregating peer feedbacks in adistributed manner six key issues for designing a cost-effective P2P reputation system: . High accuracy . Fast convergence speed . Low overhead . Adaptive to peer dynamics . Robust to malicious peers . Scalability the common ignorance of previous work: ignored the distribution of peer feedbacks or assumed an arbitrary random distribution the organization of this paper: 1) Section 2 reviews existing work on P2P reputation systems. 2) Section 3 introduce the new PowerTrust system concept and the use of trust overlay network. 3) Section 4 analyze the eBay trace data to reveal the powerlaw distribution of peer feedbacks. 4) Section 5 specifies the detailed design ofPowerTrust system and the reputation aggregation algorithms used. 5)Section 6 evaluate the performance attributes of the PowerTrust system 6) Section 7 report its application benchmark results 2 RELATED WORKS 3 OUR POWERTRUST SYSTEM APPROACH 3.1 The PowerTrust System Concept five functional modules of the system: 1) The regular random walk module: supports the initial reputation aggregation. 2) The look-ahead random walk (LRW) module: to update the reputation score,periodically. 3)a distributed ranking module: to identify the power nodes. 3.2 Trust Overlay Network (TON) TON: a virtual network on top of a P2P system 4 POWER-LAW DISTRIBUTION OF PEER FEEDBACKS Power-law distribution Three key parameters: 1) The feedback amount of a node 2) Feedback frequency 3) The ranking index 4.1 Collection Procedure of eBay Reputation Data 4.2 Feedback Distribution in eBay Reputation Data linear-regression 4.3 Feedback Distribution Analysis in P2P Systems two factors of the power-law feedback distribution : 1) dynamic growth of TON size 2) preferential node attachment next step: why power-law feedback distribution applies to P2P reputation systems in general? 5 POWERTRUST SYSTEM CONSTRUCTION the outline of this section : to give three construction algorithms 1) the initial construction, 2) distributed ranking, 3) updating process of the PowerTrust system. 5.1 Look-Ahead Random Walk (LRW) PowerTrust: feedback scores are generated by Bayesian learning or by an average rating the trust matrix R the eigenvector of the trust matrix R recursive process: motivated by the Markov random walk, 5.2 Distributed Ranking Mechanism PowerTrust; uses a Distributed Hash Table (DHT)to implement the distributed ranking mechanism. locality preserving hashing (LPH) 5.3 Initial Global Reputation Aggregation 5.4 Global Reputation Updating Procedure 6 SYSTEM PERFORMANCE ANALYSIS analyzed criterion: 1) reputation convergence overhead, 2) ranking discrepancy, 3) aggregation errors by malicious peers 6.1 Simulation Setup and Experiments Performed 6.2 Reputation Convergence Overhead convergence overhead : measured as the number of iterations before the global reputation convergence vs EigenTrust approach 6.3 Reputation Ranking Discrepancy 6.4 Effects of Malicious Peer Behaviors root-mean-square (RMS) 7 P2P APPLICATION BENCHMARK RESULTS the benchmark: PSA, parameter sweeping applications 7.1 Query Success Rate in Distributed File Sharing 7.2 P2P Grid Performance over the PSA Workload 8 CONCLUSIONS AND FURTHER WORK the purpose of this paper : the design experiences and simulated performance of a new P2P reputation system,PowerTrust. the contributions are summarized in four aspects: 1. Power-law distribution of peer feedbacks: 2. Fast reputation aggregation, ranking, and updating 3. System scalability and wide applicability 4. System robustness and operational efficiency further work: 1. Coping with peer abuses and selfishness 2. Reputation system for unstructured P2P System 3. Explore new killer P2P applications 个人点评: 好文章,层次清楚,观点新颖,具有应用价值!多读! PowerTrust A Robust and Scalable Reputation.pdf 又一篇中文翻译版: 基于幂律分布的P2P信誉评估机制.pdf Fuzzy Trust Integration for Security Enforcement in Grid Computing Shanshan Song, Kai Hwang, and Mikin Macwan IFIP International Federation for Information Processing 2004, LNCS Abstract. How to build the mutual trust among Grid resources sites is crucial to secure distributed Grid applications. We suggest enhancing the trust index of resource sites by upgrading their intrusion defense capabilities and checking the success rate of jobs running on the platforms. We propose a new fuzzy-logic trust model for securing Grid resources. Grid security is enforced through trust update, propagation, and integration across sites. Fuzzy trust integration reduces platform vulnerability and guides the defense deployment across Grid sites. We developed a SeGO scheduler for trusted Grid resource allocation. The SeGO scheduler optimizes the aggregate computing power with security assurance under fixed budget constraints. The effectiveness of the scheme was verified by simulation experiments. Our results show up to 90% enhancement in site security. Compared with no trust integration, our scheme leads to 114% improvement in Grid performance/cost ratio. The job drop rate reduces by 75%. The utilization of Grid resources increased to 92.6% as more jobs are submitted. These results demonstrate significant performance gains through optimized resource allocation and aggressive security reinforcement. 1. Introduction fuzzy logic the interaction between two Grid Resource sites The organization of this paper 1) Section 2 present author's distributed security architecture at USC GridSec project. 2) Section 3 introduces the fuzzy logic for trust management. 3) Section 4 describes the process of fuzzy trust integration. 4) Section 5 introduces the optimized resource allocation scheme. 5) Section 6 reported all experimental results. 2. GridSec Project for Trusted Grid Computing Virtual Private Networks (VPNs) vs PKI 3. Fuzzy Logic for Trust Management Two advantages of using fuzzy-logic to quantify trust in Grid applications are: (1) Fuzzy inference is capable of quantifying imprecise data or uncertainty in measuring the security index of resource sites. (2) Different membership functions and inference rules could be developed for different Grid applications, without changing the fuzzy inference engine. the trust index: job success rate and self-defense capability Fuzzy inference : a process to assess the trust index in five steps: (1) Register the initial values of the success rate Φ and defense capability Δ. (2) Use the membership functions to generate membership degrees for Φ and Δ. (3) Apply the fuzzy rule set to map the input space (Φ - Δ space) onto the output space (Γ space) through fuzzy ‘AND’ and ‘IMPLY’ operations. (4) Aggregate the outputs from each rules (5) Derive the trust index through a defuzzification process. fuzzy inference rules 4. Trust Integration Across Grid Resource Sites trust index trust vector the new trust index from the old value and present stimulus Trust update and trust propagation processes are specified in Algorithms 1 and Algorithm 2, respectively two simulation terms : the trust index_TTL and trust vector_TTL 5. Optimization of Trusted Resource Allocation the goal: Based on the fuzzy trust model, we present below in Algorithm 3 the SeGO scheduler for optimized Grid resource allocation. A job is submitted with the descriptor Job = (W, D, T, B), representing the workload, execution deadline, minimum trust, and budget limit Algorithm 4 specifies the trust integration process, in which n jobs are mapped to m sites 6. Simulation Results on Trusted Grid Resource Allocation 7. Conclusions and Suggestions for Further Research 个人点评: 这篇文章主要是基于trust model的 Grid resource allocation. 算法描述方式可借鉴 Fuzzy trust integration for security enforcement in grid computing.pdf
《The EigenTrust Algorithm for Reputation Management in P2P Networks》 Sepandar D. Kamvar,Mario T. Schlosser,Hector GarciaMolina WWW 2003 ABSTRACT Peer-to-peer file-sharing networks are currently receiving much attention as a means of sharing and distributing information. However, as recent experience shows, the anonymous, open nature of these networks offers an almost ideal environment for the spread of self-replicating inauthentic files. We describe an algorithm to decrease the number of downloads of inauthentic files in a peer-to-peer file-sharing network that assigns each peer a unique global trust value , based on the peer’s history of uploads. We present a distributed and secure method to compute global trust values, based on Power iteration. By having peers use these global trust values to choose the peers from whom they download, the network effectively identifies malicious peers and isolates them from the network. In simulations, this reputation system, called EigenTrust, has been shown to significantly decrease the number of inauthentic files on the network, even under a variety of conditions where malicious peers cooperate in an attempt to deliberately subvert the system. Keywords: Peer-to-Peer, reputation, distributed eigenvector computation 1. INTRODUCTION 2. DESIGN CONSIDERATIONS five important issues of P2P reputation system: 1) self-policing 2) anonymity 3) profit to newcomers 4) minimal overhead 5) robust to malicious 3. REPUTATION SYSTEMS example: eBay local trust values The challenge for reputation systems in a distributed environment: how to aggregate the local trust valueswithout a centralized storage and management facility. two drawbacks of previous distributed reputation system: 1)it aggregates the ratings of only a few peers and doesn’t get a wide view about a peer’s reputation, 2)it aggregates the ratings of all the peers and congests the network with system messages asking for each peer’s local trust values at every query. author's approach: based on the notion of transitive trust 4. EIGENTRUST the EigenTrust algorithm the outline of this section: 1) Section 4.1show how to normalize the local trust values in a manner that leads to an elegant probabilistic interpretation and an efficient algorithm for aggregating these values. 2)Section 4.2 discuss how to aggregate the normalized trust values in a sensible manner. 3)Section 4.3 discuss the probabilistic interpretation of the local and global trust values. 4) Section 4.4 through Section 4.6present an algorithm for computing the global trust values. 4.1 Normalizing Local Trust Values normalized local trust value 4.2 Aggregating Local Trust Values converge 4.3 Probabilistic Interpretation rule: 4.4 Basic EigenTrust 4.5 Practical Issues three practical issues : 1) a priori notions of trust 2) inactive peers 3) malicious collectives A malicious collective assumption: pre-trusted peers are essential to this algorithm, as they guarantee convergence and break up malicious collectives. 4.6 Distributed EigenTrust challenge for a distributed system: 1)howto store relative data? 2) 4.7 Algorithm Complexity 5. SECURE EIGENTRUST two basic ideasagainst malicious peers: 1) 2) distributed hash table (DHT) 5.1 Algorithm Description 5.2 Discussion 6. USING GLOBAL TRUST VALUES two clear ways to use these global trust values inP2P system: 1)The first is to isolate malicious peers from the network by biasing users to download from reputable peers. 2) The second is to incent peers to share files by rewarding reputable peers. Isolating Malicious Peers Incenting Freeriders to Share 7. EXPERIMENTS 7.1 Simulation Network model Node model Content distribution model Simulation execution 7.2 Load Distribution in a Trustbased Network 7.3 Threat Models 7.3.1 Other Threat Models 8. RELATED WORK 9. CONCLUSION 个人点评: 似懂非懂,但是必须多次阅读. PPT: sep-kamvar.ppt the eigentrust algorithm for reputation management in p2p networks.pdf
contents: 1 peer-to-peer systems and applications 2 peer-to-peer systems and applications Steinmetz, Ralf; Wehrle, Klaus (Eds.) 2005, springer 1. Introduction 2. What Is This “Peer-to-Peer” About? Internet主要新需求: -- 规模扩展性 -- 安全性和可靠性 -- QoS 3. Past and Future Fully Decentralized Architectures 自组织网络 4. Application Areas 5. First and Second Generation of Peer-to-Peer Systems 6. Random Graphs, Small-Worlds and Scale-Free Networks Models: -- Random Graphs -- Small-Worlds – The Riddle’s First Solution --Scale-Free Networks: How the Rich Get Richer 7. Distributed Hash Tables 8. Selected DHT Algorithms Chord Pastry Content Addressable Network CAN Symphony 9. Reliability and Load Balancing in Distributed Hash Tables 10. P-Grid: Dynamics of Self-Organizing Processes in Structured Peer-to-Peer Systems
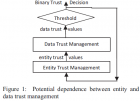
A Survey on Trust Management for Intelligent Transportation System Shuo Ma, Ouri Wolfson,Jie Lin IWCTS’11 ACM, ACM SIGSPATIAL International Workshop on Computational Transportation Science ABSTRACT Trust management is a fundamental and critical aspect of any serious application in ITS. However, only a few studies have addressed this important problem. In this paper, we present a survey on trust management for ITS. We first describe the properties of trust, trust metrics and potential attacks against trust management schemes. Existing related works are then reviewed based on the way in which trust management is implemented. Along with the review, we also identify some open research questions for future work, and consequently present a novel idea of trust management implementation. Keywords: Trust management, Intelligent Transportation System (ITS), Entity trust, Data trust, Attack prevention 1. INTRODUCTION ITS (Intelligent Transportation System) the current work overlook a fundamental issue: trust management -- the management of the trustworthiness of relationships among entities two forms ofinterpretation of trust:entity trust anddata trust the organization of this paper: 1)Section 2 first examine the properties of trust and trust metrics, and briefly describe common attacks against trust management schemes in ITS. 2) Next, Section 3 overview the related work of trust management for ITS and show how those works are connected to the concepts. 3) Finally, Section 4 summarize our discussion and conclude our work. 2. Concepts A. Properties of Trust B. Trust Metrics C. Potential Attacks the types of attacks: -- simple false information injection attacks --on-and-off attacks -- Sybil attacks -- collusion attacks hard security vs.soft security. 3. TRUST MANAGEMENT FOR ITS A. Opinion Piggybacking B. A Novel Trust Management Scheme
Handbook of Research on P2p and Grid Systems for Service-oriented Computing: Models, Methodologies and Applications Nick Antonopoulos (Editor), George Exarchakos (Editor), Maozhen Li (Editor), Antonio Liotta (Editor) Hardcover: 894 pages Publisher: Information Science Publishing (February 5, 2010) Language: English ISBN-10: 1615206868 ISBN-13: 978-1615206865
为了改善ISP与P2P软件服务提供商之间的不和谐,YALE的科研小组想到了一个方法体系(p4p),体现了这样的设计理念,使双方共赢. P4P, which stands for provider portal for P2P applications, is a new architecture to allow explicit and seamless communications between ISPs and P2P applications. It has the potential for making the Internet work more efficiently, in which Internet Service Providers (ISPs) and Peer-to-Peer (P2P) software providers can work cooperatively to deliver data. Current P2P information exchange schemes are network-oblivious and use intricate protocols for tapping the bandwidth of participating users to help move data. The existing schemes are often both inefficient and costly -- like dialing long-distance to call your neighbor, and both of you paying for the call. Professors Avi Silberschatz, Y. Richard Yang, and and Ph.D. candidate Haiyong Xie(国人) in Yale's Department of Computer Science are part of a research team that is involved in the engineering the P4P framework. The Yale team has played many roles in this project, ranging from naming and analyzing the architecture, to testing and to implementation of some key components of the system. T he objective is to have an open architecture that any ISP and any P2P can participate in. Yale has facilitated this project behind the scenes and without direct financial interest through a working group called P4P that was formed in July 2007 to prompt collaboration on the project. The working group is hosted by DCIA and led by working group co-chairs Doug Pasko from Verizon, and Laird Popkin from Pando. Currently, the group has more than 50 participating organizations. 谢海永 博士,首席研究员 美国分布式计算工业联盟(DCIA) P4P工作组 (P4P Working Group) 以上图片来自 谢海永研究员的PPT. 项目主页
 标签: p2p
标签: p2p