博文
好文推荐 ‖ 面向非线性自主系统的强化学习行为控制方法
|
研究背景
近年来,由于非线性系统具有可扩展性和冗余性的优势,以及良好的应用潜力,其逐渐成为了控制领域的研究热点。一个非线性自主系统为了实现预定的控制目标,通常需要完成多个任务,但是这些任务之间可能存在冲突,且难以同时完成。例如非线性自主系统无法沿着预定的路径运动,同时避开路径上的障碍物。如何处理多任务间冲突是非线性自主系统领域的一个难点。
行为控制方法通过建模和融合行为方式提供一种可行的解决方案。然而,行为控制方法依赖一个名为“任务监管器”的模块分配每个任务的优先级。研究人员已设计的有限状态机和模糊任务监管器均依赖人的智能去设计任务优先级的切换规则,而当任务数量较大时,所需要的切换条件数量较多,导致切换规则的设计十分困难。模型预测控制任务监管器则在线实时计算最优的任务优先级,但在每一个采样周期的在线计算将给系统的硬件配置带来巨大的计算和存储压力。
此外,当任务优先级发生切换时,系统的速度容易出现突变现象,从而造成控制输入的突变,进而引发控制代价的急剧上升。现有的行为控制器设计聚焦于提升任务执行性能,因此控制器会在任务优先级切换时,增加控制输入,以减小任务误差,达到高性能的任务执行目标。然而,控制资源通常都是有限的,为了保证极高的任务执行性能而大量消耗控制资源是不可取的,而实现控制消耗和性能的平衡是十分具有价值的。
成果介绍
福州大学电气工程与自动化学院和福州大学5G+工业互联网研究院黄捷教授团队提出了一种强化学习行为控制方法,通过“试错学习”的方式减少了非线性自主系统对人设计任务优先级切换规则和控制器设计的依赖,且将在线的计算负担转移至离线训练,减少了硬件的计算和存储压力。此外,通过在线学习最优的控制策略,有效地降低了系统在任务优先级切换时的控制代价,为非线性自主系统的决策与控制问题提供了新的思路与方法。该研究成果发表于IEEE/CAA Journal of Automatica Sincia 2022年第九卷第九期:Z. Y. Zhang, Z. B. Mo, Y. T. Chen, and J. Huang, "Reinforcement Learning Behavioral Control for Nonlinear Autonomous System" IEEE/CAA J. Autom. Sinica, vol. 9, no. 9, pp. 1561–1573, Sept. 2022. doi: 10.1109/JAS.2022.105797。
所提出的强化学习行为控制为双层结构,其原理框架如图1所示。上层是一个强化学习任务监管器,将行为控制的复合行为作为深度Q网络(Deep Q Network)算法的动作集合,离线学习最优的任务优先级,然后根据离线学习的策略在线指导非线性自主系统智能地选取最优的任务优先级;下层是一个强化学习跟踪控制器,基于辨识者-演员-评论家强化学习算法框架,克服了强非线性导致解析解求取的困难,在线学习最优控制策略,达到任务执行性能的最优化。
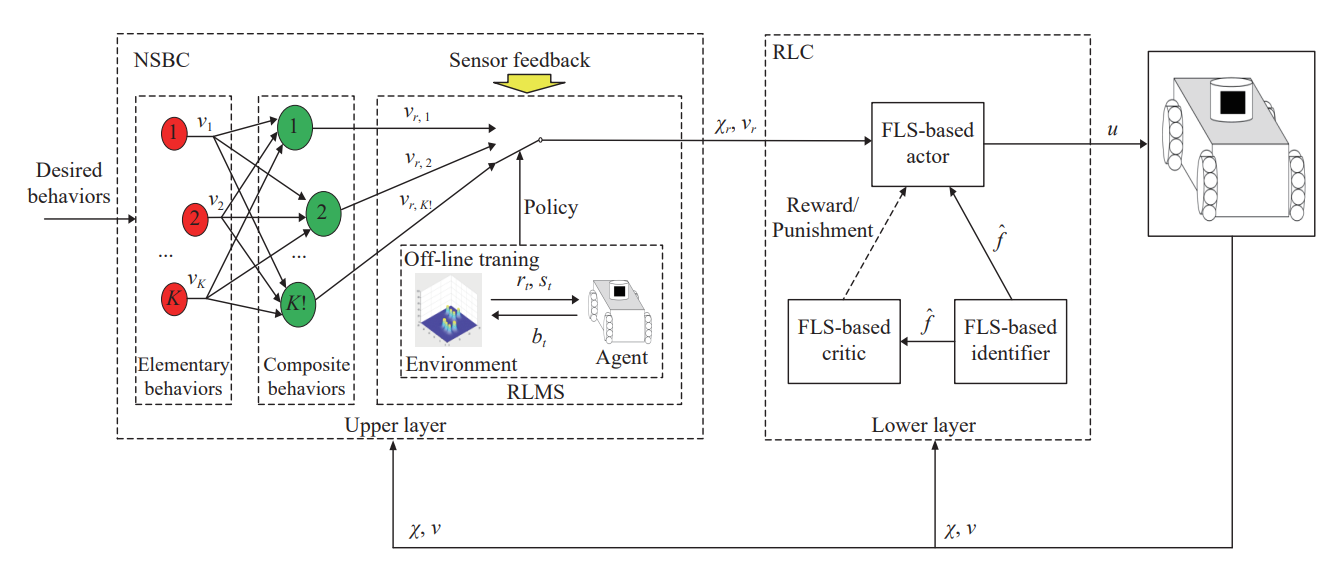
图1 强化学习行为控制原理框图
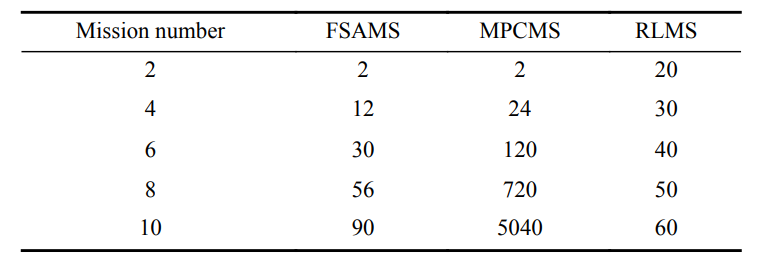
所提出的强化学习任务监管器与现有任务监管器的性能对比如图2和表1所示。从图2中可以看出强化学习任务监管器和模型预测任务监管器比有限状态机任务监管器有更好的任务切换动态性能,这是因为强化学习算法和模型预测控制方法有一定的预见性。从表1中可以看出强化学习任务监管器和有限状态机任务监管器的在线存储空间需求比模型预测任务监管器更低,这是因为模型预测控制方法需要在每一个采样周期在线存储所有任务优先级可能的结果。
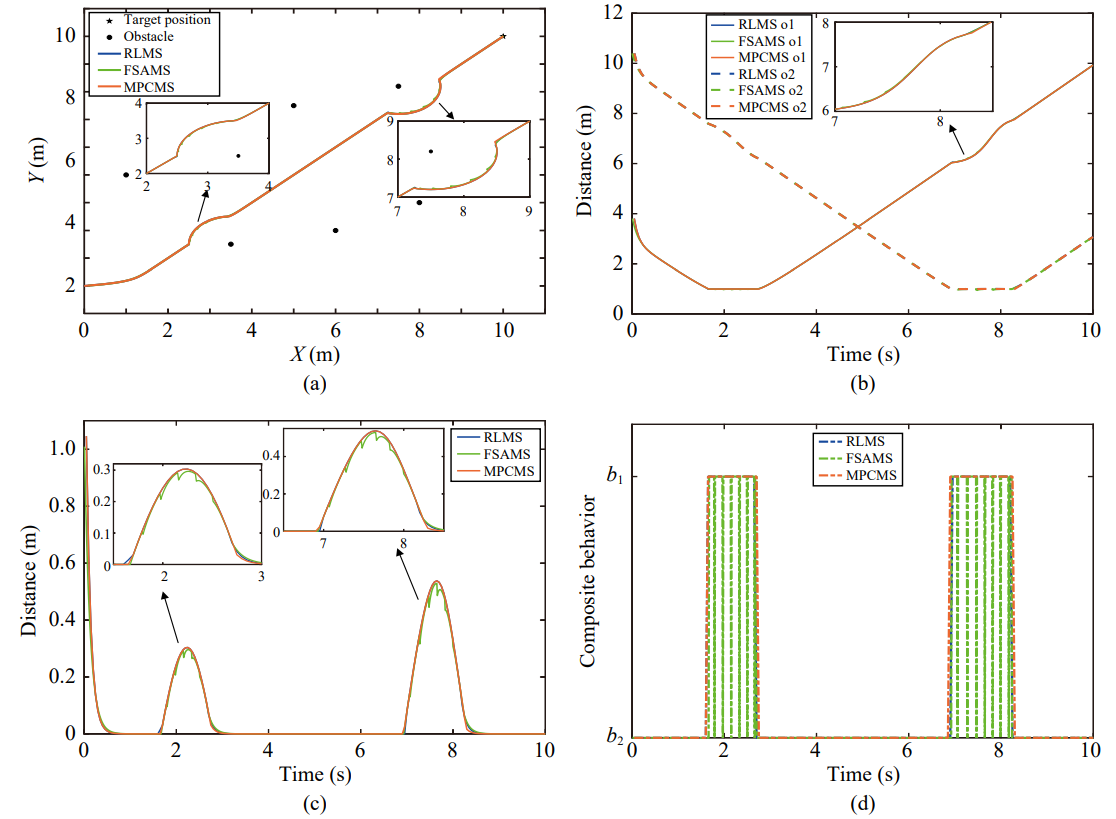
图2 采样周期100赫兹下各任务监管的性能结果图。(a)轨迹,(b)与障碍物的距离,(c)任务跟踪误差,(d)任务优先级切换
表1 各任务监管的在线存储空间随任务数量变化表
所提出强化学习控制器与现有行为控制器的性能对比如图3所示。从图3中可以看出强化学习控制器在任务优先级切换时的控制输入和控制代价最小,这是因为强化学习控制器以最小化控制代价为目标,在线学习最优的控制策略。
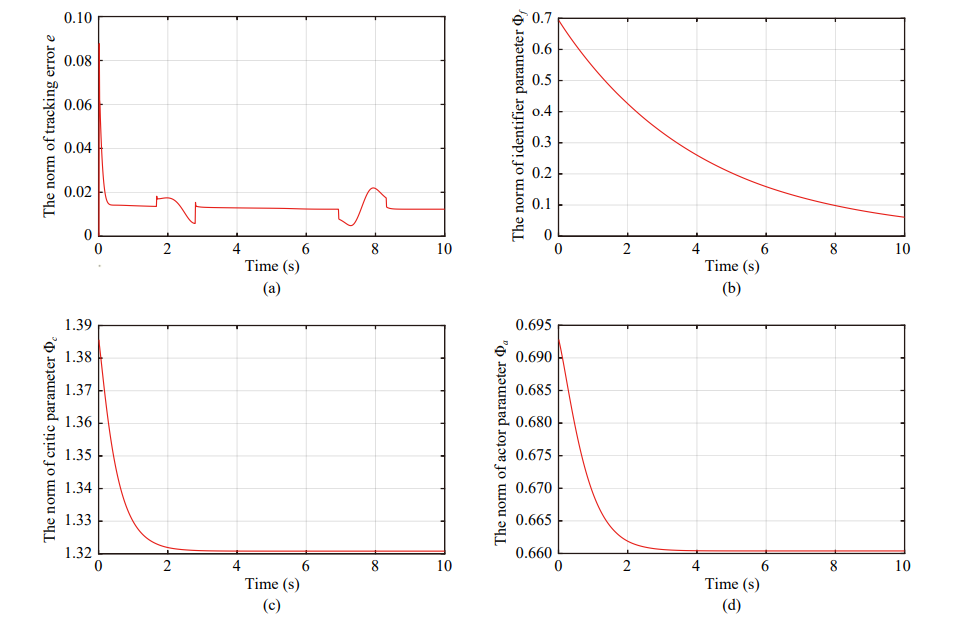
图3 采样周期100赫兹下各控制器的性能结果图。(a)轨迹,(b)控制代价,(c)跟踪误差,(d)控制输入
综上所述,该论文的创新之处可凝练为:
1) 提出了一种新颖的强化学习任务监管器来学习最优的任务优先级。与现有的任务监管器相比,强化学习任务监管器避免了人为设计任务优先级切换规则,并通过试错学习提高了优先级动态切换性能。此外,强化学习任务监管器将繁重的计算负担转移至离线训练过程,从而降低了系统硬件的需求。
2) 设计了具有辨识者-演员-评论家结果的强化学习控制器来最优地跟踪参考轨迹。与现有的行为控制器相比,强化学习控制器分别通过学习非线性模型和最优跟踪控制策略来保证鲁棒性和最优性。此外,强化学习控制器能够有效地降低任务优先级切换时的控制代价。
3) 使用Lyapunov理论证明了跟踪误差和辨识者-演员-评论家网络权重误差均达到半全局一致最终有界。通过数学归纳法给出了具有不同优先级的任务稳定性一般范式。在理论上严格地保证了任务的完成和控制目标的实现。
作者简介

张祯毅,福州大学博士研究生。主要研究方向为机器人行为学、多智能体协同控制和多智能体学习系统。

莫智斌,福州大学硕士研究生。主要研究方向为多智能体学习系统和人机混合增强智能系统。

陈宇韬,福州大学电气工程与自动化学院讲师。主要研究方向为模型预测控制算法,无人智能系统及其相关应用。

黄捷,福州大学电气工程与自动化学院教授、博导,福州大学5G+工业互联网研究院院长。曾获首届IEEE/CAA JAS Norbert Wiener Review Award(2017)、SCIENCE CHINA Information Science (SCIS) Five-Year High-Impact Paper Award(2021)等奖项。主要研究方向为自主机器人、复杂网络动力学和多智能体系统。
https://m.sciencenet.cn/blog-3291369-1368219.html
上一篇:面向全量测点耦合结构分析与估计的工业过程监测方法
下一篇:JAS持续入选中科院分区计算机科学类1区TOP期刊