博文
基于篇章的汉语句法结构树库
|
引用本文
卢露, 矫红岩, 李梦, 荀恩东. 基于篇章的汉语句法结构树库. 自动化学报, 2022, 48(12): 2911−2921 doi: 10.16383/j.aas.c190828
Lu Lu, Jiao Hong-Yan, Li Meng, Xun En-Dong. A discourse-based Chinese chunkbank. Acta Automatica Sinica, 2022, 48(12): 2911−2921 doi: 10.16383/j.aas.c190828
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c190828
关键词
语料库标注,树库,语块,句法分析
摘要
为快速构建一个大规模、多领域的高质树库, 提出一种基于短语功能与句法角色组块的、便于标注多层次结构的标注体系, 在篇章中综合利用标点、句法结构、表述功能作为句边界判断标准, 确立合理的句边界与层次; 在句子中以组块的句法功能为主, 参考篇章功能、人际功能, 以4个性质标记、8个功能标记、4个句标记来描写句中3类5种组块, 标注基本句型骨架, 突出中心词信息. 目前已初步构建有质量保证的千万汉字规模的浅层结构分析树, 包含60余万小句的9千余条句型结构库, 语料涉及百科、新闻、专利等应用领域文本1万余篇; 同时, 也探索了高效的标注众包管理模式.
文章导读
20世纪90年代以来, 汉语开发了很多体系成熟、影响较大、规模不等的树库, 短语结构树以宾州中文树库(Chinese treebank, CTB)[1]、北京大学汉语树库(Peking University treebank, PCT)[2]、清华汉语树库(Tshinghua Chinese treebank, TCT)[3]等为代表, 依存结构树主要有Chen等[4] 的Sinica、哈尔滨工业大学中文依存树库(HIT Chinese dependency treebank, HIT-CDT)[5]、苏州大学汉语依存树库[6]等. 短语结构树细致地描写了句子结构层次、短语的类别与功能, 转换为浅层结构树与依存关系树较为容易, 但往往中心词、语义关系不突出, 节点与标签较多, 计算开销大; 依存结构树突出中心词信息及依存关系, 便于转化为语义依存描述[7], 同时, 计算开销较少, 符合语言直觉而更易于标注, 但缺乏短语类别与整体功能信息, 缺乏明确依存关系的现象较多, 长距离依存也难以被解析. 一些树库尝试融合短语结构树与依存树的优点, 如TCT、北京大学多视图依存树库(Peking University mu-lti-view Chinese treebank, PMT)[8]. 为克服长句分析不理想的问题, 组块分析采取“分而治之”的策略, 北京大学中文语块库(Chinese chunkbank)[9]根据句法功能, 无嵌套地标注句子骨架, 中文命题树库(Chinese proposition bank, CPB)[10]探索“谓词−论元”结构(Predicate-argument structure)的语义组块分析, 这些树库初步探索了汉语浅层分析树库构建、组块自动分析; 随着篇章级句分析及句间关系日渐被重视, TCT与PCT则在构建树库的同时, 以传统单复句理论为指导, 区分单复句、句群, TCT同时标注句间关系, PCT则初步区分了篇章标记; 而一些篇章理论与语料库则不同程度地探讨了显明篇章标记的作用与分布, 并结合实际需求深入探讨了汉语“句”边界问题[11].
整体而言, 现有树库在规模与句法表示方面主要面临两个挑战: 1)大规模标注困难. 全树句法分析技术在大规模真实语料上正确率不高[12], 现有树库标注体系及加工模式, 人工扩大规模难以既保证标注质量, 又兼顾标注规模与速度. 2)对虽在句中但属于篇章层面、语用表达层面的成分处理牵强, 要么将其纳入句法分析范畴, 增加了句法分析的冗余度与难度, 要么被看作一种可忽略或消除的噪音[1-2], 忽视了篇章的完整性与衔接连贯性, 不便于树库系统地扩展标注层次, 也不利于分析非标准书面语文本.
此外, 大部分树库主要采用20世纪末至21世纪初的新闻杂志语料, 领域相关性问题促使不少树库, 加入了部分学术科技类、应用类、口语类等非标准书面语语料[1, 3, 6, 8, 13]. 然而, 一方面, 句法结构标注难度限制了标注速度与规模, 各树库主要在100 ~ 250万汉字之间; 另一方面, 忽视了大规模真实语料中标点往往具有高歧义性、缺失性、错误性的现象, 很难在标点断句的基础上实现有效句法分析及标注的高一致性.
本文提出一种利于大规模加工的浅层句法标注体系: 以明确的断句方法, 尽可能地反映开放域篇章中句子的结构, 提高标注一致性; 根据短语功能与句法角色, 将句子分析为由句法成分、衔接成分、辅助成分构成的块状组合序列, 以组块状短语结构树为句法表示(见图1), 直接根据各组块的性质及功能, 标注句子骨架, 突出中心词信息. 以该标注体系为指导, 初步完成树库1.0构建工作: 包含Kappa值大于0.8的合格文本1万余篇, 共计1千余万字, 由于树库构建将以短语结构标注为基础, 分级分层逐步完成缺省结构、句间结构标注, 因此先行构建浅层句法结构树库, 因此为后续应用任务及组块依存结构标注、句间关系标注奠定了基础。

图 1 组块状标注结果及浅层分析的树结构示例
本文结构如下: 第1节介绍本树库的设计, 第2节介绍本树库标注实践, 第3节对树库已有数据进行统计分析, 第4节为总结和展望.
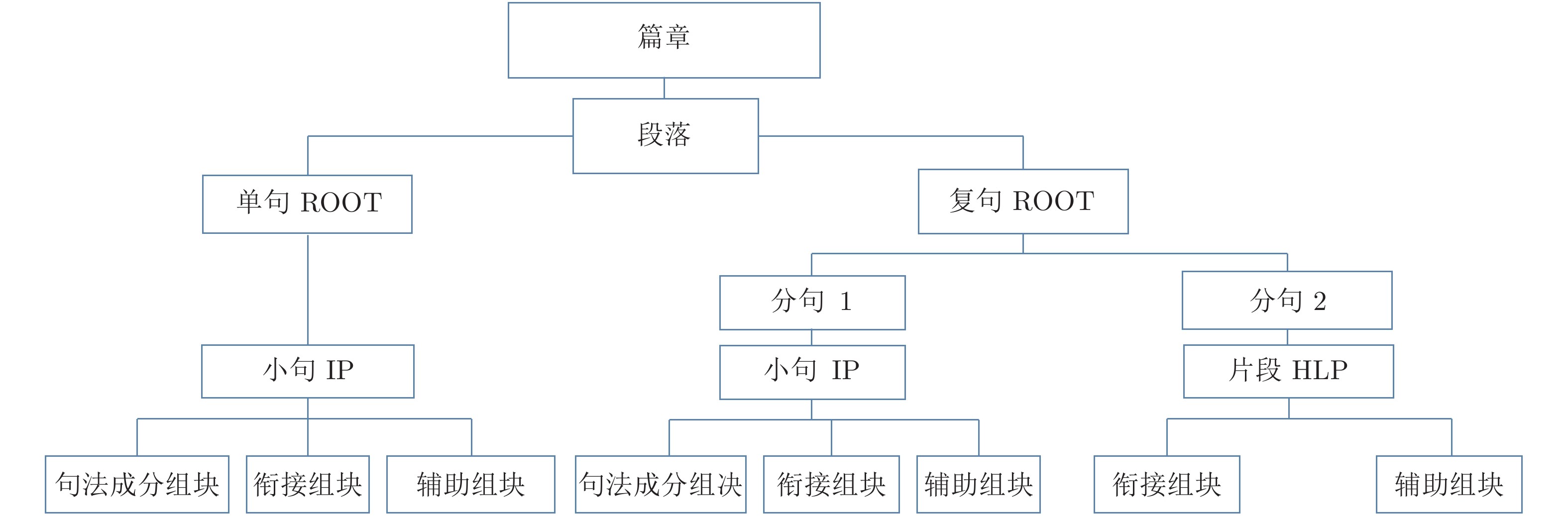
图 2 篇章中“句”的层次结构示例

图 3 标注平台标注界面及管理工具界面
本文介绍了一种基于篇章的、便于多层次结构扩展标注的浅层句法标注体系, 并据此, 初步构建了一个千万汉字级的浅层短语结构树库, 提出一种以述语为核心的句子骨架标注体系, 有助于保证质量的情况下, 进行大规模、多层次结构标注. 同时也探索了众包环境下高效标注管理模式, 为后续各项扩展任务奠定了基础; 未来本文将从三个方面对树库进行扩容: 1)依据解析器分析句型骨架效果、目前树库句型骨架分布抽取相应的篇章、段落、句子进行有针对性的标注, 丰富树库中低频句型语料, 同时依据模型标注准确率的稳定性决定语料类型在树库中的比例; 2)对已标注Kappa值较低的文本进行人机互助的二次复标、审校, 完善人机协同标注模式、全面开启人机协同标注, 加快树库构建速度, 提升预标注模型性能; 3)对已构建的句法块树库, 进行组块依存与话题结构标注, 开发依存树库解析模型, 进一步完善本树库, 从而构建完整的篇章块依存树库, 为后续延展任务打下基础.
作者简介
卢露
北京语言大学信息科学学院硕士研究生. 主要研究方向为语言智能与技术. E-mail: 201821198367@stu.blcu.edu.cn
矫红岩
北京语言大学信息科学学院硕士研究生. 主要研究方向为自然语言处理. E-mail: jiaohongyan0815@163.com
李梦
北京语言大学信息科学学院硕士研究生. 主要研究方向为计算机应用技术. E-mail: limeng_gertrude@163.com
荀恩东
北京语言大学信息科学学院教授. 主要研究方向为自然语言处理. 本文
通信作者.E-mail: edxun@blcu.edu.cn
https://m.sciencenet.cn/blog-3291369-1370509.html
上一篇:人脸亲子关系验证研究综述
下一篇:面向快速响应的赛汝生产系统构建模型与方法