博文
基于拓扑一致性对抗互学习的知识蒸馏
|
引用本文
赖轩, 曲延云, 谢源, 裴玉龙. 基于拓扑一致性对抗互学习的知识蒸馏. 自动化学报, 2023, 49(1): 102−110 doi: 10.16383/j.aas.c200665
Lai Xuan, Qu Yan-Yun, Xie Yuan, Pei Yu-Long. Topology-guided adversarial deep mutual learning for knowledge distillation. Acta Automatica Sinica, 2023, 49(1): 102−110 doi: 10.16383/j.aas.c200665
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c200665
关键词
互学习,生成对抗网络,特征优化,知识蒸馏
摘要
针对基于互学习的知识蒸馏方法中存在模型只关注教师网络和学生网络的分布差异, 而没有考虑其他的约束条件, 只关注了结果导向的监督, 而缺少过程导向监督的不足, 提出了一种拓扑一致性指导的对抗互学习知识蒸馏方法(Topology-guided adversarial deep mutual learning, TADML). 该方法将教师网络和学生网络同时训练, 网络之间相互指导学习, 不仅采用网络输出的类分布之间的差异, 还设计了网络中间特征的拓扑性差异度量. 训练过程采用对抗训练, 进一步提高教师网络和学生网络的判别性. 在分类数据集CIFAR10、CIFAR100和Tiny-ImageNet及行人重识别数据集Market1501上的实验结果表明了TADML的有效性, TADML取得了同类模型压缩方法中最好的效果.
文章导读
图像分类是计算机视觉领域的一个经典任务, 有广泛的应用需求, 例如机场和车站闸口的人脸识别、智能交通中的车辆检测等, 图像分类的应用在一定程度上减轻了工作人员的负担, 提高了工作效率. 图像分类的解决方法也为目标检测、图像分割、场景理解等视觉任务奠定了基础. 近年来, 由于GPU等硬件和深度学习技术的发展, 深度神经网络(Deep neural network, DNN)[1]在各个领域取得了长足的进展, 比如, 在ImageNet大规模视觉识别挑战赛ILSVRC比赛库上的图像分类, 基于深度学习的图像分类方法已经取得了与人类几乎相同甚至超越人类的识别性能. 然而, 这些用于图像分类的深度学习模型往往需要较高的存储空间和计算资源, 使其难以有效的应用在手机等云端设备上. 如何将模型压缩到可以适应云端设备要求, 并使得性能达到应用需求, 是当前计算机视觉研究领域一个活跃的研究主题. 轻量级模型设计是当前主要的解决途径, 到目前为止, 模型压缩方法大致分为基于模型设计的方法[2]、基于量化的方法[3]、基于剪枝的方法[4]、基于权重共享的方法[5]、基于张量分解的方法[6]和基于知识蒸馏的方法[7]六类.
本文主要关注知识蒸馏方法. 知识蒸馏最初被用于模型压缩[8]. 不同于剪枝、张量分解等模型压缩方法, 知识蒸馏(Knowledge distillation, KD)的方法, 先固定一个分类性能好的大模型作为教师网络, 然后训练一个轻量级模型作为学生网络学习教师网络蒸馏出来的知识, 在不增加参数量的情况下提升小模型的性能. 基于知识蒸馏的模型压缩方法, 将教师网络输出的预测分布视为软标签, 用于指导学生网络的预测分布, 软标签反映了不同类别信息间的隐关联, 为新网络的训练提供了更丰富的信息, 通过最小化两个网络预测的Kullback-Leibler (KL)散度差异, 来实现知识迁移. Romero等[9]认为让小模型直接在输出端模拟大模型时会造成模型训练困难, 从而尝试让小模型去学习大模型预测的中间部分, 该方法提取出教师网络中间层的特征图, 通过一个卷积转化特征图大小来指导学生网络对应层的特征图. Yim等[10]使用FSP (Flow of solution procedure)矩阵计算卷积层之间的关系, 让小模型去拟合大模型层与层之间的关系. Peng等[11]和Park等[12]同时输入多个数据, 在原知识蒸馏模型的基础上通过学习样本之间的相关性进一步提升学生网络性能.
考虑到知识蒸馏的本质是知识的迁移, 即将知识从一个模型迁移到另一个模型, Zhang等[13]提出了深度互学习(Deep mutual learning, DML)方法, 设计了一种蒸馏相关的相互学习策略, 在训练的过程中, 学生网络和教师网络可以相互学习, 知识不仅从教师网络迁移到学生网络, 也从学生网络迁移到教师网络.
协同学习也是常见的迁移学习方法之一, 多用于半监督学习. 在协同学习中, 不同的模型或者在不同分组的数据集上学习, 或者通过不同视角的特征进行学习, 例如识别同一组物体类别, 但其中一种模型输入RGB图像, 而另一种模式输入深度图像. 协同属性学习[14]就是通过属性矩阵的融合进行属性的挖掘, 从而指导两个模型的分类. 而深度互学习方法中所有模型在同一数据集上训练完成相同的任务.
尽管现有的知识蒸馏的方法已经取得了长足的进展, 但仍存在以下问题: 1)现有的深度互学习方法仅关注教师网络和学生网络输出的类分布之间的差异, 没有利用对抗训练来提升模型的判别能力; 2)现有的深度互学习仅关注结果监督, 忽视了过程监督. 特别是没有考虑高维特征空间中拓扑关系的一致性. 针对问题1), 本文设计对抗互学习框架, 生成器使用深度互学习框架, 通过对抗训练, 提高教师和学生网络的判别性; 针对问题2), 本文在教师网络和学生网络互学习模型中, 增加过程监督, 即对中间生成的特征图, 设计了拓扑一致性度量方法, 通过结果和过程同时控制, 提高模型的判别能力.
总之, 本文提出了一种基于拓扑一致性的对抗互学习知识蒸馏方法(Topology-guided adversarial deep mutual learning, TADML), 在生成对抗[15]网络架构下, 设计知识蒸馏方法, 教师网络和学生网络互相指导更新, 不仅让教师网络的知识迁移到学生网络, 也让学生网络的知识迁移到教师网络. 本文的模型框架可以推广到多个网络的对抗互学习. TADML由深度互学习网络构成的生成器和一个判别器组成. 生成器的每个子网络都是分类网络. 类似于知识蒸馏, 任一子网络都可以看作是其余网络的教师网络, 对其他网络训练更新, 进行知识迁移. 为方便计算, 本文将所有子网络组视为一个大网络同时优化更新. 每个被看作生成器的子网络, 生成输入图像的特征. 判别器更新时判断生成器的输出特征属于哪一个类别、来源于哪一个子网络, 而生成器更新时尽量混淆判别器使其无法准确判断特征来源于哪一个生成器, 进而拟合网络中隐含的信息.
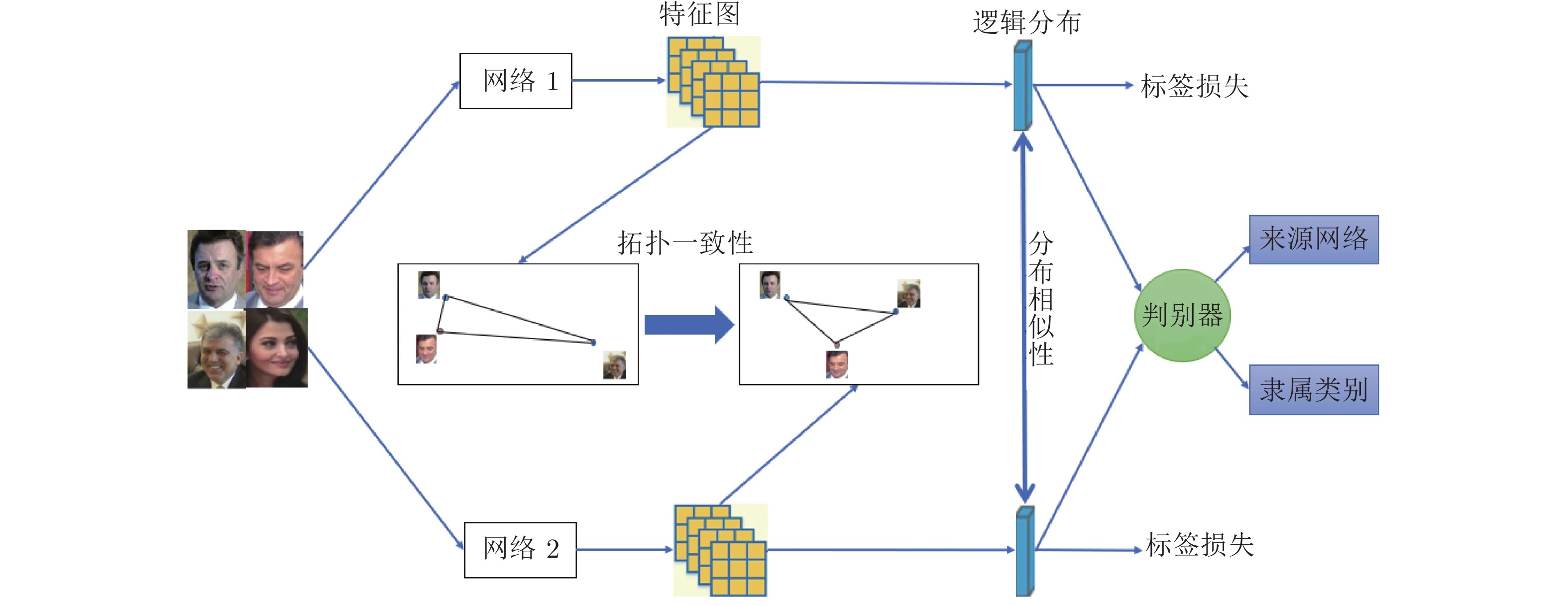
图 1 本文方法框架
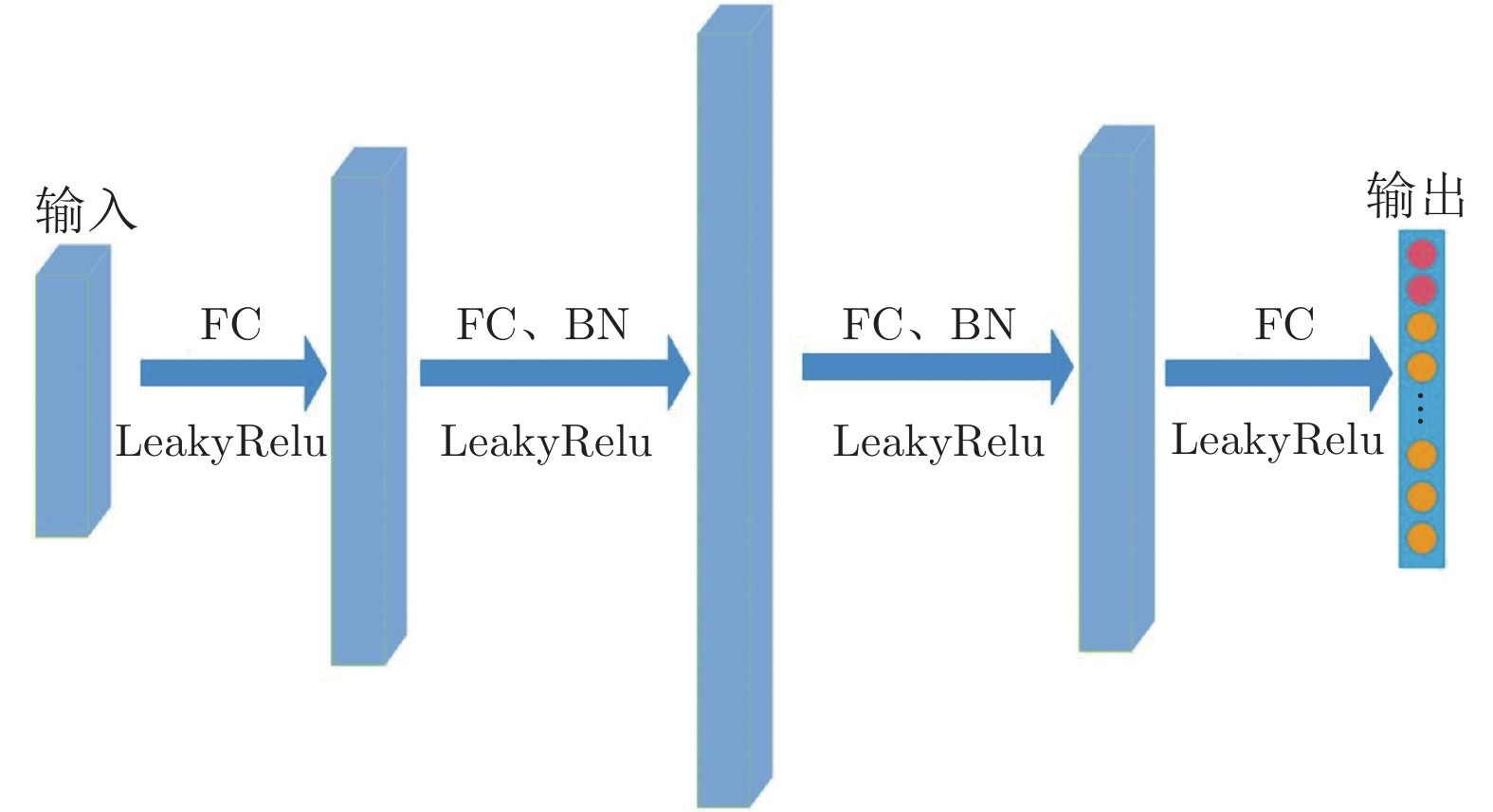
图 2 判别器结构图
本文提出了一种拓扑一致性指导的对抗互学习知识蒸馏方法. 该方法在GAN框架下, 对轻量级的学生网络进行知识迁移, 所提方法设计了样本组间拓扑一致性度量, 依此设计的损失函数结合常规的实例级别的分布相似性, 以及对抗损失及标号损失, 作为训练模型的总损失. 文中评估了不同损失函数和不同模型架构对分类精度的影响. 在3个公开的数据集上验证了本文方法TAMDL的有效性. 本文方法效果稳定且提升明显, 而且在压缩模型的性能比较中, 取得最好的结果.
作者简介
赖轩
厦门大学信息学院硕士研究生. 主要研究方向为计算机视觉与图像处理. E-mail: laixuan@stu.xmu.edu.cn
曲延云
厦门大学信息学院教授.主要研究方向为模式识别, 计算机视觉和机器学习. 本文通信作者.E-mail: yyqu@xmu.edu.cn
谢源
华东师范大学计算机科学与技术学院教授. 主要研究方向为模式识别, 计算机视觉和机器学习. E-mail: yxie@cs.ecnu.edu.cn
裴玉龙
厦门大学信息学院硕士研究生. 主要研究方向为计算机视觉与图像处理. E-mail: 23020181154279@ stu.xmu.edu.cn
https://m.sciencenet.cn/blog-3291369-1372271.html
上一篇:未知非线性零和博弈最优跟踪的事件触发控制设计
下一篇:基于单字符注意力的全品类鲁棒车牌识别