博文
基于长短记忆与信息注意的视频-脑电交互协同情感识别
|
引用本文
刘嘉敏, 苏远歧, 魏平, 刘跃虎.基于长短记忆与信息注意的视频-脑电交互协同情感识别.自动化学报, 2020, 46(10): 2137-2147 doi: 10.16383/j.aas.c180107
Liu Jia-Min, Su Yuan-Qi, Wei Ping, Liu Yue-Hu. Video-EEG based collaborative emotion recognition using LSTM and information-attention. Acta Automatica Sinica, 2020, 46(10): 2137-2147 doi: 10.16383/j.aas.c180107
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c180107
关键词
情感识别,长短记忆神经网络,时-空注意机制,多模态信号融合
摘要
基于视频-脑电信号交互协同的情感识别是人机交互重要而具有挑战性的研究问题.本文提出了基于长短记忆神经网络(Long-short term memory, LSTM)和注意机制(Attention mechanism)的视频-脑电信号交互协同的情感识别模型.模型的输入是实验参与人员观看情感诱导视频时采集到的人脸视频与脑电信号, 输出是实验参与人员的情感识别结果.该模型在每一个时间点上同时提取基于卷积神经网络(Convolution neural network, CNN)的人脸视频特征与对应的脑电信号特征, 通过LSTM进行融合并预测下一个时间点上的关键情感信号帧, 直至最后一个时间点上计算出情感识别结果.在这一过程中, 该模型通过空域频带注意机制计算脑电信号α波, β波与θ波的重要度, 从而更加有效地利用脑电信号的空域关键信息; 通过时域注意机制, 预测下一时间点上的关键信号帧, 从而更加有效地利用情感数据的时域关键信息.本文在MAHNOB-HCI和DEAP两个典型数据集上测试了所提出的方法和模型, 取得了良好的识别效果.实验结果表明本文的工作为视频-脑电信号交互协同的情感识别问题提供了一种有效的解决方法.
文章导读
情感识别是人机交互的重要研究问题之一, 其研究目的是建立可识别人类情感并做出正确反馈的机器人系统, 使人机交互过程更加友好, 自然与智能.本文采用二维情感表示理论[1], 将人类情感表示为"激活度(Arousal)-效价值(Valence)"二维空间中的坐标点(图 1).其中, 激活度用于表现人类情感激励程度的大小, 效价值用于表现人类对情感状态评价的好坏.如人类高兴时, 情感的激活度与效价值的数值均较高.二维情感表示模型可更加充分地表达和量化人类情感状态, 是多数情感识别模型使用的情感表示方法.图 1表示通过图片、视频等外部刺激可诱导出人类不同的情感状态, 进而通过多种传感器采集人类情感的多模态信号用于情感识别.
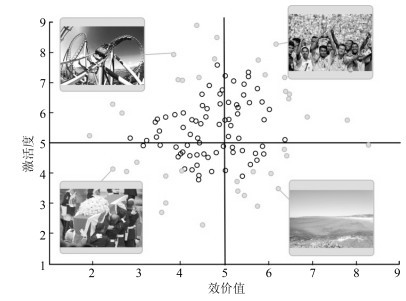
图 1 二维情感表示模型
本文所针对的人脸视频是普通摄像头、深度相机等采集到的人类面部表情信号, 可帮助分析人类直观与外在的情感状态.脑电信号是脑活动产生的微弱生物电于头皮处收集放大的信号, 是大脑内亿万神经元活动在大脑皮层的综合反映, 可帮助分析人类深层与内在的情感状态.使用人脸视频和脑电信号两种模态的情感识别模型可综合人类外在与内在的情感信息, 从而给出更准确的识别结果.通过分析实验参与人员的人脸视频与脑电信号, 识别整段情感信号中实验参与人员的情感激活度和效价值.
传统多模态情感识别方法的基本思路是手动设计提取各模态的特征, 然后进行多模态信号的融合, 最后利用标记数据集训练模式分类器[2-4].然而, 这类方法在处理较大规模的人类情感数据时效率较低.近年流行的深度学习方法具有强大的特征表达能力(例如LSTM (Long-short term memory neural network)在处理时序信号时可达到良好的效果).目前多数基于脑电信号与人脸视频的情感识别方法将两个模态的信号视作时间序列, 对两个模态分别构建LSTM情感识别模型学习得到各个序列的识别结果, 最终将识别结果进行决策层融合[5-6].这些方法在识别效果上优于传统方法.
然而, 该研究内容中仍有两个关键问题亟待解决.一是如何以交互协同的方式融合人类情感的异构多模态信号, 进而给出更加准确的情感识别结果.二是如何从包含大量冗余信息的多模态信号中迅速定位情感关键信息, 从而提升模型的效率和准确率.以一段2分钟的人脸视频为例, 它记录了一位实验参与人员在观看喜剧影像时的表情信息.此视频中, 实验参与人员只有约10秒开怀大笑的表情, 其余视频帧对情感识别是冗余的.
针对以上两个问题, 本文提出了视频-脑电信号交互协同的LSTM情感识别模型, 同时引入了空域频带注意机制和时域注意机制.其结构如图 2所示, 该模型包括特征提取与交互协同两个相互耦合关联的阶段, 以"选择性聚焦"的方式分析人类情感的各模态时间序列, 进而给出情感识别结果.在特征提取阶段, 首先将原始脑电信号可视化为αα波, ββ波与θθ波的图像序列以保留脑电信号的时域-空域信息, 从而令两个模态更高效地交互协同工作; 然后提取基于卷积神经网络(Convolution neural network, CNN)[7]的人脸视频帧与对应的可视化脑电图像的特征.在交互协同阶段, 首先使用LSTM[8]融合两个模态的特征并对该特征序列进行学习; 接下来预测下一时间点上"聚焦"的关键信号帧的时间信息, 将预测反馈至特征提取阶段; 重复上述过程直至序列结束, 最终计算出整段信号的情感识别结果.这一过程中, 通过空域频带注意机制, 模型对脑电信号的α波, β波与θ波可视化图像进行重要度计算, 从而有效利用脑电信号空域关键信息; 通过时域注意机制, 预测下一时间点的关键信号帧时间信息, 高效利用情感数据的时域关键信息.
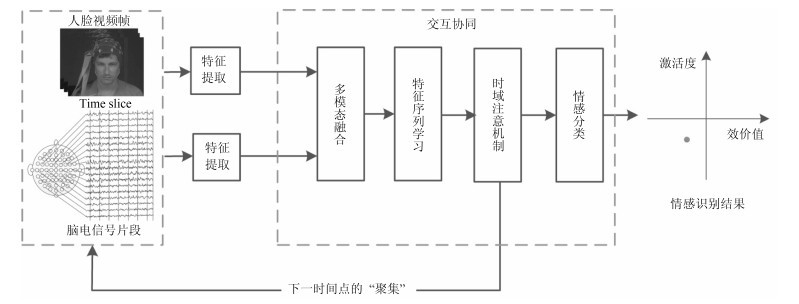
图 2 视频-脑电信号交互协同的情感识别模型
基于上述思想, 本文的章节安排如下:第1节综述情感识别的国内外研究现状; 第2节阐述了基于长短记忆与信息注意的视频-脑电信号交互协同情感识别模型; 第3节描述了模型的训练过程; 第4节给出了模型的计算实验评价结果; 第5节对本文工作进行总结.
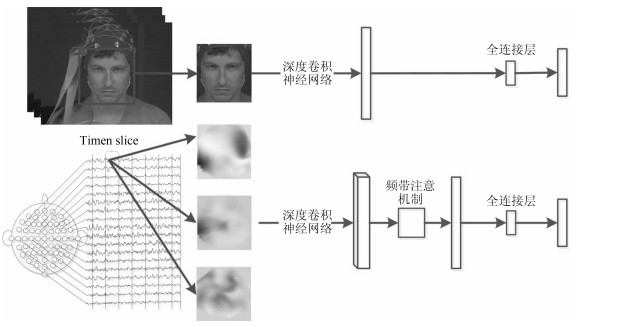
图 3 人脸视频与脑电信号的特征提取过程
本文提出了一种基于长短记忆与信息注意的视频-脑电信号交互协同情感识别方法.该方法具有两个模态信号综合作用、相互补充的优势, 可准确识别人类的情感状态.为了更有效地利用脑电信号的空域关键信息, 所提出方法将脑电信号转换为图像序列, 并利用空域频带注意机制对α, β, θ三个频带的脑电信号进行重要度计算.为了有效利用情感数据的时域关键信息, 引入时域注意机制自动定位情感数据中的关键信号帧.在两个数据集的实验结果表明, 所提出的情感识别模型能够实现更准确的识别效果.然而, 自然场景下得人类情感状态不同于特定数据集, 会随时间发生变化.在保证情感识别效果的前提下, 如何识别一段情感信号中的不同情感状态仍然是未来需要研究的重点问题.
作者简介
刘嘉敏
西安交通大学硕士研究生.主要研究方向为人机交互, 多模态情感识别, 增强学习. E-mail: ljm.168@stu.xjtu.edu.cn
魏平
西安交通大学副教授.主要研究方向为计算机视觉, 机器学习, 认知计算. E-mail: pingwei@xjtu.edu.cn
刘跃虎
西安交通大学教授.主要研究方向为计算机视觉, 人机交互, 增强现实与仿真测试. E-mail: liuyh@mail.xjtu.edu.cn
苏远歧
西安交通大学讲师.主要研究方向为图像处理, 计算机视觉, 计算机图形学.本文通信作者. E-mail: yuanqisu@mail.xjtu.edu.cn
https://m.sciencenet.cn/blog-3291369-1374564.html
上一篇:复杂无向网络连通性的一种高效判定算法
下一篇:基于透镜成像学习策略的灰狼优化算法