博文
STIGMA:单细胞组织特异性基因优先排序
||
STIGMA:单细胞组织特异性基因优先排序
下一代测序方法的广泛引入使得基因分析在临床环境中成为常规。它有利于正在进行的基因发现、功能注释和疾病映射(例如,HPO, OMIM),以及在这些基因中调用、注释、优先排序和过滤变体(例如,gnomAD, DECIPHER)的工具和资源的改进。因此,基因组或外显子组测序的诊断率一直在稳步提高,最近达到41%。然而,到目前为止,只有大约5000个基因的变异与疾病有因果关系。因此,许多功能未知的基因中的潜在有害变异被归类为不确定意义变异(VUSs),在通过实验验证(例如使用原位杂交)进一步验证之前,对罕见疾病的诊断没有贡献。换句话说,不完全的基因-疾病关联仍然是寻找罕见遗传疾病个体分子诊断的重要瓶颈。基因优先排序可以帮助克服这一限制。
基因优先排序是指将基因按与疾病相关的概率排序。它可以帮助缩小候选基因的范围。基因优先排序通常需要对基因的先验知识,包括(1)已知与疾病相关的种子基因列表和(2)基因/蛋白质的数据,如蛋白质-蛋白质相互作用、基因表达谱、已知功能注释(本体、通路等)、疾病-基因关联和基因的内在特性(基因组位置、序列、GC含量、保守性、结构等)。然后,一个计算模型根据该基因的现有注释或基于与交互网络或机器学习模型中的已知疾病相关基因的“关联罪恶感”(“guilt by association”),为每个基因分配“致病”概率。依赖于被优先排序的基因的功能注释或疾病关联的工具通常严重偏向于高度表征的基因。据报道,由于疾病与基因的关联不断演变,这种方法也会产生假阳性预测。相比之下,诸如GeneFriends, GADO,EvoTol和GeneTIER等工具完全依赖于基因表达数据,进化上的不宽容以及内在的基因数据本身是公正的。例如,GeneTIER是基于这样的假设:“负责组织特异性表型的基因在受影响的组织中比未受影响的组织中表达得更高。”这样的注释不可知论工具可以优先考虑缺乏功能注释的候选基因。然而,目前大多数基于基因表达的优先排序工具使用含有器官水平分辨率表达谱的批量RNA测序(bulk RNA-seq)数据(例如,GTEx)。这就引入了关于基因表达特异性的两个主要问题。首先,在这些数据集中平均计算细胞类型特异性基因的表达。其次,这些方法没有明确考虑表达的时间动态,这在器官发生过程中至关重要。在诊断一种罕见的先天性疾病的情况下,这可能导致目前的方法是非特异性和不敏感的。例如,在帕金森病-肌张力障碍(MIM: 613135)的病例中,无法预测已知的疾病-基因关联,作者将其归因于SLC6A3的高度细胞类型特异性表达(MIM: 126455)。使用细胞类型和发育时间特异性基因表达数据可以改善基因优先排序结果。
单细胞测序(scRNA-seq)的蓬勃发展使人类和模式生物的细胞图谱的创建成为可能,为胚胎发育和成年期间的细胞类型、细胞状态、基因表达谱、空间位置和染色质谱提供了参考图谱。这项技术使我们能够更深入地分析整个生命周期(即,从胚胎发育到出生到老年)在细胞分辨率下的健康和疾病状态下的分子机制,并正在改变医疗保健。这些细胞图谱已经被用于确定变异的优先级或建立变异-功能映射。然而,单细胞RNA测序(scRNA-seq)数据尚未应用于基因优先排序,其中考虑了细胞类型特异性或发育阶段特异性表达谱。可以说,唯一的例外是最近发表的一种风险基因鉴定方法VBASS。VBASS使用scRNA-seq数据从大型队列的新生变异数据中鉴定疾病相关基因。相比之下,这里讨论的基因优先排序的目标是缩小罕见疾病或单个个体的候选基因列表。
在这里,Balachandran等人通过使用机器学习(STIGMA,图1)开发单细胞组织特异性基因优先排序,引入基于scRNA-seq数据的先天性疾病基因优先排序。STIGMA根据基因在不同细胞类型中的表达谱预测其致病概率,同时考虑健康(野生型)生物体胚胎发生期间的时间动态,以及一些内在的基因特性。通过将该模型应用于小鼠肢体和人类胎儿心脏scRNA-seq数据集来验证STIGMA方法,分别优先考虑先天性肢体畸形和先天性心脏病(CHD)的基因。STIGMA成功地预测了几种基因与疾病的关联,如最近报道的与肢体畸形相关的UBA2 (MIM: 613295),以及与室间隔缺损(MIM: 614429)相关的ALDOB (MIM: 612724)和MMP9 (MIM: 120361) 。研究还发现PRDM1 (MIM: 603423)与小鼠左心室发育不全和主动脉弓发育不全有关(MGI: J:175213)。
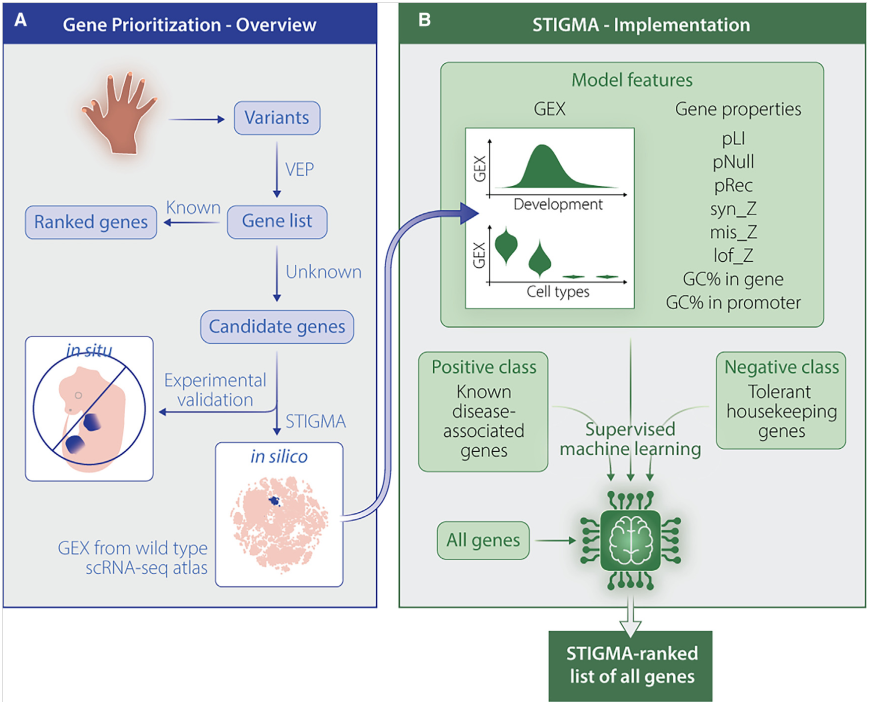
图1 先天性疾病(如肢体畸形)的遗传诊断工作流程包括检测变异及其优先排序,通常会产生许多需要实验验证的候选基因。STIGMA能够利用野生型模式生物的发育细胞图谱对候选基因进行优先排序。(B)在STIGMA中,监督机器学习应用于阳性和阴性类的单细胞基因表达数据以及内在基因特性(例如,pLI, lof_z)。然后预测所有基因(包括缺乏功能注释的基因)的致病性概率,从而得出基因排序表。GEX代表基因表达
STIGMA使用R和Python混合编程实现,详见https://github.com/SpielmannLab/STIGMA。
参考文献
[1] Balachandran S, Prada-Medina CA, Mensah MA, Kakar N, Nagel I, Pozojevic J, Audain E, Hitz MP, Kircher M, Sreenivasan VKA, Spielmann M. STIGMA: Single-cell tissue-specific gene prioritization using machine learning. Am J Hum Genet. 2024 Jan 8:S0002-9297(23)00443-3. doi: 10.1016/j.ajhg.2023.12.011.
以往推荐如下:
5. EMT标记物数据库:EMTome
8. RNA与疾病关系数据库:RNADisease v4.0
9. RNA修饰关联的读出、擦除、写入蛋白靶标数据库:RM2Target
13. 利用药物转录组图谱探索中药药理活性成分平台:ITCM
19. 基因组、药物基因组和免疫基因组水平基因集癌症分析平台:GSCA
22. 研究资源识别门户:RRID
24. HMDD 4.0:miRNA-疾病实验验证关系数据库
25. LncRNADisease v3.0:lncRNA-疾病关系数据库更新版
26. ncRNADrug:与耐药和药物靶向相关的实验验证和预测ncRNA
28. RMBase v3.0:RNA修饰的景观、机制和功能
29. CancerProteome:破译癌症中蛋白质组景观资源
30. CROST:空间转录组综合数据库

https://m.sciencenet.cn/blog-571917-1422137.html
上一篇:scMayoMap:单细胞RNA测序数据的细胞类型注释工具
下一篇:空间转录组学技术、数据资源和分析方法指南