博文
pandas数据合并pd.merge
|
模拟数据: df1 = pd.DataFrame({'Name':['Raju', 'John', 'Geeta', 'Sita', 'Sohit'], 'Marks':[80, 90, 75, 88, 59], 'Grade':['B', 'A', 'A', 'A', 'A']}) df2 = pd.DataFrame({'Name':['Raju', 'Divya', 'Geeta', 'Sita'], 'Rank':[3, 1, 4, 2 ], 'Gender':['Male', 'Female', 'Female', 'Female']}) |

![]()
参数how=
左连接是保留所有左表的信息,把右表中主键与左表一致的信息拼接进来,标签不能对齐的部分,用NAN进行填充。<无右表的Divya> df = pd.merge(df1, df2[['Name','Gender']], on='Name', how='left') |
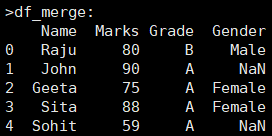
外连接是保留两个表的所有信息,拼接的时候遇到标签不能对齐的部分,用NAN进行填充。 df = pd.merge(df1, df2[['Name','Gender']], on='Name', how='outer') |
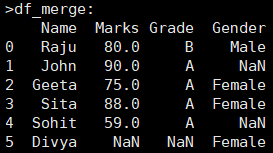
右连接是保留所有右表的信息,把左表中主键与左表一致的信息拼接进来,标签不能对齐的部分,用NAN进行填充。 df = pd.merge(df1, df2[['Name','Gender']], on='Name', how='right') |
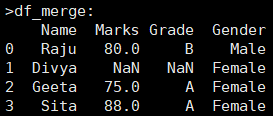

参数suffixes=
如果两个表中有相同的列名,除了作为主键的列之外,其他相同名的列被拼接到表中的时候会有一个后缀表示这个列来自于哪个表格,用于区分名字相同的列,这个后缀默认是(_x和_y),例如这个拼接的结果,能看到Name作为主键,拼接后的表里有两个Grade列,后边会增加后缀。 df = pd.merge(df1, df2[['Name','Grade']], on='Name', how='left') |

后缀是可以自定义的,控制它的参数就是suffixes,将后缀改成了(_L和_R)。 df = pd.merge(df1, df2[['Name','Grade']], on='Name', how='left',suffixes=('_L','_R')) |


参数indicator=
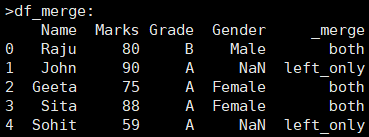
通过indicator参数设置,默认是False不显示数据来源,把参数设置为True显示拼接后的表中信息来自于哪个表格。 df = pd.merge(df1, df2[['Name','Gender']], on='Name', how='left',indicator=True) |
注意:
如果df内有重复数据,合并之后的结果也有会重复的数据。

https://m.sciencenet.cn/blog-994715-1394596.html
上一篇:pandas中阶实战
下一篇:R和Rstudio安装说明